Analytic and Cognitive Language in Instagram Captions
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
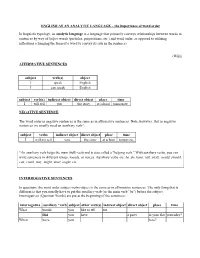
ENGLISH AS an ANALYTIC LANGUAGE – the Importance of Word Order
ENGLISH AS AN ANALYTIC LANGUAGE – the importance of word order In linguistic typology, an analytic language is a language that primarily conveys relationships between words in sentences by way of helper words (particles, prepositions, etc.) and word order, as opposed to utilizing inflections (changing the form of a word to convey its role in the sentence) (Wiki) AFFIRMATIVE SENTENCES subject verb(s) object I speak English I can speak English subject verb(s) indirect object direct object place time I will tell you the story at school tomorrow. NEGATIVE SENTENCE The word order in negative sentences is the same as in affirmative sentences. Note, however, that in negative sentences we usually need an auxiliary verb*: subject verbs indirect object direct object place time I will not tell you the story at school tomorrow. *An auxiliary verb helps the main (full) verb and is also called a "helping verb." With auxiliary verbs, you can write sentences in different tenses, moods, or voices. Auxiliary verbs are: be, do, have, will, shall, would, should, can, could, may, might, must, ought, etc. INTERROGATIVE SENTENCES In questions, the word order subject-verbs-object is the same as in affirmative sentences. The only thing that is different is that you usually have to put the auxiliary verb (or the main verb “be”) before the subject. Interrogatives (Question Words) are put at the beginning of the sentences: interrogative auxiliary *verb subject other verb(s) indirect object direct object place time What would you like to tell me Did you have a party in your flat yesterday? When were you here? Question Words in English The most common question words in English are the following: WHO is only used when referring to people. -

To Ba Or Not to Ba Differential Object Marking in Chinese
î To ba or not to ba Differential Object Marking in Chinese Geertje van Bergen I To ba or not to ba Differential Object Marking in Chinese Geertje van Bergen PIONIER Project Case Cross-linguistically Department of Linguistics Radboud University Nijmegen P.O. Box 9103 6500 HD Nijmegen the Netherlands www.ru.nl/pionier [email protected] III To ba or not to ba Differential Object Marking in Chinese Master’s Thesis General Linguistics Faculty of Arts Radboud University Nijmegen November 2006 Geertje van Bergen 0136433 First supervisor: Dr. Helen de Hoop Second supervisor: Prof. Dr. Pieter Muysken V Acknowledgements I would like to thank Lotte Hogeweg and the members of the PIONIER-project Case Cross-linguistically for the nice cooperation during the past year; many thanks go to Monique Lamers for the pleasant teamwork. I am especially grateful to Yangning for the close cooperation in Beijing and Nijmegen, which has laid the foundation of ¡ £¢ this thesis. Many thanks also go to Sander Lestrade for clarifying conversations over countless cups of coffee. I would like to thank Pieter Muysken for his willingness to be my second supervisor and for his useful comments on an earlier version. Also, I gratefully acknowledge the Netherlands Organisation of Scientific Research (NWO) for financial support, grant 220-70-003, principal investigator Helen de Hoop (PIONIER-project ‘Case cross-linguistically’). Especially, I would like to thank Helen de Hoop for her great support and supervision, for keeping me from losing courage and keeping me on schedule, for her indispensable comments and for all the opportunities she offered me to develop my research skills. -

Variation in the Ergative Pattern of Kurmanji Songül Gündoğdu, Muş
Variation in the Ergative Pattern of Kurmanji Songül Gündoğdu, Muş Alparslan University, Muş, Turkey LANGUAGE KEYWORDS: Northern Kurdish (Kurmanji) AREA KEYWORDS: Middle East (Turkey) ABSTRACT (ENGLISH) Kurdish-Kurmanji (or Northern Kurdish) belongs to the Iranian branch of the Indo-European language family. This study is dedicated to a deeper understanding of a specific grammatical feature typical of Kurmanji: the ergative structure. Based on the example of this core structure, and with empirical evidence from the Kurmanji dialect of Muş in Turkey, I will discuss the issues of variation and change in Kurmanji, more precisely the ongoing shift from ergative to nominative-accusative structures. The causes for such a fundamental shift, however, are not easy to define. The close historical vicinity to Turkish and Armenian might be a trigger for the shift; another trigger is language-internal (diachronic) change. In sum, the investigated variation sheds light on a fascinating grammatical change in a language that is also sociopolitically in a situation of constant change, movement, and upheaval. ABSTRACT (DEUTSCH) Kurdisch-Kurmanci (oder Nordkurdisch) gehört zum iranischen Zweig der indoeuropäischen Sprachfamilie. Eine zentrale und charakteristische grammatische Struktur dieser Sprache ist der Ergativ; ihm ist der vorliegende Beitrag gewidmet. Am Beispiel des Ergativ werde ich Variation und Wandel im Kurmanci diskutieren und insbesondere auf den Dialekt von Muş (Türkei) eingehen. Dabei zeigt sich, dass sich derzeit im Kurmanci der Wandel von einer Ergativ- zu einer Nominativ-Akkusativ-Sprache vollzieht. Die Ursachen für einen derart grundlegenden Wandel sind nicht leicht zu benennen. Ein Grund mag in der schon historisch engen Nachbarschaft zum Türkischen und Armenischen liegen; ein anderer Grund mag im sprach-internen (diachronen) Wandel des Kurmanci selbst zu finden sein. -

Hybridity Versus Revivability
40 Hybridity versus revivability HYBRIDITY VERSUS REVIVABILITY: MULTIPLE CAUSATION, FORMS AND PATTERNS Ghil‘ad Zuckermann Abstract The aim of this article is to suggest that due to the ubiquitous multiple causation, the revival of a no-longer spoken language is unlikely without cross-fertilization from the revivalists’ mother tongue(s). Thus, one should expect revival efforts to result in a language with a hybridic genetic and typological character. The article highlights salient morphological constructions and categories, illustrating the difficulty in determining a single source for the grammar of Israeli, somewhat misleadingly a.k.a. ‘Modern Hebrew’. The European impact in these features is apparent inter alia in structure, semantics or productivity. Multiple causation is manifested in the Congruence Principle, according to which if a feature exists in more than one contributing language, it is more likely to persist in the emerging language. Consequently, the reality of linguistic genesis is far more complex than a simple family tree system allows. ‘Revived’ languages are unlikely to have a single parent. The multisourced nature of Israeli and the role of the Congruence Principle in its genesis have implications for historical linguistics, language planning and the study of language, culture and identity. “Linguistic and social factors are closely interrelated in the development of language change. Explanations which are confined to one or the other aspect, no matter how well constructed, will fail to account for the rich body of -

Modeling Infant Segmentation of Two Morphologically Diverse Languages
Modeling infant segmentation of two morphologically diverse languages Georgia Rengina Loukatou1 Sabine Stoll 2 Damian Blasi2 Alejandrina Cristia1 (1) LSCP, Département d’études cognitives, ENS, EHESS, CNRS, PSL Research University, Paris, France (2) University of Zurich, Zurich, Switzerland [email protected] RÉSUMÉ Les nourrissons doivent trouver des limites de mots dans le flux continu de la parole. De nombreuses études computationnelles étudient de tels mécanismes. Cependant, la majorité d’entre elles se sont concentrées sur l’anglais, une langue morphologiquement simple et qui rend la tâche de segmen- tation aisée. Les langues polysynthétiques - pour lesquelles chaque mot est composé de plusieurs morphèmes - peuvent présenter des difficultés supplémentaires lors de la segmentation. De plus, le mot est considéré comme la cible de la segmentation, mais il est possible que les nourrissons segmentent des morphèmes et non pas des mots. Notre étude se concentre sur deux langues ayant des structures morphologiques différentes, le chintang et le japonais. Trois algorithmes de segmentation conceptuellement variés sont évalués sur des représentations de mots et de morphèmes. L’évaluation de ces algorithmes nous mène à tirer plusieurs conclusions. Le modèle lexical est le plus performant, notamment lorsqu’on considère les morphèmes et non pas les mots. De plus, en faisant varier leur évaluation en fonction de la langue, le japonais nous apporte de meilleurs résultats. ABSTRACT A rich literature explores unsupervised segmentation algorithms infants could use to parse their input, mainly focusing on English, an analytic language where word, morpheme, and syllable boundaries often coincide. Synthetic languages, where words are multi-morphemic, may present unique diffi- culties for segmentation. -

Information Structure and Object Marking: a Study Of
INFORMATION STRUCTURE AND OBJECT MARKING: A STUDY OF THE OBJECT PREPOSITION ʾET IN BIBLICAL HEBREW A DISSERTATION SUBMITTED TO THE FACULTY OF THE SCHOOL OF GRADUATE STUDIES HEBREW UNION COLLEGE—JEWISH INSTITUTE OF RELIGION BY PETER JOSEPH BEKINS IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY ________________________________ First Reader: Dr. Stephen A. Kaufman ________________________________ Second Reader: Dr. W. Randall Garr NOVEMBER 2012 © Copyright by Peter Joseph Bekins 2012 All rights reserved Acknowledgements I would like to begin by thanking my readers for their tireless work. My advisor, Stephen Kaufman, was everything that one could ask for in a first reader—direct and quick. I have benefited greatly from my years studying under him and completing this project with him. My second reader, Randall Garr, graciously took on this project despite the fact that we had never previously spoken, much less met. He proved to be the perfect complement with an eye to detail, and this work was improved immeasurably by his participation. I would like to thank my professors and colleagues at Hebrew Union College—Jewish Institute of Religion. The faculty of the graduate school, including Sam Greengus, David Weisberg !"#, Nili Fox, David Aaron, Jason Kalman, and Adam Kamesar, have all contributed to my growth as a scholar and a person. I thank my fellow graduate students for their friendship, fellowship, and encouragement. I would like to thank the other scholars who have taken an interest in my work and provided both support and encouragement. Robert Holmstedt and John Hobbins have given feedback and encouragement in various stages of the project. -

٧٠٩ Morphological Typology
جامعة واسط العـــــــــــــــدد السابع والثﻻثون مجلــــــــة كليــــــــة التربيــــــة الجزء اﻷول / تشرين الثاني / 2019 Morphological Typology: A Comparative Study of Some Selected Languages Bushra Farhood Khudheyier AlA'amiri Prof. Dr. Abdulkareem Fadhil Jameel, Ph.D. Department of English, College of Education/ Ibn Rushud for Humanities Baghdad University, Baghdad, Iraq Abstract Morphology is a main part of English linguistics which deals with forms of words. Morphological typology organizes languages on the basis of these word forms. This organization of languages depends on structural features to mould morphological, patterns, typologising languages, assigning them to analytic, or synthetic types on the base of words segmentability and invariance, or measuring the number of morphemes per word. Morphological typology studies the universals in languages, the differences and similarities between languages in the structural patterns found in different languages, which occur within a restricted range. This paper aims at distinguishing the various types of several universal languages and comparing them with English. The comparison of languages are set according to the number of morphemes, the degree of being analytic ,or synthetic languages by given examples of each type. Accordingly, it is hypothesed that languages are either to be analytic, or synthetic according to the syntactic and morphological form of morphemes and their meaning relation. The analytical procedures consist of expressing the morphological types with some selected examples, then making the comparison between each type and English. The conclusions reached at to the point of the existence of similarity between these morphological types . English is Analytic , but it has some synythetic aspects, so it validated the first hypothesis and not entirely refuted the second one. -

Chapter 36. Grammatical Change
Chapter 36. Grammatical change Willem B. Hollmann 36.1 Preliminaries Grammatical change is an extremely interesting area but does presuppose some knowledge of grammar. For this reason, if you do not have this knowledge yet, this chapter will work best if you have first familiarised yourself with the terminology discussed in the chapters on grammar, i.e. especially chapters and 5–8. Chapters on grammatical change in traditional textbooks on the history of English or historical linguistics by and large focus on change in morphology (the structure of words) and/or syntax (the structure of phrases and clauses). Some of the most important changes in the history of English can indeed be described in more or less purely structural terms, i.e. without considering meaning very much. Sentences (1–2), below, illustrate object-verb (or OV) constituent order,1 which was quite frequent in Old English but became less and less common during Middle English, until it was completely lost in the sixteenth century. (1) Gregorius [hine object] [afligde verb]. (Homilies of Ælfric 22.624) Gregory him put-to-flight ‘Gregory made him flee’ (2) Ne sceal he [naht unaliefedes object] [don verb]. (Pastoral Care 10.61.14) not shall he nothing unlawful do ‘He will do nothing unlawful’ Example (2) shows that we must be careful when discussing OV order in Old and Middle English: the finite verb (here: sceal) actually often occurred before the object, taking up the second position in the clause (the initial position here being occupied by the negator ne). Thus, it is often only the lexical verb (here: don) that follows the object. -

CONTRASTIVE GRAMMAR: Theory and Practice
Киї вськии університет Національнии університет імені Бориса Грінченка «Києво-Могилянська академія» CONTRASTIVE GRAMMAR: Theory and Practice KYIV 2019 0 УДК 811.111-112(076) Contrastive Grammar: Theory and Practice = Порівняльна граматика: теорія і практика: навч. посіб. / авт.-сост.: Н. Ф. Гладуш, Н. В. Павлюк; Київ. ун-т. ім. Б. Грінченка; Нац. ун-т «Києво-Могилянська акад.». – К., 2019. – 296 с. Навчальний посібник з порівняльної граматики англійської та української мов висвітлює теоретичні питання, які розкривають спільні та відмінні риси у структурі двох мов. Кожна тема з морфології та синтаксису супроводжується практичними завданнями, які допомагають краще зрозуміти і засвоїти матеріал. У другій частині надаються таблиці, які систематизують і класифікують явища, що вивчаються. Посібник відповідає програмі курсу «Порівняльна граматика англійської та української мов» для вищих навчальних закладів. Розраховано на студентів спеціальності «Філологія» навчальних закладів вищої освіти, викладачів та усіх, кого цікавлять питання структурної організації мови. УДК 811.111-112(076) 1 CONTENTS Preface 4 Unit 1. Introduction to Contrastive Grammar 5 Unit 2. Basic Grammar Notions 16 Unit 3. Contrastive Morphology 19 Unit 4. The Noun in English and Ukrainian 26 Unit 5. The Adjective, Numeral and Pronoun in English and Ukrainian 34 Unit 6. The Article 43 Unit 7. Functional Parts of Speech in English and Ukrainian 48 Unit 8. The Verb in English and Ukrainian 55 Unit 9. Verbals in English and Ukrainian 65 Unit 10. The Adverb and Stative in English and Ukrainian 72 Unit 11. Contrastive Syntax. Phrases in English and Ukrainian 78 Unit 12. The Simple sentence in English and Ukrainian 87 Unit 13. The Composite Sentence in English and Ukrainian 95 Unit 14. -

Morphology Handout 1
Kirk Hazen HEL Morphology Handout 1. Analytic. 1.1. Most words are single morphemes (even for concepts like "we" which is both first person and plural (i.e. two different concepts and two different words in an analytic language). 1.2. Mandarin Chinese. 1.2.1. [wò mën tan tcin] 'I plural play piano' 1.2.2. [wò mën tan tcin lë] 'I plural play piano past ' 1.2.3. [ta da wò mën] 'S/he hit I plural ' 2. Synthetic. 2.1. Synthetic languages combine several morphemes into single words. How they combine them determines what kind of synthetic language they are. 2.1.1. Hungarian 2.1.1.1. [òz èmber la…tjò ò kuca…t] 'the man sees the dog-object ' 2.1.1.2. [òz kucò la…tjò ò èmbert] 'the dog sees the man-object ' 2.1.1.3. [ò ha…zunk zold] 'the house-our green' Our house is green. 2.1.1.4. [ò ha…zòd zold] 'the house-your green' Your house is green. 2.1.2. Agglutinative 2.1.2.1. Swahili 2.1.2.1.1. nitakupenda 'I will like you' (literally ni 'I' ta 'future' ku 'second-person object', penda 'like'; 'I will you like'). 2.1.2.1.2. The parts which correspond to each concept or grammatical function are clearly discrete (albeit joined) from the other elements in the word. 2.1.3. Fusional 2.1.3.1. Spanish 2.1.3.1.1. hablo (I am speaking), habla (S/he is speaking), hable‰ (I spoke), but also hablamos (We are speaking), hablan (They are speaking). -

Null Expletives in Malay
GEMA Online® Journal of Language Studies 224 Volume 20(2), May 2020 http://doi.org/10.17576/gema-2020-2002-13 Null Expletives in Malay Amir Rashad Mustaffa [email protected] University of Malaya & University of Edinburgh ABSTRACT Malay is not known to have expletives due to their absence in the grammar, but this does not necessarily entail that expletives do not exist altogether. Gaps are observed in constructions with positions in which one would expect an expletive in a strictly non-pro-drop language such as English, hence making it seem as though Malay has a phonetically null variety of expletive. This phenomenon is common in attested pro-drop languages; however, data from Malay have not been properly documented and a principled account of the hypothesised existence of null expletives in Malay is lacking in the literature. This paper attempts to confirm whether Malay does have expletives by examining certain null-subject constructions through Chomsky’s (1982) Extended Projection Principle and comparing Malay with English and Irish. All cited examples in Malay are from the online archive of Utusan newspapers and those in Irish are from McCloskey (1991) and McCloskey (1996). All other examples are from consultants who are native speakers. It is found that Malay obeys the EPP, based on the obligatory movement of a subject into TP, which consequently makes it necessary for the use of a null expletive when no other constituent is able to raise to satisfy the EPP. The merging of a null expletive therefore creates an expletive-argument chain that causes the definiteness restriction in the existential construction, which can be overridden by substituting the expletive with clitic -nya on the verb. -

Old, Middle, and Early Modern Morphology and Syntax Through Texts
Old, Middle, and Early Modern Morphology and Syntax through Texts Elly van Gelderen 6 August 2016 1 Table of Contents List of Abbreviations Chapter 1 Introduction 1 The history of English in a nutshell 2 Functions and case 3 Verbal inflection and clause structure 4 Language change 5 Sources and resources 6 Conclusion Chapter 2 The Syntax of Old, Middle, and Early Modern English 1 Major Changes in the Syntax of English 2 Word Order 3 Inflections 4 Demonstratives, pronouns, and articles 5 Clause boundaries 6 Dialects in English 7 Conclusion Chapter 3 Old English Before 1100 1 The script 2 Historical prose narrative: Orosius 2 3 Sermon: Wulfstan on the Antichrist 4 Biblical gloss and translation: Lindisfarne, Rushworth, and Corpus Versions 5 Poetic monologue: the Wife’s Lament and the Wanderer 6 Conclusion Chapter 4 Early Middle English 1100‐1300 1 Historical prose narrative: Peterborough Chronicle 2 Prose Legend: Seinte Katerine 3 Debate poetry: The Owl and the Nightingale 4 Historical didactic poetry: Physiologus (Bestiary) 5 Prose: Richard Rolle’s Psalter Preface 6 Conclusion Chapter 5 Late Middle English and Early Modern 1300‐1600 1 Didactic poem: Cleanness 2 Instructional scientific prose: Chaucer’s Astrolabe 3 Religious: Margery of Kempe 4 Romance: Caxton 5 Chronicle and letters: Henry Machyn and Queen Elizabeth 6 Conclusion Chapter 6 Conclusion Appendix I Summary of all grammatical information 3 Appendix II Background on texts Appendix III Keys to the exercises Bibliography Glossary 4 Preface This book examines linguistic characteristics of English texts by studying manuscript images. I divide English into Old English, before 1100 but excluding runic inscriptions; Early Middle English, between 1100 and 1300; Late Middle English, between 1300 and 1500; and Early Modern English, after 1500.