Crowd-Sourced Speech Corpora for Javanese, Sundanese, Sinhala, Nepali, and Bangladeshi Bengali
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -

Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-04-22 Document version: 2.7 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract This document lays down the Label Generation Ruleset for Gurmukhi script. Three main components of the Gurmukhi Script LGR i.e. Code point repertoire, Variants and Whole Label Evaluation Rules have been described in detail here. All these components have been incorporated in a machine-readable format in the accompanying XML file named "proposal-gurmukhi-lgr-22apr19-en.xml". In addition, a document named “gurmukhi-test-labels-22apr19-en.txt” has been provided. It provides a list of labels which can produce variants as laid down in Section 6 of this document and it also provides valid and invalid labels as per the Whole Label Evaluation laid down in Section 7. 2. Script for which the LGR is proposed ISO 15924 Code: Guru ISO 15924 Key N°: 310 ISO 15924 English Name: Gurmukhi Latin transliteration of native script name: gurmukhī Native name of the script: ਗੁਰਮੁਖੀ Maximal Starting Repertoire [MSR] version: 4 1 3. Background on Script and Principal Languages Using It 3.1. The Evolution of the Script Like most of the North Indian writing systems, the Gurmukhi script is a descendant of the Brahmi script. The Proto-Gurmukhi letters evolved through the Gupta script from 4th to 8th century, followed by the Sharda script from 8th century onwards and finally adapted their archaic form in the Devasesha stage of the later Sharda script, dated between the 10th and 14th centuries. -

Ahom Range: 11700–1174F
Ahom Range: 11700–1174F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

The Word Formation of Panyandra in Javanese Wedding
The Word Formation of Panyandra in Javanese Wedding Rahutami Rahutami and Ari Wibowo Program Studi Pendidikan Bahasa dan Sastra Indonesia, Fakultas Bahasa dan Sastra, Universitas Kanjuruhan Malang, Jl. S. Supriyadi 48 Malang 65148, Indonesia [email protected] Keywords: Popular forms, literary forms, panyandra. Abstract: This study aims to describe the form of speech in the Javanese wedding ceremony. For this purpose, a descriptive kualitatif methode with 'direct element' analysis of the word panyandra is used. The results show that there are popular forms of words and literary words. Vocabulary can be invented form and a basic form. The popular form is meant to explain to the listener, while the literary form serves to create the atmosphere the sacredness of Javanese culture. The sacredness was built with the use of the Old Javanese affixes. Panyandra in Malang shows differences with panyandra used in other areas, especially Surakarta and Jogjakarta style. 1 INTRODUCTION The panyadra are the words used in various Javanese cultural events. These words serve to describe events by using a form that has similarities Every nation has a unique culture. Each ethnic has a ritual in life, for example in a wedding ceremony or parallels (pepindhan). Panyandra can be distinguished by cultural events, such as birth, death, (Rohman & Ismail, 2013; Safarova, 2014). A or marriage. These terms adopt many of the ancient wedding ceremony is a sacred event that has an important function in the life of the community, and Javanese vocabulary and Sanskrit words. It is intended to give a formal, religious, and artistic each wedding procession shows a way of thinking impression. -

Halfwidth and Fullwidth Forms Range: FF00–FFEF
Halfwidth and Fullwidth Forms Range: FF00–FFEF This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

The Song of Macapat Semarangan: the Acculturation of Javanese and Islamic Culture
Harmonia: Journal of Arts Research and Education 20 (1) (2020), 10-18 p-ISSN 2541-1683|e-ISSN 2541-2426 Available online at http://journal.unnes.ac.id/nju/index.php/harmonia DOI: http://dx.doi.org/10.15294/harmonia.v20i1.25050 The Song of Macapat Semarangan: The Acculturation of Javanese and Islamic Culture Agus Cahyono, Widodo Widodo, Muhamad Jazuli, Onang Murtiyoso Department of Drama, Dance, and Music, Faculty of Languages and Arts, Universitas Negeri Semarang, Indonesia Submitted: January 4, 2020. Revised: March 9, 2020. Accepted: July 4, 2020 Abstract The research objective is to explain the macapat Semarangan song which is the result of accul- turation of Javanese and Islamic culture. The study used qualitative methods by uncovering the concept of processing of Javanese music and acculturation. Research location was in Semarang with the object of macapat Semarangan song study. Data was collected through interviews, ob- servations, and study documents. The validity of the data was examined through triangulation techniques and the analysis is done through the stages of identification, classification, compari- son, interpretation, reduction, verification, and making conclusions. The results showed that the macapat Semarangan song has unique characteristics of arrangement. The song’s grooves use long and complicated musical ornamentations with varying pitch heights to reach high notes. This is a manifestation of the results of acculturation of Javanese and Islamic culture seen from arrange- ment on the parts of Adzan (call to prayer) and tilawatil Qur’an. The process of acculturation of elements of Islamic culture also involves scales. Azan songs use diatonic scales, some macapat Semarangan songs also use the same scales, but a cycle of five notes close to nuances of Chi- nese music scales. -

Download Hajj Guide
In the name of Allah the Beneficent and the Merciful Hajj Guide for Pilgrims With Islamic Rulings (Ahkaam) Philosophy & Supplications (Duaas) SABA Hajj Group Shia-Muslim Association of Bay Area San Jose, California, USA First Edition (Revision 1.1) December, 2003 Second Edition (Revision 2.1) October, 2005 Third Edition (Revision 2.0) December, 2006 Authors & Editors: Hojjatul Islam Dr. Nabi Raza Abidi, Resident Scholar of Shia-Muslim Association of Bay Area Hussnain Gardezi, Haider Ali, Urooj Kazmi, Akber Kazmi, Ali Hasan - Hajj-Guide Committee Reviewers: Hojjatul Islam Zaki Baqri, Hojjatul Islam Sayyed Mojtaba Beheshti, Batool Gardezi, Sayeed Himmati, Muzaffar Khan, and 2003 SABA Hajj Group Hajj Committee: Hojjatul Islam Dr. Nabi Raza Abidi, Syed Mohammad Hussain Muttaqi, Dr. Mohammad Rakhshandehroo, Muzaffar Khan, Haider Ali, Ali Hasan, Sayeed Himmati Copyright Free & Non-Profit Notice: The SABA Hajj Guide can be freely copied, duplicated, reproduced, quoted, distributed, printed, used in derivative works and saved on any media and platform for non-profit and educational purposes only. A fee no higher than the cost of copying may be charged for the material. Note from Hajj Committee: The Publishers and the Authors have made every effort to present the Quranic verses, prophetic and masomeen traditions, their explanations, Islamic rulings from Manasik of Hajj books and the material from the sources referenced in an accurate, complete and clear manner. We ask for forgiveness from Allah (SWT) and the readers if any mistakes have been overlooked during the review process. Contact Information: Any correspondence related to this publication and all notations of errors or omissions should be addressed to Hajj Committee, Shia-Muslim Association of Bay Area at [email protected]. -

UTC L2/20-061 2020-01-28 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale De Normalisation
UTC L2/20-061 2020-01-28 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Doc Type: Working Group Document Title: Final Proposal to encode Western Cham in the UCS Source: Martin Hosken Status: Individual contribution Action: For consideration by UTC and ISO Date: 2020-01-28 Executive Summary. This proposal is to add 97 characters to a block: 1E200-1E26F in the supplementary plane, named Western Cham. In addition, 1 character is proposed for inclusion in the Arabic Extended A block: 08A0-08FF. The proposal is a revision of L2/19-217r3. A revision history is given at the end of the main text of this document. Introduction. Eastern Cham is already encoded in the range AA00-AA5F. As stated in N4734, Western Cham while closely related to Eastern Cham, is sufficiently different in style for Eastern Cham characters in plain text to be unintelligible to Western Cham readers and therefore a separate block is required. As such, the proposal to encode Western Cham in a separate block from (Eastern) Cham can be considered a disunification. But since Western Cham was never supported in the (Eastern) Cham block, it can be argued that this is a proposal for a new script. This is further discussed in the section on disunification. The Western Cham encoding follows the same encoding model as for (Eastern) Cham. There is no halant or virama that calls for a Brahmic model. The basic structure is a base character followed by a sequence of marks as described in the section on combining orders. -

Balinese Romanization Table
Balinese Principal consonants1 (h)a2 ᬳ ᭄ᬳ na ᬦ ᭄ᬦ ca ᬘ ᭄ᬘ᭄ᬘ ra ᬭ ᭄ᬭ ka ᬓ ᭄ᬓ da ᬤ ᭄ᬤ ta ᬢ ᭄ᬢ sa ᬲ ᭄ᬲ wa ᬯ la ᬮ ᭄ᬙ pa ᬧ ᭄ᬧ ḍa ᬟ ᭄ᬠ dha ᬥ ᭄ᬟ ja ᬚ ᭄ᬚ ya ᬬ ᭄ᬬ ña ᬜ ᭄ᬜ ma ᬫ ᭄ᬫ ga ᬕ ᭄ᬕ ba ᬩ ᭄ᬩ ṭa ᬝ ᭄ᬝ nga ᬗ ᭄ᬗ Other consonant forms3 na (ṇa) ᬡ ᭄ᬡ ca (cha) ᭄ᬙ᭄ᬙ ta (tha) ᬣ ᭄ᬣ sa (śa) ᬱ ᭄ᬱ sa (ṣa) ᬰ ᭄ᬰ pa (pha) ᬨ ᭄ᬛ ga (gha) ᬖ ᭄ᬖ ba (bha) ᬪ ᭄ᬪ ‘a ᬗ᬴ ha ᬳ᬴ kha ᬓ᬴ fa ᬧ᬴ za ᬚ᬴ gha ᬕ᬴ Vowels and other agglutinating signs4 5 a ᬅ 6 ā ᬵ ᬆ e ᬾ ᬏ ai ᬿ ᬐ ĕ ᭂ ö ᭃ i ᬶ ᬇ ī ᬷ ᬈ o ᭀ ᬑ au ᭁ ᬒ u7 ᬸ ᬉ ū ᬹ ᬊ ya, ia8 ᭄ᬬ r9 ᬃ ra ᭄ᬭ rĕ ᬋ rö ᬌ ᬻ lĕ ᬍ ᬼ lö ᬎ ᬽ h ᬄ ng ᬂ ng ᬁ Numerals 1 2 3 4 5 ᭑ ᭒ ᭓ ᭔ ᭕ 6 7 8 9 0 ᭖ ᭗ ᭘ ᭙ ᭐ 1 Each consonant has two forms, the regular and the appended, shown on the left and right respectively in the romanization table. The vowel a is implicit after all consonants and consonant clusters and should be supplied in transliteration, unless: (a) another vowel is indicated by the appropriate sign; or (b) the absence of any vowel is indicated by the use of an adeg-adeg sign ( ). (Also known as the tengenen sign; ᭄ paten in Javanese.) 2 This character often serves as a neutral seat for a vowel, in which case the h is not transcribed. -
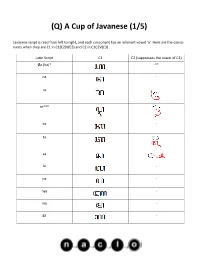
Q) a Cup of Javanese (1/5
(Q) A Cup of Javanese (1/5) Javanese script is read from left to right, and each consonant has an inherent vowel ‘a’. Here are the conso- nants when they are C1 in C1(C2)V(C3) and C2 in C1C2V(C3). Latin Script C1 C2 (suppresses the vowel of C1) Øa (ha)* -** na - ra re*** ka - ta sa la - pa - nya - ma - ga - (Q) A Cup of Javanese (2/5) Javanese script is read from left to right, and each consonant has an inherent vowel ‘a’. Here are the conso- nants when they are C1 in C1(C2)V(C3) and C2 in C1C2V(C3). Latin Script C1 C2 (suppresses the vowel of C1) ba nga - *The consonant is either ‘Ø’ (no consonant) or ‘h,’ but the problem contains only the former. **The ‘-’ means that the form exists, but not in this problem. ***The CV combination ‘re’ (historical remnant of /ɽ/) has its own special letters. ‘ng,’ ‘h,’ and ‘r’ must be C3 in (C1)(C2)VC3 before another C or at the end of a word. All other consonants after V must be C1 of the next syllable. If these consonants end a word, a ‘vowel suppressor’ must be added to suppress the inherent ‘a.’ Latin Script C3 -ng -h -r -C (vowel suppressor) Consonants can be modified to change the inherent vowel ‘a’ in C1(C2)V(C3). Latin Script V* e** (Q) A Cup of Javanese (3/5) Latin Script V* i é u o * If C2 is on the right side of C1, then ‘e,’ ‘i,’ and ‘u’ modify C2. -

The Unicode Standard, Version 3.0, Issued by the Unicode Consor- Tium and Published by Addison-Wesley
The Unicode Standard Version 3.0 The Unicode Consortium ADDISON–WESLEY An Imprint of Addison Wesley Longman, Inc. Reading, Massachusetts · Harlow, England · Menlo Park, California Berkeley, California · Don Mills, Ontario · Sydney Bonn · Amsterdam · Tokyo · Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. If these files have been purchased on computer-readable media, the sole remedy for any claim will be exchange of defective media within ninety days of receipt. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. ISBN 0-201-61633-5 Copyright © 1991-2000 by Unicode, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or other- wise, without the prior written permission of the publisher or Unicode, Inc.