Download from and Is Required to Run the Island Generator Program
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Re-Awakening Languages: Theory and Practice in the Revitalisation Of
RE-AWAKENING LANGUAGES Theory and practice in the revitalisation of Australia’s Indigenous languages Edited by John Hobson, Kevin Lowe, Susan Poetsch and Michael Walsh Copyright Published 2010 by Sydney University Press SYDNEY UNIVERSITY PRESS University of Sydney Library sydney.edu.au/sup © John Hobson, Kevin Lowe, Susan Poetsch & Michael Walsh 2010 © Individual contributors 2010 © Sydney University Press 2010 Reproduction and Communication for other purposes Except as permitted under the Act, no part of this edition may be reproduced, stored in a retrieval system, or communicated in any form or by any means without prior written permission. All requests for reproduction or communication should be made to Sydney University Press at the address below: Sydney University Press Fisher Library F03 University of Sydney NSW 2006 AUSTRALIA Email: [email protected] Readers are advised that protocols can exist in Indigenous Australian communities against speaking names and displaying images of the deceased. Please check with local Indigenous Elders before using this publication in their communities. National Library of Australia Cataloguing-in-Publication entry Title: Re-awakening languages: theory and practice in the revitalisation of Australia’s Indigenous languages / edited by John Hobson … [et al.] ISBN: 9781920899554 (pbk.) Notes: Includes bibliographical references and index. Subjects: Aboriginal Australians--Languages--Revival. Australian languages--Social aspects. Language obsolescence--Australia. Language revival--Australia. iv Copyright Language planning--Australia. Other Authors/Contributors: Hobson, John Robert, 1958- Lowe, Kevin Connolly, 1952- Poetsch, Susan Patricia, 1966- Walsh, Michael James, 1948- Dewey Number: 499.15 Cover image: ‘Wiradjuri Water Symbols 1’, drawing by Lynette Riley. Water symbols represent a foundation requirement for all to be sustainable in their environment. -

MIGRATION ACTION Working with Interpreters
/ MIGRATION ACTION LIBRARY Vol. XVIII, Number 1 BROTHER' I00D GF ST. LA0EL1CE May, 1996 67 BRUNSWICK STREET FITZROY VICTORIA 3065 Working with Interpreters ( \ '.Ati'T (JNPZRSTAtiD A L O O F D YOU'RE SAil^KS UJHlCH M£AN$: I NE£P HBLP 74HPB&3S Interpreting and Translating Services in Australia Books from the CHOMI Bookshop New Translators Through History RRP: $45.00 edited and directed by Jean Delisle and Judith Woodsworth, 1996 New InterculturalCommunication: Pragmatics, Genealogy, Deconstruction RRP: $26.95 by Robert Young, 1996 New Liaison interpreting: a Handbook RRP: $24.95 by Adolfo Gentile, Uldis Ozlins and Mary Vasilakakos,1996 New The Politics of Language in Australia RRP: $36.95 by Uldis Ozlins, 1993 New 24 Hours RRP: $45.00 by n.O., 1995 B649 Interpreters and the Legal System RRP: $35.00 by Kathy Laster & Veronica Taylor, 1994 B669 Speaking of Speaking RRP: $20.00 by Maree Pardy, 1995 B702 Housing and Refugee Women Research Report RRP: $10.00 by Sherron Dunbar, 1995 B715 Teaching for Justice in the Age of Good Universities Guide: a working RRP: $12.00 paper by Les Terry, 1995 B726 Improving Intercultural Interactions: Modules for Cross-cultural Training RRP: $39.95 Program s edited by Richard W. Brislin and Tomoko Yoshida, 1994 B727 Assessing and Treating Culturally Diverse Clients: a Practical Guide RRP: $29.95 by Freddy A. Paniagua, 1994 B729 Emma: a Recipe for life RRP: $24.95 by Emma Ciccotosto and Michal Bosworth, 1995 B730 Judaism in Australia RRP: $8.95 by W.D. Rubinstein, 1995 B731 The General Langfitt Story: Polish Refugees Recount their Experiences of RRP: $14.95 exile, dispersal and resettlement by Mary on Allbrook and Helen Cattalini, 1995 B732 Racism and Criminology RRP:$38.95 Dee Cook and Barbara Hudson, 1993 Purchases from the CHOMI bookshop may be made by calling the EMC on Ph.(03) 9416 0044 or Fax(03) 9416 1827 or by using the enclosed order form. -

Mapping the Language – How a Dying Language Loses Its Place in the World
Mapping the language – how a dying language loses its place in the world Dorothea Hoffmann Argue Department of Linguistics, Faculty of the Humanities University of Chicago Abstract This paper is concerned with documenting critically endangered and culturally significant aspects of spatial language in MalakMalak, a non- Pama-Nyungan Northern Daly language with eleven identified remaining speakers based in the Daly River Region in Australia. The documentation combines current speaker knowledge collected in fieldwork settings between 2012 and 2013 with historical recordings (Birk, 1971-1973) to identify such areas of knowledge that have been lost over time. As a result, this paper focuses on the intricate relationship between language, culture, landscape, and tradition in the absence of customary community life. It asks whether or not aspects of language may ever be fully documented when speakers no longer live in traditional areas practicing customary cultural life. Keywords: language endangerment, Australian Indigenous languages, spatial language, language documentation, MalakMalak 1. Introduction Naming, travelling, and ‘singing’ the land is of very high significance to the culture in indigenous Australia. In traditional mythological dreamtime narratives the ancestral beings travel the country to give it form and identity (Myers, 1986: 49-50). In the customary lifestyle of hunting and gathering high significance was placed on using highly specific spatial language and intricate knowledge of toponyms and landscape features. It is not surprising that therefore, as observed for other Australian languages such as Gurindji (Meakins, 2011), Jaminjung (Schultze-Berndt, 2006), Arrernte (Wilkins, 2006), Warrwa (McGregor, 2006), Guugu Yimithirr (Haviland, 1993), Kriol (Hoffmann, 2012) and many others, spatial absolute and deictic systems in MalakMalak are a highly significant part of the languages’ grammar and underlying cognitive system (Hoffmann, under review/2013). -

Information Bulletin
Information Bulletin Ministry of Health, NSW 73 Miller Street North Sydney NSW 2060 Locked Mail Bag 961 North Sydney NSW 2059 Telephone (02) 9391 9000 Fax (02) 9391 9101 http://www.health.nsw.gov.au/policies/ space space Country of Birth and Preferred Language Classification Codeset Updates - Effective 1 July 2017 space Document Number IB2017_007 Publication date 24-Feb-2017 Functional Sub group Corporate Administration - Information and data Clinical/ Patient Services - Information and data Summary This Information Bulletin advises of updates to the NSW Country of Birth and Preferred Language codesets for the purposes of admitted patient, emergency department and other client registration data collections across NSW. Author Branch Health System Information & Performance Reporting Branch contact Health System Information & Performance 0293919388 Applies to Local Health Districts, Board Governed Statutory Health Corporations, Specialty Network Governed Statutory Health Corporations, Ministry of Health, Public Hospitals Audience Data collection units, patient administration system manager/developers, health information managers Distributed to Public Health System, Ministry of Health Review date 24-Feb-2022 Policy Manual Not applicable File No. 16/4437 Status Active Director-General INFORMATION BULLETIN COUNTRY OF BIRTH AND PREFERRED LANGUAGE CLASSIFICATION CODESET UPDATES – EFFECTIVE 1 JULY 2017 PURPOSE The purpose of this Information Bulletin is to inform NSW Health service providers and source system administrators of changes to the classification and code set standards for Country of Birth and Preferred language. The revised codesets are applicable for the Client Contact Data Stream, and all data collections and data streams which contain the relevant data items. KEY INFORMATION As of 1 July 2017, two classifications are being updated with revisions to the current NSW Health codesets: Country of Birth and Preferred Language. -

Production and Perception of Stop Consonants in Spanish, Quichua, and Media Lengua by Jesse Stewart a Thesis Submitted to the F
Production and perception of stop consonants in Spanish, Quichua, and Media Lengua by Jesse Stewart A Thesis submitted to the Faculty of Graduate Studies of The University of Manitoba in partial fulfilment of the requirements of the degree of DOCTOR OF PHILOSOPHY Department of Linguistics University of Manitoba Winnipeg Copyright © 2015 by Jesse Stewart Abstract This dissertation explores the phonetics and phonology of language contact, specifically pertaining to the integration of Spanish voiced stops /b/, /d/, and /g/ into Quichua, a language with non-contrastive stop voicing. Conflicting areas of convergence of this type appear when two or more phonological systems interact and phonemes from the target language are unknown natively to speakers of the source language. Media Lengua is a mixed language with an agglutinating Quichua morphology, and Quichua syntactic and phonological systems where nearly all the native Quichua vocabulary has been replaced by Spanish. This extreme contact scenario has integrated the voiced stop series into Media Lengua and abundant minimal pairs are present. If the phonological system of Media Lengua is indeed of Quichua origin however, how have speakers integrated the voiced stop series productively and perceptually? Have they adopted different strategies from Quichua speakers? If so, how do they differ? Chapter 1 sets the scene with an in-depth description of how contact between Spanish and Quichua has mutually influenced each language at the morphosyntactic level. Chapter 2 explores voice onset time (VOT) production in all five language varieties. Statistical modeling is used to search for differences in duration while taking into account a number of linguistic and demographic factors. -

International Marketing Projectанаaustralia
International Marketing Project Australia Neil Bastendorff Crater School of Business May 22, 2016 Neil Bastendorff Australia Table of Contents Introduction …………………………………………………………………………………………………2 Issue …………………………………………………………………………………………………3 Nonprofit …………………………………………………………………..……………………………..4 Geographical Area Analysis …………………………………………………………………………………………………6 Economic Analysis Part 1 …………………………………………………………………………………………………8 Economic Analysis Part 2 ……………………………………………………………………………………..…………11 Political System ………………………………………………………………………………....……………..15 Trade Laws and Legal Analysis ………………………………………………………………………………………..………18 Population …………………………………………………………………………………………..……19 Diet and Nutrition …………………………………………………………………………………..……………22 Housing …………………………………………………………………………………..……………24 Transportation ………………………………………………………………………………………..………28 Labor ………………………………………………………………………………………..………30 Education ………………………………………………………………………………………..………31 Clothing ………………………………………………………………………………………..………33 Recreation and Leisure ………………………………………………………………………………………………..35 Language ……………………………………………………………………………………..…………37 Religion ……………………………………………………………………………………..…………39 Bibliography ………………………………………………………………………………………..………40 Appendix ………………………………………………………………………………………..………41 1 Neil Bastendorff Australia Introduction About the Country The Commonwealth of Australia became a nation independent of Great Britain on January 1st, 1901. This day became known as Federation Day, when the British Parliament passed legislation that allowed the six colonies of Australia to govern in their -

A Linguistic Bibliography of Aboriginal Australia and the Torres Strait Islands
OZBIB: a linguistic bibliography of Aboriginal Australia and the Torres Strait Islands Dedicated to speakers of the languages of Aboriginal Australia and the Torres Strait Islands and al/ who work to preserve these languages Carrington, L. and Triffitt, G. OZBIB: A linguistic bibliography of Aboriginal Australia and the Torres Strait Islands. D-92, x + 292 pages. Pacific Linguistics, The Australian National University, 1999. DOI:10.15144/PL-D92.cover ©1999 Pacific Linguistics and/or the author(s). Online edition licensed 2015 CC BY-SA 4.0, with permission of PL. A sealang.net/CRCL initiative. PACIFIC LINGUISTICS FOUNDING EDITOR: Stephen A. Wurm EDITORIAL BOARD: Malcolm D. Ross and Darrell T. Tryon (Managing Editors), John Bowden, Thomas E. Dutton, Andrew K. Pawley Pacific Linguistics is a publisher specialising in linguistic descriptions, dictionaries, atlases and other material on languages of the Pacific, the Philippines, Indonesia and Southeast Asia. The authors and editors of Pacific Linguistics publications are drawn from a wide range of institutions around the world. Pacific Linguistics is associated with the Research School of Pacific and Asian Studies at The Australian NatIonal University. Pacific Linguistics was established in 1963 through an initial grant from the Hunter Douglas Fund. It is a non-profit-making body financed largely from the sales of its books to libraries and individuals throughout the world, with some assistance from the School. The Editorial Board of Pacific Linguistics is made up of the academic staff of the School's Department of Linguistics. The Board also appoints a body of editorial advisors drawn from the international community of linguists. -

The Vowel Inventory of Roper Kriol
THE VOWEL INVENTORY OF ROPER KRIOL Rikke Bundgaard-Nielsen Brett Baker MARCS Institute, University of Western Sydney/La Trobe University, University of Melbourne [email protected], [email protected] ABSTRACT monophthongs with an additional duration contrast, Despite being the largest Indigenous Australian and a number of diphthongs (at least /ei/, /ai/, /oi/, language, Kriol—an English-lexified creole spoken /ou/); not reported on here). We argue that Kriol has across the northern part of Australia—is still largely maintained a substrate-like five-vowel inventory, but unexamined from an instrumental or phonological also used a duration contrast as a means of doubling point of view. This hampers efforts to predict cross- the number of contrastive elements usually found in linguistic difficulties experienced by Kriol speakers Australian languages. We propose that the Kriol in English-language settings and crucially in vowel inventory developed into this 'five-vowel predicting the difficulties that Kriol-speaking system with a duration contrast' as a strategy to children face in learning Standard Australian maintain most of the quality contrasts in English. English. We report here on the vowel inventory of Kriol, which has previously been claimed to have 2. BACKGROUND between five and seven monophthongs and three or four diphthongs ([19],[20]). We show that its vowel The characteristic features of vowel systems of system is in fact a triangular five-vowel system, with Australian Indigenous languages are summarised in a duration contrast, and a number of diphthongs. [9]. Australian vowel systems tend to be small (3 This system thus reflects, in certain respects, typical qualities is typical), and the vowel space relatively inventories of the Indigenous substrate languages, restricted, compared to many other languages, except that, by radically increasing the number of including English. -
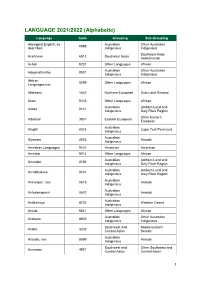
Language List
LANGUAGE 2021/2022 (Alphabetic) Language Code Grouping Sub-Grouping Aboriginal English, so Australian Other Australian 8998 described Indigenous Indigenous Southeast Asian Acehnese 6513 Southeast Asian Austronesian Acholi 9201 Other Languages African Australian Other Australian Adnymathanha 8901 Indigenous Indigenous African 9299 Other Languages African Languages,nec Afrikaans 1403 Northern European Dutch and Related Akan 9203 Other Languages African Australian Arnhem Land and Alawa 8121 Indigenous Daly River Region Other Eastern Albanian 3901 Eastern European European Australian Alngith 8315 Cape York Peninsula Indigenous Australian Alyawarr 8603 Arandic Indigenous American Languages 9101 American American Amharic 9214 Other Languages African Australian Arnhem Land and Amurdak 8156 Indigenous Daly River Region Australian Arnhem Land and Anindilyakwa 8101 Indigenous Daly River Region Australian Anmatyerr, nec 8619 Arandic Indigenous Australian Antekerrepenh 8607 Arandic Indigenous Australian Antikarinya 8703 Western Desert Indigenous Anuak 9241 Other Languages African Australian Other Australian Arabana 8902 Indigenous Indigenous Southwest and Middle Eastern Arabic 4202 Central Asian Semitic Australian Arandic, nec 8699 Arandic Indigenous Southwest and Other Southwest and Armenian 4901 Central Asian Central Asian 1 Language Code Grouping Sub-Grouping Arnhem Land and Australian Arnhem Land and Daly River Region 8199 Indigenous Daly River Region Languages, nec Aromunian (Macedo- Other Eastern 3903 Eastern European Romanian) European Australian -

Stewart, Jesse--Dissertation
Production and perception of stop consonants in Spanish, Quichua, and Media Lengua by Jesse Stewart A Thesis submitted to the Faculty of Graduate Studies of The University of Manitoba in partial fulfilment of the requirements of the degree of DOCTOR OF PHILOSOPHY Department of Linguistics University of Manitoba Winnipeg Copyright © 2015 by Jesse Stewart Abstract This dissertation explores the phonetics and phonology of language contact, specifically pertaining to the integration of Spanish voiced stops /b/, /d/, and /g/ into Quichua, a language with non-contrastive stop voicing. Conflicting areas of convergence of this type appear when two or more phonological systems interact and phonemes from the target language are unknown natively to speakers of the source language. Media Lengua is a mixed language with an agglutinating Quichua morphology, and Quichua syntactic and phonological systems where nearly all the native Quichua vocabulary has been replaced by Spanish. This extreme contact scenario has integrated the voiced stop series into Media Lengua and abundant minimal pairs are present. If the phonological system of Media Lengua is indeed of Quichua origin however, how have speakers integrated the voiced stop series productively and perceptually? Have they adopted different strategies from Quichua speakers? If so, how do they differ? Chapter 1 sets the scene with an in-depth description of how contact between Spanish and Quichua has mutually influenced each language at the morphosyntactic level. Chapter 2 explores voice onset time (VOT) production in all five language varieties. Statistical modeling is used to search for differences in duration while taking into account a number of linguistic and demographic factors. -

An Introduction to the Australian National Corpus Project1
An Introduction to the Australian National Corpus Project 1 » SimON MUSGraVE In the last few years, a consensus has emerged from and newly collected samples together in one place researchers in various disciplines that a vital piece and provide tools to help researchers annotate, of research infrastructure is lacking in Australia, analyse and work collaboratively on this data. namely, a substantial collection of computerised The corpus will contain collections of: language data. A result of this consensus is • published texts from many genres an initiative aimed at the establishment of an • transcribed speech, often with Australian National Corpus. Australia’s language aligned audio files data resources at present remain scattered and • visual records of interaction (video) relatively inaccessible, and the Australian National • electronic texts including email, Corpus Initiative constitutes a sustained effort on blogs and social media. the part of linguists, applied linguists and language AusNC aims to illustrate Australian English in technologists to overcome this data inaccessibility all its variety: situational, social, generational, by establishing a massive online database of and ethnic; and to document languages other spoken and written language in Australia, in all than English used in Australia, including Auslan, its forms and diversity (audio files, written texts, and the community languages of immigrants. etc.). It represents a major expansion of Australia’s The corpus will be built from existing collections e-research infrastructure in the humanities and contributed by researchers from many disciplines; social sciences. The Australian National Corpus is these will be adapted as needed to allow them to being developed (currently with support from the be properly integrated into AusNC. -

Language Acquisition by Aboriginal Children and Educational Implications
What languages are Aboriginal children learning? Samantha Disbray, Patrick McConvell, Felicity Meakins, Karin Moses, Carmel O’Shannessy, Jane Simpson and Gillian Wigglesworth ACLA Project AIATSIS 18 October 2004 Communities and languages involved in the project Situation of languages Traditional Children’s Type Components Children’s Children’s Language First language passive active knowledge: proficiency: traditional traditional language language Warlpiri Light Warlpiri Mixed Warlpiri+ Good Moderate language Kriol Gurindji Gurindji Kriol Mixed Gurindji+ Moderate Low language Kriol Warumungu Aboriginal acrolectal (a few Low None English creole Warumungu forms) Walmajarri Kriol basilectal (a very few Low None creole Walmajarri forms) The effect of contact • Devaluation of traditional languages • Addition of new codes – Standard English and its associated range of written and spoken registers – Pidgin English – Kriol – Mixed Languages • Switching between codes Types of code Register: a language variety appropriate to a particular language situation e.g. formal or informal language Dialect: When a language L has two or more distinct forms which are associated with different regional or social or ethnic groups Language: a dialect or collection of dialects which cannot be understood and spoken by other people without considerable language learning effort Code-switching • When people talk with each other, they may use just one code throughout the conversation, or they may use different registers, dialects or languages in the same utterance or conversation. They may switch codes. How children learn codes • Input – from parents and caregivers – from playmates – from the media • Interpretation of input reconstructing rules of a code on the basis of the input Codes in contact • Pidgin: a simple code that develops as a means of communicating between speakers of two languages which are not mutually intelligible • Creole: a language which evolves when children hear a pidgin and develop it into a full language.