Machine-Assisted Phonemic Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Lawu Languages
The Lawu languages: footprints along the Red River valley corridor Andrew Hsiu ([email protected]) https://sites.google.com/site/msealangs/ Center for Research in Computational Linguistics (CRCL), Bangkok, Thailand Draft published on December 30, 2017; revised on January 8, 2018 Abstract In this paper, Lawu (Yang 2012) and Awu (Lu & Lu 2011) are shown to be two geographically disjunct but related languages in Yunnan, China forming a previously unidentified sub-branch of Loloish (Ngwi). Both languages are located along the southwestern banks of the Red River. Additionally, Lewu, an extinct language in Jingdong County, may be related to Lawu, but this is far from certain due to the limited data. The possible genetic position of the unclassified Alu language in Lüchun County is also discussed, and my preliminary analysis of the highly limited Alu data shows that it is likely not a Lawu language. The Lawu (alternatively Lawoid or Lawoish) branch cannot be classified within any other known branch or subgroup or Loloish, and is tentatively considered to be an independent branch of Loloish. Further research on Lawu languages and surrounding under-documented languages would be highly promising, especially on various unidentified languages of Jinping County, southern Yunnan. Table of contents Abstract 1. Introduction 2. Lawu 3. Awu 4. Lewu Yao: a possible relative of Lawu 5. Alu: a Lalo language rather than a Lawu language 6. Conclusions 7. Final remarks: suggestions for future research References Appendix 1: Comparative word list of Awu, Lawu, and Proto-Lalo Appendix 2: Phrase list of Lewu Yao Appendix 3: Comparative word list of Yi lects of Lüchun County 1 1. -

A Study from the Perspectives of Shared Innovation
SUBGROUPING OF NISOIC (YI) LANGUAGES: A STUDY FROM THE PERSPECTIVES OF SHARED INNOVATION AND PHYLOGENETIC ESTIMATION by ZIWO QIU-FUYUAN LAMA Presented to the Faculty of the Graduate School of The University of Texas at Arlington in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY THE UNIVERSITY OF TEXAS AT ARLINGTON May 2012 Copyright © by Ziwo Qiu-Fuyuan Lama 2012 All Rights Reserved To my parents: Qiumo Rico and Omu Woniemo Who have always wanted me to stay nearby, but they have also wished me to go my own way! ACKNOWLEDGEMENTS The completion of this dissertation could not have happened without the help of many people; I own much gratitude to these people and I would take this moment to express my heartfelt thanks to them. First, I wish to express my deep thanks to my supervisor, Professor Jerold A Edmondson, whose guidance, encouragement, and support from the beginning to the final page of this dissertation. His direction showed me the pathway of the writing of this dissertation, especially, while working on chapter of phylogenetic study of this dissertation, he pointed out the way to me. Secondly, I would like to thank my other committee members: Dr. Laurel Stvan, Dr. Michael Cahill, and Dr. David Silva. I wish to thank you very much for your contribution to finishing this dissertation. Your comments and encouragement were a great help. Third, I would like to thank my language informants and other people who helped me during my field trip to China in summer 2003, particularly ZHANF Jinzhi, SU Wenliang, PU Caihong, LI Weibing, KE Fu, ZHAO Hongying, ZHOU Decai, SHI Zhengdong, ZI Wenqing, and ZUO Jun. -
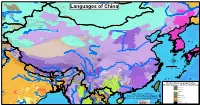
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

Mission Kashmir
Advertise with the Harvard Asia Quarterly Please return this section with your payment in US Dollars, payable to “Harvard Asia Quarterly”. (Please PRINT clearly) Company: _____________________________________ Contact Name:__________________________________ Return this form with your payment to: Address:_______________________________ ______________________________________________ HARVARD ASIA QUARTERLY ______________________________________________ C/O HARVARD ASIA CENTER ______________________________________________ 1737 CAMBRIDGE STREET E-mail: _______________________________________ CAMBRIDGE, MA 02138 Phone: ________________________________________ USA Specifications Please send your advertisement as either: (1) an Adobe PageMaker file; (2) a .jpeg, .gif or .pdf file; (3) a Microsoft Word file For faster processing, please submit your order form and advertisement through email to [email protected] If ordering by email, please send the check to the address above and retain a copy of this form for your records. A copy of the issue(s) for which you purchase an advertisement will be sent to you at the address you list above. Advertisement Options (Please check one) Back Cover ($650) ______ Inside Front Cover ($500) ______ Inside Back Cover ($350) ______ Full Page ($200) ______ Half Page ($150) ______ Quarter Page ($75) ______ Issue Options and Deadlines Fall (November 1, 2003) ______ Ad Price: ______ Winter (January 15, 2004) ______ Number of Issues: ______ Spring (March 15, 2004) ______ Four-Issue Discount: ______ Summer (May 1, 2004) ______ Total Cost: ______ NOTE: We offer a 20% discount for ads placed in four consecutive issues. Harvard Asia Quarterly Summer 2003 1 HAQ CONTENTS HAQ Editorial Staff Editor in Chief Jongsoo Lee Graduate School of Arts and Sciences 4 Patriotism and the Muslim Citizen in Hindi Films Executive Editor Loretta Kim Amit Rai Graduate School of Arts and Sciences Numerous Bollywood films address the trauma of communal violence that has Managing Editor plagued India’s recent history. -
Language Use and Language Attitudes Among Rural Nisu
Language Use and Language Attitudes among Rural Nisu Ken Chan, Bai Bibo, and Yang Liujin SIL International 2008 SIL Electronic Survey Report 2008-017, August 2008 Copyright © Ken Chan, Bai Bibo, and Yang Liujin, and SIL International All rights reserved Contents Abstract 1. Purpose 2. Sampling 3. Method 4. Data 5. Overall results 5.1 The Nisu believe that as an ethnic group they should still speak Nisu. 5.2 The Nisu believe that the younger generation can still speak Nisu. 5.3 The Nisu do not insist that Nisu should only marry Nisu. 5.4 The Nisu predominantly speak Nisu with their spouses, siblings, their parents, and their grandparents. 5.5 A substantial number of Nisu speak the local dialect of Chinese with their children , but the majority of participants use Nisu with their children. 5.6 The use of Nisu among spouses may have slightly declined from the previous generation. 5.7 A majority of Nisu switch to speaking Chinese when they are in the market or when they are with a school teacher. 5.8 A minority of Nisu reported that they will sometimes speak Chinese with Nisu who are not their family members. 6. Geographical differences 6.1 Most Sinicized areas 6.2 Relatively Sinicized areas 6.3 Relatively less Sinicized areas 6.4 Least Sinicized areas 7. Generational differences 7.1 Attitude toward ability of younger Nisu to speak Nisu 7.2 Attitude toward importance of speaking Nisu 7.3 Attitude toward intermarriage with other ethnic groups 7.4 Language use with children 7.5 Language use with parents 7.6 Language use with spouses 7.7 Language use among teachers and children outside of school 7.8 Language use among children at play 7.9 Language use in the fields 7.10 Language use with animals 8. -

CLASSIFYING LALO LANGUAGES: SUBGROUPING, PHONETIC DISTANCE, and INTELLIGIBILITY* Cathryn Yang SIL International
Linguistics of the Tibeto-Burman Area Volume 35.2 — October 2012 CLASSIFYING LALO LANGUAGES: SUBGROUPING, PHONETIC DISTANCE, AND INTELLIGIBILITY* Cathryn Yang SIL International Abstract: Lalo is a Central Ngwi (Loloish) language cluster spoken in western Yunnan, China by fewer than 300,000 speakers. Previously, most Lalo varieties were undocumented, and Lalo was thought to have only two dialects. This paper presents the first rigorous classification of Lalo languages, based on a dialectological study conducted in eighteen Lalo villages, which included the recording of 1,001-item vocabularies, comprehension tests, and sociolinguistic interviews. Synthesizing results from diachronic subgrouping, intelligibility, and phonetic distance measured by Levenshtein distance, this paper argues that the Lalo cluster actually comprises at least seven closely related languages. Phonetic distance correlates strongly with comprehension, and the NeighborNet network based on phonetic distance concurs with the diachronic subgrouping at shallow time depths, providing further validation of the dialectometric techniques. This paper suggests that such techniques are useful in the classification of lesser-known, endangered, indigenous languages, which often have an urgent need for language maintenance efforts. Keywords: Lalo, classification, subgrouping, phonetic distance, intelligibility 1. INTRODUCTION Lalo, spoken in western Yunnan, China, is one of the least studied of the Central Ngwi (Loloish) language clusters, with no documentation of most Lalo varieties until this study. Chen, Bian & Li (1985: 195), in their wide-sweeping survey of many Ngwi languages, claimed that Lalo had only two dialects, without specifying details of how the dialects differed. To address this gap, a dialectological study was conducted from February 2008 to January 2009 in Dali, Baoshan, Lincang, and Pu’er prefectures. -
![Title Attempt to Identify the Origin of Ms. CHI. YI. 26 [Ms. CHI. 80] Of](https://docslib.b-cdn.net/cover/7112/title-attempt-to-identify-the-origin-of-ms-chi-yi-26-ms-chi-80-of-8337112.webp)
Title Attempt to Identify the Origin of Ms. CHI. YI. 26 [Ms. CHI. 80] Of
Attempt to identify the origin of Ms. CHI. YI. 26 [Ms. CHI. Title 80] of Bibliothèque Interuniversitaire des Langues Orientales, Paris Author(s) Iwasa, Kazue Proceedings of the 51st International Conference on Sino- Citation Tibetan Languages and Linguistics (2018) Issue Date 2018-09 URL http://hdl.handle.net/2433/235282 This is a paper for which the prior permission is required from Right the author(s) to cite. Type Conference Paper Textversion author Kyoto University Attempt to identify the origin of Ms. CHI. YI. 26 [Ms. CHI. 80] of Bibliothèque Interuniversitaire des Langues Orientales, Paris Visiting scholar of Kobe City University of Foreign Studies Kazue IWASA 0. Introduction 0.1 Basic information of Ms. CHI. YI. 26 [Ms. CHI. 80] of BIULO* • One of the Yi manuscripts preserved in *Bibliothèque Interuniversitare des Langues Orientales (BIULO), in Paris. • Yi-Chinese bilingual manuscript, which is hardly found both inside and outside China except Huayi-Yiyu • This is not only partially translated in Chinese but also transcribed by Chinese characters. 0.2 Main findings in Iwasa (2008)* • The Yi language written in this manuscript: Nisu () , the Southern dialect according to the official classification in China, although in the inventory it was classified as Yi de l’est, namely the Eastern Yi, Nasu. • The content: an allegory of a vicious woman called Mrs Xian-Zheng. • The style: a pentasyllabic poetry style. • Several differences from other Nisu manuscripts: more Chinese-like punctuation () and calligraphic handwriting than other Nisu manuscripts. 0.3 Summary of this presentation • This presentation will show you a very possible origin of this gripping bilingual manuscript and several assumptive phonetic values of the Yi characters: • by comparing the shape and pronunciation of the Yi characters of this manuscript with those from the data of my field work and Yi character maps. -

Phonology of Deori: an ‘Endangered’ Language
Phonology of Deori: an ‘endangered’ language DISSERTATION Submitted in Partial Fulfilment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY in LINGUISTICS BY PRARTHANA ACHARYYA DEPARTMENT OF HUMANITIES AND SOCIAL SCIENCES INDIAN INSTITUTE OF TECHNOLOGY GUWAHATI GUWAHATI, ASSAM - 781039 2019 TH-2450_136141007 DECLARATION This is to certify that the dissertation entitled “Phonology of Deori: an ‘endangered’ language”, submitted by me to the Indian Institute of Technology Guwahati, for the award of the degree of Doctor of Philosophy in Linguistics, is an authentic work carried out by me under the supervision of Dr. Shakuntala Mahanta. The content of this dissertation, in full or in parts, have not been submitted to any other University or Institute for the award of any degree or diploma. Signature: Prarthana Acharyya Research Scholar Department of Humanities and Social Sciences Indian Institute of Technology Guwahati Guwahati - 781039, Assam, India. October, 2019 TH-2450_136141007 CERTIFICATE This is to certify that the dissertation entitled “Phonology of Deori: an ‘endangered’ language” submitted by Ms. Prarthana Acharyya (Registration Number: 136141007), a research scholar in the Department of Humanities and Social Sciences, Indian Institute of Technology Guwahati, for the award of the degree of Doctor of Philosophy in Linguistics, is a record of an original research work carried out by her under my supervision and guidance. The dissertation has fulfilled all requirements as per the regulations of the institute and in my opinion, has reached the standard needed for submission. The results in this thesis have not been submitted to any other University or Institute for the award of any degree or diploma. -

Operation China
Nisu, Jianshui September 7 Location: Approximately in southern Yunnan for many soon he is able to break his 370,000 Jianshui Nisu centuries. Only during the feet through the cuffs and GUIZHOU people are located in past century have a small put the pants on.”3 •Kunming southern Yunnan Province, number of Jianshui Nisu •Mile YUNNAN •Huaning GUANGXI • • primarily in Shiping, been assimilated by Han Religion: The Jianshui Nisu Qiubei Guangnan •Kaiyuan Jianshui, Gejiu, and Mengzi Chinese who have settled in worship numerous spirits, Jinping •Pingbian 2 Scale • counties in Honghe the area. some of whom are 0 KM 160 VIETNAM Prefecture. About 13,000 considered benevolent and Population in China: live in Tonghai and Eshan Customs: Women of this others evil. 361,000 (1999) counties of Yuxi Prefecture. group living in Jianshui and 370,200 (2000) Shiping counties wear three Christianity: The first 464,600 (2010) Location: Yunnan Identity: The Jianshui Nisu tightly wound stripes of red missionaries in Jianshui Religion: Polytheism are part of the Yi nationality yarn in their hair, often arrived in 1933 and stayed Christians: 400 in China. Chinese records partially covered by a red or for two years. In 1945 a invariably mention two white headdress. In Shiping Presbyterian work began in Overview of the designations of Nisu in this County, “the family of the Jianshui and was joined by Jianshui Nisu part of the country: Hua Yao bride is to make a new two Italian missionaries. By (Flowery Belt) and San Dao costume to present to the 1950 there were a reported Countries: China Hong (Three Stripes of Red). -

Languages and Dialects of Tibeto-Burman
STEDT Monograph Series, No. 2 James A. Matisoff, General Editor LANGUAGES AND DIALECTS OF TIBETO-BURMAN James A. Matisoff with Stephen P. Baron John B. Lowe Sino-Tibetan Etymological Dictionary and Thesaurus Center for Southeast Asia Studies University of California, Berkeley Cover: Tangut and Tibetan manuscripts from Khara-Khoto from Sir Aurel Stein’s Innermost Asia; a detailed report of explorations in ISBN 0-944613-26-8 Central Asia, Kan-su and eastern Iran. New Delhi : Cosmo, 1981. STEDT Monograph Series, No. 2 LANGUAGES AND DIALECTS OF TIBETO-BURMAN Sino-Tibetan Etymological Dictionary and Thesaurus Monograph Series General Editor James A. Matisoff University of California, Berkeley STEDT Monograph 1: Bibliography of the International Conferences on Sino-Tibetan Languages and Linguistics I-XXI (1989) Randy J. LaPolla and John B. Lowe with Amy Dolcourt lix, 292 pages out of print STEDT Monograph 1A: Bibliography of the International Conferences on Sino-Tibetan Languages and Linguistics I-XXV (1994) Randy J. LaPolla and John B. Lowe lxiv, 308 pages $32.00 + shipping and handling STEDT Monograph 2: Languages and Dialects of Tibeto-Burman (1996) James A. Matisoff with Stephen P. Baron and John B. Lowe xxx, 180 pages $20.00 + shipping and handling STEDT Monograph 3: Phonological Inventories of Tibeto-Burman Languages (1996) Ju Namkung, editor xxviii, 507 pages $35.00 + shipping and handling Shipping and Handling: Domestic: $4.00 for first volume + $2.00 for each additional volume International: $6.00 for first volume + $2.50 for each additional volume Orders must be prepaid. Please make checks payable to ‘UC Regents’. Visa and Mastercard accepted. -

Some Principles on the Use of Macro-Areas in Typological Comparison
Language Dynamics and Change 4 (2014) 167–187 brill.com/ldc Some Principles on the Use of Macro-Areas in Typological Comparison Harald Hammarström Max Planck Institute for Psycholinguistics & Centre for Language Studies, Radboud Universiteit Nijmegen, The Netherlands [email protected] Mark Donohue Department of Linguistics, Australian National University, Australia [email protected] Abstract While the notion of the ‘area’ or ‘Sprachbund’ has a long history in linguistics, with geographically-defined regions frequently cited as a useful means to explain typolog- ical distributions, the problem of delimiting areas has not been well addressed. Lists of general-purpose, largely independent ‘macro-areas’ (typically continent size) have been proposed as a step to rule out contact as an explanation for various large-scale linguistic phenomena. This squib points out some problems in some of the currently widely-used predetermined areas, those found in the World Atlas of Language Struc- tures (Haspelmath et al., 2005). Instead, we propose a principled division of the world’s landmasses into six macro-areas that arguably have better geographical independence properties. Keywords areality – macro-areas – typology – linguistic area 1 Areas and Areality The investigation of language according to area has a long tradition (dating to at least as early as Hervás y Panduro, 1971 [1799], who draws few historical © koninklijke brill nv, leiden, 2014 | doi: 10.1163/22105832-00401001 168 hammarström and donohue conclusions, or Kopitar, 1829, who is more interested in historical inference), and is increasingly seen as just as relevant for understanding a language’s history as the investigation of its line of descent, as revealed through the application of the comparative method.