Totem: Domain-Specific Reconfigurable Logic
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
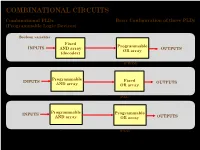
COMBINATIONAL CIRCUITS Combinational Plds Basic Configuration of Three Plds (Programmable Logic Devices)
COMBINATIONAL CIRCUITS Combinational PLDs Basic Configuration of three PLDs (Programmable Logic Devices) Boolean variables Fixed Programmable INPUTS AND array OUTPUTS OR array (decoder) Programmable Read-Only Memory (PROM) Programmable INPUTS Fixed OUTPUTS AND array OR array Programmable Array Logic (PAL) Programmable INPUTS Programmable AND array OR array OUTPUTS (Field) Programmable Logic Array (PLA) 1 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs Two-level AND-OR Arrays (Programmable Logic Devices) F (C,B, A) = CBA + CB A A AND B + V B C A C B F C F AND F + V 1 B OR C Multiple functions Simplified equivalent circuit for two-level AND-OR array 2 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs Field-programmable AND and OR Arrays (Programmable Logic Devices) Field-programmable logic elements are devices that contain uncommitted AND/OR arrays that are (programmed) configured by the designer. + V + V A A F (C,B, A) F (C,B, A) = CBA B B C C Unprogrammed AND array Fuse can be "blown" by passing a high current through it. 3 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs Field-programmable AND and OR Arrays (Programmable Logic Devices) F (P1 ,P2 ,P3 ) = P1 + P3 P1 P1 P2 P2 P3 P3 F F (P1 ,P2 ,P3 ) Unprogrammed OR array Programmed OR array P1 P2 P3 P1 + P3 4 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs Output Polarity Options (Programmable Logic Devices) I1 Ik Active high Active low Complementary outputs Programmable polarity P P 1 m + V 5 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs Bidirectional Pins and Feed back Lines (Programmable Logic Devices) I1 Ik Feedback IOm Three-state driver 6 ©Loberg COMBINATIONAL CIRCUITS Combinational PLDs PLA (Programmable Logic Array) (Programmable Logic Devices) If we use ROM to implement the Boolean function we will waste the silicon area. -

VLSI Design: a New Approach
International Journal of Information Theory Volume 1, Issue 1, 2011, pp-01-04 Available online at: http://www.bioinfo.in/contents.php?id=103 VLSI Design: A New Approach M.B. Swami and V.P. Pawar Department of Physics/Electronics/Computer Science, Maharashtra Udyagiri Mahavidyalaya, Udgir, India e-mail: [email protected] Abstract—This paper presents the different • Cores such as PCI are available and able to Programmable Logic Array is an important building circuit integrate with relative ease Getting started in of VLSI chips and some of the FPGA architectures have FPGA design is easy. evolved from the basic Programmable Logic Array The tools are cheap (and sometimes free) for low- architectures. In this paper the new concepts of Verilog Hardware Description language is included in VLSI Design. end devices and affordable for the high end. Modern Keywords: Programmable Logic Array, FPGA, Verilog. HDL (hardware design language) environments are very powerful for creating and verifying a design. There I. INTRODUCTION is plenty of documentation available for using different vendor’s FPGA design tools and exploiting features of Very-large-scale integration (VLSI) is the process of different FPGAs. creating integrated circuits by combining thousands of Even with modern tools, the fundamentals of transistor-based circuits into a single chip. digital design still remain intact and must be Implementation is based on FPGA design flow with understood. If the fundamentals are ignored, there is a Xilinx tools which will help you to design complex good chance that your design will not work consistently digital systems using HDL and also to get experience of and will probably exhibit intermittent modes of processor and controller implementations on FPGAs. -

Introduction to ASIC Design
’14EC770 : ASIC DESIGN’ An Introduction Application - Specific Integrated Circuit Dr.K.Kalyani AP, ECE, TCE. 1 VLSI COMPANIES IN INDIA • Motorola India – IC design center • Texas Instruments – IC design center in Bangalore • VLSI India – ASIC design and FPGA services • VLSI Software – Design of electronic design automation tools • Microchip Technology – Offers VLSI CMOS semiconductor components for embedded systems • Delsoft – Electronic design automation, digital video technology and VLSI design services • Horizon Semiconductors – ASIC, VLSI and IC design training • Bit Mapper – Design, development & training • Calorex Institute of Technology – Courses in VLSI chip design, DSP and Verilog HDL • ControlNet India – VLSI design, network monitoring products and services • E Infochips – ASIC chip design, embedded systems and software development • EDAIndia – Resource on VLSI design centres and tutorials • Cypress Semiconductor – US semiconductor major Cypress has set up a VLSI development center in Bangalore • VDAT 2000 – Info on VLSI design and test workshops 2 VLSI COMPANIES IN INDIA • Sandeepani – VLSI design training courses • Sanyo LSI Technology – Semiconductor design centre of Sanyo Electronics • Semiconductor Complex – Manufacturer of microelectronics equipment like VLSIs & VLSI based systems & sub systems • Sequence Design – Provider of electronic design automation tools • Trident Techlabs – Power systems analysis software and electrical machine design services • VEDA IIT – Offers courses & training in VLSI design & development • Zensonet Technologies – VLSI IC design firm eg3.com – Useful links for the design engineer • Analog Devices India Product Development Center – Designs DSPs in Bangalore • CG-CoreEl Programmable Solutions – Design services in telecommunications, networking and DSP 3 Physical Design, CAD Tools. • SiCore Systems Pvt. Ltd. 161, Greams Road, ... • Silicon Automation Systems (India) Pvt. Ltd. ( SASI) ... • Tata Elxsi Ltd. -

The Basics of Logic Design
C APPENDIX The Basics of Logic Design C.1 Introduction C-3 I always loved that C.2 Gates, Truth Tables, and Logic word, Boolean. Equations C-4 C.3 Combinational Logic C-9 Claude Shannon C.4 Using a Hardware Description IEEE Spectrum, April 1992 Language (Shannon’s master’s thesis showed that C-20 the algebra invented by George Boole in C.5 Constructing a Basic Arithmetic Logic the 1800s could represent the workings of Unit C-26 electrical switches.) C.6 Faster Addition: Carry Lookahead C-38 C.7 Clocks C-48 AAppendixC-9780123747501.inddppendixC-9780123747501.indd 2 226/07/116/07/11 66:28:28 PPMM C.8 Memory Elements: Flip-Flops, Latches, and Registers C-50 C.9 Memory Elements: SRAMs and DRAMs C-58 C.10 Finite-State Machines C-67 C.11 Timing Methodologies C-72 C.12 Field Programmable Devices C-78 C.13 Concluding Remarks C-79 C.14 Exercises C-80 C.1 Introduction This appendix provides a brief discussion of the basics of logic design. It does not replace a course in logic design, nor will it enable you to design signifi cant working logic systems. If you have little or no exposure to logic design, however, this appendix will provide suffi cient background to understand all the material in this book. In addition, if you are looking to understand some of the motivation behind how computers are implemented, this material will serve as a useful intro- duction. If your curiosity is aroused but not sated by this appendix, the references at the end provide several additional sources of information. -

RESEARCH INSIGHTS – Hardware Design: FPGA Security Risks
RESEARCH INSIGHTS Hardware Design: FPGA Security Risks www.nccgroup.trust CONTENTS Author 3 Introduction 4 FPGA History 6 FPGA Development 10 FPGA Security Assessment 12 Conclusion 17 Glossary 18 References & Further Reading 19 NCC Group Research Insights 2 All Rights Reserved. © NCC Group 2015 AUTHOR DUNCAN HURWOOD Duncan is a senior consultant at NCC Group, specialising in telecom, embedded systems and application review. He has over 18 years’ experience within the telecom and security industry performing almost every role within the software development cycle from design and development to integration and product release testing. A dedicated security assessor since 2010, his consultancy experience includes multiple technologies, languages and platforms from web and mobile applications, to consumer devices and high-end telecom hardware. NCC Group Research Insights 3 All Rights Reserved. © NCC Group 2015 GLOSSARY AES Advanced encryption standard, a cryptography OTP One time programmable, allowing write once cipher only ASIC Application-specific integrated circuit, non- PCB Printed circuit board programmable hardware logic chip PLA Programmable logic array, forerunner of FPGA Bitfile Binary instruction file used to program FPGAs technology CLB Configurable logic block, an internal part of an PUF Physically unclonable function FPGA POWF Physical one-way function CPLD Complex programmable logic device PSoC Programmable system on chip, an FPGA and EEPROM Electronically erasable programmable read- other hardware on a single chip only memory -

Full-Custom Ics Standard-Cell-Based
Full-Custom ICs Design a chip from scratch. Engineers design some or all of the logic cells, circuits, and the chip layout specifi- cally for a full-custom IC. Custom mask layers are created in order to fabricate a full-custom IC. Advantages: complete flexibility, high degree of optimization in performance and area. Disadvantages: large amount of design effort, expensive. 1 Standard-Cell-Based ICs Use predesigned, pretested and precharacterized logic cells from standard-cell li- brary as building blocks. The chip layout (defining the location of the building blocks and wiring between them) is customized. As in full-custom design, all mask layers need to be customized to fabricate a new chip. Advantages: save design time and money, reduce risk compared to full-custom design. Disadvantages: still incurs high non-recurring-engineering (NRE) cost and long manufacture time. 2 D A B C A B B D C D A A B B Cell A Cell B Cell C Cell D Feedthrough Cell Standard-cell-based IC design. 3 Gate-Array Parts of the chip are pre-fabricated, and other parts are custom fabricated for a particular customer’s circuit. Idential base cells are pre-fabricated in the form of a 2-D array on a gate-array (this partially finished chip is called gate-array template). The wires between the transistors inside the cells and between the cells are custom fabricated for each customer. Custom masks are made for the wiring only. Advantages: cost saving (fabrication cost of a large number of identical template wafers is amortized over different customers), shorter manufacture lead time. -

CPLD and FPGA Architectures
ECE 428 Programmable ASIC Design CPLD and FPGA Architectures Haibo Wang ECE Department Southern Illinois University Carbondale, IL 62901 3-1 Definitions Field Programmable Device (FPD): — a general term that refers to any type of integrated circuit used for implementing digital hardware, where the chip can be configured by the end user to realize different designs. Programming of such a device often involves placing the chip into a special programming unit, but some chips can also be configured “in-system”. Another name for FPDs is programmable logic devices (PLDs). Source: S. Brown and J. Rose, FPGA and CPLD Architectures: A Tutorial, IEEE Design and Test of Computer, 1996 3-2 Classifications PLA — a Programmable Logic Array (PLA) is a relatively small FPD that contains two levels of logic, an AND- plane and an OR-plane, where both levels are programmable PAL — a Programmable Array Logic (PAL) is a relatively small FPD that has a programmable AND-plane followed by a fixed OR-plane SPLD — refers to any type of Simple PLD, usually either a PLA or PAL CPLD — a more Complex PLD that consists of an arrangement of multiple SPLD-like blocks on a single chip. FPGA — a Field-Programmable Gate Array is an FPD featuring a general structure that allows very high logic capacity. 3-3 PLA Programmable AND Plane Programmable OR Plane Programmable Node Un-programmed Connect Disconnect X Y O1 O2 O3 O4 X XY Y XY XY XY XX YY 3-4 PLA Programmable AND Plane Programmable OR Plane YZ XZ XYZ XY XY Z XY+YZ ?? XZ+XYZ 3-5 PAL Programmable AND Plane Fix OR Plane X Y O1 O2 O3 O4 3-6 PAL with Logic Expanders Programmable AND Plane Fix OR Plane ? Logic expanders 3-7 PLA v.s. -

Logic Directory Programmable
coverstory By Brian Dipert, Technical Editor Programmable-Programmable- he umbrella term “logic devices” subdivides into several categories: discrete logic, simple and logiclogic Tcomplex PLDs, FPGAs, and standard- and cus- tom-cell ASICs. FPGAs, SPLDs/PALs, and CPLDs are all programmable-logic devices, although their inter- nal architecture implementations differ. Programmable-logic devices are the fastest growing segment of the logic-device family, for two funda- directorydirectory mental reasons. For one thing, their ever-increasing per-device logic-gate count “gathers up”functions that might otherwise spread over a number of discrete-log- ic and memory chips, improving end-system size, power consumption, performance, reliability, and cost. Equally important, you can in a matter of seconds or THE SECOND ANNUAL EDN PLD minutes configure and, in many cases, reconfigure these devices at your workstation or in the system-as- DIRECTORY HIGHLIGHTS THE sembly line. This capability provides powerful flexi- bility to react to last-minute design changes, to pro- ARCHITECTURES AVAILABLE FOR YOUR totype ideas before implementation, and to meet time-to-market deadlines driven by both customer NEXT DESIGN. FIND OUT WHAT’S NEW, need and competitive pressures. Programmable-logic devices lack the long lead- WHAT’S OBSOLETE, AND WHAT’S times, up-front NRE charges, minimum-order quan- tities, and inventory complexity of ASICs. As per-gate EVOLVEDEVOLVED ININ PALS,PALs, PLDS,PLDS, ANDAND FPGAFPGAS.S. cost decreases and the number of gates per component increases, programmable-logic devices are making sig- nificant inroads into gate-array-ASIC territory. Sys- AND CHECK THIS OUT: tem designers and manufacturers are only beginning WE’VE POSTED COMPREHENSIVE to explore and exploit in-system reprogrammability, either to correct errors and upgrade functions once the TABLES OF DEVICES AND FEATURES end system is in users’ hands or to use a fixed number IN THE WEB VERSION OF THIS of logic gates to implement multiple functions. -

Ch7. Memory and Programmable Logic
EEA091 - Digital Logic 數位邏輯 Chapter 7 Memory and Programmable Logic 吳俊興 國立高雄大學 資訊工程學系 2006 Chapter 7 Memory and Programmable Logic 7-1 Introduction 7-2 Random-Access Memory 7-3 Memory Decoding 7-4 Error Detection and Correction 7-5 Read-Only Memory 7-6 Programmable Logic Array 7-7 Programmable Array Logic 7-8 Sequential Programmable Devices 7-1 Introduction • Memory unit –a collection of cells capable of storing a large quantity of binary information and • to which binary information is transferred for storage • from which information is available when needed for processing –together with associated circuits needed to transfer information in and out of the device • write operation: storing new information into memory • read operation: transferring the stored information out of the memory • Two major types –RAM (Random-access memory): Read + Write • accept new information for storage to be available later for use –ROM (Read-only memory): perform only read operation Programmable Logic Device •Programmable logic device (PLD) –an integrated circuit with internal logic gates • hundreds to millions of gates interconnected through hundreds to thousands of internal paths –connected through electronic paths that behave similar to fuse • In the original state, all the fuses are intact –programming the device • blowing those fuse along the paths that must be removed in order to obtain particular configuration of the desired logic function •Types –Read-only Memory (ROM, Section 7-5) –programmable logic array (PLA, Section 7-6) –programmable array -

A Cost- Effective Design of Reversible Programmable Logic Array
International Journal of Computer Applications (0975 – 8887) Volume 41– No.15, March 2012 A Cost- Effective Design of Reversible Programmable Logic Array Pradeep Singla Naveen Kr. Malik M.Tech Scholer Assistant Professor Hindu College of Engineering Hindu College of Engineering Sonipat, India Sonipat, India ABSTRACT portable systems exhaust their batteries. Now a day‟s digital In the recent era, Reversible computing is a growing field circuit dissipates even more energy than the theoretical [12]. having applications in nanotechnology, optical information Even C.H. Bennett in 1973 also showed that the dissipated processing, quantum networks etc. In this paper, the authors energy directly correlated to the number of lost bits [2]. So, show the design of a cost effective reversible programmable there is an alternative is to use logic operations that do not lost logic array using VHDL. It is simulated on Xilinx ISE 8.2i bits during computation. These are called reversible logic and results are shown. The proposed reversible Programming operations, and in principle they dissipate arbitrarily little heat logic array called RPLA is designed by MUX gate & [5] [6]. Feynman gate for 3- inputs, which is able to perform any The idea of reversible computing comes from the reversible 3- input logic function or Boolean function. thermodynamics which taught us the benefits of the reversible Furthermore the quantized analysis with comparative finding process over irreversible process. So, it is called reversible is shown for the realized RPLA against the existing one. The computing if its inputs can always be retrieved from its result shows improvement in the quantum cost and total outputs [3] [4] [5] [6]. -

Nasa Handbook Nasa-Hdbk 8739.23A Measurement
NASA HANDBOOK NASA-HDBK 8739.23A National Aeronautics and Space Administration Approved: 02-02-2016 Washington, DC 20546 Superseding: NASA-HDBK-8739.23 With Change 1 NASA COMPLEX ELECTRONICS HANDBOOK FOR ASSURANCE PROFESSIONALS MEASUREMENT SYSTEM IDENTIFICATION: METRIC APPROVED FOR PUBLIC RELEASE – DISTRIBUTION IS UNLIMITED NASA-HDBK 8739.23A—2016-02-02 Mars Exploration Rover (2003) 2 of 161 NASA-HDBK 8739.23A—2016-02-02 DOCUMENT HISTORY LOG Document Status Approval Date Description Revision Initial Release Baseline 2011-02-16 (JWL4) Editorial correction to page 2 figure caption Change 1 2011-03-29 (JWL4) Significant changes were made in this revision, including: expanded content; reflected terminology and technology from the NASA-HDBK-4008, Programmable Revision A 2016-02-02 Logic Devices (PLD) Handbook (released in 2013); eliminated duplication with the PLD Handbook; and, incorporated other clarifications and corrections. (MW) 3 of 161 NASA-HDBK 8739.23A—2016-02-02 This page intentionally left blank. 4 of 161 NASA-HDBK 8739.23A—2016-02-02 This page intentionally left blank. 6 of 161 NASA-HDBK 8739.23A—2016-02-02 TABLE OF CONTENTS 1 OVERVIEW ................................................................................................................ 12 1.1 Purpose .......................................................................................................................... 12 1.2 Scope ............................................................................................................................. 12 1.3 Anticipated -

UNIT-III Design of Combinational Circuits Using Programmable Logic Devices (Plds)
UNIT-III Design of combinational circuits using Programmable Logic Devices (PLDs) PLA- Programmable logic array: • The PLA consists of two programmable planes AND and OR . The AND plane consists of programmable interconnect along with AND gates. • The OR plane consists of programmable interconnect along with OR gates. • Each of the inputs can be connected to an AND gate with any of the other inputs by connecting the crossover point of the vertical and horizontal interconnect lines in the AND gate programmable interconnect. • Initially, the crossover points are not electrically connected, but configuring the PLA will connect particular cross over points together. • The AND gate is seen with a single line to the input. This view is by convention, but this also means that any of the inputs (vertical lines) can be connected. Hence, for four PLA inputs, the AND gate also has four inputs. The single output from each of the AND gates is applied to an OR gate programmable inter connect. EXAMPLES: Steps to program PLA: Step I: Find the Boolean Function from the truth table. A B C Y1 Y2 0 0 0 0 0 0 0 1 0 0 0 1 0 0 1 0 1 1 1 0 1 0 0 0 0 1 0 1 1 1 1 1 0 0 0 1 1 1 1 1 Y1=AC+BC Y2=AC+A’BC’ STEP II: Identify the number of input buffers. Number of variables=number of input buffers=3. STEP III: Implementation of the Boolean function in PLA. PROGRAMMABLE ARRAY LOGIC (PAL) • The first programmable device was the programmable array logic (PAL) developed by Monolithic Memories Inc(MMI).