The Construction of a Chinese Collocational Knowledge Resource and Its Application for Second Language Acquisition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Noun Group and Verb Group Identification for Hindi
Noun Group and Verb Group Identification for Hindi Smriti Singh1, Om P. Damani2, Vaijayanthi M. Sarma2 (1) Insideview Technologies (India) Pvt. Ltd., Hyderabad (2) Indian Institute of Technology Bombay, Mumbai, India [email protected], [email protected], [email protected] ABSTRACT We present algorithms for identifying Hindi Noun Groups and Verb Groups in a given text by using morphotactical constraints and sequencing that apply to the constituents of these groups. We provide a detailed repertoire of the grammatical categories and their markers and an account of their arrangement. The main motivation behind this work on word group identification is to improve the Hindi POS Tagger’s performance by including strictly contextual rules. Our experiments show that the introduction of group identification rules results in improved accuracy of the tagger and in the resolution of several POS ambiguities. The analysis and implementation methods discussed here can be applied straightforwardly to other Indian languages. The linguistic features exploited here are drawn from a range of well-understood grammatical features and are not peculiar to Hindi alone. KEYWORDS : POS tagging, chunking, noun group, verb group. Proceedings of COLING 2012: Technical Papers, pages 2491–2506, COLING 2012, Mumbai, December 2012. 2491 1 Introduction Chunking (local word grouping) is often employed to reduce the computational effort at the level of parsing by assigning partial structure to a sentence. A typical chunk, as defined by Abney (1994:257) consists of a single content word surrounded by a constellation of function words, matching a fixed template. Chunks, in computational terms are considered the truncated versions of typical phrase-structure grammar phrases that do not include arguments or adjuncts (Grover and Tobin 2006). -

“Sorry We Apologize So Much”
Intercultural Communication Studies VIII-1 1998-9 Chu-hsia Wu [Special phonetic symbols do not appear in the online version] Linguistic Analysis of Chinese Verb Compounds and Measure Words to Cultural Values Chu-hsia Wu National Cheng Kung University, Taiwan Abstract Languages derived from different families show different morphological and syntactic structures, therefore, reflect different flavors in the sense of meaning. Inflections and derivatives do more work in Western languages than is asked of them in Chinese. However, the formation of verb compounds allows Chinese to attain the enlargement of lexicon. On the contrary, measure words do more work in Chinese but there is no exact equivalent of Chinese measure words in English. In this study, the Chinese verb compounds such as verb-object compound, cause-result compound, synonymous, and reduplication to cultural values will be discussed first. Measure Words to Cultural Symbolism will be rendered next from two aspects, pictorial symbolism and the characteristics to distinguish noun homophones. Introduction Languages derived from different families show different morphological and syntactic structures, therefore, reflect different flavors in the sense of meaning. Inflections and derivatives do more work in Western languages than is asked of them in Chinese. However, the formation of verb compounds allows Chinese to attain the enlargement of lexicon. On the contrary, measure words do more work in Chinese but there is no exact equivalent of Chinese measure words in English. Therefore, the purpose of this paper will be focused on the formation of verb compounds and the use of measure words relating to their corresponding meanings in Chinese respectively. -

ASIAN Athletics 2 0 1 7 R a N K I N G S
ASIAN athletics 2 0 1 7 R a n k i n g s compiled by: Heinrich Hubbeling - ASIAN AA Statistician – C o n t e n t s Page 1 Table of Contents/Abbreviations for countries 2 - 3 Introduction/Details 4 - 9 Asian Continental Records 10 - 60 2017 Rankings – Men events 60 Name changes (to Women´s Rankings) 61 - 108 2017 Rankings – Women events 109 – 111 Asian athletes in 2017 World lists 112 Additions/Corrections to 2016 Rankings 113 - 114 Contacts for other publications etc. ============================================================== Abbreviations for countries (as used in this booklet) AFG - Afghanistan KGZ - Kyrghizstan PLE - Palestine BAN - Bangladesh KOR - Korea (South) PRK - D P R Korea BHU - Bhutan KSA - Saudi Arabia QAT - Qatar BRN - Bahrain KUW - Kuwait SGP - Singapore BRU - Brunei LAO - Laos SRI - Sri Lanka CAM - Cambodia LBN - Lebanon SYR - Syria CHN - China MAC - Macau THA - Thailand HKG - Hongkong MAS - Malaysia TJK - Tajikistan INA - Indonesia MDV - Maldives TKM - Turkmenistan IND - India MGL - Mongolia TLS - East Timor IRI - Iran MYA - Myanmar TPE - Chinese Taipei IRQ - Iraq NEP - Nepal UAE - United Arab E. JOR - Jordan OMA - Oman UZB - Uzbekistan JPN - Japan PAK - Pakistan VIE - Vietnam KAZ - Kazakhstan PHI - Philippines YEM - Yemen ============================================================== Cover Photo: MUTAZ ESSA BARSHIM -World Athlet of the Year 2017 -World Champion 2017 -World 2017 leader with 2.40 m (achieved twice) -undefeated during the 2017 season 1 I n t r o d u c t i o n With this booklet I present my 29th consecutive edition of Asian athletics statistics. As in the previous years I am very grateful to the ASIAN ATHLETICS ASSOCIATION and its secretary and treasurer, Mr Maurice Nicholas as well as to Mrs Regina Long; without their support I would not have been able to realise this project. -

Tagging Guidelines for BOLT Chinese-English Word Alignment
Tagging Guidelines for BOLT Chinese-English Word Alignment Version 2.0 – 4/10/2014 Linguistic Data Consortium Created by: Xuansong Li, [email protected] With contributions from: Niyu Ge, [email protected] Stephanie Strassel, [email protected] BOLT_TaggingWA_V2.0 Tagging Guidelines for BOLT Chinese-English Word Alignment Page 1 of 24 Version 2.0 –4/10/2014 Table of Content 1 Introduction .................................................................................................... 3 2 Types of links ................................................................................................. 3 2.1 Semantic links ........................................................................................ 4 2.2 Function links .......................................................................................... 4 2.3 DE-clause links ....................................................................................... 5 2.4 DE-modifier links .................................................................................... 6 2.5 DE-possessive links ............................................................................... 6 2.6 Grammatical inference semantic links .................................................... 6 2.7 Grammatical inference function links ...................................................... 7 2.8 Contextual inference link ........................................................................ 7 3 Types of tags ................................................................................................ -

Chinese: Parts of Speech
Chinese: Parts of Speech Candice Chi-Hang Cheung 1. Introduction Whether Chinese has the same parts of speech (or categories) as the Indo-European languages has been the subject of much debate. In particular, while it is generally recognized that Chinese makes a distinction between nouns and verbs, scholars’ opinions differ on the rest of the categories (see Chao 1968, Li and Thompson 1981, Zhu 1982, Xing and Ma 1992, inter alia). These differences in opinion are due partly to the scholars’ different theoretical backgrounds and partly to the use of different terminological conventions. As a result, scholars use different criteria for classifying words and different terminological conventions for labeling the categories. To address the question of whether Chinese possesses the same categories as the Indo-European languages, I will make reference to the familiar categories of the Indo-European languages whenever possible. In this chapter, I offer a comprehensive survey of the major categories in Chinese, aiming to establish the set of categories that are found both in Chinese and in the Indo-European languages, and those that are found only in Chinese. In particular, I examine the characteristic features of the major categories in Chinese and discuss in what ways they are similar to and different from the major categories in the Indo-European languages. Furthermore, I review the factors that contribute to the long-standing debate over the categorial status of adjectives, prepositions and localizers in Chinese. 2. Categories found both in Chinese and in the Indo-European languages This section introduces the categories that are found both in Chinese and in the Indo-European languages: nouns, verbs, adjectives, adverbs, prepositions and conjunctions. -

Classifiers Determiners Yicheng Wu Adams Bodomo
REMARKS AND REPLIES 487 Classifiers ϶ Determiners Yicheng Wu Adams Bodomo Cheng and Sybesma (1999, 2005) argue that classifiers in Chinese are equivalent to a definite article. We argue against this position on empirical grounds, drawing attention to the fact that semantically, syntactically, and functionally, Chinese classifiers are not on the same footing as definite determiners. We also show that compared with Cheng and Sybesma’s ClP analysis of Chinese NPs (in particular, Cantonese NPs, on which their proposal crucially relies), a consistent DP analysis is not only fully justified but strongly supported. Keywords: classifiers, open class, definite determiners, closed class, Mandarin, Cantonese 1 Introduction While it is often proposed that the category DP exists not only in languages with determiners such as English but also in languages without determiners such as Chinese (see, e.g., Pan 1990, Tang 1990a,b, Li 1998, 1999, Cheng and Sybesma 1999, 2005, Simpson 2001, 2005, Simpson and Wu 2002, Wu 2004), there seems to be no consensus about which element (if any) in Chinese is the possible counterpart of a definite determiner like the in English. In their influential 1999 article with special reference to Mandarin and Cantonese, Cheng and Sybesma (hereafter C&S) declare that ‘‘both languages have the equivalent of a definite article, namely, classifiers’’ (p. 522).1 Their treatment of Chinese classifiers as the counterpart of definite determiners is based on the following arguments: (a) both can serve the individualizing/singularizing function; (b) both can serve the deictic function. These arguments and the conclusion drawn from them have been incorporated into C&S 2005, C&S’s latest work on the classifier system in Chinese. -

Imaginary Conversations Curated by Gayatri Sinha and Gao Minglu
Window in the Wall: India and China – Imaginary Conversations Curated by Gayatri Sinha and Gao Minglu Featuring works by Indian artists Abir Karmakar, Gigi Scaria, Lavanya Mani, Manjunath Kamath, Mithu Sen, Ranbir Kaleka, Sharmila Samant, T. Venkanna And by Chinese artists Cui Xiuwen, Ge Zhen, Hu Zhiying, Li Zhanyang, Ma Yuan, Su Xinping, Tan Xun Exhibition Dates 9th September – 9th November, 2011 Opening Celebration Party on Thursday, 8th September, 2011, 5-8 pm Pearl Lam Fine Art, No. 181 Middle Jiangxi Road, Shanghai, China 200002 Works will also be shown at our additional Project Space, No. 500 S.Ruijin Road, by appointment only Shanghai—Pearl Lam Fine Art is delighted to present Window in the Wall: India and China - Imaginary Conversations, an exhibition curated by Gayatri Sinha, an art critic and curator based in New Delhi, India, and Professor Gao Minglu, a curator, critic and professor at the University of Pittsburgh, USA. This exhibition is a unique combination of photography, video, sculpture and painting from fifteen contemporary Indian and Chinese artists. China and India are the world’s two most populous nations with the fastest growing economies. Both countries are on the cusp of a changing global order, which puts them at the centre of world scrutiny. As a consequence of their rise in prominence, Indian and Chinese art are playing a more significant role in the international art market with some Indian and Chinese artists attracting a global following. Relations between China and India date back to ancient times. Both cultures reflect a humanist and artistic exchange. Today through diplomatic and economic ties spurred by their respective growth, they have successfully entered into mutually beneficial dialogue. -
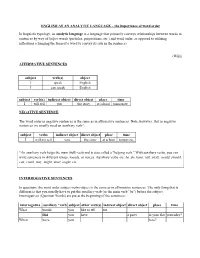
ENGLISH AS an ANALYTIC LANGUAGE – the Importance of Word Order
ENGLISH AS AN ANALYTIC LANGUAGE – the importance of word order In linguistic typology, an analytic language is a language that primarily conveys relationships between words in sentences by way of helper words (particles, prepositions, etc.) and word order, as opposed to utilizing inflections (changing the form of a word to convey its role in the sentence) (Wiki) AFFIRMATIVE SENTENCES subject verb(s) object I speak English I can speak English subject verb(s) indirect object direct object place time I will tell you the story at school tomorrow. NEGATIVE SENTENCE The word order in negative sentences is the same as in affirmative sentences. Note, however, that in negative sentences we usually need an auxiliary verb*: subject verbs indirect object direct object place time I will not tell you the story at school tomorrow. *An auxiliary verb helps the main (full) verb and is also called a "helping verb." With auxiliary verbs, you can write sentences in different tenses, moods, or voices. Auxiliary verbs are: be, do, have, will, shall, would, should, can, could, may, might, must, ought, etc. INTERROGATIVE SENTENCES In questions, the word order subject-verbs-object is the same as in affirmative sentences. The only thing that is different is that you usually have to put the auxiliary verb (or the main verb “be”) before the subject. Interrogatives (Question Words) are put at the beginning of the sentences: interrogative auxiliary *verb subject other verb(s) indirect object direct object place time What would you like to tell me Did you have a party in your flat yesterday? When were you here? Question Words in English The most common question words in English are the following: WHO is only used when referring to people. -

To Ba Or Not to Ba Differential Object Marking in Chinese
î To ba or not to ba Differential Object Marking in Chinese Geertje van Bergen I To ba or not to ba Differential Object Marking in Chinese Geertje van Bergen PIONIER Project Case Cross-linguistically Department of Linguistics Radboud University Nijmegen P.O. Box 9103 6500 HD Nijmegen the Netherlands www.ru.nl/pionier [email protected] III To ba or not to ba Differential Object Marking in Chinese Master’s Thesis General Linguistics Faculty of Arts Radboud University Nijmegen November 2006 Geertje van Bergen 0136433 First supervisor: Dr. Helen de Hoop Second supervisor: Prof. Dr. Pieter Muysken V Acknowledgements I would like to thank Lotte Hogeweg and the members of the PIONIER-project Case Cross-linguistically for the nice cooperation during the past year; many thanks go to Monique Lamers for the pleasant teamwork. I am especially grateful to Yangning for the close cooperation in Beijing and Nijmegen, which has laid the foundation of ¡ £¢ this thesis. Many thanks also go to Sander Lestrade for clarifying conversations over countless cups of coffee. I would like to thank Pieter Muysken for his willingness to be my second supervisor and for his useful comments on an earlier version. Also, I gratefully acknowledge the Netherlands Organisation of Scientific Research (NWO) for financial support, grant 220-70-003, principal investigator Helen de Hoop (PIONIER-project ‘Case cross-linguistically’). Especially, I would like to thank Helen de Hoop for her great support and supervision, for keeping me from losing courage and keeping me on schedule, for her indispensable comments and for all the opportunities she offered me to develop my research skills. -

Variation in the Ergative Pattern of Kurmanji Songül Gündoğdu, Muş
Variation in the Ergative Pattern of Kurmanji Songül Gündoğdu, Muş Alparslan University, Muş, Turkey LANGUAGE KEYWORDS: Northern Kurdish (Kurmanji) AREA KEYWORDS: Middle East (Turkey) ABSTRACT (ENGLISH) Kurdish-Kurmanji (or Northern Kurdish) belongs to the Iranian branch of the Indo-European language family. This study is dedicated to a deeper understanding of a specific grammatical feature typical of Kurmanji: the ergative structure. Based on the example of this core structure, and with empirical evidence from the Kurmanji dialect of Muş in Turkey, I will discuss the issues of variation and change in Kurmanji, more precisely the ongoing shift from ergative to nominative-accusative structures. The causes for such a fundamental shift, however, are not easy to define. The close historical vicinity to Turkish and Armenian might be a trigger for the shift; another trigger is language-internal (diachronic) change. In sum, the investigated variation sheds light on a fascinating grammatical change in a language that is also sociopolitically in a situation of constant change, movement, and upheaval. ABSTRACT (DEUTSCH) Kurdisch-Kurmanci (oder Nordkurdisch) gehört zum iranischen Zweig der indoeuropäischen Sprachfamilie. Eine zentrale und charakteristische grammatische Struktur dieser Sprache ist der Ergativ; ihm ist der vorliegende Beitrag gewidmet. Am Beispiel des Ergativ werde ich Variation und Wandel im Kurmanci diskutieren und insbesondere auf den Dialekt von Muş (Türkei) eingehen. Dabei zeigt sich, dass sich derzeit im Kurmanci der Wandel von einer Ergativ- zu einer Nominativ-Akkusativ-Sprache vollzieht. Die Ursachen für einen derart grundlegenden Wandel sind nicht leicht zu benennen. Ein Grund mag in der schon historisch engen Nachbarschaft zum Türkischen und Armenischen liegen; ein anderer Grund mag im sprach-internen (diachronen) Wandel des Kurmanci selbst zu finden sein. -
Analytic and Cognitive Language in Instagram Captions
ISSN 2474-8927 SOCIAL BEHAVIOR RESEARCH AND PRACTICE Open Journal Brief Research Report What Were They Thinking? Analytic and Cognitive Language in Instagram Captions Sheila Brownlow, PhD1*; Makenna Pate, BA2; Abigail Alger, BA [Student]2; Natalie Naturile, BA2 1Department of Psychology, Catawba College, Salisbury NC 28144, USA *Corresponding author Sheila Brownlow, PhD Professor and Chair, Department of Psychology, Catawba College, Salisbury NC 28144, USA; E-mail: [email protected] Article Information Received: June 15th, 2019; Revised: July 8th, 2019; Accepted: July 15th, 2019; Published: July 16th, 2019 Cite this article Brownlow S, Pate M, Alger A, Naturile N. What were they thinking? Analytic and cognitive language in Instagram captions. Soc Behav Res Pract Open J. 2019; 4(1): 21-25. doi: 10.17140/SBRPOJ-4-117 ABSTRACT Background We examined content and expression of Instagram captions of major celebrities who differed according to sex and status, with a focus on determining whether these variables influenced the use of analytic language and cognitive content. Method Instagram captions (n=942) were analyzed with the linguistic inquiry and word count (LIWC), which delineated percentage of language reflecting analytical thought and various cognitive mechanisms, such as causality and discrepancy. Results Men and low-status persons used more functional analytic language, demonstrating critical thought; in contrast, high-status celeb- rities showed more causality. Women more than men “qualified” their speech with discrepancy. These findings were not a function of sentence length. Conclusion Status increased the tendency to construct and explain, perhaps because higher status celebrities (particularly women) knew that they could hold followers’ attention with complex content. -

Hybridity Versus Revivability
40 Hybridity versus revivability HYBRIDITY VERSUS REVIVABILITY: MULTIPLE CAUSATION, FORMS AND PATTERNS Ghil‘ad Zuckermann Abstract The aim of this article is to suggest that due to the ubiquitous multiple causation, the revival of a no-longer spoken language is unlikely without cross-fertilization from the revivalists’ mother tongue(s). Thus, one should expect revival efforts to result in a language with a hybridic genetic and typological character. The article highlights salient morphological constructions and categories, illustrating the difficulty in determining a single source for the grammar of Israeli, somewhat misleadingly a.k.a. ‘Modern Hebrew’. The European impact in these features is apparent inter alia in structure, semantics or productivity. Multiple causation is manifested in the Congruence Principle, according to which if a feature exists in more than one contributing language, it is more likely to persist in the emerging language. Consequently, the reality of linguistic genesis is far more complex than a simple family tree system allows. ‘Revived’ languages are unlikely to have a single parent. The multisourced nature of Israeli and the role of the Congruence Principle in its genesis have implications for historical linguistics, language planning and the study of language, culture and identity. “Linguistic and social factors are closely interrelated in the development of language change. Explanations which are confined to one or the other aspect, no matter how well constructed, will fail to account for the rich body of