N4185 Preliminary Proposal to Encode Siddham in ISO/IEC 10646
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

75 Characters Maximum
Kannada Script LGR Proposal Introduction, Current Analysis and Next Steps Dr. U.B. Pavanaja NBGP F2F Meeting, Colombo 14 December 2017 | 1 Agenda 1 2 3 Introduction to Repertoire Analysis Within Script Kannada Script Variants 4 5 6 Cross-Script WLE Rules Current Status and Variants Next Steps for Completion | 2 Introduction to Kannada Script Population – there are about 60 million speakers of Kannada language which uses Kannada script. Geographical area - Kannada is spoken predominantly by the people of Karnataka State of India. It is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad Languages written in Kannada script – Kannada, Tulu, Kodava (Coorgi), Konkani, Havyaka, Sanketi, Beary (byaari), Arebaase, Koraga | 3 Classification of Characters Swaras (vowels) Letter ಅ ಆ ಇ ಈ ಉ ಊ ಋ ಎ ಏ ಐ ಒ ಓ ಔ Vowel sign/ N/Aಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ matra Yogavahas In Kannada, all consonants Anusvara ಅಂ (vyanjanas) when written as ಕ (ka), ಖ (kha), ಗ (ga), etc. actually have a built-in vowel sign (matra) Visarga ಅಃ of vowel ಅ (a) in them. | 4 Classification of Characters Vargeeya vyanjana (structured consonants) voiceless voiceless aspirate voiced voiced aspirate nasal Velars ಕ ಖ ಗ ಘ ಙ Palatals ಚ ಛ ಜ ಝ ಞ Retroflex ಟ ಠ ಡ ಢ ಣ Dentals ತ ಥ ದ ಧ ನ Labials ಪ ಫ ಬ ಭ ಮ Avargeeya vyanjana (unstructured consonants) ಯ ರ ಱ (obsolete) ಲ ವ ಶ ಷ ಸ ಹ ಳ ೞ (obsolete) | 5 Repertoire Included-1 Sr. Unicode Glyph Character Name Unicode Indic Ref Widespread No. Code General Syllabic use ? Point Category Category [Yes/No] 1 0C82 ಂ KANNADA SIGN ANUSVARA Mc Anusvara Yes 2 0C83 ಂ KANNADA SIGN VISARGA Mc Visarga Yes 3 0C85 ಅ KANNADA LETTER A Lo Vowel Yes 4 0C86 ಆ KANNADA LETTER AA Lo Vowel Yes 5 0C87 ಇ KANNADA LETTER I Lo Vowel Yes 6 0C88 ಈ KANNADA LETTER II Lo Vowel Yes 7 0C89 ಉ KANNADA LETTER U Lo Vowel Yes 8 0C8A ಊ KANNADA LETTER UU Lo Vowel Yes KANNADA LETTER VOCALIC 9 0C8B ಋ R Lo Vowel Yes 10 0C8E ಎ KANNADA LETTER E Lo Vowel Yes | 6 Repertoire Included-2 Sr. -

UNICODE for Kannada General Information & Description
UNICODE for Kannada (U+0C80 to U+0CFF) General Information & Description Written by: C V Srinatha Sastry Issued by: Director Directorate of Information Technology Government of Karnataka Multi Storied Buildings, Vidhana Veedhi BANGALORE 560 001 INDIA PDF created with FinePrint pdfFactory Pro trial version http://www.pdffactory.com UNICODE for Kannada Introduction The Kannada script is a South Indian script. It is used to write Kannada language of Karnataka State in India. This is also used in many parts of Tamil Nadu, Kerala, Andhra Pradesh and Maharashtra States of India. In addition, the Kannada script is also used to write Tulu, Konkani and Kodava languages. Kannada along with other Indian language scripts shares a large number of structural features. The Kannada block of Unicode Standard (0C80 to 0CFF) is based on ISCII-1988 (Indian Standard Code for Information Interchange). The Unicode Standard (version 3) encodes Kannada characters in the same relative positions as those coded in the ISCII-1988 standard. The Writing system that employs Kannada script constitutes a cross between syllabic writing systems and phonemic writing systems (alphabets). The effective unit of writing Kannada is the orthographic syllable consisting of a consonant (Vyanjana) and vowel (Vowel) (CV) core and optionally, one or more preceding consonants, with a canonical structure of ((C)C)CV. The orthographic syllable need not correspond exactly with a phonological syllable, especially when a consonant cluster is involved, but the writing system is built on phonological principles and tends to correspond quite closely to pronunciation. The orthographic syllable is built up of alphabetic pieces, the actual letters of Kannada script. -
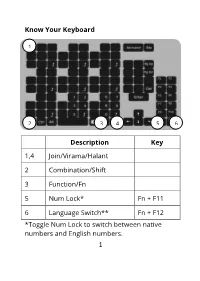
Know Your Keyboard Description Key 1,4 Join/Virama/Halant 2
Know Your Keyboard 1 2 3 4 5 6 Description Key 1,4 Join/Virama/Halant 2 Combination/Shift 3 Function/Fn 5 Num Lock* Fn + F11 6 Language Switch** Fn + F12 *Toggle Num Lock to switch between native numbers and English numbers. 1 ** Language Switch works on Windows, Linux and Android. For macOS, a configuration in settings is required. Note: If numbers are appearing in English, turn off Num Lock. Connecting Your Keyboard To Computer – Plug-in the cable to USB port on your computer. To Android Phone/Tablet 3 2 1 Use USB-to-OTG connector to plug-in keyboard. 2 Language and Layout You can use one keyboard to type multiple languages. You need to install at least one language to type. Language Layout Bengali Ka-Naada Bengali Keyboard Assamese Devanagari Sanskrit Hindi Ka-Naada Hindi Keyboard Marathi Neapli English Ka-Naada English Keyboard Guajarati Ka-Naada Guajarati Keyboard Kannada Ka-Naada Kannada Keyboard Malayalam Ka-Naada Malayalam Keyboard Tulu Odiya Ka-Naada Odiya Keyboard Panjabi Ka-Naada Gurmukhi Keyboard Telugu Ka-Naada Telugu Keyboard 3 Note: You need to switch to Ka-Naada input language before typing. Note: To switch between the languages you’re using, repeatedly press Language Switch key to cycle through all your installed languages. Language Pack Installation Go to https://ka-naada.com/downloads/ and click on the “Download” button in front of your operating system. Installation – Windows 1. Open your “Downloads” folder and locate “kanaada_keyboards.zip”. 2. Right click on zip file and choose “Extract Here” from the option menu. 3. -

Analysis of Comments for Telugu Script LGR Proposal for the Root Zone Revision: June 30, 2019
Neo-Brahmi Generation Panel: Analysis of comments for Telugu script LGR Proposal for the Root Zone Revision: June 30, 2019 Neo-Brahmi Generation Panel (NBGP) published the Telugu script LGR Propsoal for the Root Zone for public comment on 8 August 2018. This document is an additional document of the public comment report, collecting NBGP analyses as well as the concluded responses. There is 1 (one) comment submission. The analysis is as follow: No. 1 From Liang Hai Subject A Quick review of the Telugu proposal Comment 2, “telɯgɯ”: This is probably a phonetic transcription, not an accurate transliteration that should be used in this document. NBGP The NBGP acknowledges the comment. Analysis NBGP Updated the proposal in section 2 to use ‘Telugu’ Response Comment 3.5, “… and 16 dependent signs”: 15. NBGP There are 16 Matras: 14 Matras are in the repertoire, 2 Matras are Analysis excluded from the repertoire. NBGP No action required. Response Comment 3.5.1: Vocalic l should be categorized with vocalic rr and vocalic ll. Transliteration of vocalic ll is wrong. NBGP Agree. Analysis NBGP Update as suggested. Response 1 Comment 3.5.1, R1, “ca= a consonant with an inherent ‘a’”: When discussing text encoding, Indic consonants naturally are with an inherent vowel. Try to distinguish phonetic seQuence and written forms and encoded character sequence. The 3 lines under R1 are not helpful. NBGP The comment does not affect the normative part of the LGR. Analysis NBGP No action required. Response Comment 3.5.3: The introduction of arasunna usage is unclear. Is it commonly used today or not? NBGP The arsunna is not used frequently and it is not in the MSR. -

The Unicode Standard, Version 4.0--Online Edition
This PDF file is an excerpt from The Unicode Standard, Version 4.0, issued by the Unicode Consor- tium and published by Addison-Wesley. The material has been modified slightly for this online edi- tion, however the PDF files have not been modified to reflect the corrections found on the Updates and Errata page (http://www.unicode.org/errata/). For information on more recent versions of the standard, see http://www.unicode.org/standard/versions/enumeratedversions.html. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The Unicode® Consortium is a registered trademark, and Unicode™ is a trademark of Unicode, Inc. The Unicode logo is a trademark of Unicode, Inc., and may be registered in some jurisdictions. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

Tibetan Romanization Table
Tibetan Comment [LRH1]: Transliteration revisions are highlighted below in light-gray or otherwise noted in a comment. ALA-LC romanization of Tibetan letters follows the principles of the Wylie transliteration system, as described by Turrell Wylie (1959). Diacritical marks are used for those letters representing Indic or other non-Tibetan languages, and parallel the use of these marks when transcribing their counterpart letters in Sanskrit. These are applied for the sake of consistency, and to reflect international publishing standards. Accordingly, romanize words of non-Tibetan origin systematically (following this table) in all cases, even though the word may derive from Sanskrit or another language. When Tibetan is written in another script (e.g., ʼPhags-pa) the corresponding letters in that script are also romanized according to this table. Consonants (see Notes 1-3) Vernacular Romanization Vernacular Romanization Vernacular Romanization ka da zha ཀ་ ད་ ཞ་ kha na za ཁ་ ན་ ཟ་ Comment [LH2]: While the current ALA-LC ga pa ’a table stipulates that an apostrophe should be used, ག་ པ་ འ་ this revision proposal recommends that the long- nga pha ya standing defacto LC practice of using an alif (U+02BC) be continued and explicitly stipulated in ང་ ཕ་ ཡ་ the Table. See accompanying Narrative for details. ca ba ra ཅ་ བ་ ར་ cha ma la ཆ་ མ་ ལ་ ja tsa sha ཇ་ ཙ་ ཤ་ nya tsha sa ཉ་ ཚ་ ས་ ta dza ha ཏ་ ཛ་ ཧ་ tha wa a ཐ་ ཝ་ ཨ་ Vowels and Diphthongs (see Notes 4 and 5) ཨི་ i ཨཱི་ ī རྀ་ r̥ ཨུ་ u ཨཱུ་ ū རཱྀ་ r̥̄ ཨེ་ e ཨཻ་ ai ལྀ་ ḷ ཨོ་ o ཨཽ་ au ལཱྀ ḹ ā ཨཱ་ Other Letters or Diacritical Marks Used in Words of Non-Tibetan Origin (see Notes 6 and 7) ṭa gha ḍha ཊ་ གྷ་ ཌྷ་ ṭha jha anusvāra ṃ Comment [LH3]: This letter combination does ཋ་ ཇྷ་ ◌ ཾ not occur in Tibetan texts, and has been deprecated from the Unicode Standard. -

A Barrier to Indic-Language Implementation of Unicode Is the Perception That Encoding Order in Unicode Is Equivalent to Lingui
Issues in Indic Language Collation Issues in Indic Language Collation Cathy Wissink Program Manager, Windows Globalization Microsoft Corporation I. Introduction As the software market for India1 grows, so does the interest in developing products for this market, and Unicode is part of many vendors’ solutions. However, many software vendors see a barrier to implementing Unicode on products for the Indic-language market. This barrier is the perception that deficiencies in Unicode will keep software developers from creating products that are culturally and linguistically appropriate for the Indian market. This perception manifests itself in a number of ways, but one major concern that the Indic language community has voiced is the fact that the Unicode character encoding order is not appropriate for linguistic collation (or sorting). This belief that character encoding order in Unicode must be equivalent to linguistic collation of these same scripts and their respective languages is considered by some developers a blocking point to adoption of Unicode in the Indian market, and is indicative of the greater concern within the Indic-language community about the feasibility of Unicode for their scripts. This paper will demonstrate that this perceived barrier to Unicode adoption does not exist and that it is possible to provide properly globalized software for the Indic market with the current implementation of Unicode, using the example of Indic language collation. A brief history of Indic encodings will be given to set the stage for the current mentality regarding Unicode in the Indian market. The basics of linguistic collation and its application to Indic scripts will then be discussed, compared to encoding, and demonstrated as it exists on Windows XP. -

World Braille Usage, Third Edition
World Braille Usage Third Edition Perkins International Council on English Braille National Library Service for the Blind and Physically Handicapped Library of Congress UNESCO Washington, D.C. 2013 Published by Perkins 175 North Beacon Street Watertown, MA, 02472, USA International Council on English Braille c/o CNIB 1929 Bayview Avenue Toronto, Ontario Canada M4G 3E8 and National Library Service for the Blind and Physically Handicapped, Library of Congress, Washington, D.C., USA Copyright © 1954, 1990 by UNESCO. Used by permission 2013. Printed in the United States by the National Library Service for the Blind and Physically Handicapped, Library of Congress, 2013 Library of Congress Cataloging-in-Publication Data World braille usage. — Third edition. page cm Includes index. ISBN 978-0-8444-9564-4 1. Braille. 2. Blind—Printing and writing systems. I. Perkins School for the Blind. II. International Council on English Braille. III. Library of Congress. National Library Service for the Blind and Physically Handicapped. HV1669.W67 2013 411--dc23 2013013833 Contents Foreword to the Third Edition .................................................................................................. viii Acknowledgements .................................................................................................................... x The International Phonetic Alphabet .......................................................................................... xi References ............................................................................................................................ -

Internationalized Domain Names-Dogri
Draft Policy Document For INTERNATIONALIZED DOMAIN NAMES Language: DOGRI 1 RECORD OF CHANGES *A - ADDED M - MODIFIED D - DELETED PAGES A* COMPLIANCE VERSION DATE AFFECTED M TITLE OR BRIEF VERSION OF NUMBER D DESCRIPTION MAIN POLICY DOCUMENT 1.0 21 January, Whole M Language Specific 2010 Document Policy Document for DOGRI 1.1 22 March, Whole M Description of 2011 Document sequence added, Variant removed 1.2 13 January, Page5,6,7 M Inclusion of Vowel 2012 Modifier(MODIFIE R LETTER APOSTROPHE) [S] after Matra [M] 1.3 01 January, All M D Modified character 1.8 2013 repertoire as per IDNA 2008 2 Table of Contents 1. AUGMENTED BACKUS-NAUR FORMALISM (ABNF) ...........................................4 1.1 Declaration of variables ....................................................................................... 4 1.2 ABNF Operators .................................................................................................. 4 1.3 The Vowel Sequence ............................................................................................ 4 1.4 Consonant Sequence ............................................................................................ 5 1.5 Sequence .............................................................................................................. 7 1.6 ABNF Applied to the DOGRI IDN ..................................................................... 7 2. RESTRICTION RULES ................................................................................................10 3. EXAMPLES: ............................................................................................................12 -

Proposal to Annotate Brahmi Sign Anusvara Vinodh Rajan [email protected] Shriramana Sharma [email protected]
P a g e | 1 Proposal to Annotate Brahmi Sign Anusvara Vinodh Rajan [email protected] Shriramana Sharma [email protected] 1 Introduction L2/19-402 initially proposed the addition of 6 Old Tamil characters to the Brahmi block, out of which 5 were accepted by the UTC #162 in January 2020. The dot-shaped Old Tamil Virama was not accepted due to the block already having another dot-shaped character i.e. U+11001 the Brahmi Anusvara character, which could possibly be repurposed to represent the Old Tamil Virama. It was also suggested to reconsider the unification with the existing Virama character. This document proposes the unification of the Brahmi Anusvara and the Old Tamil Virama and requests that the existing Brahmi Anusvara character be annotated for its additional usage as the Tamil-Brahmi Virama. 2 Positioning of Brahmi Anusvara and Tamil-Brahmi Virama The Brahmi Anusvara is a dot-shaped character usually placed at the top-right position. However, it may also be placed at the top or even at the bottom-right position. Below shown are examples from Indoskript1 for occurrences of the following syllables - /aṃ/, /khaṃ/, /kiṃ/, /tuṃ/ & /luṃ/ - between 300 BCE and 100 CE. 1 http://userpage.fu-berlin.de/falk/ P a g e | 2 Old Tamil Virama is also a dot-shaped character, which can occur in multiple positions. From Early Tamil Epigraphy by Iravatham Mahadevan https://www.cmi.ac.in/gift/Epigraphy/epig_vikramangalam_not%20considered.htm Standardized representation of Tamil in recent books also shows variation in positioning: http://know-your-heritage.blogspot.com/p/blog-page_14.html Old Tamil Virama occurring at the top position P a g e | 3 https://www.newindianexpress.com/states/tamil-nadu/2018/dec/12/this-is-how-thiruvalluvar-wrote- thirukkural-couplets-1910278.html Old Tamil Virama occurring to the left As it can been seen, both the Anusvara and the Old Tamil Virama are dot-shaped characters with variable positioning. -

General Historical and Analytical / Writing Systems: Recent Script
9 Writing systems Edited by Elena Bashir 9,1. Introduction By Elena Bashir The relations between spoken language and the visual symbols (graphemes) used to represent it are complex. Orthographies can be thought of as situated on a con- tinuum from “deep” — systems in which there is not a one-to-one correspondence between the sounds of the language and its graphemes — to “shallow” — systems in which the relationship between sounds and graphemes is regular and trans- parent (see Roberts & Joyce 2012 for a recent discussion). In orthographies for Indo-Aryan and Iranian languages based on the Arabic script and writing system, the retention of historical spellings for words of Arabic or Persian origin increases the orthographic depth of these systems. Decisions on how to write a language always carry historical, cultural, and political meaning. Debates about orthography usually focus on such issues rather than on linguistic analysis; this can be seen in Pakistan, for example, in discussions regarding orthography for Kalasha, Wakhi, or Balti, and in Afghanistan regarding Wakhi or Pashai. Questions of orthography are intertwined with language ideology, language planning activities, and goals like literacy or standardization. Woolard 1998, Brandt 2014, and Sebba 2007 are valuable treatments of such issues. In Section 9.2, Stefan Baums discusses the historical development and general characteristics of the (non Perso-Arabic) writing systems used for South Asian languages, and his Section 9.3 deals with recent research on alphasyllabic writing systems, script-related literacy and language-learning studies, representation of South Asian languages in Unicode, and recent debates about the Indus Valley inscriptions.