MUFI Character Recommendation V. 4.0: Alphabetical Order
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Origin of the Peculiarities of the Vietnamese Alphabet André-Georges Haudricourt
The origin of the peculiarities of the Vietnamese alphabet André-Georges Haudricourt To cite this version: André-Georges Haudricourt. The origin of the peculiarities of the Vietnamese alphabet. Mon-Khmer Studies, 2010, 39, pp.89-104. halshs-00918824v2 HAL Id: halshs-00918824 https://halshs.archives-ouvertes.fr/halshs-00918824v2 Submitted on 17 Dec 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Published in Mon-Khmer Studies 39. 89–104 (2010). The origin of the peculiarities of the Vietnamese alphabet by André-Georges Haudricourt Translated by Alexis Michaud, LACITO-CNRS, France Originally published as: L’origine des particularités de l’alphabet vietnamien, Dân Việt Nam 3:61-68, 1949. Translator’s foreword André-Georges Haudricourt’s contribution to Southeast Asian studies is internationally acknowledged, witness the Haudricourt Festschrift (Suriya, Thomas and Suwilai 1985). However, many of Haudricourt’s works are not yet available to the English-reading public. A volume of the most important papers by André-Georges Haudricourt, translated by an international team of specialists, is currently in preparation. Its aim is to share with the English- speaking academic community Haudricourt’s seminal publications, many of which address issues in Southeast Asian languages, linguistics and social anthropology. -

The Unicode Standard, Version 6.1 This File Contains an Excerpt from the Character Code Tables and List of Character Names for the Unicode Standard, Version 6.1
Latin Extended-D Range: A720–A7FF The Unicode Standard, Version 6.1 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 6.1. Characters in this chart that are new for The Unicode Standard, Version 6.1 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/errata/ for an up-to-date list of errata. See http://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See http://www.unicode.org/charts/PDF/Unicode-6.1/ for charts showing only the characters added in Unicode 6.1. See http://www.unicode.org/Public/6.1.0/charts/ for a complete archived file of character code charts for Unicode 6.1. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 6.1 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 6.1, online at http://www.unicode.org/versions/Unicode6.1.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, and #44, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. -
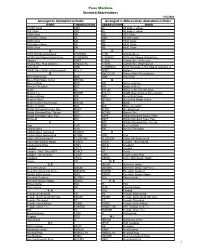
Arranged in Abbreviation Alphabetical Order Arranged in Alphabetical Order Penn Machine Standard Abbreviations
Penn Machine Standard Abbreviations 1/25/2008 Arranged in Alphabetical Order Arranged in Abbreviation Alphabetical Order WORD ABBREVIATION ABBREVIATION WORD 10,000 Class 10M 45 45 degree elbow 150 Class 150 90 90 degree elbow 3000 Class 3M 150 150 Class 45 degree elbow 45 10M 10,000 Class 6000 Class 6M 3M 3000 Class 90 degree elbow 90 6M 6000 Class 9000 Class 9M 9M 9000 Class A A A105 Hot Dip Galvanized A105HDG A105 Carbon Steel A105N Hot Dipped Galvanized A105NHDG A105HDG A105 Hot Dipped Galvanized Adapter ADPT A105A Carbon Steel Annealed Amoco Pipe Plug w/groove AMOCO PL A105N Carbon Steel Normalized Annealed ANN A105NHDG A105 Normalized Hot Dipped Galvanized ASME Spec Defines Dimensions* B16.11 ADPT Adapter B AMOCO PL Amoco Pipe Plug w/groove Bevel Both Ends BBE ANN Annealed Bevel End Nipple Outlet BE NOL B Bevel x Plain BXP B/B Brass to Brass Bevel x Threaded BXT B/S Brass to Steel Blank BL B/S UN Brass to Steel Seat Union Branch Tee BRTEE B16.11 ASME Spec Defines Dimensions* Brass to Brass B/B BBE Bevel Both Ends Brass to Steel B/S BE NOL Bevel End Nipple Outlet Brass to Steel Seat Union B/S UN BL Blank Braze-on Outlet BOL BOL Braze-on Outlet British Standard Parallel Pipe BSPP BOSS Welding Boss British Standard Pipe Thread BST BRTEE Branch Tee British Standard Taper Pipe BSPT BSPP British Standard Parallel Pipe Buttweld BW BSPT British Standard Taper Pipe C BST British Standard Pipe Thread Cap CAP BXP Bevel x Plain Carbon Steel A105 BXT Bevel x Threaded Carbon Steel Annealed A105HT C Carbon Steel Normalized A105N CAP Cap Class 200 -

Supplemental Information 1: System Assumptions
Electronic Supplementary Material (ESI) for Lab on a Chip This journal is © The Royal Society of Chemistry 2011 Supplemental Information 1: System Assumptions Starting from the mass transfer equation: ∂C 2 + υ ⋅ ∇C = D∇ C + R ∂t (a) Distance between the droplet and air channels, O(10‐4) m is much smaller than the distance between the droplet channel PDMS device boundary O(10‐2) m, so little € mass transfer is out of the device and most mass transfer is into the air channel. (b) Assume the oil provides no resistance as compared to the PDMS. (c) Assume psuedo‐steady state since the PDMS boundaries and concentration boundary conditions are fixed: ∂C = 0 ∂t (d) No convection € υ = 0 (e) No reaction € R = 0 (f) Since the oil provides little resistance to mass transfer, the end of the droplets can be assumes as a constant value with surface area equal to the height of the droplet, h, multiplied by the width of the droplet (g) The concentration out the top is a function of the distance between droplet and air channels and will related to mass transfer out the sides for fixed droplet/air separations. This mass transfer can be represented by multiplying by an effective area. Therefore the system is simplified to one dimension. ∂ 2C = 0 ∂x 2 BC1 C(x = 0) = Csat,PDMS € Csat,PDMS BC2 C(x = d) = Cair = HCair Csat,air € (Csat,PDMS − HCair ) C = Csat,PDMS − x d € dC C − HC J = −D = D ( sat,PDMS air ) dx d € € Electronic Supplementary Material (ESI) for Lab on a Chip This journal is © The Royal Society of Chemistry 2011 Supplemental Information 2: Droplet Change This derivation and model is derived assuming an approximate rectangular block shaped droplet with constant fluxes (Jtop, Jend, Jside) out of each the top, the ends and the side of the drop (Atop, Aend, Aside) in Equation S1. -

Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W
Knowl. Org. 46(2019)No.3 209 W. Korwin and H. Lund. Alphabetization Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W. Dunedin Rd., Columbus, OH 43214, USA, <[email protected]> **University of Copenhagen, Department of Information Studies, DK-2300 Copenhagen S Denmark, <[email protected]> Wendy Korwin received her PhD in American studies from the College of William and Mary in 2017 with a dissertation entitled Material Literacy: Alphabets, Bodies, and Consumer Culture. She has worked as both a librarian and an archivist, and is currently based in Columbus, Ohio, United States. Haakon Lund is Associate Professor at the University of Copenhagen, Department of Information Studies in Denmark. He is educated as a librarian (MLSc) from the Royal School of Library and Information Science, and his research includes research data management, system usability and users, and gaze interaction. He has pre- sented his research at international conferences and published several journal articles. Korwin, Wendy and Haakon Lund. 2019. “Alphabetization.” Knowledge Organization 46(3): 209-222. 62 references. DOI:10.5771/0943-7444-2019-3-209. Abstract: The article provides definitions of alphabetization and related concepts and traces its historical devel- opment and challenges, covering analog as well as digital media. It introduces basic principles as well as standards, norms, and guidelines. The function of alphabetization is considered and related to alternatives such as system- atic arrangement or classification. Received: 18 February 2019; Revised: 15 March 2019; Accepted: 21 March 2019 Keywords: order, orders, lettering, alphabetization, arrangement † Derived from the article of similar title in the ISKO Encyclopedia of Knowledge Organization Version 1.0; published 2019-01-10. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Conversion Table a = 1 B = 2 C = 3 D = 4 E = 5 F = 6 G = 7 H = 8 I = 9 J = 10 K =11 L = 12 M = 13 N =14 O =15 P = 16 Q =17 R
Classroom Activity 2 Math 113 The Dating Game Introduction: Disclaimer: Although this is called the “Dating Game”, it is merely intended to help the student gain understanding of the concept of Standard Deviation. It is not intended to help students find dates. The day after Thanksgiving, 1996, I was driving my sister, Conversion Table brother-in-law, and sister-in-law over to meet my brother in A=1 K=11 U=21 Springfield at the Mission where he and his wife helped out. B=2 L=12 V=22 During this drive, I ask my sister, “How do you know which C=3 M=13 W=23 woman is the right one for you?”. Now, my sister was born D=4 N=14 X=24 a Jones, and like the rest of the family, she can make E=5 O=15 Y=25 anything sound believable. Without missing a beat, she F=6 P=16 Z=26 said, “You take the letters in her name, convert them to G=7 Q=17 numbers, find the standard deviation, and whoever’s H=8 R=18 standard deviation is closest to yours is the woman for you.” I=9S=19 I was so proud of my sister, that was a really good answer. J=10 T=20 Then, she followed it up with “Actually, if you can find a woman who knows what a standard deviation is, that’s the woman for you.” The first part was easy, take each letter in your name and convert it to a number. Use the system where an A=1, B=2, .. -

T T Th D P T Th H Ld D P P
Estimating the Size and Components of the U.S. Child Care Workforce and Caregiving Population Key Findings from the Child Care Wo r k f o rce Estimate ( Preliminary Re p o rt ) May 2002 Center for the Child Care Human Services Policy Center, Workforce, U n i versity of Wa s h i n g t o n , Washington, D.C. Seattle, Wa s h i n g t o n Alice Burt o n R i c h a rd N. Brandon, Ph.D. M a rcy Whitebook, Ph.D. Erin Maher, Ph.D. M a rci Yo u n g Dan Bellm Claudia Wa y n e © 2002 Center for the Child Care Wo r k f o rce and Human Services Policy Center Center for the Child Care Wo r k f o rc e The Center for the Child Care Workforce 733 15th St reet, N.W., Suite 1037 The Center for the Child Care Wo r k f o rc e , Washington, DC 20005 founded in 1978 as the Child Care Employe e (202) 737-7700 Project, is a nonprofit re s e a rch and education o rganization whose mission is to improve the Human Se rvices Policy Center quality of child care services by improv i n g Evans School of Public Affairs child care jobsÐÐupgrading the compensa- B ox 353060 tion, working conditions and training of child U n i versity of Wa s h i n g t o n c a re teachers and family child care prov i d e r s . -

Alphabets, Letters and Diacritics in European Languages (As They Appear in Geography)
1 Vigleik Leira (Norway): [email protected] Alphabets, Letters and Diacritics in European Languages (as they appear in Geography) To the best of my knowledge English seems to be the only language which makes use of a "clean" Latin alphabet, i.d. there is no use of diacritics or special letters of any kind. All the other languages based on Latin letters employ, to a larger or lesser degree, some diacritics and/or some special letters. The survey below is purely literal. It has nothing to say on the pronunciation of the different letters. Information on the phonetic/phonemic values of the graphic entities must be sought elsewhere, in language specific descriptions. The 26 letters a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z may be considered the standard European alphabet. In this article the word diacritic is used with this meaning: any sign placed above, through or below a standard letter (among the 26 given above); disregarding the cases where the resulting letter (e.g. å in Norwegian) is considered an ordinary letter in the alphabet of the language where it is used. Albanian The alphabet (36 letters): a, b, c, ç, d, dh, e, ë, f, g, gj, h, i, j, k, l, ll, m, n, nj, o, p, q, r, rr, s, sh, t, th, u, v, x, xh, y, z, zh. Missing standard letter: w. Letters with diacritics: ç, ë. Sequences treated as one letter: dh, gj, ll, rr, sh, th, xh, zh. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -

ISO/IEC JTC1/SC2/WG2 N 2029 Date: 1999-05-29
ISO INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION --------------------------------------------------------------------------------------- ISO/IEC JTC1/SC2/WG2 Universal Multiple-Octet Coded Character Set (UCS) -------------------------------------------------------------------------------- ISO/IEC JTC1/SC2/WG2 N 2029 Date: 1999-05-29 TITLE: Repertoire additions for ISO/IEC 10646-1 - Cumulative List No.9 SOURCE: Bruce Paterson, project editor STATUS: Standing Document, replacing WG2 N 1936 ACTION: For review and confirmation by WG2 DISTRIBUTION: Members of JTC1/SC2/WG2 INTRODUCTION This working paper contains the accumulated list of additions to the repertoire of ISO/IEC 10646-1 agreed by WG2, up to meeting no.36 (Fukuoka). A summary of all allocations within the BMP is given in Annex 1. A list of additional Collections, Blocks, and character tables is given in Annex 2. All additions are assigned to a Character Category, in accordance with clause II of the document "Principles and Procedures for Allocation of New Characters and Scripts" WG2 N 1502. The column Cat. in the table below shows the category (A to G) assigned by WG2. An entry P in this column indicates that the characters are provisionally accepted by WG2. WG2 Cat. No of Code Character(s) Source Current Ballot mtg.res chars position(s) doc. ref. end date NEW/EXTENDED SCRIPTS 27.14 A 11172 AC00-D7A3 Hangul syllables (revision) N1158 AMD 5 - 28.2 A 31 0591-05AF Hebrew cantillation marks N1217 AMD 7 - +05C4 28.5 A 174 0F00-0FB9 Tibetan N1238 AMD 6 - 31.4 A 346 1200-137F Ethiopic N1420 AMD10 - 31.6 A 623 1400-167F Canadian Aboriginal Syllabics N1441 AMD11 - 31.7 B1 85 13A0-13AF Cherokee N1172 AMD12 - & N1362 32.14 A 6582 3400-4DBF CJK Unified Ideograph Exten. -

Chapter 5. Characters: Typology and Page Encoding 1
Chapter 5. Characters: typology and page encoding 1 Chapter 5. Characters: typology and encoding Version 2.0 (16 May 2008) 5.1 Introduction PDF of chapter 5. The basic characters a-z / A-Z in the Latin alphabet can be encoded in virtually any electronic system and transferred from one system to another without loss of information. Any other characters may cause problems, even well established ones such as Modern Scandinavian ‘æ’, ‘ø’ and ‘å’. In v. 1 of The Menota handbook we therefore recommended that all characters outside a-z / A-Z should be encoded as entities, i.e. given an appropriate description and placed between the delimiters ‘&’ and ‘;’. In the last years, however, all major operating systems have implemented full Unicode support and a growing number of applications, including most web browsers, also support Unicode. We therefore believe that encoders should take full advantage of the Unicode Standard, as recommended in ch. 2.2.2 above. As of version 2.0, the character encoding recommended in The Menota handbook has been synchronised with the recommendations by the Medieval Unicode Font Initiative . The character recommendations by MUFI contain more than 1,300 characters in the Latin alphabet of potential use for the encoding of Medieval Nordic texts. As a consequence of the synchronisation, the list of entities which is part of the Menota scheme is identical to the one by MUFI. In other words, if a character is encoded with a code point or an entity in the MUFI character recommendation, it will be a valid character encoding also in a Menota text.