Di-Phone-Based Concatenative Speech Synthesis Systems for Marathi Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Some Principles of the Use of Macro-Areas Language Dynamics &A
Online Appendix for Harald Hammarstr¨om& Mark Donohue (2014) Some Principles of the Use of Macro-Areas Language Dynamics & Change Harald Hammarstr¨om& Mark Donohue The following document lists the languages of the world and their as- signment to the macro-areas described in the main body of the paper as well as the WALS macro-area for languages featured in the WALS 2005 edi- tion. 7160 languages are included, which represent all languages for which we had coordinates available1. Every language is given with its ISO-639-3 code (if it has one) for proper identification. The mapping between WALS languages and ISO-codes was done by using the mapping downloadable from the 2011 online WALS edition2 (because a number of errors in the mapping were corrected for the 2011 edition). 38 WALS languages are not given an ISO-code in the 2011 mapping, 36 of these have been assigned their appropri- ate iso-code based on the sources the WALS lists for the respective language. This was not possible for Tasmanian (WALS-code: tsm) because the WALS mixes data from very different Tasmanian languages and for Kualan (WALS- code: kua) because no source is given. 17 WALS-languages were assigned ISO-codes which have subsequently been retired { these have been assigned their appropriate updated ISO-code. In many cases, a WALS-language is mapped to several ISO-codes. As this has no bearing for the assignment to macro-areas, multiple mappings have been retained. 1There are another couple of hundred languages which are attested but for which our database currently lacks coordinates. -

DEPARTMENT of MARATHI Faculty's of Marathi Department
DEPARTMENT OF MARATHI Faculty’s of Marathi Department Prof. Kalawati B. Mohod Dr. Prashant W. Dhanvij M.A.,B.Ed. M.A., M.Phil., Ph.D.(NET) Associate Professor Assistant Professor Date of Joining: 01 October 1992 Date of Joining: 14 January 2009 About Marathi Language Introduction Marathi is an Indo-Aryan language spoken predominantly by Marathi people of Maharashtra. It is the official language and co-official language in Maharashtra and Goa states of Western India respectively, and it is among the 23 official Languages of India. There were 73 million speakers in 2001; Marathi ranks 19th in the list of most spoken languages in the world. Marathi has the fourth largest number of native speakers in India. Marathi has some of the oldest literature of all modern Indo-Aryan languages, dating from about 900 AD. The major dialects of Marathi are Standard Marathi and the Varhadi dialect. There are other related languages such as Khandeshi, Dangi, Vadavali and Samavedi. Malvani Konkani has been heavily influenced by Marathi varieties. Geographic Distribution Marathi is primarily spoken in Maharashtra and parts of neighbouring states of Gujrat, Madhya Pradesh, Goa, Karnataka, Chhattisgarh and Andhra Pradesh, union-territories of Daman and Div and Dadra and Nagar Haveli. The cities of Baroda, Surat and Ahmedabad (Gujrat), Belgaum (Karnataka), Indore, Gwalior (Madhya Pradesh), Hydrabad and Tanjore (Tamil Nadu) each have sizable Marathi-speaking communities. Marathi is also spoken by Maharashtrian emigrants worldwide, especially in the United States, United Kingdom, Israel, Mauritius and Canada. Official Status Marathi is the official language of Maharashtra and co-official language in the union territories of Daman and Diu and Dadra and Nagar Haveli. -

Unit 1 'Propositions' by Sujit Mukherjee
‘Propositions’ by Sujit UNIT 1 ‘PROPOSITIONS’ BY SUJIT Mukherjee MUKHERJEE Structure 1.0 Objectives 1.1 Introduction 1.1.1 Analysis of the Points Listed in the Introduction 1.2 About the Author, Sujit Mukherjee 1.3 Some Excerpts from Sujit Mukherjee’s ‘Propositions’ 1.4 The Need for a New Methodology to write Indian Literary History 1.4.1 Textual Analysis 1.5 Let Us Sum Up 1.6 Aids to Activities 1.7 Glossary 1.8 Unit End Questions 1.9 References and Suggested Reading 1.0 OBJECTIVES By the end of this unit, you will be able to understand why Sujit Mukherjee wants a new methodology to write Indian literary history learn about his new methodology, taking into account the numerous Indian languages, their literary traditions and the multiple mutual influences of Indian languages on one another discover the running undercurrent of one single Indian literary culture among different Indian languages and literatures Words in bold are explained in the Glossary 1.1 INTRODUCTION Eminent scholars and commentators have criticized the step motherly treatment given to Indian literary studies and traditions vis-à-vis Western literature and culture in our universities and have attributed this lapse to four reasons: 1) The colonial hangover resulting in love for western culture and a continuation of English studies to the neglect of studies in Indian culture and literature. 2) The emphasis on ‘modernity’ that has diminished the importance of Indian literature which is mistakenly viewed as an ancient tradition and therefore anti-modern. 3) The advent of -

Grapheme-To-Phoneme Tools for the Marathi Speech Synthesis
Sangramsing Kayte et al. Int. Journal of Engineering Research and Applications www.ijera.com ISSN: 2248-9622, Vol. 5, Issue 11, (Part - 4) November 2015, pp.87-92 RESEARCH ARTICLE OPEN ACCESS Grapheme-To-Phoneme Tools for the Marathi Speech Synthesis Sangramsing N. Kayte1, Monica Mundada1, Dr. Charansing N. Kayte2, Dr.Bharti Gawali* 1,3Department of Computer Science and Information Technology Dr. Babasaheb Ambedkar Marathwada University, Aurangabad 2Department of Digital and Cyber Forensic, Aurangabad, Maharashtra ABSTRACT We describe in detail a Grapheme-to-Phoneme (G2P) converter required for the development of a good quality Marathi Text-to-Speech (TTS) system. The Festival and Festvox framework is chosen for developing the Marathi TTS system. Since Festival does not provide complete language processing support specie to various languages, it needs to be augmented to facilitate the development of TTS systems in certain new languages. Because of this, a generic G2P converter has been developed. In the customized Marathi G2P converter, we have handled schwa deletion and compound word extraction. In the experiments carried out to test the Marathi G2P on a text segment of 2485 words, 91.47% word phonetisation accuracy is obtained. This Marathi G2P has been used for phonetising large text corpora which in turn is used in designing an inventory of phonetically rich sentences. The sentences ensured a good coverage of the phonetically valid di-phones using only 1.3% of the complete text corpora. Keywords: Grapheme-to-Phoneme (G2P), TTS, Festival, festvox, di-phone, ICT. I. INTRODUCTION foremost reason for this is that developing a TTS Marathi is an Indo-Aryan language spoken system in a new language needs inputs for resolving predominantly by Marathi people of Maharashtra. -

Chapter One: Social, Cultural and Linguistic Landscape of India
Chapter one: Social, Cultural and Linguistic Landscape of India 1.1 Introduction: India also known as Bharat is the seventh largest country covering a land area of 32, 87,263 sq.km. It stretches 3,214 km. from North to South between the extreme latitudes and 2,933 km from East to West between the extreme longitudes. On this 2.4 % of earth‟s surface, lives 16% of world‟s population. With a population of 1,028,737,436 variations is there at every step of life. India is a land of bewildering diversity. India is bounded by the Indian Ocean on the Figure 1.1: India in World Population south, the Arabian Sea on the west and the Bay of Bengal on the east. Many outsiders explored India via these routes. The whole of India is divided into twenty eight states and seven union territories. Each state has its own cultural and linguistic peculiarities and diversities. This diversity can be seen in every aspect of Indian life. Whether it is culture, language, script, religion, food, clothing etc. makes ones identity multi-dimensional. Ones identity lies in his language, his culture, caste, state, village etc. So one can say India is a multi-centered nation. Indian multilingualism is unique in itself. It has been rightly said, “Each part of India is a kind of replica of the bigger cultural space called India.” (Singh U. N, 2009). Also multilingualism in India is not considered a barrier but a boon. 17 Chapter One: Social, Cultural and Linguistic Landscape of India Languages act as bridges because it enables us to know about others. -

Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo
Asia No. Language [ISO 639-3 Code] Country (Region) 1 A’ou [aou] Iouo China 2 Abai Sungai [abf] Iouo Malaysia 3 Abaza [abq] Iouo Russia, Turkey 4 Abinomn [bsa] Iouo Indonesia 5 Abkhaz [abk] Iouo Georgia, Turkey 6 Abui [abz] Iouo Indonesia 7 Abun [kgr] Iouo Indonesia 8 Aceh [ace] Iouo Indonesia 9 Achang [acn] Iouo China, Myanmar 10 Ache [yif] Iouo China 11 Adabe [adb] Iouo East Timor 12 Adang [adn] Iouo Indonesia 13 Adasen [tiu] Iouo Philippines 14 Adi [adi] Iouo India 15 Adi, Galo [adl] Iouo India 16 Adonara [adr] Iouo Indonesia Iraq, Israel, Jordan, Russia, Syria, 17 Adyghe [ady] Iouo Turkey 18 Aer [aeq] Iouo Pakistan 19 Agariya [agi] Iouo India 20 Aghu [ahh] Iouo Indonesia 21 Aghul [agx] Iouo Russia 22 Agta, Alabat Island [dul] Iouo Philippines 23 Agta, Casiguran Dumagat [dgc] Iouo Philippines 24 Agta, Central Cagayan [agt] Iouo Philippines 25 Agta, Dupaninan [duo] Iouo Philippines 26 Agta, Isarog [agk] Iouo Philippines 27 Agta, Mt. Iraya [atl] Iouo Philippines 28 Agta, Mt. Iriga [agz] Iouo Philippines 29 Agta, Pahanan [apf] Iouo Philippines 30 Agta, Umiray Dumaget [due] Iouo Philippines 31 Agutaynen [agn] Iouo Philippines 32 Aheu [thm] Iouo Laos, Thailand 33 Ahirani [ahr] Iouo India 34 Ahom [aho] Iouo India 35 Ai-Cham [aih] Iouo China 36 Aimaq [aiq] Iouo Afghanistan, Iran 37 Aimol [aim] Iouo India 38 Ainu [aib] Iouo China 39 Ainu [ain] Iouo Japan 40 Airoran [air] Iouo Indonesia 1 Asia No. Language [ISO 639-3 Code] Country (Region) 41 Aiton [aio] Iouo India 42 Akeu [aeu] Iouo China, Laos, Myanmar, Thailand China, Laos, Myanmar, Thailand, -
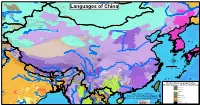
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

ONLINE APPENDIX: Not for Print Publication
ONLINE APPENDIX: not for print publication A Additional Tables and Figures Figure A1: Permutation Tests Panel A: Female Labor Force Participation Panel B: Gender Difference in Labor Force Participation A1 Table A1: Cross-Country Regressions of LFP Ratio Dependent variable: LFPratio Specification: OLS OLS OLS (1) (2) (3) Proportion speaking gender language -0.16 -0.25 -0.18 (0.03) (0.04) (0.04) [p < 0:001] [p < 0:001] [p < 0:001] Continent Fixed Effects No Yes Yes Country-Level Geography Controls No No Yes Observations 178 178 178 R2 0.13 0.37 0.44 Robust standard errors are clustered by the most widely spoken language in all specifications; they are reported in parentheses. P-values are reported in square brackets. LFPratio is the ratio of the percentage of women in the labor force, mea- sured in 2011, to the percentage of men in the labor force. Geography controls are the percentage of land area in the tropics or subtropics, average yearly precipitation, average temperature, an indicator for being landlocked, and the Alesina et al. (2013) measure of suitability for the plough. A2 Table A2: Cross-Country Regressions of LFP | Including \Bad" Controls Dependent variable: LFPf LFPf - LFPm Specification: OLS OLS (1) (2) Proportion speaking gender language -6.66 -10.42 (2.80) (2.84) [p < 0:001] [p < 0:001] Continent Fixed Effects Yes Yes Country-Level Geography Controls Yes Yes Observations 176 176 R2 0.57 0.68 Robust standard errors are clustered by the most widely spoken language in all specifications; they are reported in parentheses. -

Summer Institute of Linguistics
DOI: 10.7252/Archives.He.0195 Correspondence of Rodger Hedlund: Summer Institute of Linguistics Archives Special Collection: Papers of Roger Hedlund Digital version at http://place.asburyseminary.edu/rogerhedlundpapers/ The copyright of this material belongs to Asbury Theological Seminary’s Archives, B.L. Fisher Library. These items are available for noncommercial and educational uses, such as research, teaching and private study. B.L. Fisher Library has licensed the digital version of this work under the Creative Commons Attribution Noncommercial 3.0 United States License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc/3.0/us/ . For all other uses, contact: B.L. Fisher Library Archives Asbury Theological Seminary 204 N. Lexington Ave. Wilmore, KY 40390 - Box 2270 lVTanill'l, Philippi n '::' 2flfJ I PhOlW: Gfl3· -I776 Callt· !\.( <lre-s: LL"lG II. "rA .•f.\i'\JLA , v ia RC AREA DIREC10R Daniel H. Wea l1c r August 13. 1982 ASSO I Ar~ A REA DI TOR Don Gregson Dr Roger E. Hedlund Church Growth Research Centre Poat Bag 768 Kilpauk. Madras INDIA 600 010 Dear Dr Hedlund. Don Gregson returned from his recent trip which included the INA Confere ce and brought with a copy of your book B the C h and your paper "Uureached Peoples Research s." ve enjoyed reading theee very much and pro.pted~ ask a couple questions. One of the you often aention is (Bihar W. Bengal. M.P., Orissa. etc.). These people are also Kurux Kurukh), and other things as well. We are particularly interested in knowing if there ia an active progra. -

Bibliographie Générale4
Bibliographie générale4 Abbi A. & Gopalakrishnan D., 1992, The explicates compound verb: some definitional issues and criteria for identification, Indian Linguistics 53 : 1-4, p. 28^6. Abbi A., 1992, Reduplication in South Asian languages. An Areal, Typological and Historical Study, New Delhi, Allied Publishers. Abbi A., l994,Semantic Universals in Indian Languages, Simla, Indian Institute of Advanced Study. AbbiDelhi. A. (ed.), Motilal 1996, Banarsidass, The Languages Senes inand Linguistics Tribes of 10. Indigenous Peoples of India, Agesthiafingom S., 1977, A Grammar of Old Tamil with special reference to Patirrupattu (Phonology and verb morphology), Annamalainagar, Annamalai University Press. AgesthialingomAnnamalai Nagar, S. & Annamalai Srinivas Univ.Varma Press. G., 1980, Auxiliaries in Dravidian, Allen N., 1975, Sketch of Thulung grammar, Ithaca, Cornell East Asia Papers 6, Andronoy M. S., 1964? On the Typological Similarity of New bido-Aryan and Dravidian, Indian Linguistics 25, p. 1 19-26. AndronovTamil StudiesM. S., 1976,10, p. The1-12. negative in Dravidian : A comparative study, Journal of Annamalai E., Jerundd H. B. & Rubin J., (eds.), 1986, Language Planning, Mysore, Central Institute for Indian Languages. Anscombre J.-C, 1973, Même le roi de France est sage, Communications 20, p. 40- Apte M. L., 1974, Pidginization of a Lingua Franca : A Linguistic Analysis of Hindi- Urdu spoken m Bombay, in F. C. Southworth & M. L. Apte (eds.), Contact and Convergence in South Asian languages, HDL 1-3, p. 21-41. Arden A. it, 1976. A progressive grammar of the Tamil language, Madras, CLS. Asher RE., 1968, Existential, possessive, locative and copulative sentences in Malayalam, in J.W. M. Verhar (ed), The verb 'Be' and its synonyms, vol.6 (2), Foundations of language supplementary series, Dordrecht, p. -

WILDRE-2 2Nd Workshop on Indian Language Data
WILDRE2 - 2nd Workshop on Indian Language Data: Resources and Evaluation Workshop Programme 27th May 2014 14.00 – 15.15 hrs: Inaugural session 14.00 – 14.10 hrs – Welcome by Workshop Chairs 14.10 – 14.30 hrs – Inaugural Address by Mrs. Swarn Lata, Head, TDIL, Dept of IT, Govt of India 14.30 – 15.15 hrs – Keynote Lecture by Prof. Dr. Dafydd Gibbon, Universität Bielefeld, Germany 15.15 – 16.00 hrs – Paper Session I Chairperson: Zygmunt Vetulani Sobha Lalitha Devi, Vijay Sundar Ram and Pattabhi RK Rao, Anaphora Resolution System for Indian Languages Sobha Lalitha Devi, Sindhuja Gopalan and Lakshmi S, Automatic Identification of Discourse Relations in Indian Languages Srishti Singh and Esha Banerjee, Annotating Bhojpuri Corpus using BIS Scheme 16.00 – 16.30 hrs – Coffee break + Poster Session Chairperson: Kalika Bali Niladri Sekhar Dash, Developing Some Interactive Tools for Web-Based Access of the Digital Bengali Prose Text Corpus Krishna Maya Manger, Divergences in Machine Translation with reference to the Hindi and Nepali language pair András Kornai and Pushpak Bhattacharyya, Indian Subcontinent Language Vitalization Niladri Sekhar Dash, Generation of a Digital Dialect Corpus (DDC): Some Empirical Observations and Theoretical Postulations S Rajendran and Arulmozi Selvaraj, Augmenting Dravidian WordNet with Context Menaka Sankarlingam, Malarkodi C S and Sobha Lalitha Devi, A Deep Study on Causal Relations and its Automatic Identification in Tamil Panchanan Mohanty, Ramesh C. Malik & Bhimasena Bhol, Issues in the Creation of Synsets in Odia: A Report1 Uwe Quasthoff, Ritwik Mitra, Sunny Mitra, Thomas Eckart, Dirk Goldhahn, Pawan Goyal, Animesh Mukherjee, Large Web Corpora of High Quality for Indian Languages i Massimo Moneglia, Susan W. -

The Use of the Copula in Non-Copula Constructions in the Languages of South Asia Anna Sjöberg
UPPSALA UNIVERSITET Masteruppsats, 30 HP Institutionen för lingvistik och filologi VT18 The Use of the Copula in Non-Copula Constructions in the Languages of South Asia Anna Sjöberg Supervisor: Prof. Anju Saxena Abstract In this thesis, I explore the use of copulas in non-copula constructions in the languages of South Asia to establish possible genetic and areal tendencies in the distribution. Using materials – language descriptions and data – from Grierson’s Linguistic Survey of India, I examine the phenomenon in 206 languages from four families (Munda, Dravidian, Indo-Aryan and Sino- Tibetan). It is found that the languages of South Asia appear to be more likely than the world- wide average to use the copula in non-copula constructions and that at least Munda, Dravidian and Indo-Aryan use it in the same way with regards to tense, namely in the past and present but not the future. Finally, I argue that there is some evidence supporting that the use of the copula in non-copula constructions is an areal feature, though more work is needed to make any definitive conclusions. i Contents Abstract ................................................................................................................................... i Contents ................................................................................................................................. ii List of maps .......................................................................................................................... iii List of figures.......................................................................................................................