Index Next: Table 02 Submission 12-Mar-1998
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Alphabets, Letters and Diacritics in European Languages (As They Appear in Geography)
1 Vigleik Leira (Norway): [email protected] Alphabets, Letters and Diacritics in European Languages (as they appear in Geography) To the best of my knowledge English seems to be the only language which makes use of a "clean" Latin alphabet, i.d. there is no use of diacritics or special letters of any kind. All the other languages based on Latin letters employ, to a larger or lesser degree, some diacritics and/or some special letters. The survey below is purely literal. It has nothing to say on the pronunciation of the different letters. Information on the phonetic/phonemic values of the graphic entities must be sought elsewhere, in language specific descriptions. The 26 letters a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z may be considered the standard European alphabet. In this article the word diacritic is used with this meaning: any sign placed above, through or below a standard letter (among the 26 given above); disregarding the cases where the resulting letter (e.g. å in Norwegian) is considered an ordinary letter in the alphabet of the language where it is used. Albanian The alphabet (36 letters): a, b, c, ç, d, dh, e, ë, f, g, gj, h, i, j, k, l, ll, m, n, nj, o, p, q, r, rr, s, sh, t, th, u, v, x, xh, y, z, zh. Missing standard letter: w. Letters with diacritics: ç, ë. Sequences treated as one letter: dh, gj, ll, rr, sh, th, xh, zh. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -

MUFI Character Recommendation V. 3.0: Alphabetical Order
MUFI character recommendation Characters in the official Unicode Standard and in the Private Use Area for Medieval texts written in the Latin alphabet ⁋ ※ ð ƿ ᵹ ᴆ ※ ¶ ※ Part 1: Alphabetical order ※ Version 3.0 (5 July 2009) ※ Compliant with the Unicode Standard version 5.1 ____________________________________________________________________________________________________________________ ※ Medieval Unicode Font Initiative (MUFI) ※ www.mufi.info ISBN 978-82-8088-402-2 ※ Characters on shaded background belong to the Private Use Area. Please read the introduction p. 11 carefully before using any of these characters. MUFI character recommendation ※ Part 1: alphabetical order version 3.0 p. 2 / 165 Editor Odd Einar Haugen, University of Bergen, Norway. Background Version 1.0 of the MUFI recommendation was published electronically and in hard copy on 8 December 2003. It was the result of an almost two-year-long electronic discussion within the Medieval Unicode Font Initiative (http://www.mufi.info), which was established in July 2001 at the International Medi- eval Congress in Leeds. Version 1.0 contained a total of 828 characters, of which 473 characters were selected from various charts in the official part of the Unicode Standard and 355 were located in the Private Use Area. Version 1.0 of the recommendation is compliant with the Unicode Standard version 4.0. Version 2.0 is a major update, published electronically on 22 December 2006. It contains a few corrections of misprints in version 1.0 and 516 additional char- acters (of which 123 are from charts in the official part of the Unicode Standard and 393 are additions to the Private Use Area). -

Developments of the Lateral in Occitan Dialects and Their Romance and Cross-Linguistic Context Daniela Müller
Developments of the lateral in occitan dialects and their romance and cross-linguistic context Daniela Müller To cite this version: Daniela Müller. Developments of the lateral in occitan dialects and their romance and cross- linguistic context. Linguistics. Université Toulouse le Mirail - Toulouse II, 2011. English. NNT : 2011TOU20122. tel-00674530 HAL Id: tel-00674530 https://tel.archives-ouvertes.fr/tel-00674530 Submitted on 27 Feb 2012 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. en vue de l’obtention du DOCTORATDEL’UNIVERSITÉDETOULOUSE délivré par l’université de toulouse 2 - le mirail discipline: sciences du langage zur erlangung der doktorwürde DERNEUPHILOLOGISCHENFAKULTÄT DERRUPRECHT-KARLS-UNIVERSITÄTHEIDELBERG présentée et soutenue par vorgelegt von DANIELAMÜLLER DEVELOPMENTS OF THE LATERAL IN OCCITAN DIALECTS ANDTHEIRROMANCEANDCROSS-LINGUISTICCONTEXT JURY Jonathan Harrington (Professor, Ludwig-Maximilians-Universität München) Francesc Xavier Lamuela (Catedràtic, Universitat de Girona) Jean-Léonard Léonard (Maître de conférences HDR, Paris -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

FUPA) in the UCS Source: Michael Everson and Klaas Ruppel Version: 2.0 Date: 1998-11-02
Title: Encoding Finno-Ugric Phonetic Alphabet (FUPA) in the UCS Source: Michael Everson and Klaas Ruppel Version: 2.0 Date: 1998-11-02 The Finno-Ugric Phonetic Alphabet (FUPA) 0. Introduction This paper presents a collection of characters, diacritics, and notation marks used in the FUPA scheme. This transcription is and has been used creatively by different scientists in different countries at different times (Lagercrantz probably made the most baroque use of the system); therefore the phonetic or phonematic values of the elements of the FUPA are intentionally left aside here. However, all the users of this scheme have one thing in common: they use the FUPA in a technical way, as described below. We prefer the term ÒFUPAÓ to ÒFUTÓ (Finno- Ugric Transcription) because of its analogy to the IPA (International Phonetic Alphabet). It is not the intention of this paper to encourage exact (or over-exact) phonetic transcription or the extensive use of diacritics. The intention is rather to facilitate the use of the FUPA by the Uralicist community in the context of the Universal Character Set (UCS), by ensuring that a comprehensive analysis of the system leads to the possibility of encoding FUPA texts, past and present, with the UCS. In the exploratory versions of this document, firm advice on how to use FUPA will not be given; when the study is complete, however, advice on which characters in the UCS refer to whch letters used in the FUPA system will be given. An example of this, we believe, will be the advice for the LATIN SMALL LETTER ENG to be used in coded representations of FUPA texts, past and present, for the velar nasal, in preference to the GREEK SMALL LETTER ETA, although a great many printed texts use an eta glyph (Ç) and not an eng glyph (Ë). -

Uu Clicks Correlate with Phonotactic Patterns Amanda L. Miller
Tongue body and tongue root shape differences in N|uu clicks correlate with phonotactic patterns Amanda L. Miller 1. Introduction There is a phonological constraint, known as the Back Vowel Constraint (BVC), found in most Khoesan languages, which provides information as to the phonological patterning of clicks. BVC patterns found in N|uu, the last remaining member of the !Ui branch of the Tuu family spoken in South Africa, have never been described, as the language only had very preliminary documentation undertaken by Doke (1936) and Westphal (1953–1957). In this paper, I provide a description of the BVC in N|uu, based on lexico-statistical patterns found in a database that I developed. I also provide results of an ultrasound study designed to investigate posterior place of articulation differences among clicks. Click consonants have two constrictions, one anterior, and one posterior. Thus, they have two places of articulation. Phoneticians since Doke (1923) and Beach (1938) have described the posterior place of articulation of plain clicks as velar, and the airstream involved in their production as velaric. Thus, the anterior place of articulation was thought to be the only phonetic property that differed among the various clicks. The ultrasound results reported here and in Miller, Brugman et al. (2009) show that there are differences in the posterior constrictions as well. Namely, tongue body and tongue root shape differences are found among clicks. I propose that differences in tongue body and tongue root shape may be the phonetic bases of the BVC. The airstream involved in click production is described as velaric airstream by earlier researchers. -

IPA Consonant Trap Rules
IPA Consonant Trap rules Basic rules: Begin the initial set up of the game by moving the IPA symbols (white squares) to six grid spaces, with 10 symbols per space (they are randomized, so just move them in order): The goal is to “trap” all of the IPA symbols in all six grid spaces using the coloured phonetic descrip- tions to match the symbols. All matching symbols within the same grid space count as trapped, so for example, the palatal description in the upper left grid space traps all of the palatal consonants (including labial-palatal, but not alveolopalatal): 1 When the game is over, the board will look something like the following: You want to try to trap symbols as efficiently as possible, such as how fricative traps five symbols in the second grid at the top and in the grid in the lower left. Phonetic descriptions in grey are singletons; there is only one flap/tap, click, etc., so these need to be used wisely. There are two special dark grey descriptions, voiced and voiceless, which should only be used as a last resort because they are so powerful. When you get the end of the game, try to rework the solution to avoid having to use voiced and voiceless. As you’ll see here, the way the symbols were trapped in the upper left changed by the end of the game, in order to make better use of the remaining descriptions, and without having to use voiced and voiceless. Special notes: Lateral approximants are matched by either lateral or approximant; you don’t need both. -
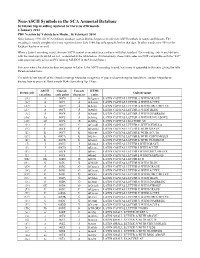
Non-ASCII Symbols in the SCA Armorial Database
Non-ASCII Symbols in the SCA Armorial Database by Iulstan Sigewealding, updated by Herveus d'Ormonde 4 January 2014 PDF Version by Yehuda ben Moshe, 16 February 2014 Since January 1996, the SCA Ordinary database (oanda.db) has begun to encode non-ASCII symbols in names and blazons. The encoding is mostly complete for items registered since July 1980, but only sporadic before that date. In other words, over 90% of the database has been revised. When a Latin-1 encoding exists, the non-ASCII symbol is encoded in accordance with that standard. The resulting code is an 8-bit byte with the most-significant bit set to 1, as detailed in the table below. (Unfortunately, these 8-bit codes are NOT compatible with the "437" code page normally active on PCs running MS-DOS in the United States.) For cases where the character does not appear in Latin-1, the ASCII encoding is used, but a note is appended to the entry giving the fully Da'ud encoded form. The table below lists all of the Da'ud encodings Morsulus recognizes. If you need something not listed there, contact Morsulus to discuss how to proceed. Don't simply Make Something Up. Please. ASCII Unicode Unicode HTML Da'ud code Unicode name encoding code point character entity {'A} A 00C0 À À LATIN CAPITAL LETTER A WITH GRAVE {A'} A 00C1 Á Á LATIN CAPITAL LETTER A WITH ACUTE {A^} A 00C2 Â Â LATIN CAPITAL LETTER A WITH CIRCUMFLEX {A~} A 00C3 Ã Ã LATIN CAPITAL LETTER A WITH TILDE {A:} A 00C4 Ä Ä LATIN CAPITAL LETTER A WITH DIAERESIS {Ao} Aa 00C5 Å Å LATIN CAPITAL LETTER -

Information to Users
INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adversely affect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand comer and continuing from left to right in equal sections with small overlaps. Photographs included in the original manuscript have been reproduced xerographicaily in this copy. Higher quality 6” x 9” black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order. ProQuest Information and Learning 300 North Zeeb Road, Ann Arbor, Ml 48106-1346 USA 800-521-0600 UMI* GROUNDING JUl’HOANSI ROOT PHONOTACTICS: THE PHONETICS OF THE GUTTURAL OCP AND OTHER ACOUSTIC MODULATIONS DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of the Ohio State University By Amanda Miller-Ockhuizen, M.A. The Ohio State University 2001 Dissertation Committee: Approved by Mary. -

Phonetic Analysis of Clicks, Plosives and Implosives of Isixhosa: a Preliminary Report
Phonetic Analysis of Clicks, Plosives and Implosives of IsiXhosa: A Preliminary Report MIHOKO WHEELER University of Florida and University of Central Florida [email protected] Abstract: This pilot study examined the effectiveness of locus equations in differentiating places of articulation among stop consonants (clicks, plosives and implosives) in IsiXhosa in the context of the vowel /a/. The results obtained showed that the slope values for the dental and the postalveolar clicks are similar and shallower than that of the lateral click. Velar stops (plosives, implosives and ejectives) exhibited a steeper slope than either the bilabial or the dental stops. These results suggest that locus equations may be effective at distinguishing places of articulation for a variety of stop consonants. 1. Introduction IsiXhosa is a language spoken in South Africa that uses 18 clicks (three places and six manners of articulation). This paper is a pilot study of the acoustic properties differentiating place or articulation of clicks and plosives in isiXhosa in the context of the following low vowel: /a/. 2. Literature Review 2.1. Background of isiXhosa IsiXhosa is a member of the Nguni languages, which belong to a large family of languages called Bantu, named by the German linguist, Wilhelm Bleek, from the word for ‘people’ (Niesler et al. 2005: 460, Pinnock 1998: 5). The language is one of the few Bantu languages that use clicks, and clicks are viewed as the features of earlier languages (Herbert 1990). According to the 2011 census (Statistics South Africa, 2012), it is a statutory national language of South Africa, and there are over 8.15 million native speakers. -

Latin Extended-B Range: 0180–024F
Latin Extended-B Range: 0180–024F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation.