The Unicode Standard, Version 4.0--Online Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UNICODE for Kannada General Information & Description
UNICODE for Kannada (U+0C80 to U+0CFF) General Information & Description Written by: C V Srinatha Sastry Issued by: Director Directorate of Information Technology Government of Karnataka Multi Storied Buildings, Vidhana Veedhi BANGALORE 560 001 INDIA PDF created with FinePrint pdfFactory Pro trial version http://www.pdffactory.com UNICODE for Kannada Introduction The Kannada script is a South Indian script. It is used to write Kannada language of Karnataka State in India. This is also used in many parts of Tamil Nadu, Kerala, Andhra Pradesh and Maharashtra States of India. In addition, the Kannada script is also used to write Tulu, Konkani and Kodava languages. Kannada along with other Indian language scripts shares a large number of structural features. The Kannada block of Unicode Standard (0C80 to 0CFF) is based on ISCII-1988 (Indian Standard Code for Information Interchange). The Unicode Standard (version 3) encodes Kannada characters in the same relative positions as those coded in the ISCII-1988 standard. The Writing system that employs Kannada script constitutes a cross between syllabic writing systems and phonemic writing systems (alphabets). The effective unit of writing Kannada is the orthographic syllable consisting of a consonant (Vyanjana) and vowel (Vowel) (CV) core and optionally, one or more preceding consonants, with a canonical structure of ((C)C)CV. The orthographic syllable need not correspond exactly with a phonological syllable, especially when a consonant cluster is involved, but the writing system is built on phonological principles and tends to correspond quite closely to pronunciation. The orthographic syllable is built up of alphabetic pieces, the actual letters of Kannada script. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
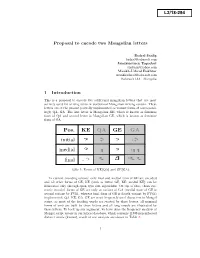
Pos. KE QA GE GA Initial ᠬ ᠭ Medial Final
Proposal to encode two Mongolian letters Badral Sanlig [email protected] Jamiyansuren Togoobat [email protected] Munkh-Uchral Enkhtur [email protected] Bolorsoft LLC, Mongolia 1 Introduction This is a proposal to encode two additional mongolian letters that are most actively used for writing texts in traditional Mongolian writing system. These letters are at the present partially implemented as variant forms of correspond- ingly QA, GA. The first letter is Mongolian KE, which is known as feminine form of QA and second letter is Mongolian GE, which is known as feminine form of GA. Pos. KE QA GE GA ᠬ ᠭ initial medial final - Table 1: Forms of KE(QA) and GE(GA). In current encoding scheme, only final and medial form of GE are encoded and all other forms of GE, KE (such as initial GE, KE, medial KE) can be illustrated only through open type font algorithms. On top of that, those cur- rently encoded forms of GE are only as variant of GA (medial form of GE is second variant by FVS1, whereas final form of GE is fourth variant by FVS3) implemented. QA, KE, GA, GE are most frequently used characters in Mongol script, as most of the heading words are started by these letters, all nominal forms of verb are built by these letters and all long vowels are illustrated by these letters. To back up our argument, we have done the frequency analysis of Mongol script letters in our lexical database, which contains 41808 non-inflected distinct words (lemma), result of our analysis are shown in Table 2. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -
Problems with Unicode for Languages Unsupported by Computers
Problems with Unicode for Languages Unsupported by Computers Pat Hall, Language Technology Kendra, Patan, Nepal [email protected] Abstract If a language is to be used on the Internet it needs to be written and that writing encoded for the computer. The problems of achieving this for small languages is illustrated with respect to Nepal. Nepal has over 120 languages, with only the national language Nepali having any modern computer support. Nepali is relatively easy, since it is written in Devanagari which is also used for Hindi and other Indian languages, though with some local differences. I focus on the language of the Newar people, a language which has a mature written tradition spanning more than one thousand years, with several different styles of writing, and yet has no encoding of its writing within Unicode. Why has this happened? I explore this question, looking for answers in the view of technology of the people involved, in their different and possibly competing interests, and in the incentives for working on standards. I also explore what should be done about the many other unwritten and uncomputerised languages of Nepal. We are left with serious concerns about the standardisation process, but appreciate that encoding is critically important and we must work with the standardisation process as we find it.. Introduction If we are going to make knowledge written in our language available to everybody in their own languages, those languages must be written and that writing must be encoded in the computer. Those of us privileged to be native speakers of a world language such as English or Spanish may think this is straightforward, but it is not, as will be explained here. -

KHA in ANCIENT INDIAN MATHEMATICS It Was in Ancient
KHA IN ANCIENT INDIAN MATHEMATICS AMARTYA KUMAR DUTTA It was in ancient India that zero received its first clear acceptance as an integer in its own right. In 628 CE, Brahmagupta describes in detail rules of operations with integers | positive, negative and zero | and thus, in effect, imparts a ring structure on integers with zero as the additive identity. The various Sanskrit names for zero include kha, ´s¯unya, p¯urn. a. There was an awareness about the perils of zero and yet ancient Indian mathematicians not only embraced zero as an integer but allowed it to participate in all four arithmetic operations, including as a divisor in a division. But division by zero is strictly forbidden in the present edifice of mathematics. Consequently, verses from ancient stalwarts like Brahmagupta and Bh¯askar¯ac¯arya referring to numbers with \zero in the denominator" shock the modern reader. Certain examples in the B¯ıjagan. ita (1150 CE) of Bh¯askar¯ac¯arya appear as absurd nonsense. But then there was a time when square roots of negative numbers were considered non- existent and forbidden; even the validity of subtracting a bigger number from a smaller number (i.e., the existence of negative numbers) took a long time to gain universal acceptance. Is it not possible that we too have confined ourselves to a certain safe convention regarding the zero and that there could be other approaches where the ideas of Brahmagupta and Bh¯askar¯ac¯arya, and even the examples of Bh¯askar¯ac¯arya, will appear not only valid but even natural? Enterprising modern mathematicians have created elaborate legal (or technical) machinery to overcome the limitations imposed by the prohibition against use of zero in the denominator. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

Ahom Range: 11700–1174F
Ahom Range: 11700–1174F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

A Glimpse of Kirat-Yakthung (Limbu) Language, Writing, and Literacy
Journal of Global Literacies, Technologies, and Emerging Pedagogies Volume 4, Issue 1, March 2017, pp. 560-593 Delinking, Relinking, and Linking Methodologies: A Glimpse of Kirat-Yakthung (Limbu) Language, Writing, and Literacy Marohang Limbu1 Writing, Rhetoric, and American Cultures Michigan State University, USA Abstract: Limbus (Limboos), who are also known as “Yakthungs” or “Kirat-Yakthung” or “Kirats,” have/had their own unique culture, language, writing, and Mundhum rhetorics. After “Nun-Paani Sandhi” (Salt-Water Treaty) in 1774 with Khas-Aryas, they (Khas- Aryans) ideologically and Politically banned Limbus from teaching of their language, writing, and Mundhum rhetorics in Yakthung laje (Limbuwan). Because of the Khas-Aryan oPPression, Limbu culture had/has become oral-dominant; Yakthungs used/use oral- Performance-based Mundhum rhetorics to Preserve their culture, language, histories, and Mundhum rhetorics. The main PurPose of this article is to discuss the develoPment of Kirat-Yakthung’s writing and rhetoric and/or rise-fall-rise of Yakthung scriPt, writing, and literacy. The essay demonstrates how Kirat-Yakthung indigenous PeoPles are delinking (denaturalizing or unlearning) Khas-Aryan-, Indian-, and Western linguistic and/or cultural colonization, how they are relinking (revisiting or relandscaPing) their Susuwa Lilim and/or Sawa Yet Hang ePistemologies, and how they are linking their cultural and linguistic identities from local to global level. In this essay, I briefly discuss delinking, relinking, and linking methodology, and how Kirat-Yakthungs are translating it into Practice. This essay demonstrates Khas-Aryan intervention and/or Khas-Aryan paracolonial intervention in the develoPment of Kirat-Yakthung writing and literacy, and Kirat-Yakthungs’ resistance for their existence. -

Proposal to Encode 0D5F MALAYALAM LETTER ARCHAIC II
Proposal to encode 0D5F MALAYALAM LETTER ARCHAIC II Shriramana Sharma, jamadagni-at-gmail-dot-com, India 2012-May-22 §1. Introduction In the Malayalam Unicode encoding, the independent letter form for the long vowel Ī is: ഈ where the length mark ◌ൗ is appended to the short vowel ഇ to parallel the symbols for U/UU i.e. ഉ/ഊ. However, Ī was originally written as: As these are entirely different representations of Ī, although their sound value may be the same, it is proposed to encode the archaic form as a separate character. §2. Background As the core Unicode encoding for the major Indic scripts is based on ISCII, and the ISCII code chart for Malayalam only contained the modern form for the independent Ī [1, p 24]: … thus it is this written form that came to be encoded as 0D08 MALAYALAM LETTER II. While this “new” written form is seen in print as early as 1936 CE [2]: … there is no doubt that the much earlier form was parallel to the modern Grantha , both of which are derived from the old Grantha Ī as seen below: 1 ma - īdṛgvidhā | tatarāya īṇ Old Grantha from the Iḷaiyānputtūr copper plates [3, p 13]. Also seen is the Vatteḻuttu Ī of the same time (line 2, 2nd char from right) which also exhibits the two dots. Of course, both are derived from old South Indian Brahmi Ī which again has the two dots. It is said [entire paragraph: Radhakrishna Warrier, personal communication] that it was the poet Vaḷḷattōḷ Nārāyaṇa Mēnōn (1878–1958) who introduced the new form of Ī ഈ. -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

A Script Independent Approach for Handwritten Bilingual Kannada and Telugu Digits Recognition
IJMI International Journal of Machine Intelligence ISSN: 0975–2927 & E-ISSN: 0975–9166, Volume 3, Issue 3, 2011, pp-155-159 Available online at http://www.bioinfo.in/contents.php?id=31 A SCRIPT INDEPENDENT APPROACH FOR HANDWRITTEN BILINGUAL KANNADA AND TELUGU DIGITS RECOGNITION DHANDRA B.V.1, GURURAJ MUKARAMBI1, MALLIKARJUN HANGARGE2 1Department of P.G. Studies and Research in Computer Science Gulbarga University, Gulbarga, Karnataka. 2Department of Computer Science, Karnatak Arts, Science and Commerce College Bidar, Karnataka. *Corresponding author. E-mail: [email protected],[email protected],[email protected] Received: September 29, 2011; Accepted: November 03, 2011 Abstract- In this paper, handwritten Kannada and Telugu digits recognition system is proposed based on zone features. The digit image is divided into 64 zones. For each zone, pixel density is computed. The KNN and SVM classifiers are employed to classify the Kannada and Telugu handwritten digits independently and achieved average recognition accuracy of 95.50%, 96.22% and 99.83%, 99.80% respectively. For bilingual digit recognition the KNN and SVM classifiers are used and achieved average recognition accuracy of 96.18%, 97.81% respectively. Keywords- OCR, Zone Features, KNN, SVM 1. Introduction recognition of isolated handwritten Kannada numerals Recent advances in Computer technology, made every and have reported the recognition accuracy of 90.50%. organization to implement the automatic processing Drawback of this procedure is that, it is not free from systems for its activities. For example, automatic thinning. U. Pal et al. [11] have proposed zoning and recognition of vehicle numbers, postal zip codes for directional chain code features and considered a feature sorting the mails, ID numbers, processing of bank vector of length 100 for handwritten Kannada numeral cheques etc.