UNICODE for Kannada General Information & Description
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

The Unicode Standard, Version 4.0--Online Edition
This PDF file is an excerpt from The Unicode Standard, Version 4.0, issued by the Unicode Consor- tium and published by Addison-Wesley. The material has been modified slightly for this online edi- tion, however the PDF files have not been modified to reflect the corrections found on the Updates and Errata page (http://www.unicode.org/errata/). For information on more recent versions of the standard, see http://www.unicode.org/standard/versions/enumeratedversions.html. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The Unicode® Consortium is a registered trademark, and Unicode™ is a trademark of Unicode, Inc. The Unicode logo is a trademark of Unicode, Inc., and may be registered in some jurisdictions. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

Tibetan Romanization Table
Tibetan Comment [LRH1]: Transliteration revisions are highlighted below in light-gray or otherwise noted in a comment. ALA-LC romanization of Tibetan letters follows the principles of the Wylie transliteration system, as described by Turrell Wylie (1959). Diacritical marks are used for those letters representing Indic or other non-Tibetan languages, and parallel the use of these marks when transcribing their counterpart letters in Sanskrit. These are applied for the sake of consistency, and to reflect international publishing standards. Accordingly, romanize words of non-Tibetan origin systematically (following this table) in all cases, even though the word may derive from Sanskrit or another language. When Tibetan is written in another script (e.g., ʼPhags-pa) the corresponding letters in that script are also romanized according to this table. Consonants (see Notes 1-3) Vernacular Romanization Vernacular Romanization Vernacular Romanization ka da zha ཀ་ ད་ ཞ་ kha na za ཁ་ ན་ ཟ་ Comment [LH2]: While the current ALA-LC ga pa ’a table stipulates that an apostrophe should be used, ག་ པ་ འ་ this revision proposal recommends that the long- nga pha ya standing defacto LC practice of using an alif (U+02BC) be continued and explicitly stipulated in ང་ ཕ་ ཡ་ the Table. See accompanying Narrative for details. ca ba ra ཅ་ བ་ ར་ cha ma la ཆ་ མ་ ལ་ ja tsa sha ཇ་ ཙ་ ཤ་ nya tsha sa ཉ་ ཚ་ ས་ ta dza ha ཏ་ ཛ་ ཧ་ tha wa a ཐ་ ཝ་ ཨ་ Vowels and Diphthongs (see Notes 4 and 5) ཨི་ i ཨཱི་ ī རྀ་ r̥ ཨུ་ u ཨཱུ་ ū རཱྀ་ r̥̄ ཨེ་ e ཨཻ་ ai ལྀ་ ḷ ཨོ་ o ཨཽ་ au ལཱྀ ḹ ā ཨཱ་ Other Letters or Diacritical Marks Used in Words of Non-Tibetan Origin (see Notes 6 and 7) ṭa gha ḍha ཊ་ གྷ་ ཌྷ་ ṭha jha anusvāra ṃ Comment [LH3]: This letter combination does ཋ་ ཇྷ་ ◌ ཾ not occur in Tibetan texts, and has been deprecated from the Unicode Standard. -

N4185 Preliminary Proposal to Encode Siddham in ISO/IEC 10646
ISO/IEC JTC1/SC2/WG2 N4185 L2/12-011R 2012-05-03 Preliminary Proposal to Encode Siddham in ISO/IEC 10646 Anshuman Pandey Department of History University of Michigan Ann Arbor, Michigan, U.S.A. [email protected] May 3, 2012 1 Introduction This is a preliminary proposal to encode the Siddham script in the Universal Character Set (ISO/IEC 10646). It is a collaborative effort between the Script Encoding Initiative (SEI) at the University of California, Berke- ley and the Shingon Buddhist International Institute, Fresno, California. Feedback is requested from experts and users of the script. Comments may be submitted to the author at the email address given above. Siddham is a Brahmi-based writing system that originated in India, but which is used primarily in East Asia. At present it is associated with esoteric Buddhist traditions in Japan. Nevertheless, Siddham is structurally an Indic script and its proposed encoding adheres to the UCS model for Brahmi-based writing systems, such as Devanagari and similar scripts. The technical description for Siddham given here may differ from the traditional analysis and philosophical interpretations of the script and its constituent characters and glyphs. An attempt has been made to encode all distinct characters attested in Siddham records, although more characters may be uncovered through additional research. The characters that are proposed for encoding have been analyzed in accordance with the character-glyph model of the UCS. As a result, the proposed encoding may contain characters that are not part of traditional character repertoires. It may also exclude characters that are traditionally regarded as independent letters, such as conjuncts, which are to be represented in the manner specified by the UCS encoding model. -
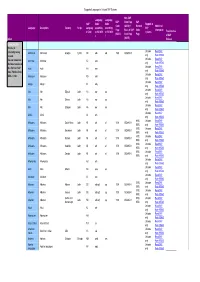
Supported Languages in Unicode SAP Systems Index Language
Supported Languages in Unicode SAP Systems Non-SAP Language Language SAP Code Page SAP SAP Code Code Support in Code (ASCII) = Blended Additional Language Description Country Script Languag according according SAP Page Basis of SAP Code Information e Code to ISO 639- to ISO 639- systems Translated as (ASCII) Code Page Page 2 1 of SAP Index (ASCII) Release Download Info: AThis list is Unicode Read SAP constantly being Abkhazian Abkhazian Georgia Cyrillic AB abk ab 1500 ISO8859-5 revised. only Note 895560 Unicode Read SAP You can download Achinese Achinese AC ace the latest version of only Note 895560 Unicode Read SAP this file from SAP Acoli Acoli AH ach Note 73606 or from only Note 895560 Unicode Read SAP SDN -> /i18n Adangme Adangme AD ada only Note 895560 Unicode Read SAP Adygei Adygei A1 ady only Note 895560 Unicode Read SAP Afar Afar Djibouti Latin AA aar aa only Note 895560 Unicode Read SAP Afar Afar Eritrea Latin AA aar aa only Note 895560 Unicode Read SAP Afar Afar Ethiopia Latin AA aar aa only Note 895560 Unicode Read SAP Afrihili Afrihili AI afh only Note 895560 6100, Unicode Read SAP Afrikaans Afrikaans South Africa Latin AF afr af 1100 ISO8859-1 6500, only Note 895560 6100, Unicode Read SAP Afrikaans Afrikaans Botswana Latin AF afr af 1100 ISO8859-1 6500, only Note 895560 6100, Unicode Read SAP Afrikaans Afrikaans Malawi Latin AF afr af 1100 ISO8859-1 6500, only Note 895560 6100, Unicode Read SAP Afrikaans Afrikaans Namibia Latin AF afr af 1100 ISO8859-1 6500, only Note 895560 6100, Unicode Read SAP Afrikaans Afrikaans Zambia -

Internationalized Domain Names-Dogri
Draft Policy Document For INTERNATIONALIZED DOMAIN NAMES Language: DOGRI 1 RECORD OF CHANGES *A - ADDED M - MODIFIED D - DELETED PAGES A* COMPLIANCE VERSION DATE AFFECTED M TITLE OR BRIEF VERSION OF NUMBER D DESCRIPTION MAIN POLICY DOCUMENT 1.0 21 January, Whole M Language Specific 2010 Document Policy Document for DOGRI 1.1 22 March, Whole M Description of 2011 Document sequence added, Variant removed 1.2 13 January, Page5,6,7 M Inclusion of Vowel 2012 Modifier(MODIFIE R LETTER APOSTROPHE) [S] after Matra [M] 1.3 01 January, All M D Modified character 1.8 2013 repertoire as per IDNA 2008 2 Table of Contents 1. AUGMENTED BACKUS-NAUR FORMALISM (ABNF) ...........................................4 1.1 Declaration of variables ....................................................................................... 4 1.2 ABNF Operators .................................................................................................. 4 1.3 The Vowel Sequence ............................................................................................ 4 1.4 Consonant Sequence ............................................................................................ 5 1.5 Sequence .............................................................................................................. 7 1.6 ABNF Applied to the DOGRI IDN ..................................................................... 7 2. RESTRICTION RULES ................................................................................................10 3. EXAMPLES: ............................................................................................................12 -

Information, Characters, Unicode
Information, Characters, Unicode Unicode © 24 August 2021 1 / 107 Hidden Moral Small mistakes can be catastrophic! Style Care about every character of your program. Tip: printf Care about every character in the program’s output. (Be reasonably tolerant and defensive about the input. “Fail early” and clearly.) Unicode © 24 August 2021 2 / 107 Imperative Thou shalt care about every Ěaracter in your program. Unicode © 24 August 2021 3 / 107 Imperative Thou shalt know every Ěaracter in the input. Thou shalt care about every Ěaracter in your output. Unicode © 24 August 2021 4 / 107 Information – Characters In modern computing, natural-language text is very important information. (“number-crunching” is less important.) Characters of text are represented in several different ways and a known character encoding is necessary to exchange text information. For many years an important encoding standard for characters has been US ASCII–a 7-bit encoding. Since 7 does not divide 32, the ubiquitous word size of computers, 8-bit encodings are more common. Very common is ISO 8859-1 aka “Latin-1,” and other 8-bit encodings of characters sets for languages other than English. Currently, a very large multi-lingual character repertoire known as Unicode is gaining importance. Unicode © 24 August 2021 5 / 107 US ASCII (7-bit), or bottom half of Latin1 NUL SOH STX ETX EOT ENQ ACK BEL BS HT LF VT FF CR SS SI DLE DC1 DC2 DC3 DC4 NAK SYN ETP CAN EM SUB ESC FS GS RS US !"#$%&’()*+,-./ 0123456789:;<=>? @ABCDEFGHIJKLMNO PQRSTUVWXYZ[\]^_ `abcdefghijklmno pqrstuvwxyz{|}~ DEL Unicode Character Sets © 24 August 2021 6 / 107 Control Characters Notice that the first twos rows are filled with so-called control characters. -

Proposal for an Oriya Script Root Zone Label Generation Ruleset (LGR)
Proposal for an Oriya Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.12 Authors: Neo-Brahmi Generation Panel [NBGP] 1 General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Root Zone Level Generation Rules for the Oriya script. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-oriya-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: oriya-test-labels-06mar19-en.txt 2 Script for which the LGR is proposed ISO 15924 Code: Orya ISO 15924 Key N°: 327 ISO 15924 English Name: Oriya (Odia) Latin transliteration of native script name: oṛiā Native name of the script: ଓଡ଼ିଆ Maximal Starting Repertoire (MSR) version: MSR-4 3 Background on Script and Principal Languages using it Oriya (amended later as Odia) is an Eastern Indic language spoken by about 40 million people (3,75,21,324 as per census 2011(http://censusindia.gov.in/2011Census/Language- 2011/Statement-4.pdf) mainly in the Indian state of Orissa, and also in parts of West Proposal for an Oriya Root Zone LGR Neo-Brahmi Generation Panel Bengal, Jharkhand, Chhattisgarh and Andhra Pradesh. Oriya(Odia) is one of the many official languages of India. It is the official language of Odisha, and the second official language of Jharkhand. -

Globalization Support Oracle Unicode Database Support
Globalization Support Oracle Unicode database support An Oracle White Paper May 2005 Oracle Unicode database support Introduction ....................................................................................................... 3 Requirement....................................................................................................... 3 What is UNICODE? ........................................................................................ 4 Supplementary Characters........................................................................... 4 Unicode Encodings ...................................................................................... 5 UTF-8 Encoding ...................................................................................... 5 UCS-2 Encoding ...................................................................................... 6 UTF-16 Encoding.................................................................................... 6 Unicode and Oracle .......................................................................................... 7 AL24UTFFSS................................................................................................ 7 UTF8 .............................................................................................................. 8 UTFE.............................................................................................................. 8 AL32UTF8 .................................................................................................... 8 AL16UTF16 ................................................................................................. -

Iso/Iec Jtc1/Sc2/Wg2 L2/12-322
ISO/IEC JTC1/SC2/WG2 N4330 L2/12-322 2012-09-27 Title: Proposal to Encode the SANDHI MARK for Sharada Source: Script Encoding Initiative (SEI) Author: Anshuman Pandey ([email protected]) Status: Liaison Contribution Action: For consideration by UTC and WG2 Date: 2012-09-27 1 Introduction This is a preliminary proposal to encode a new character in the Sharada block of the Universal Character Set (ISO/IEC 10646). Properties of the proposed character are: 111C9 Po 0 L N AL 2 Description The is used in some Sharada manuscripts for indicating external sandhi in Sanskrit documents. It is a below-base mark that is written after the syllable where sandhi occurs. The excerpt below, from Bhagavad Gītā 1.1, illustrates usage of the mark (adapted from Lokesh Chandra 1982): Here the occurs in the phrases pāṇḍavāścaiva and kimakurvata . In the first phrase, it indicates ⃓ + + ⃓ vowel sandhi between ca and eva (°a e° → °ai°); in the second it indicates fusion of a bare consonant and a vowel between kim and akurvata (°m a° → °ma°). In this manuscript of the BG, the is written twice in order to indicate sandhi between two long vowels, as in the following excerpt from BG 2.1: 1 Proposal to Encode the SANDHI MARK for Sharada Anshuman Pandey Here the doubled mark occurs in the phrase kr̥ payāvisṭ aṃ , where it indicates sandhi of identical long vowels ++ between kr̥ payā and āvisṭ aṃ (°ā ā° → °ā°). However, the double is not consistently through- out the manuscript for marking long-vowel sandhi. 3 Relationship to Avagraha The graphical shape of is similar to that of ᇁ +111C1 .