٧٠٩ Morphological Typology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computational Challenges for Polysynthetic Languages
Computational Modeling of Polysynthetic Languages Judith L. Klavans, Ph.D. US Army Research Laboratory 2800 Powder Mill Road Adelphi, Maryland 20783 [email protected] [email protected] Abstract Given advances in computational linguistic analysis of complex languages using Machine Learning as well as standard Finite State Transducers, coupled with recent efforts in language revitalization, the time was right to organize a first workshop to bring together experts in language technology and linguists on the one hand with language practitioners and revitalization experts on the other. This one-day meeting provides a promising forum to discuss new research on polysynthetic languages in combination with the needs of linguistic communities where such languages are written and spoken. Finally, this overview article summarizes the papers to be presented, along with goals and purpose. Motivation Polysynthetic languages are characterized by words that are composed of multiple morphemes, often to the extent that one long word can express the meaning contained in a multi-word sentence in lan- guage like English. To illustrate, consider the following example from Inuktitut, one of the official languages of the Territory of Nunavut in Canada. The morpheme -tusaa- (shown in boldface below) is the root, and all the other morphemes are synthetically combined with it in one unit.1 (1) tusaa-tsia-runna-nngit-tu-alu-u-junga hear-well-be.able-NEG-DOER-very-BE-PART.1.S ‘I can't hear very well.’ Kabardian (Circassian), from the Northwest Caucasus, also shows this phenomenon, with the root -še- shown in boldface below: (2) wə-q’ə-d-ej-z-γe-še-ž’e-f-a-te-q’əm 2SG.OBJ-DIR-LOC-3SG.OBJ-1SG.SUBJ-CAUS-lead-COMPL-POTENTIAL-PAST-PRF-NEG ‘I would not let you bring him right back here.’ Polysynthetic languages are spoken all over the globe and are richly represented among Native North and South American families. -

“Today's Morphology Is Yeatyerday's Syntax”
MOTHER TONGUE Journal of the Association for the Study of Language in Prehistory • Issue XXI • 2016 From North to North West: How North-West Caucasian Evolved from North Caucasian Viacheslav A. Chirikba Abkhaz State University, Sukhum, Republic of Abkhazia The comparison of (North-)West Caucasian with (North-)East Caucasian languages suggests that early Proto-West Caucasian underwent a fundamental reshaping of its phonological, morphological and syntactic structures, as a result of which it became analytical, with elementary inflection and main grammatical roles being expressed by lexical means, word order and probably also by tones. The subsequent development of compounding and incorporation resulted in a prefixing polypersonal polysynthetic agglutinative language type typical for modern West Caucasian languages. The main evolutionary line from a North Caucasian dialect close to East Caucasian to modern West Caucasian languages was thus from agglutinative to the analytical language-type, due to a near complete loss of inflection, and then to the agglutinative polysynthetic type. Although these changes blurred the genetic relationship between West Caucasian and East Caucasian languages, however, this can be proven by applying standard procedures of comparative-historical linguistics. 1. The West Caucasian languages.1 The West Caucasian (WC), or Abkhazo-Adyghean languages constitute a branch of the North Caucasian (NC) linguistic family, which consists of five languages: Abkhaz and Abaza (the Abkhaz sub-group), Adyghe and Kabardian (the Circassian sub-group), and Ubykh. The traditional habitat of these languages is the Western Caucasus, where they are still spoken, with the exception of the extinct Ubykh. Typologically, the WC languages represent a rather idiosyncratic linguistic type not occurring elsewhere in Eurasia. -

Reconsidering the “Isolating Protolanguage Hypothesis” in the Evolution of Morphology Author(S): Jaïmé Dubé Proceedings
Reconsidering the “isolating protolanguage hypothesis” in the evolution of morphology Author(s): Jaïmé Dubé Proceedings of the 37th Annual Meeting of the Berkeley Linguistics Society (2013), pp. 76-90 Editors: Chundra Cathcart, I-Hsuan Chen, Greg Finley, Shinae Kang, Clare S. Sandy, and Elise Stickles Please contact BLS regarding any further use of this work. BLS retains copyright for both print and screen forms of the publication. BLS may be contacted via http://linguistics.berkeley.edu/bls/. The Annual Proceedings of the Berkeley Linguistics Society is published online via eLanguage, the Linguistic Society of America's digital publishing platform. Reconsidering the Isolating Protolanguage Hypothesis in the Evolution of Morphology1 JAÏMÉ DUBÉ Université de Montréal 1 Introduction Much recent work on the evolution of language assumes explicitly or implicitly that the original language was without morphology. Under this assumption, morphology is merely a consequence of language use: affixal morphology is the result of the agglutination of free words, and morphophonemic (MP) alternations arise through the morphologization of once regular phonological processes. This hypothesis is based on at least two questionable assumptions: first, that the methods and results of historical linguistics can provide a window on the evolution of language, and second, based on the claim that some languages have no morphology (the so-called isolating languages), that morphology is not a necessary part of language. The aim of this paper is to suggest that there is in fact no basis for what I will call the Isolating Proto-Language Hypothesis (henceforth IPH), either on historical or typological grounds, and that the evolution of morphology remains an interesting question. -

Transparency in Language a Typological Study
Transparency in language A typological study Published by LOT phone: +31 30 253 6111 Trans 10 3512 JK Utrecht e-mail: [email protected] The Netherlands http://www.lotschool.nl Cover illustration © 2011: Sanne Leufkens – image from the performance ‘Celebration’ ISBN: 978-94-6093-162-8 NUR 616 Copyright © 2015: Sterre Leufkens. All rights reserved. Transparency in language A typological study ACADEMISCH PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Universiteit van Amsterdam op gezag van de Rector Magnificus prof. dr. D.C. van den Boom ten overstaan van een door het college voor promoties ingestelde commissie, in het openbaar te verdedigen in de Agnietenkapel op vrijdag 23 januari 2015, te 10.00 uur door Sterre Cécile Leufkens geboren te Delft Promotiecommissie Promotor: Prof. dr. P.C. Hengeveld Copromotor: Dr. N.S.H. Smith Overige leden: Prof. dr. E.O. Aboh Dr. J. Audring Prof. dr. Ö. Dahl Prof. dr. M.E. Keizer Prof. dr. F.P. Weerman Faculteit der Geesteswetenschappen i Acknowledgments When I speak about my PhD project, it appears to cover a time-span of four years, in which I performed a number of actions that resulted in this book. In fact, the limits of the project are not so clear. It started when I first heard about linguistics, and it will end when we all stop thinking about transparency, which hopefully will not be the case any time soon. Moreover, even though I might have spent most time and effort to ‘complete’ this project, it is definitely not just my work. Many people have contributed directly or indirectly, by thinking about transparency, or thinking about me. -

Typology, Documentation, Description, and Typology
Typology, Documentation, Description, and Typology Marianne Mithun University of California, Santa Barbara Abstract If the goals of linguistic typology, are, as described by Plank (2016): (a) to chart linguistic diversity (b) to seek out order or even unity in diversity knowledge of the current state of the art is an invaluable tool for almost any linguistic endeavor. For language documentation and description, knowing what distinctions, categories, and patterns have been observed in other languages makes it possible to identify them more quickly and thoroughly in an unfamiliar language. Knowing how they differ in detail can prompt us to tune into those details. Knowing what is rare cross-linguistically can ensure that unusual features are richly documented and prominent in descriptions. But if documentation and description are limited to filling in typological checklists, not only will much of the essence of each language be missed, but the field of typology will also suffer, as new variables and correlations will fail to surface, and our understanding of deeper factors behind cross-linguistic similarities and differences will not progress. 1. Typological awareness as a tool Looking at the work of early scholars such as Franz Boas and Edward Sapir, it is impossible not to be amazed at the richness of their documentation and the insight of their descriptions of languages so unlike the more familiar languages of Europe. It is unlikely that Boas first arrived on Baffin Island forewarned to watch for velar/uvular distinctions and ergativity. Now more than a century later, an awareness of what distinctions can be significant in languages and what kinds of systems recur can provide tremendous advantages, allowing us to spot potentially important features sooner and identify patterns on the basis of fewer examples. -
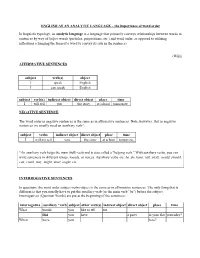
ENGLISH AS an ANALYTIC LANGUAGE – the Importance of Word Order
ENGLISH AS AN ANALYTIC LANGUAGE – the importance of word order In linguistic typology, an analytic language is a language that primarily conveys relationships between words in sentences by way of helper words (particles, prepositions, etc.) and word order, as opposed to utilizing inflections (changing the form of a word to convey its role in the sentence) (Wiki) AFFIRMATIVE SENTENCES subject verb(s) object I speak English I can speak English subject verb(s) indirect object direct object place time I will tell you the story at school tomorrow. NEGATIVE SENTENCE The word order in negative sentences is the same as in affirmative sentences. Note, however, that in negative sentences we usually need an auxiliary verb*: subject verbs indirect object direct object place time I will not tell you the story at school tomorrow. *An auxiliary verb helps the main (full) verb and is also called a "helping verb." With auxiliary verbs, you can write sentences in different tenses, moods, or voices. Auxiliary verbs are: be, do, have, will, shall, would, should, can, could, may, might, must, ought, etc. INTERROGATIVE SENTENCES In questions, the word order subject-verbs-object is the same as in affirmative sentences. The only thing that is different is that you usually have to put the auxiliary verb (or the main verb “be”) before the subject. Interrogatives (Question Words) are put at the beginning of the sentences: interrogative auxiliary *verb subject other verb(s) indirect object direct object place time What would you like to tell me Did you have a party in your flat yesterday? When were you here? Question Words in English The most common question words in English are the following: WHO is only used when referring to people. -

To Ba Or Not to Ba Differential Object Marking in Chinese
î To ba or not to ba Differential Object Marking in Chinese Geertje van Bergen I To ba or not to ba Differential Object Marking in Chinese Geertje van Bergen PIONIER Project Case Cross-linguistically Department of Linguistics Radboud University Nijmegen P.O. Box 9103 6500 HD Nijmegen the Netherlands www.ru.nl/pionier [email protected] III To ba or not to ba Differential Object Marking in Chinese Master’s Thesis General Linguistics Faculty of Arts Radboud University Nijmegen November 2006 Geertje van Bergen 0136433 First supervisor: Dr. Helen de Hoop Second supervisor: Prof. Dr. Pieter Muysken V Acknowledgements I would like to thank Lotte Hogeweg and the members of the PIONIER-project Case Cross-linguistically for the nice cooperation during the past year; many thanks go to Monique Lamers for the pleasant teamwork. I am especially grateful to Yangning for the close cooperation in Beijing and Nijmegen, which has laid the foundation of ¡ £¢ this thesis. Many thanks also go to Sander Lestrade for clarifying conversations over countless cups of coffee. I would like to thank Pieter Muysken for his willingness to be my second supervisor and for his useful comments on an earlier version. Also, I gratefully acknowledge the Netherlands Organisation of Scientific Research (NWO) for financial support, grant 220-70-003, principal investigator Helen de Hoop (PIONIER-project ‘Case cross-linguistically’). Especially, I would like to thank Helen de Hoop for her great support and supervision, for keeping me from losing courage and keeping me on schedule, for her indispensable comments and for all the opportunities she offered me to develop my research skills. -

Variation in the Ergative Pattern of Kurmanji Songül Gündoğdu, Muş
Variation in the Ergative Pattern of Kurmanji Songül Gündoğdu, Muş Alparslan University, Muş, Turkey LANGUAGE KEYWORDS: Northern Kurdish (Kurmanji) AREA KEYWORDS: Middle East (Turkey) ABSTRACT (ENGLISH) Kurdish-Kurmanji (or Northern Kurdish) belongs to the Iranian branch of the Indo-European language family. This study is dedicated to a deeper understanding of a specific grammatical feature typical of Kurmanji: the ergative structure. Based on the example of this core structure, and with empirical evidence from the Kurmanji dialect of Muş in Turkey, I will discuss the issues of variation and change in Kurmanji, more precisely the ongoing shift from ergative to nominative-accusative structures. The causes for such a fundamental shift, however, are not easy to define. The close historical vicinity to Turkish and Armenian might be a trigger for the shift; another trigger is language-internal (diachronic) change. In sum, the investigated variation sheds light on a fascinating grammatical change in a language that is also sociopolitically in a situation of constant change, movement, and upheaval. ABSTRACT (DEUTSCH) Kurdisch-Kurmanci (oder Nordkurdisch) gehört zum iranischen Zweig der indoeuropäischen Sprachfamilie. Eine zentrale und charakteristische grammatische Struktur dieser Sprache ist der Ergativ; ihm ist der vorliegende Beitrag gewidmet. Am Beispiel des Ergativ werde ich Variation und Wandel im Kurmanci diskutieren und insbesondere auf den Dialekt von Muş (Türkei) eingehen. Dabei zeigt sich, dass sich derzeit im Kurmanci der Wandel von einer Ergativ- zu einer Nominativ-Akkusativ-Sprache vollzieht. Die Ursachen für einen derart grundlegenden Wandel sind nicht leicht zu benennen. Ein Grund mag in der schon historisch engen Nachbarschaft zum Türkischen und Armenischen liegen; ein anderer Grund mag im sprach-internen (diachronen) Wandel des Kurmanci selbst zu finden sein. -
Analytic and Cognitive Language in Instagram Captions
ISSN 2474-8927 SOCIAL BEHAVIOR RESEARCH AND PRACTICE Open Journal Brief Research Report What Were They Thinking? Analytic and Cognitive Language in Instagram Captions Sheila Brownlow, PhD1*; Makenna Pate, BA2; Abigail Alger, BA [Student]2; Natalie Naturile, BA2 1Department of Psychology, Catawba College, Salisbury NC 28144, USA *Corresponding author Sheila Brownlow, PhD Professor and Chair, Department of Psychology, Catawba College, Salisbury NC 28144, USA; E-mail: [email protected] Article Information Received: June 15th, 2019; Revised: July 8th, 2019; Accepted: July 15th, 2019; Published: July 16th, 2019 Cite this article Brownlow S, Pate M, Alger A, Naturile N. What were they thinking? Analytic and cognitive language in Instagram captions. Soc Behav Res Pract Open J. 2019; 4(1): 21-25. doi: 10.17140/SBRPOJ-4-117 ABSTRACT Background We examined content and expression of Instagram captions of major celebrities who differed according to sex and status, with a focus on determining whether these variables influenced the use of analytic language and cognitive content. Method Instagram captions (n=942) were analyzed with the linguistic inquiry and word count (LIWC), which delineated percentage of language reflecting analytical thought and various cognitive mechanisms, such as causality and discrepancy. Results Men and low-status persons used more functional analytic language, demonstrating critical thought; in contrast, high-status celeb- rities showed more causality. Women more than men “qualified” their speech with discrepancy. These findings were not a function of sentence length. Conclusion Status increased the tendency to construct and explain, perhaps because higher status celebrities (particularly women) knew that they could hold followers’ attention with complex content. -

Hybridity Versus Revivability
40 Hybridity versus revivability HYBRIDITY VERSUS REVIVABILITY: MULTIPLE CAUSATION, FORMS AND PATTERNS Ghil‘ad Zuckermann Abstract The aim of this article is to suggest that due to the ubiquitous multiple causation, the revival of a no-longer spoken language is unlikely without cross-fertilization from the revivalists’ mother tongue(s). Thus, one should expect revival efforts to result in a language with a hybridic genetic and typological character. The article highlights salient morphological constructions and categories, illustrating the difficulty in determining a single source for the grammar of Israeli, somewhat misleadingly a.k.a. ‘Modern Hebrew’. The European impact in these features is apparent inter alia in structure, semantics or productivity. Multiple causation is manifested in the Congruence Principle, according to which if a feature exists in more than one contributing language, it is more likely to persist in the emerging language. Consequently, the reality of linguistic genesis is far more complex than a simple family tree system allows. ‘Revived’ languages are unlikely to have a single parent. The multisourced nature of Israeli and the role of the Congruence Principle in its genesis have implications for historical linguistics, language planning and the study of language, culture and identity. “Linguistic and social factors are closely interrelated in the development of language change. Explanations which are confined to one or the other aspect, no matter how well constructed, will fail to account for the rich body of -

Modeling Infant Segmentation of Two Morphologically Diverse Languages
Modeling infant segmentation of two morphologically diverse languages Georgia Rengina Loukatou1 Sabine Stoll 2 Damian Blasi2 Alejandrina Cristia1 (1) LSCP, Département d’études cognitives, ENS, EHESS, CNRS, PSL Research University, Paris, France (2) University of Zurich, Zurich, Switzerland [email protected] RÉSUMÉ Les nourrissons doivent trouver des limites de mots dans le flux continu de la parole. De nombreuses études computationnelles étudient de tels mécanismes. Cependant, la majorité d’entre elles se sont concentrées sur l’anglais, une langue morphologiquement simple et qui rend la tâche de segmen- tation aisée. Les langues polysynthétiques - pour lesquelles chaque mot est composé de plusieurs morphèmes - peuvent présenter des difficultés supplémentaires lors de la segmentation. De plus, le mot est considéré comme la cible de la segmentation, mais il est possible que les nourrissons segmentent des morphèmes et non pas des mots. Notre étude se concentre sur deux langues ayant des structures morphologiques différentes, le chintang et le japonais. Trois algorithmes de segmentation conceptuellement variés sont évalués sur des représentations de mots et de morphèmes. L’évaluation de ces algorithmes nous mène à tirer plusieurs conclusions. Le modèle lexical est le plus performant, notamment lorsqu’on considère les morphèmes et non pas les mots. De plus, en faisant varier leur évaluation en fonction de la langue, le japonais nous apporte de meilleurs résultats. ABSTRACT A rich literature explores unsupervised segmentation algorithms infants could use to parse their input, mainly focusing on English, an analytic language where word, morpheme, and syllable boundaries often coincide. Synthetic languages, where words are multi-morphemic, may present unique diffi- culties for segmentation. -

Inflection, P. 1
36607. MORPHOLOGY Prof. Yehuda N. Falk Inflection, p. 1 In flectional morphology expresses morphosyntactic properties of lexemes. For each lexical category (part of speech) there is a certain set of available properties; the forms specify the properties. The most straightforward way to model this is in terms of features and their vvvaluesvaluesalues. For nirkod expresses a particular set of properties associated נרקוד example, the Hebrew form with the lexeme RAKAD : the feature TENSE with the value FUTURE , the feature PERSON with the value 1, and the feature NUMBER with the value PLURAL . The textbook uses di Terent terminology: in flectional dimension instead of feature , and in flectional category instead of value . The term feature is also sometimes used for a feature-value combination, such as the phrase “the past tense feature”. The in flectional properties of a word can be represented as a fffeature-valuefeature-value (or attribute-valueattribute-value) representation: RAKAD TENSE FUT nirkod PERS 1 NUM PL This can also be written horizontally, and even abbreviated: 〈RAKAD , [ TENSE FUT , PERS 1, NUM PL ]〉 nirkod 1Pl.Fut A paradigm is a chart showing all the features and feature values for a particular lexeme. The expression of in flectional properties is called exponenceexponence. In the simplest case, there is a . זכרונות one-to-one relationship between properties and exponents. Note the word ZIKARON zixron+ot []NUM PL Zixron is the stem, and the su Ux -ot is the exponent of the [ NUM PL ] feature. טובות Not everything is that simple, though. Consider the adjective 36607. MORPHOLOGY Prof. Yehuda N. Falk Inflection, p.