The Balinese Unicode Text Processing-02
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

From Arabic Style Toward Javanese Style: Comparison Between Accents of Javanese Recitation and Arabic Recitation
From Arabic Style toward Javanese Style: Comparison between Accents of Javanese Recitation and Arabic Recitation Nur Faizin1 Abstract Moslem scholars have acceptedmaqamat in reciting the Quran otherwise they have not accepted macapat as Javanese style in reciting the Quran such as recitationin the State Palace in commemoration of Isra` Miraj 2015. The paper uses a phonological approach to accents in Arabic and Javanese style in recitingthe first verse of Surah Al-Isra`. Themethod used here is analysis of suprasegmental sound (accent) by usingSpeech Analyzer programand the comparison of these accents is analyzed by descriptive method. By doing so, the author found that:first, there is not any ideological reason to reject Javanese style because both of Arabic and Javanese style have some aspects suitable and unsuitable with Ilm Tajweed; second, the suitability of Arabic style was muchthan Javanese style; third, it is not right to reject recitingthe Quran with Javanese style only based on assumption that it evokedmistakes and errors; fourth, the acceptance of Arabic style as the art in reciting the Quran should risedacceptanceof the Javanese stylealso. So, rejection of reciting the Quranwith Javanese style wasnot due to any reason and it couldnot be proofed by any logical argument. Keywords: Recitation, Arabic Style, Javanese Style, Quran. Introduction There was a controversial event in commemoration of Isra‘ Mi‘raj at the State Palacein Jakarta May 15, 2015 ago. The recitation of the Quran in the commemoration was recitedwithJavanese style (langgam).That was not common performance in relation to such as official event. Muhammad 58 Nur Faizin, From Arabic Style toward Javanese Style Yasser Arafat, a lecture of Sunan Kalijaga State Islamic University Yogyakarta has been reciting first verse of Al-Isra` by Javanese style in the front of state officials and delegationsof many countries. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
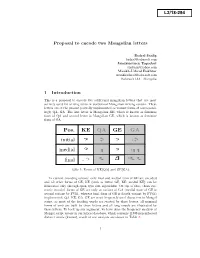
Pos. KE QA GE GA Initial ᠬ ᠭ Medial Final
Proposal to encode two Mongolian letters Badral Sanlig [email protected] Jamiyansuren Togoobat [email protected] Munkh-Uchral Enkhtur [email protected] Bolorsoft LLC, Mongolia 1 Introduction This is a proposal to encode two additional mongolian letters that are most actively used for writing texts in traditional Mongolian writing system. These letters are at the present partially implemented as variant forms of correspond- ingly QA, GA. The first letter is Mongolian KE, which is known as feminine form of QA and second letter is Mongolian GE, which is known as feminine form of GA. Pos. KE QA GE GA ᠬ ᠭ initial medial final - Table 1: Forms of KE(QA) and GE(GA). In current encoding scheme, only final and medial form of GE are encoded and all other forms of GE, KE (such as initial GE, KE, medial KE) can be illustrated only through open type font algorithms. On top of that, those cur- rently encoded forms of GE are only as variant of GA (medial form of GE is second variant by FVS1, whereas final form of GE is fourth variant by FVS3) implemented. QA, KE, GA, GE are most frequently used characters in Mongol script, as most of the heading words are started by these letters, all nominal forms of verb are built by these letters and all long vowels are illustrated by these letters. To back up our argument, we have done the frequency analysis of Mongol script letters in our lexical database, which contains 41808 non-inflected distinct words (lemma), result of our analysis are shown in Table 2. -

Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-04-22 Document version: 2.7 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract This document lays down the Label Generation Ruleset for Gurmukhi script. Three main components of the Gurmukhi Script LGR i.e. Code point repertoire, Variants and Whole Label Evaluation Rules have been described in detail here. All these components have been incorporated in a machine-readable format in the accompanying XML file named "proposal-gurmukhi-lgr-22apr19-en.xml". In addition, a document named “gurmukhi-test-labels-22apr19-en.txt” has been provided. It provides a list of labels which can produce variants as laid down in Section 6 of this document and it also provides valid and invalid labels as per the Whole Label Evaluation laid down in Section 7. 2. Script for which the LGR is proposed ISO 15924 Code: Guru ISO 15924 Key N°: 310 ISO 15924 English Name: Gurmukhi Latin transliteration of native script name: gurmukhī Native name of the script: ਗੁਰਮੁਖੀ Maximal Starting Repertoire [MSR] version: 4 1 3. Background on Script and Principal Languages Using It 3.1. The Evolution of the Script Like most of the North Indian writing systems, the Gurmukhi script is a descendant of the Brahmi script. The Proto-Gurmukhi letters evolved through the Gupta script from 4th to 8th century, followed by the Sharda script from 8th century onwards and finally adapted their archaic form in the Devasesha stage of the later Sharda script, dated between the 10th and 14th centuries. -

M. Ricklefs an Inventory of the Javanese Manuscript Collection in the British Museum
M. Ricklefs An inventory of the Javanese manuscript collection in the British Museum In: Bijdragen tot de Taal-, Land- en Volkenkunde 125 (1969), no: 2, Leiden, 241-262 This PDF-file was downloaded from http://www.kitlv-journals.nl Downloaded from Brill.com09/29/2021 11:29:04AM via free access AN INVENTORY OF THE JAVANESE MANUSCRIPT COLLECTION IN THE BRITISH MUSEUM* he collection of Javanese manuscripts in the British Museum, London, although small by comparison with collections in THolland and Indonesia, is nevertheless of considerable importance. The Crawfurd collection, forming the bulk of the manuscripts, provides a picture of the types of literature being written in Central Java in the late eighteenth and early nineteenth centuries, a period which Dr. Pigeaud has described as a Literary Renaissance.1 Because they were acquired by John Crawfurd during his residence as an official of the British administration on Java, 1811-1815, these manuscripts have a convenient terminus ad quem with regard to composition. A large number of the items are dated, a further convenience to the research worker, and the dates are seen to cluster in the four decades between AD 1775 and AD 1815. A number of the texts were originally obtained from Pakualam I, who was installed as an independent Prince by the British admini- stration. Some of the manuscripts are specifically said to have come from him (e.g. Add. 12281 and 12337), and a statement in a Leiden University Bah ad from the Pakualaman suggests many other volumes in Crawfurd's collection also derive from this source: Tuwan Mister [Crawfurd] asked to be instructed in adat law, with examples of the Javanese usage. -

The Local Wisdom in Javanese Thinking Culture Within Hanacaraka Philosophy
THE LOCAL WISDOM IN JAVANESE THINKING CULTURE WITHIN HANACARAKA PHILOSOPHY Fitriana Kartika Sari STKIP PGRI Ponorogo email: [email protected] Abstract (Title: The Local Wisdom In Javanese Thinking Culture Within Hanacaraka Philosophy). Hanacaraka refers to the written language of Javanese, Javanese script. The name is based on the order of the twenty-Javanese-script, which is started by the series of hanacaraka script. This study aims to describe the local wisdom content of Javanese Thinking culture within the philosophical meaning of hanacaraka. This study used a semiotic approach applied to the main data source, namely Sêrat Kérata Basa. The results showed that (1) the philosophical meaning of the hanacaraka script was fully equipped with the wisdom of Javanese thinking culture in the form of symbolism and othak-athik mathuk which is supported by deep contemplation which involves all the common senses, including the inner sensitivity; (2) hanacaraka philosophy depicts God creature’s (human) circumstances, which is equipped with creation, feeling, and effort; human cannot avoid all God’s fate upon them until the end of their life; human conditions that achieve life harmony due to the ability to unify the manifestation of God and human characteristics, which heats up within themselves; human condition which put God’s order highly by doing all the orders and avoiding all of His warnings. Keywords: local wisdom, Javanese thinking, Hanacaraka INTRODUCTION because human is always eager to know and Javanese local wisdom is the principal find the authentic truth for everything. Human factor of thoughtful thinking which covers tries to seek for the revelating indicator of all then aspects of knowledge, faith, mysteries deeply through the use of all the comprehension or understanding, customs, common senses to gain satisfying conclusive and ethics. -

Suspicious Identity of U+A9B5 JAVANESE VOWEL SIGN TOLONG
L2/19-003 Suspicious identity of U+A9B5 JAVANESE VOWEL SIGN TOLONG Liang Hai / 梁海 <[email protected]> Aditya Bayu Perdana / <[email protected]> ꦄꦢꦶꦠꦾ ꦧꦪꦸꦥꦢꦤ 4 January 2019 1 Acknowledgements The authors would like to thank Ilham Nurwansah and the Script Ad Hoc group for their feedback. Ilham Nurwansah also kindly provided the Sundanese samples (Figure 2, 3, 4, and 5). 2 Background In the original Unicode Javanese proposal L2/08-015R Proposal for encoding the Javanese script in the UCS, the character tolong (U+A9B5 JAVANESE VOWEL SIGN TOLONG) was described as a vowel sign that is used exclusively in the Sundanese writing system with three major use cases: 1. Used alone as the vowel sign o 2. As a part of the vowel sign eu: <vowel sign ĕ, tolong> 3. As a part of the letters and conjoined forms of reu/leu: <letter / conjoined form rĕ/lĕ, tolong> Table 1. Sundanese tolong usage according to the original proposal Written form ◌ ◌ꦵ ◌ꦼ ◌ꦼꦵ ◌� ◌�ꦵ A9C0 PANGKON A9BC PEPET Encoding (A9B5 TOLONG) A989 PA CEREK (A9B5 TOLONG) (A9B5 TOLONG) Transcription a o ĕ eu rĕ reu Pronunciation [a] [o] [ə] [ɤ] [rə] [rɤ] See also the note under Table 2. However, tolong appears to be merely a stylistic variant of tarung (U+A9B4 JAVANESE VOWEL SIGN TARUNG), therefore the disunification of tolong from tarung is likely a mistake. 3 Proposal The Unicode Standard needs to recommend how the inappropriately disunified character U+A9B5 JAVANESE VOWEL SIGN TOLONG should be handled. 1 In particular, clarification in the names list and the Core Specification is necessary for explaining the background of the mis-disunification and recommending how both the tarung and tolong forms for both the Javanese and Sundanese languages should be implemented. -

Design of Javanese Text to Speech Application
Design of Javanese Text to Speech Application Yulia, Liliana, Rudy Adipranata, Gregorius Satia Budhi Informatics Department, Industrial Technology Faculty, Petra Christian University Surabaya, Indonesia [email protected] Abstract—Javanese is one of the many regional languages used in Indonesia. Javanese language is used by most of the population in Java. But now along with the development of the era, the use of regional languages including Javanese language is to be re- duced especially among the younger generation. One way to help conserve the use of Javanese language is to utilize information technologies, one of them is by developing a text to speech appli- cation that can be used to find out how the pronunciation of Ja- vanese language. In this paper, we discussed the design for Java- nese text to speech applications uses finite state automata. The design result will be used as rules to separate syllables when im- plementing text to speech application. Index Terms—Javanese language; Finite state automata; Text to speech. Figure 1: Basic Javanese characters I. INTRODUCTION In addition to the basic characters, the Javanese character Javanese language is a language widely spoken by the peo- has supplementary characters, consist of symbols for express- ple of Java. It is one of the regional languages of many region- ing vowels as well as a combination of two specific conso- al languages spoken in Indonesia. As one of the assets of na- nants. This supplementary characters is called sandhangan tional culture, Javanese language needs to be preserved. The and can be seen in Figure 2 [5]. younger generation is now more interested in learning a for- Symbol Example Read eign language, rather than the native Indonesian local lan- guage. -

Ahom Range: 11700–1174F
Ahom Range: 11700–1174F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

2016 Semi Finalists Medals
2016 US Physics Olympiad Semi Finalists Medal Rankings StudentMedal School City State Abbott, Ryan WHopkinsBronze Medal SchoolNew Haven CT Alton, James SLakesideHonorable Mention High SchoolEvans GA ALUMOOTIL, VARKEY TCanyonHonorable Mention Crest AcademySan Diego CA An, Seung HwanGold Medal Taft SchoolWatertown CT Ashary, Rafay AWilliamHonorable Mention P Clements High SchoolSugar Land TX Balaji, ShreyasSilver Medal John Foster Dulles High SchoolSugar Land TX Bao, MikeGold Medal Cambridge Educational InstituteChino Hills CA Beasley, NicholasGold Medal Stuyvesant High SchoolNew York NY BENABOU, JOSHUA N Gold Medal Plandome NY Bhattacharyya, MoinakSilver Medal Lynbrook High SchoolSan Jose CA Bhattaram, Krishnakumar SLynbrookBronze Medal High SchoolSan Jose CA Bhimnathwala, Tarung SBronze Medal Manalapan High SchoolManalapan NJ Boopathy, AkhilanGold Medal Lakeside Upper SchoolSeattle WA Cao, AntonSilver Medal Evergreen Valley High SchoolSan Jose CA Cen, Edward DBellaireHonorable Mention High SchoolBellaire TX Chadraa, Dalai BRedmondHonorable Mention High SchoolRedmond WA Chakrabarti, DarshanBronze Medal Northside College Preparatory HSChicago IL Chan, Clive ALexingtonSilver Medal High SchoolLexington MA Chang, Kevin YBellarmineSilver Medal Coll PrepSan Jose CA Cheerla, NikhilBronze Medal Monta Vista High SchoolSan Jose CA Chen, AlexanderSilver Medal Princeton High SchoolPrinceton NJ Chen, Andrew LMissionSilver Medal San Jose High SchoolFremont CA Chen, Benjamin YArdentSilver Medal Academy for Gifted YouthIrvine CA Chen, Bryan XMontaHonorable -

The Word Formation of Panyandra in Javanese Wedding
The Word Formation of Panyandra in Javanese Wedding Rahutami Rahutami and Ari Wibowo Program Studi Pendidikan Bahasa dan Sastra Indonesia, Fakultas Bahasa dan Sastra, Universitas Kanjuruhan Malang, Jl. S. Supriyadi 48 Malang 65148, Indonesia [email protected] Keywords: Popular forms, literary forms, panyandra. Abstract: This study aims to describe the form of speech in the Javanese wedding ceremony. For this purpose, a descriptive kualitatif methode with 'direct element' analysis of the word panyandra is used. The results show that there are popular forms of words and literary words. Vocabulary can be invented form and a basic form. The popular form is meant to explain to the listener, while the literary form serves to create the atmosphere the sacredness of Javanese culture. The sacredness was built with the use of the Old Javanese affixes. Panyandra in Malang shows differences with panyandra used in other areas, especially Surakarta and Jogjakarta style. 1 INTRODUCTION The panyadra are the words used in various Javanese cultural events. These words serve to describe events by using a form that has similarities Every nation has a unique culture. Each ethnic has a ritual in life, for example in a wedding ceremony or parallels (pepindhan). Panyandra can be distinguished by cultural events, such as birth, death, (Rohman & Ismail, 2013; Safarova, 2014). A or marriage. These terms adopt many of the ancient wedding ceremony is a sacred event that has an important function in the life of the community, and Javanese vocabulary and Sanskrit words. It is intended to give a formal, religious, and artistic each wedding procession shows a way of thinking impression. -

1 PASANGAN DAN SANDHANGAN DALAM AKSARA JAWA Oleh
PASANGAN DAN SANDHANGAN DALAM AKSARA JAWA1 oleh: Sri Hertanti Wulan [email protected] Jurusan Pendidikan Bahasa Daerah FBS UNY Aksara nglegena yang digunakan dalam ejaan bahasa Jawa pada dasarnya terdiri atas dua puluh aksara yang bersifat silabik Darusuprapta (2002: 12-13). Masing-masing aksara mempunyai aksara pasangan, yakni aksara yang berfungsi untuk menghubungkan suku kata mati/tertutup dengan suku kata berikutnya, kecuali suku kata yang tertutup dengan wignyan (.. ), layar (....), dan cecak (....). Pasangan – pasangan tersebut antara lain: a) Aksara pasangan wutuh, ditulis di bawah aksara yang diberi pasangan dan tidak disambung, yaitu antara lain: Tabel 1 Pasangan Wutuh pasangan Wujud Contoh Ra … dalan ramé= Ya … tumbas yuyu = Ga … dalan gĕdhé = .… dolan ngomah = nga b) Aksara pasangan tugelan ditulis di belakang aksara yang diberi pasangan dan tidak disambungkan dengan aksara yang diberi pasangan, yaitu antara lain: 1Disampaikan dalam PPM PelatihanAksaraJawadan PendirianHanacaraka Centre sebagaiRevitalisasiFungsiAksaraJawa kerjasama FBS UNY dan Dinas Dikpora DIY. Dilaksanakan di Dikpora DIY, Senin 28 Oktober 2013. 1 Tabel 2.1 Pasangan Tugelan pasangan Wujud Contoh ha … adhĕm hawané = pa … bakul pĕlĕm = sa … dalan sĕpi = c) Aksara pasangan tugelan ditulis di bawah aksara yang diberi pasangan dan tidak disambungkan dengan aksara yang diberi pasangan, yaitu antara lain: Tabel 2.2 Pasangan Tugelan pasangan Wujud Contoh kilèn kalen= ka … wis takon = ta … tas larang = la … Pasangan – pasangan tersebut, bila mendapatkan sandhangan