Modeling Infant Segmentation of Two Morphologically Diverse Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Syntactic and Semantic Relationship in Synthetic Languages
This is the published version of the bachelor thesis: Navarro Caparrós, Raquel; van Wijk Adan, Malou, dir. The Syntactic and Semantic Relationship in Synthetic Languagues : Linear Modification in Latin and Old English. 2016. 41 pag. (838 Grau en Estudis d’Anglès i de Clàssiques) This version is available at https://ddd.uab.cat/record/164293 under the terms of the license The Syntactic and Semantic Relationship in Synthetic Languages: Linear Modification in Latin and Old English TFG – Grau d’Estudis d’Anglès i Clàssiques Supervisor: Malou van Wijk Adan Raquel Navarro Caparrós June 2016 ACKNOWLEDGMENTS First and foremost, I would like to express my gratitude to my supervisor Ms. Malou van Wijk Adan for her assistance and patience during the period of my research. This project would not have been possible without her guidance and valuable comments throughout. I would also like to thank all my teachers of Classical Studies and English Studies for sharing their knowledge with me throughout these four years. Finally, I wish to acknowledge my mum and my sister Ruth whose invaluable support helped me to overcome any obstacle, especially in the last two years. Without them, I am sure that I would have never been able to get where I am now. TABLE OF CONTENTS List of Abbreviations ...................................................................................................... ii List of Tables .................................................................................................................. iii Abstract .......................................................................................................................... -

II Levels of Language
II Levels of language 1 Phonetics and phonology 1.1 Characterising articulations 1.1.1 Consonants 1.1.2 Vowels 1.2 Phonotactics 1.3 Syllable structure 1.4 Prosody 1.5 Writing and sound 2 Morphology 2.1 Word, morpheme and allomorph 2.1.1 Various types of morphemes 2.2 Word classes 2.3 Inflectional morphology 2.3.1 Other types of inflection 2.3.2 Status of inflectional morphology 2.4 Derivational morphology 2.4.1 Types of word formation 2.4.2 Further issues in word formation 2.4.3 The mixed lexicon 2.4.4 Phonological processes in word formation 3 Lexicology 3.1 Awareness of the lexicon 3.2 Terms and distinctions 3.3 Word fields 3.4 Lexicological processes in English 3.5 Questions of style 4 Syntax 4.1 The nature of linguistic theory 4.2 Why analyse sentence structure? 4.2.1 Acquisition of syntax 4.2.2 Sentence production 4.3 The structure of clauses and sentences 4.3.1 Form and function 4.3.2 Arguments and complements 4.3.3 Thematic roles in sentences 4.3.4 Traces 4.3.5 Empty categories 4.3.6 Similarities in patterning Raymond Hickey Levels of language Page 2 of 115 4.4 Sentence analysis 4.4.1 Phrase structure grammar 4.4.2 The concept of ‘generation’ 4.4.3 Surface ambiguity 4.4.4 Impossible sentences 4.5 The study of syntax 4.5.1 The early model of generative grammar 4.5.2 The standard theory 4.5.3 EST and REST 4.5.4 X-bar theory 4.5.5 Government and binding theory 4.5.6 Universal grammar 4.5.7 Modular organisation of language 4.5.8 The minimalist program 5 Semantics 5.1 The meaning of ‘meaning’ 5.1.1 Presupposition and entailment 5.2 -

Grammatical Analyticity Versus Syntheticity in Varieties of English
Language Variation and Change, 00 (2009), 1–35. © Cambridge University Press, 2009 0954-3945/09 $16.00 doi:10.1017/S0954394509990123 1 2 3 4 Typological parameters of intralingual variability: 5 Grammatical analyticity versus syntheticity in varieties 6 7 of English 8 B ENEDIKT S ZMRECSANYI 9 Freiburg Institute for Advanced Studies 10 11 12 ABSTRACT 13 Drawing on terminology, concepts, and ideas developed in quantitative morphological 14 typology, the present study takes an exclusive interest in the coding of grammatical 15 information. It offers a sweeping overview of intralingual variability in terms of 16 overt grammatical analyticity (the text frequency of free grammatical markers), 17 grammatical syntheticity (the text frequency of bound grammatical markers), and 18 grammaticity (the text frequency of grammatical markers, bound or free) in English. 19 The variational dimensions investigated include geography, text types, and real time. 20 Empirically, the study taps into a number of publicly accessible text corpora that 21 comprise a large number of different varieties of English. Results are interpreted in 22 terms of how speakers and writers seek to achieve communicative goals while 23 minimizing different types of complexity. 24 25 This study surveys language-internal variability and short-term diachronic change, 26 along dimensions that are familiar from the cross-linguistic typology of languages. 27 The terms analytic and synthetic have a long and venerable tradition in linguistics, 28 going back to the 19th century and August Wilhelm von Schlegel, who is usually 29 credited for coining the opposition (Schlegel, 1818). This is, alas, not the place to 30 even attempt to review the rich history of thought in this area (but see Schwegler, “ 31 1990:chapter 1 for an excellent overview). -
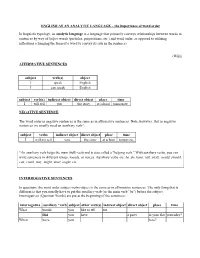
ENGLISH AS an ANALYTIC LANGUAGE – the Importance of Word Order
ENGLISH AS AN ANALYTIC LANGUAGE – the importance of word order In linguistic typology, an analytic language is a language that primarily conveys relationships between words in sentences by way of helper words (particles, prepositions, etc.) and word order, as opposed to utilizing inflections (changing the form of a word to convey its role in the sentence) (Wiki) AFFIRMATIVE SENTENCES subject verb(s) object I speak English I can speak English subject verb(s) indirect object direct object place time I will tell you the story at school tomorrow. NEGATIVE SENTENCE The word order in negative sentences is the same as in affirmative sentences. Note, however, that in negative sentences we usually need an auxiliary verb*: subject verbs indirect object direct object place time I will not tell you the story at school tomorrow. *An auxiliary verb helps the main (full) verb and is also called a "helping verb." With auxiliary verbs, you can write sentences in different tenses, moods, or voices. Auxiliary verbs are: be, do, have, will, shall, would, should, can, could, may, might, must, ought, etc. INTERROGATIVE SENTENCES In questions, the word order subject-verbs-object is the same as in affirmative sentences. The only thing that is different is that you usually have to put the auxiliary verb (or the main verb “be”) before the subject. Interrogatives (Question Words) are put at the beginning of the sentences: interrogative auxiliary *verb subject other verb(s) indirect object direct object place time What would you like to tell me Did you have a party in your flat yesterday? When were you here? Question Words in English The most common question words in English are the following: WHO is only used when referring to people. -

To Ba Or Not to Ba Differential Object Marking in Chinese
î To ba or not to ba Differential Object Marking in Chinese Geertje van Bergen I To ba or not to ba Differential Object Marking in Chinese Geertje van Bergen PIONIER Project Case Cross-linguistically Department of Linguistics Radboud University Nijmegen P.O. Box 9103 6500 HD Nijmegen the Netherlands www.ru.nl/pionier [email protected] III To ba or not to ba Differential Object Marking in Chinese Master’s Thesis General Linguistics Faculty of Arts Radboud University Nijmegen November 2006 Geertje van Bergen 0136433 First supervisor: Dr. Helen de Hoop Second supervisor: Prof. Dr. Pieter Muysken V Acknowledgements I would like to thank Lotte Hogeweg and the members of the PIONIER-project Case Cross-linguistically for the nice cooperation during the past year; many thanks go to Monique Lamers for the pleasant teamwork. I am especially grateful to Yangning for the close cooperation in Beijing and Nijmegen, which has laid the foundation of ¡ £¢ this thesis. Many thanks also go to Sander Lestrade for clarifying conversations over countless cups of coffee. I would like to thank Pieter Muysken for his willingness to be my second supervisor and for his useful comments on an earlier version. Also, I gratefully acknowledge the Netherlands Organisation of Scientific Research (NWO) for financial support, grant 220-70-003, principal investigator Helen de Hoop (PIONIER-project ‘Case cross-linguistically’). Especially, I would like to thank Helen de Hoop for her great support and supervision, for keeping me from losing courage and keeping me on schedule, for her indispensable comments and for all the opportunities she offered me to develop my research skills. -

Variation in the Ergative Pattern of Kurmanji Songül Gündoğdu, Muş
Variation in the Ergative Pattern of Kurmanji Songül Gündoğdu, Muş Alparslan University, Muş, Turkey LANGUAGE KEYWORDS: Northern Kurdish (Kurmanji) AREA KEYWORDS: Middle East (Turkey) ABSTRACT (ENGLISH) Kurdish-Kurmanji (or Northern Kurdish) belongs to the Iranian branch of the Indo-European language family. This study is dedicated to a deeper understanding of a specific grammatical feature typical of Kurmanji: the ergative structure. Based on the example of this core structure, and with empirical evidence from the Kurmanji dialect of Muş in Turkey, I will discuss the issues of variation and change in Kurmanji, more precisely the ongoing shift from ergative to nominative-accusative structures. The causes for such a fundamental shift, however, are not easy to define. The close historical vicinity to Turkish and Armenian might be a trigger for the shift; another trigger is language-internal (diachronic) change. In sum, the investigated variation sheds light on a fascinating grammatical change in a language that is also sociopolitically in a situation of constant change, movement, and upheaval. ABSTRACT (DEUTSCH) Kurdisch-Kurmanci (oder Nordkurdisch) gehört zum iranischen Zweig der indoeuropäischen Sprachfamilie. Eine zentrale und charakteristische grammatische Struktur dieser Sprache ist der Ergativ; ihm ist der vorliegende Beitrag gewidmet. Am Beispiel des Ergativ werde ich Variation und Wandel im Kurmanci diskutieren und insbesondere auf den Dialekt von Muş (Türkei) eingehen. Dabei zeigt sich, dass sich derzeit im Kurmanci der Wandel von einer Ergativ- zu einer Nominativ-Akkusativ-Sprache vollzieht. Die Ursachen für einen derart grundlegenden Wandel sind nicht leicht zu benennen. Ein Grund mag in der schon historisch engen Nachbarschaft zum Türkischen und Armenischen liegen; ein anderer Grund mag im sprach-internen (diachronen) Wandel des Kurmanci selbst zu finden sein. -
Analytic and Cognitive Language in Instagram Captions
ISSN 2474-8927 SOCIAL BEHAVIOR RESEARCH AND PRACTICE Open Journal Brief Research Report What Were They Thinking? Analytic and Cognitive Language in Instagram Captions Sheila Brownlow, PhD1*; Makenna Pate, BA2; Abigail Alger, BA [Student]2; Natalie Naturile, BA2 1Department of Psychology, Catawba College, Salisbury NC 28144, USA *Corresponding author Sheila Brownlow, PhD Professor and Chair, Department of Psychology, Catawba College, Salisbury NC 28144, USA; E-mail: [email protected] Article Information Received: June 15th, 2019; Revised: July 8th, 2019; Accepted: July 15th, 2019; Published: July 16th, 2019 Cite this article Brownlow S, Pate M, Alger A, Naturile N. What were they thinking? Analytic and cognitive language in Instagram captions. Soc Behav Res Pract Open J. 2019; 4(1): 21-25. doi: 10.17140/SBRPOJ-4-117 ABSTRACT Background We examined content and expression of Instagram captions of major celebrities who differed according to sex and status, with a focus on determining whether these variables influenced the use of analytic language and cognitive content. Method Instagram captions (n=942) were analyzed with the linguistic inquiry and word count (LIWC), which delineated percentage of language reflecting analytical thought and various cognitive mechanisms, such as causality and discrepancy. Results Men and low-status persons used more functional analytic language, demonstrating critical thought; in contrast, high-status celeb- rities showed more causality. Women more than men “qualified” their speech with discrepancy. These findings were not a function of sentence length. Conclusion Status increased the tendency to construct and explain, perhaps because higher status celebrities (particularly women) knew that they could hold followers’ attention with complex content. -

Hybridity Versus Revivability
40 Hybridity versus revivability HYBRIDITY VERSUS REVIVABILITY: MULTIPLE CAUSATION, FORMS AND PATTERNS Ghil‘ad Zuckermann Abstract The aim of this article is to suggest that due to the ubiquitous multiple causation, the revival of a no-longer spoken language is unlikely without cross-fertilization from the revivalists’ mother tongue(s). Thus, one should expect revival efforts to result in a language with a hybridic genetic and typological character. The article highlights salient morphological constructions and categories, illustrating the difficulty in determining a single source for the grammar of Israeli, somewhat misleadingly a.k.a. ‘Modern Hebrew’. The European impact in these features is apparent inter alia in structure, semantics or productivity. Multiple causation is manifested in the Congruence Principle, according to which if a feature exists in more than one contributing language, it is more likely to persist in the emerging language. Consequently, the reality of linguistic genesis is far more complex than a simple family tree system allows. ‘Revived’ languages are unlikely to have a single parent. The multisourced nature of Israeli and the role of the Congruence Principle in its genesis have implications for historical linguistics, language planning and the study of language, culture and identity. “Linguistic and social factors are closely interrelated in the development of language change. Explanations which are confined to one or the other aspect, no matter how well constructed, will fail to account for the rich body of -

Information Structure and Object Marking: a Study Of
INFORMATION STRUCTURE AND OBJECT MARKING: A STUDY OF THE OBJECT PREPOSITION ʾET IN BIBLICAL HEBREW A DISSERTATION SUBMITTED TO THE FACULTY OF THE SCHOOL OF GRADUATE STUDIES HEBREW UNION COLLEGE—JEWISH INSTITUTE OF RELIGION BY PETER JOSEPH BEKINS IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY ________________________________ First Reader: Dr. Stephen A. Kaufman ________________________________ Second Reader: Dr. W. Randall Garr NOVEMBER 2012 © Copyright by Peter Joseph Bekins 2012 All rights reserved Acknowledgements I would like to begin by thanking my readers for their tireless work. My advisor, Stephen Kaufman, was everything that one could ask for in a first reader—direct and quick. I have benefited greatly from my years studying under him and completing this project with him. My second reader, Randall Garr, graciously took on this project despite the fact that we had never previously spoken, much less met. He proved to be the perfect complement with an eye to detail, and this work was improved immeasurably by his participation. I would like to thank my professors and colleagues at Hebrew Union College—Jewish Institute of Religion. The faculty of the graduate school, including Sam Greengus, David Weisberg !"#, Nili Fox, David Aaron, Jason Kalman, and Adam Kamesar, have all contributed to my growth as a scholar and a person. I thank my fellow graduate students for their friendship, fellowship, and encouragement. I would like to thank the other scholars who have taken an interest in my work and provided both support and encouragement. Robert Holmstedt and John Hobbins have given feedback and encouragement in various stages of the project. -

٧٠٩ Morphological Typology
جامعة واسط العـــــــــــــــدد السابع والثﻻثون مجلــــــــة كليــــــــة التربيــــــة الجزء اﻷول / تشرين الثاني / 2019 Morphological Typology: A Comparative Study of Some Selected Languages Bushra Farhood Khudheyier AlA'amiri Prof. Dr. Abdulkareem Fadhil Jameel, Ph.D. Department of English, College of Education/ Ibn Rushud for Humanities Baghdad University, Baghdad, Iraq Abstract Morphology is a main part of English linguistics which deals with forms of words. Morphological typology organizes languages on the basis of these word forms. This organization of languages depends on structural features to mould morphological, patterns, typologising languages, assigning them to analytic, or synthetic types on the base of words segmentability and invariance, or measuring the number of morphemes per word. Morphological typology studies the universals in languages, the differences and similarities between languages in the structural patterns found in different languages, which occur within a restricted range. This paper aims at distinguishing the various types of several universal languages and comparing them with English. The comparison of languages are set according to the number of morphemes, the degree of being analytic ,or synthetic languages by given examples of each type. Accordingly, it is hypothesed that languages are either to be analytic, or synthetic according to the syntactic and morphological form of morphemes and their meaning relation. The analytical procedures consist of expressing the morphological types with some selected examples, then making the comparison between each type and English. The conclusions reached at to the point of the existence of similarity between these morphological types . English is Analytic , but it has some synythetic aspects, so it validated the first hypothesis and not entirely refuted the second one. -

Polysynthetic Structures of Lowland Amazonia
OUP UNCORRECTED PROOF – REVISES, Sat Aug 19 2017, NEWGEN Chapter 15 Polysynthetic Structures of Lowland Amazonia Alexandra Y. Aikhenvald 15.1 Lowland Amazonian languages: a backdrop The Amazon basin is an area of high linguistic diversity (rivalled only by the island of New Guinea). It comprises around 350 languages grouped into over fifteen language families, in addition to a number of isolates. The six major linguistic families of the Amazon basin are as follows. • The Arawak language family is the largest in South America in terms of its geographical spread, with over forty extant languages between the Caribbean and Argentina. Well- established subgroups include Campa in Peru and a few small North Arawak groupings in Brazil and Venezuela. Arawak languages are spoken in at least ten locations north of the River Amazon, and in at least ten south of it. European languages contain a number of loans from Arawak languages, among them hammock and tobacco. • The Tupí language family consists of about seventy languages; nine of its ten branches are spoken exclusively in Amazonia. The largest branch, Tupí- Guaraní, extends beyond the Amazonian Basin into Bolivia and Paraguay. Loans from Tupí-Guaraní languages include jaguar and jacaranda. • Carib languages number about twenty five, and are spoken in various locations in Brazil and Venezuela in northern Amazonia, and in the region of the Upper Xingu and adjacent areas of Mato Grosso in Brazil south of the River Amazon. The place name ‘Caribbean’ and the noun cannibal (a version of the ethnonym ‘Carib’) are a legacy from Carib languages. • Panoan languages number about thirty, and are spoken on the eastern side of the Andes in Peru and adjacent areas of Brazil. -

Chapter 36. Grammatical Change
Chapter 36. Grammatical change Willem B. Hollmann 36.1 Preliminaries Grammatical change is an extremely interesting area but does presuppose some knowledge of grammar. For this reason, if you do not have this knowledge yet, this chapter will work best if you have first familiarised yourself with the terminology discussed in the chapters on grammar, i.e. especially chapters and 5–8. Chapters on grammatical change in traditional textbooks on the history of English or historical linguistics by and large focus on change in morphology (the structure of words) and/or syntax (the structure of phrases and clauses). Some of the most important changes in the history of English can indeed be described in more or less purely structural terms, i.e. without considering meaning very much. Sentences (1–2), below, illustrate object-verb (or OV) constituent order,1 which was quite frequent in Old English but became less and less common during Middle English, until it was completely lost in the sixteenth century. (1) Gregorius [hine object] [afligde verb]. (Homilies of Ælfric 22.624) Gregory him put-to-flight ‘Gregory made him flee’ (2) Ne sceal he [naht unaliefedes object] [don verb]. (Pastoral Care 10.61.14) not shall he nothing unlawful do ‘He will do nothing unlawful’ Example (2) shows that we must be careful when discussing OV order in Old and Middle English: the finite verb (here: sceal) actually often occurred before the object, taking up the second position in the clause (the initial position here being occupied by the negator ne). Thus, it is often only the lexical verb (here: don) that follows the object.