CLASSIFYING LALO LANGUAGES: SUBGROUPING, PHONETIC DISTANCE, and INTELLIGIBILITY* Cathryn Yang SIL International
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Is Kanakanavu an Ergative Language?
Voice and transitivity in Kanakanavu Dissertation zur Erlangung des akademischen Grades einer Doktorin der Philosophie (Dr. phil.) der Philosophischen Fakultät der Universität Erfurt vorgelegt von Ilka Wild Erfurt, März 2018 Gutachter der Arbeit: Prof. Dr. Christian Lehmann, Universität Erfurt Prof. Dr. Volker Gast, Friedrich-Schiller-Universität Jena Datum der Defensio: 6. August 2018 Universitätsbibliothek Erfurt Electronic Text Center URN:nbn:de:gbv:547-201800530 Abstract This is a dissertation on the Kanakanavu language, i.e. that linguistic phenomena found while working on the language underwent a deeper analysis and linguistic techniques were used to provide data and to present analyses in a structured manner. Various topics of the Kanakanavu language system are exemplified: Starting with a grammar sketch of the language, the domains phonology, morphology, and syntax are described and information on the linguistic features in these domains are given. Beyond a general overview of the situation and a brief description of the language and its speakers, an investigation on a central part of the Kanakanavu language system, namely its voice system, can be found in this work. First, it is analyzed and described by its formal characteristics. Second, the question of the motivation of using the voice system in connection to transitivity and, in the literature less often recognized, the semantic side of transitive constructions, i.e. its effectiveness, is discussed. Investigations on verb classes in Kanakanavu and possible semantic connections are presented as well as investigations on possible situations of different degrees of effectiveness. This enables a more detailed view on the language system and, in particular, its voice system. -

Prayer Cards (709)
Pray for the Nations Pray for the Nations A Che in China A'ou in China Population: 43,000 Population: 2,800 World Popl: 43,000 World Popl: 2,800 Total Countries: 1 Total Countries: 1 People Cluster: Tibeto-Burman, other People Cluster: Tai Main Language: Ache Main Language: Chinese, Mandarin Main Religion: Ethnic Religions Main Religion: Ethnic Religions Status: Unreached Status: Unreached Evangelicals: 0.00% Evangelicals: 0.00% Chr Adherents: 0.00% Chr Adherents: 0.00% Scripture: Translation Needed Scripture: Complete Bible www.joshuaproject.net Source: Operation China, Asia Harvest www.joshuaproject.net Source: Operation China, Asia Harvest "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations A-Hmao in China Achang in China Population: 458,000 Population: 35,000 World Popl: 458,000 World Popl: 74,000 Total Countries: 1 Total Countries: 2 People Cluster: Miao / Hmong People Cluster: Tibeto-Burman, other Main Language: Miao, Large Flowery Main Language: Achang Main Religion: Christianity Main Religion: Ethnic Religions Status: Significantly reached Status: Partially reached Evangelicals: 75.0% Evangelicals: 7.0% Chr Adherents: 80.0% Chr Adherents: 7.0% Scripture: Complete Bible Scripture: Complete Bible www.joshuaproject.net www.joshuaproject.net Source: Anonymous Source: Wikipedia "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations Achang, Husa in China Adi -

SOUTHERN LISU DICTIONARY Qaaaqrc Qbq[D @^J Hell Ebll Ell
STEDT Monograph Series, No. 4 James A. Matisoff, general editor SOUTHERN LISU DICTIONARY QaaaqRc Qbq[d @^j Hell Ebll ell David Bradley with Edward Reginald Hope, James Fish and Maya Bradley Sino-Tibetan Etymological Dictionary and Thesaurus Project Center for Southeast Asia Studies University of California, Berkeley 2006 © 2005 David Bradley All Rights Reserved ISBN 0-944613-43-8 Volume #4 in the STEDT Monograph Series Sino-Tibetan Etymological Dictionary and Thesaurus Project <http://stedt.berkeley.edu/> Department of Linguistics research unit in International and Area Studies University of California, Berkeley Sino-Tibetan Etymological Dictionary and Thesaurus Monograph Series General Editor JAMES A. MATISOFF University of California, Berkeley Previous Titles in the STEDT Monograph Series: STEDT MONOGRAPH NO. 1A: Bibliography of the International Conferences on Sino-Tibetan Languages and Linguistics I-XXV (second edition) STEDT MONOGRAPH NO. 2: Annotated Directory of Tibeto-Burman Languages and Dialects (revised) STEDT MONOGRAPH NO. 3: Phonological Inventories of Tibeto- Burman Languages Author’s Dedication: for my Lisu friends CONTENTS Series Editor’s Introduction vii Introduction xv The Lisu xv Lisu Phonology xviii Lisu Orthographies xxv Lisu Syntax xxviii Acknowledgements xxix References xxxi Hel Bck Ubl (Lisu Introduction) xxxiii List of Abbreviations xxxiv @ b 1 @\ bj 14 A p 17 A\ pj 31 B pæ 33 B\ pæj 42 C d 45 D t 56 E tæ 70 F g 80 G k 87 H kæ 101 I dÔ 112 J tΔ 121 K tΔæ 133 L dz 146 M ts 155 N tsæ 163 O m 173 O\ mj 194 P n 198 -

第四届中国西南地区汉藏语国际研讨会program and Abstract Book
FOURTH WORKSHOP ON SINO-TIBETAN LANGUAGES OF SOUTHWEST CHINA 第四届中国西南地区汉藏语国际研讨会 UNIVERSITY OF WASHINGTON, SEATTLE SEPTEMBER 8-10, 2016 PROGRAM AND ABSTRACT BOOK Table of Contents General Information & Special Thanks to Our Sponsors ......................................................... 3 Program Synoptic Schedule ..................................................................................................................... 4 Thursday, September 8 .............................................................................................................. 5 Friday, September 9 ................................................................................................................... 6 Saturday, September 10 ............................................................................................................. 7 Abstracts (in presentation order) Scott DeLancey, Reconstructing Hierarchical Argument Indexation in Trans-Himalayan .... 8 James A. Matisoff, Lahu in the 21st century: vocabulary enrichment and orthographical issues ........................................................................................................................................ 10 Guillaume Jacques, The life cycle of multiple indexation and bipartite verbs in Sino-Tibetan ................................................................................................................................................. 11 Jackson T.-S. SUN and Qianzi TIAN, Argument Indexation patterns in Horpa languages: a major Rgyalrongic subgroup .................................................................................................. -

A Grammar of Vaeakau-Taumako Mouton Grammar Library 52
A Grammar of Vaeakau-Taumako Mouton Grammar Library 52 Editors Georg Bossong Bernard Comrie Matthew Dryer De Gruyter Mouton A Grammar of Vaeakau-Taumako by 0 Ashild N cess and Even Hovdhaugen De Gruyter Mouton ISBN 978-3-11-023826-6 e-ISBN 978-3-11-023827-3 ISSN 0933-7636 Library of Congress Cataloging-in-Publication Data N <'eSS, Asbild. A grammar of Vaeakau-Taumako I by Asbild N<'tss and Even Hovdhaugen. p. em. - (Mouton grammar library; 52) Includes bibliographical references and index. ISBN 978-3-11-023826-6 (alk. paper) 1. Pileni language. 2. Pileni language - Grammar. 3. Poly- nesian languages. 4. Solomon Islands - Languages. 1. Hovd- haugen, Even. II. Title. PL6488N25 2011 499' .46-dc23 2011017828 Bibliographic information published by the Deutsche Nationalbihliothek The Deutsche Nationalbibliothek lists this publication in the Deutsche Nationalbibliografie; detailed bibliographic data are available in the Internet at http://dnb.d-nb.de. © 2011 Walter de Gruyter GmbH & Co. KG, Berlin/Boston Printing: Hubert & Co. GmbH & Co. KG, G6ttingen w Printed on acid-free paper Printed in Germany www.degruyter.com Preface Although it was not the original plan, it is perhaps fitting that this book has ended up as a collaborative work, We have been working on the V aeakau Taurnako language - back then known as Pileni - since 1997, when Even Hovdhaugen made his first exploratory field trip to Pileni island, On his re turn, he found one of his students in desperate need of a topic for an MA the sis, and so began a collaboration that would last -

The Lawu Languages
The Lawu languages: footprints along the Red River valley corridor Andrew Hsiu ([email protected]) https://sites.google.com/site/msealangs/ Center for Research in Computational Linguistics (CRCL), Bangkok, Thailand Draft published on December 30, 2017; revised on January 8, 2018 Abstract In this paper, Lawu (Yang 2012) and Awu (Lu & Lu 2011) are shown to be two geographically disjunct but related languages in Yunnan, China forming a previously unidentified sub-branch of Loloish (Ngwi). Both languages are located along the southwestern banks of the Red River. Additionally, Lewu, an extinct language in Jingdong County, may be related to Lawu, but this is far from certain due to the limited data. The possible genetic position of the unclassified Alu language in Lüchun County is also discussed, and my preliminary analysis of the highly limited Alu data shows that it is likely not a Lawu language. The Lawu (alternatively Lawoid or Lawoish) branch cannot be classified within any other known branch or subgroup or Loloish, and is tentatively considered to be an independent branch of Loloish. Further research on Lawu languages and surrounding under-documented languages would be highly promising, especially on various unidentified languages of Jinping County, southern Yunnan. Table of contents Abstract 1. Introduction 2. Lawu 3. Awu 4. Lewu Yao: a possible relative of Lawu 5. Alu: a Lalo language rather than a Lawu language 6. Conclusions 7. Final remarks: suggestions for future research References Appendix 1: Comparative word list of Awu, Lawu, and Proto-Lalo Appendix 2: Phrase list of Lewu Yao Appendix 3: Comparative word list of Yi lects of Lüchun County 1 1. -

Languages of Southeast Asia
Jiarong Horpa Zhaba Amdo Tibetan Guiqiong Queyu Horpa Wu Chinese Central Tibetan Khams Tibetan Muya Huizhou Chinese Eastern Xiangxi Miao Yidu LuobaLanguages of Southeast Asia Northern Tujia Bogaer Luoba Ersu Yidu Luoba Tibetan Mandarin Chinese Digaro-Mishmi Northern Pumi Yidu LuobaDarang Deng Namuyi Bogaer Luoba Geman Deng Shixing Hmong Njua Eastern Xiangxi Miao Tibetan Idu-Mishmi Idu-Mishmi Nuosu Tibetan Tshangla Hmong Njua Miju-Mishmi Drung Tawan Monba Wunai Bunu Adi Khamti Southern Pumi Large Flowery Miao Dzongkha Kurtokha Dzalakha Phake Wunai Bunu Ta w an g M o np a Gelao Wunai Bunu Gan Chinese Bumthangkha Lama Nung Wusa Nasu Wunai Bunu Norra Wusa Nasu Xiang Chinese Chug Nung Wunai Bunu Chocangacakha Dakpakha Khamti Min Bei Chinese Nupbikha Lish Kachari Ta se N a ga Naxi Hmong Njua Brokpake Nisi Khamti Nung Large Flowery Miao Nyenkha Chalikha Sartang Lisu Nung Lisu Southern Pumi Kalaktang Monpa Apatani Khamti Ta se N a ga Wusa Nasu Adap Tshangla Nocte Naga Ayi Nung Khengkha Rawang Gongduk Tshangla Sherdukpen Nocte Naga Lisu Large Flowery Miao Northern Dong Khamti Lipo Wusa NasuWhite Miao Nepali Nepali Lhao Vo Deori Luopohe Miao Ge Southern Pumi White Miao Nepali Konyak Naga Nusu Gelao GelaoNorthern Guiyang MiaoLuopohe Miao Bodo Kachari White Miao Khamti Lipo Lipo Northern Qiandong Miao White Miao Gelao Hmong Njua Eastern Qiandong Miao Phom Naga Khamti Zauzou Lipo Large Flowery Miao Ge Northern Rengma Naga Chang Naga Wusa Nasu Wunai Bunu Assamese Southern Guiyang Miao Southern Rengma Naga Khamti Ta i N u a Wusa Nasu Northern Huishui -

A Study from the Perspectives of Shared Innovation
SUBGROUPING OF NISOIC (YI) LANGUAGES: A STUDY FROM THE PERSPECTIVES OF SHARED INNOVATION AND PHYLOGENETIC ESTIMATION by ZIWO QIU-FUYUAN LAMA Presented to the Faculty of the Graduate School of The University of Texas at Arlington in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY THE UNIVERSITY OF TEXAS AT ARLINGTON May 2012 Copyright © by Ziwo Qiu-Fuyuan Lama 2012 All Rights Reserved To my parents: Qiumo Rico and Omu Woniemo Who have always wanted me to stay nearby, but they have also wished me to go my own way! ACKNOWLEDGEMENTS The completion of this dissertation could not have happened without the help of many people; I own much gratitude to these people and I would take this moment to express my heartfelt thanks to them. First, I wish to express my deep thanks to my supervisor, Professor Jerold A Edmondson, whose guidance, encouragement, and support from the beginning to the final page of this dissertation. His direction showed me the pathway of the writing of this dissertation, especially, while working on chapter of phylogenetic study of this dissertation, he pointed out the way to me. Secondly, I would like to thank my other committee members: Dr. Laurel Stvan, Dr. Michael Cahill, and Dr. David Silva. I wish to thank you very much for your contribution to finishing this dissertation. Your comments and encouragement were a great help. Third, I would like to thank my language informants and other people who helped me during my field trip to China in summer 2003, particularly ZHANF Jinzhi, SU Wenliang, PU Caihong, LI Weibing, KE Fu, ZHAO Hongying, ZHOU Decai, SHI Zhengdong, ZI Wenqing, and ZUO Jun. -
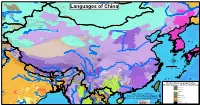
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

Regional Variation in Lalo: Beyond East and West
Regional Variation in Lalo: Beyond East and West Cathryn Yang La Trobe University, Australia SIL International Abstract Lalo, a Burmic, Central Ngwi language spoken in western Yunnan, China, has been classified as having two dialects: East Mountain and West Mountain (Chen et al., 1985). Wang (2003) mentions a few differences between the dialects, but, in general, previous research has left major patterns of variation and the relative degrees of difference unexplored. Fieldwork conducted in 2008, including the collection of wordlists and texts, reveals a linguistic diversity previously unimagined. This paper presents evidence for the subgrouping of three lower-level dialect clusters: Central, Northwestern, and Eastern, from both a diachronic and a synchronic perspective. Diachronically, shared innovations in tone, initials and rhymes are used as criteria for subgrouping. Synchronically, the Levenshtein distance algorithm is applied to quantify aggregate pronunciation differences (Heeringa, 2004), and the results are presented using NeighborNet network mapping and multidimensional scaling. The synchronic, dialectometric results show a high degree of congruence with the diachronic findings for lower-level clusters. East and West Mountain Lalo are found to group together within the Central Lalo cluster. Northwestern, Eastern, and Central Lalo are clear lower-level subgroups, with possible higher-level connections to each other that distinguish them from peripheral Lalo groups that migrated out of the Lalo homeland area. Besides presenting major regional variation patterns in Lalo, this research furthermore reveals that the degree of difference is considerable, a finding with implications for any future Lalo language planning. Keywords: Lalo, Ngwi, Levenshtein distance, dialectology, dialectometry 1. Introduction Lalo is a Burmic, Central Ngwi language cluster spoken in Western Yunnan, China and is closely related to Lolo, Lisu and Lahu. -

Machine-Assisted Phonemic Analysis
Machine-Assisted Phonemic Analysis Timothy Kempton Department of Computer Science February 2012 Dissertation submitted to the University of Sheffield for the degree of Doctor of Philosophy Supervisor: Professor Roger K. Moore Acknowledgements Firstly I would like to thank my supervisor Roger Moore. From the start, Roger was flexible and enthusiastic about my original proposal. I have really appreciated his patience as I slowly devel- oped in the role of a researcher. I’ve particularly benefitted from Roger’s wealth of knowledge of previous speech recognition work, and his depth of insight on the subject. I am also very grateful for being funded by the UK Engineering and Physical Sciences Re- search Council (EPSRC grant number EP/P502748/1) through the University of Sheffield. I have had a lot of assistance from fieldworkers in Southeast Asia. Andy Castro has been particularly helpful in providing the Kua-nsi data, and talking through the phonology of the language. Brian Crook was also on hand later to provide transcriptions and recordings on re- quest. I have also benefited from conversations with Cathryn Yang about fieldwork andfrom receiving her survey data on the Nisu language. Mary Pearce has been tremendously helpful in conversations about field linguistics and phonemic analysis, and I have appreciated her dedication in reading through an earlier draft of the thesis. Cathy Bartram gave me a helpful steer at the start on phonemic analysis heuristics. Juha Yliniemi put me in touch with the above linguists including David Morgan who helped me access the resources at the SIL UK library. I have hugely benefited from the expertise of those on the SIL linguistics discussion list. -

How Typology Allows for a New Analysis of the Verb Phrase in Burmese Alice Vittrant
How typology allows for a new analysis of the verb phrase in Burmese Alice Vittrant To cite this version: Alice Vittrant. How typology allows for a new analysis of the verb phrase in Burmese. LIDIL - Revue de linguistique et de didactique des langues, UGA Editions, 2012, 46, pp.101-126. hal-00779831 HAL Id: hal-00779831 https://hal.archives-ouvertes.fr/hal-00779831 Submitted on 22 Jan 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Lidil n°46 - 2012 How typology allows for a new analysis of verb phrase in Burmese Alice VITTRANT LACITO-CNRS Université d’Aix-Marseille [email protected] Description, classification, diversity and universality of languages are the key terms of linguistic typology, which first aims at answering the following question: what do languages have in common and in what ways do they differ?1 In other words, typology is concerned with finding properties that are shared by languages (invariants in Lazard terms)2, and has to do with cross-linguistic comparison. Its first task is therefore to describe languages in terms of pre-established features, leading to a classification of languages into different structural types according to the affinities that emerge from the descriptions.