ISO/IEC JTC1/SC2/WG2 N 2005 Date: 1999-05-29
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -

List of Aleph Tables
List of Aleph Tables Version 22 CONFIDENTIAL INFORMATION The information herein is the property of Ex Libris Ltd. or its affiliates and any misuse or abuse will result in economic loss. DO NOT COPY UNLESS YOU HAVE BEEN GIVEN SPECIFIC WRITTEN AUTHORIZATION FROM EX LIBRIS LTD. This document is provided for limited and restricted purposes in accordance with a binding contract with Ex Libris Ltd. or an affiliate. The information herein includes trade secrets and is confidential. DISCLAIMER The information in this document will be subject to periodic change and updating. Please confirm that you have the most current documentation. There are no warranties of any kind, express or implied, provided in this documentation, other than those expressly agreed upon in the applicable Ex Libris contract. This information is provided AS IS. Unless otherwise agreed, Ex Libris shall not be liable for any damages for use of this document, including, without limitation, consequential, punitive, indirect or direct damages. Any references in this document to third-party material (including third-party Web sites) are provided for convenience only and do not in any manner serve as an endorsement of that third-party material or those Web sites. The third-party materials are not part of the materials for this Ex Libris product and Ex Libris has no liability for such materials. TRADEMARKS "Ex Libris," the Ex Libris bridge , Primo, Aleph, Alephino, Voyager, SFX, MetaLib, Verde, DigiTool, Preservation, URM, Voyager, ENCompass, Endeavor eZConnect, WebVoyage, Citation Server, LinkFinder and LinkFinder Plus, and other marks are trademarks or registered trademarks of Ex Libris Ltd. -
Dyalog APL Binding Strengths
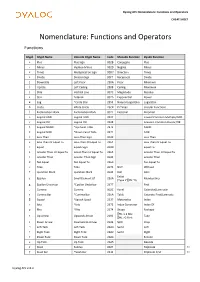
Dyalog APL Nomenclature: Functions and Operators CHEAT SHEET Nomenclature: Functions and Operators Functions Glyph Glyph Name Unicode Glyph Name Code Monadic Function Dyadic Function + Plus Plus Sign 002B Conjugate Plus - Minus Hyphen-Minus 002D Negate Minus × Times Multiplication Sign 00D7 Direction Times ÷ Divide Division Sign 00F7 Reciprocal Divide ⌊ Downstile Left Floor 230A Floor Minimum ⌈ Upstile Left Ceiling 2308 Ceiling Maximum | Stile Vertical Line 007C Magnitude Residue * Star Asterisk 002A Exponential Power ⍟ Log *Circle Star 235F Natural Logarithm Logarithm ○ Circle White Circle 25CB Pi Times Circular Functions ! Exclamation Mark Exclamation Mark 0021 Factorial Binomial ∧ Logical AND Logical AND 2227 Lowest Common Multiple/AND ∨ Logical OR Logical OR 2228 Greatest Common Divisor/OR ⍲ Logical NAND *Up Caret Tilde 2372 NAND ⍱ Logical NOR *Down Caret Tilde 2371 NOR < Less Than Less-Than Sign 003C Less Than ≤ Less Than Or Equal To Less-Than Or Equal To 2264 Less Than Or Equal To = Equal Equals Sign 003D Equal To ≥ Greater Than Or Equal To Great-Than Or Equal To 2265 Greater Than Or Equal To > Greater Than Greater-Than Sign 003E Greater Than ≠ Not Equal Not Equal To 2260 Not Equal To ~ Tilde Tilde 007E NOT Without ? Question Mark Question Mark 003F Roll Deal Enlist ∊ Epsilon Small Element Of 220A Membership (Type if ⎕ML=0) ⍷ Epsilon Underbar *Epsilon Underbar 2377 Find , Comma Comma 002C Ravel Catenate/Laminate ⍪ Comma Bar *Comma Bar 236A Table Catenate First/Laminate ⌷ Squad *Squish Quad 2337 Materialise Index ⍳ Iota *Iota 2373 -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Evitalia NORMAS ISO En El Marco De La Complejidad
No. 7 Revitalia NORMAS ISO en el marco de la complejidad ESTEQUIOMETRIA de las relaciones humanas FRACTALIDAD en los sistemas biológicos Dirección postal Calle 82 # 102 - 79 Bogotá - Colombia Revista Revitalia Publicación trimestral Contacto [email protected] Web http://revitalia.biogestion.com.co Volumen 2 / Número 7 / Noviembre-Enero de 2021 ISSN: 2711-4635 Editor líder: Juan Pablo Ramírez Galvis. Consultor en Biogestión, NBIC y Gerencia Ambiental/de la Calidad. Globuss Biogestión [email protected] ORCID: 0000-0002-1947-5589 Par evaluador: Jhon Eyber Pazos Alonso Experto en nanotecnología, biosensores y caracterización por AFM. Universidad Central / Clúster NBIC [email protected] ORCID: 0000-0002-5608-1597 Contenido en este número Editorial p. 3 Estequiometría de las relaciones humanas pp. 5-13 Catálogo de las normas ISO en el marco de la complejidad pp. 15-28 Fractalidad en los sistemas biológicos pp. 30-37 Licencia Creative Commons CC BY-NC-ND 4.0 2 Editorial: “En armonía con lo ancestral” Juan Pablo Ramírez Galvis. Consultor en Biogestión, NBIC y Gerencia Ambiental/de la Calidad. [email protected] ORCID: 0000-0002-1947-5589 La dicotomía entre ciencia y religión proviene de la edad media, en la cual, los aspectos espirituales no podían explicarse desde el método científico, y a su vez, la matematización mecánica del universo era el único argumento que convencía a los investigadores. Sin embargo, más atrás en la línea del tiempo, los egipcios, sumerios, chinos, etc., unificaban las teorías metafísicas con las ciencias básicas para dar cuenta de los fenómenos en todas las escalas desde lo micro hasta lo macro. -

Descriptive Metadata Guidelines for RLG Cultural Materials I Many Thanks Also to These Individuals Who Reviewed the Final Draft of the Document
������������������������������� �������������������������� �������� ����������������������������������� ��������������������������������� ��������������������������������������� ���������������������������������������������������� ������������������������������������������������� � ���������������������������������������������� ������������������������������������������������ ����������������������������������������������������������� ������������������������������������������������������� ���������������������������������������������������� �� ���������������������������������������������� ������������������������������������������� �������������������� ������������������� ���������������������������� ��� ���������������������������������������� ����������� ACKNOWLEDGMENTS Many thanks to the members of the RLG Cultural Materials Alliance—Description Advisory Group for their participation in developing these guidelines: Ardie Bausenbach Library of Congress Karim Boughida Getty Research Institute Terry Catapano Columbia University Mary W. Elings Bancroft Library University of California, Berkeley Michael Fox Minnesota Historical Society Richard Rinehart Berkeley Art Museum & Pacific Film Archive University of California, Berkeley Elizabeth Shaw Aziza Technology Associates, LLC Neil Thomson Natural History Museum (UK) Layna White San Francisco Museum of Modern Art Günter Waibel RLG staff liaison Thanks also to RLG staff: Joan Aliprand Arnold Arcolio Ricky Erway Fae Hamilton Descriptive Metadata Guidelines for RLG Cultural Materials i Many -

Ahom Range: 11700–1174F
Ahom Range: 11700–1174F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

Haptiread: Reading Braille As Mid-Air Haptic Information
HaptiRead: Reading Braille as Mid-Air Haptic Information Viktorija Paneva Sofia Seinfeld Michael Kraiczi Jörg Müller University of Bayreuth, Germany {viktorija.paneva, sofia.seinfeld, michael.kraiczi, joerg.mueller}@uni-bayreuth.de Figure 1. With HaptiRead we evaluate for the first time the possibility of presenting Braille information as touchless haptic stimulation using ultrasonic mid-air haptic technology. We present three different methods of generating the haptic stimulation: Constant, Point-by-Point and Row-by-Row. (a) depicts the standard ordering of cells in a Braille character, and (b) shows how the character in (a) is displayed by the three proposed methods. HaptiRead delivers the information directly to the user, through their palm, in an unobtrusive manner. Thus the haptic display is particularly suitable for messages communicated in public, e.g. reading the departure time of the next bus at the bus stop (c). ABSTRACT Author Keywords Mid-air haptic interfaces have several advantages - the haptic Mid-air Haptics, Ultrasound, Haptic Feedback, Public information is delivered directly to the user, in a manner that Displays, Braille, Reading by Blind People. is unobtrusive to the immediate environment. They operate at a distance, thus easier to discover; they are more hygienic and allow interaction in 3D. We validate, for the first time, in INTRODUCTION a preliminary study with sighted and a user study with blind There are several challenges that blind people face when en- participants, the use of mid-air haptics for conveying Braille. gaging with interactive systems in public spaces. Firstly, it is We tested three haptic stimulation methods, where the hap- more difficult for the blind to maintain their personal privacy tic feedback was either: a) aligned temporally, with haptic when engaging with public displays. -

2903 Date: 2005-08-22
ISO/IEC JTC 1/SC 2/WG 2 N2903 DATE: 2005-08-22 ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) - ISO/IEC 10646 Secretariat: ANSI DOC TYPE: Meeting Minutes TITLE: Unconfirmed minutes of WG 2 meeting 46 Jinyan Hotel, Xiamen, Fujian Province, China; 2005-01-24/28 SOURCE: V.S. Umamaheswaran, Recording Secretary, and Mike Ksar, Convener PROJECT: JTC 1.02.18 – ISO/IEC 10646 STATUS: SC 2/WG 2 participants are requested to review the attached unconfirmed minutes, act on appropriate noted action items, and to send any comments or corrections to the convener as soon as possible but no later than 2005-09-05. ACTION ID: ACT DUE DATE: 2005-09-05 DISTRIBUTION: SC 2/WG 2 members and Liaison organizations MEDIUM: Acrobat PDF file NO. OF PAGES: 67 (including cover sheet) Mike Ksar Convener – ISO/IEC/JTC 1/SC 2/WG 2 Microsoft Corporation Phone: +1 425 707-6973 One Microsoft Way Fax: +1 425 936-7329 Bldg 24/2217 email: [email protected] Redmond, WA 98052-6399 or [email protected] Unconfirmed Meeting Minutes ISO/IEC JTC1/SC2/WG2 Meeting 46 Page 1 of 67 N2903 Jinyan Hotel, Xiamen, Fujian Province, China; 2005-01-24/28 2005-08-22 ISO International Organization for Standardization Organisation Internationale de Normalisation ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) ISO/IEC JTC 1/SC 2/WG 2 N2903 Date: 2005-08-22 Title: Unconfirmed minutes of WG 2 meeting 46 Jinyan Hotel, Xiamen, Fujian Province, China; 2005-01-24/28 Source: V.S. -

1 PASANGAN DAN SANDHANGAN DALAM AKSARA JAWA Oleh
PASANGAN DAN SANDHANGAN DALAM AKSARA JAWA1 oleh: Sri Hertanti Wulan [email protected] Jurusan Pendidikan Bahasa Daerah FBS UNY Aksara nglegena yang digunakan dalam ejaan bahasa Jawa pada dasarnya terdiri atas dua puluh aksara yang bersifat silabik Darusuprapta (2002: 12-13). Masing-masing aksara mempunyai aksara pasangan, yakni aksara yang berfungsi untuk menghubungkan suku kata mati/tertutup dengan suku kata berikutnya, kecuali suku kata yang tertutup dengan wignyan (.. ), layar (....), dan cecak (....). Pasangan – pasangan tersebut antara lain: a) Aksara pasangan wutuh, ditulis di bawah aksara yang diberi pasangan dan tidak disambung, yaitu antara lain: Tabel 1 Pasangan Wutuh pasangan Wujud Contoh Ra … dalan ramé= Ya … tumbas yuyu = Ga … dalan gĕdhé = .… dolan ngomah = nga b) Aksara pasangan tugelan ditulis di belakang aksara yang diberi pasangan dan tidak disambungkan dengan aksara yang diberi pasangan, yaitu antara lain: 1Disampaikan dalam PPM PelatihanAksaraJawadan PendirianHanacaraka Centre sebagaiRevitalisasiFungsiAksaraJawa kerjasama FBS UNY dan Dinas Dikpora DIY. Dilaksanakan di Dikpora DIY, Senin 28 Oktober 2013. 1 Tabel 2.1 Pasangan Tugelan pasangan Wujud Contoh ha … adhĕm hawané = pa … bakul pĕlĕm = sa … dalan sĕpi = c) Aksara pasangan tugelan ditulis di bawah aksara yang diberi pasangan dan tidak disambungkan dengan aksara yang diberi pasangan, yaitu antara lain: Tabel 2.2 Pasangan Tugelan pasangan Wujud Contoh kilèn kalen= ka … wis takon = ta … tas larang = la … Pasangan – pasangan tersebut, bila mendapatkan sandhangan -

Source Readings in Javanese Gamelan and Vocal Music, Volume 2
THE UNIVERSITY OF MICHIGAN CENTER FOR SOUTH AND SOUTHEAST ASIAN STUDIES MICHIGAN PAPERS ON SOUTH AND SOUTHEAST ASIA Editorial Board Alton L. Becker Karl L. Hutterer John K. Musgrave Peter E. Hook, Chairman Ann Arbor, Michigan USA KARAWITAN SOURCE READINGS IN JAVANESE GAMELAN AND VOCAL MUSIC Judith Becker editor Alan H. Feinstein assistant editor Hardja Susilo Sumarsam A. L. Becker consultants Volume 2 MICHIGAN PAPERS ON SOUTH AND SOUTHEAST ASIA; Center for South and Southeast Asian Studies The University of Michigan Number 30 Open access edition funded by the National Endowment for the Humanities/ Andrew W. Mellon Foundation Humanities Open Book Program. Library of Congress Catalog Card Number: 82-72445 ISBN 0-89148-034-X Copyright ©' 1987 by Center for South and Southeast Asian Studies The University of Michigan Publication of this book was assisted in part by a grant from the Publications Program of the National Endowment for the Humanities. Additional funding or assistance was provided by the National Endowment for the Humanities (Transla- tions); the Southeast Asia Regional Council, Association for Asian Studies; The Rackham School of Graduate Studies, The University of Michigan; and the School of Music, The University of Michigan. Printed in the United States of America ISBN 978-0-89-148034-1 (hardcover) ISBN 978-0-47-203819-0 (paper) ISBN 978-0-47-212769-6 (ebook) ISBN 978-0-47-290165-4 (open access) The text of this book is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License: https://creativecommons.org/licenses/by-nc-nd/4.0/ CONTENTS PREFACE: TRANSLATING THE ART OF MUSIC A.