A Barrier to Indic-Language Implementation of Unicode Is the Perception That Encoding Order in Unicode Is Equivalent to Lingui
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PROC SORT (Then And) NOW Derek Morgan, PAREXEL International
Paper 143-2019 PROC SORT (then and) NOW Derek Morgan, PAREXEL International ABSTRACT The SORT procedure has been an integral part of SAS® since its creation. The sort-in-place paradigm made the most of the limited resources at the time, and almost every SAS program had at least one PROC SORT in it. The biggest options at the time were to use something other than the IBM procedure SYNCSORT as the sorting algorithm, or whether you were sorting ASCII data versus EBCDIC data. These days, PROC SORT has fallen out of favor; after all, PROC SQL enables merging without using PROC SORT first, while the performance advantages of HASH sorting cannot be overstated. This leads to the question: Is the SORT procedure still relevant to any other than the SAS novice or the terminally stubborn who refuse to HASH? The answer is a surprisingly clear “yes". PROC SORT has been enhanced to accommodate twenty-first century needs, and this paper discusses those enhancements. INTRODUCTION The largest enhancement to the SORT procedure is the addition of collating sequence options. This is first and foremost recognition that SAS is an international software package, and SAS users no longer work exclusively with English-language data. This capability is part of National Language Support (NLS) and doesn’t require any additional modules. You may use standard collations, SAS-provided translation tables, custom translation tables, standard encodings, or rules to produce your sorted dataset. However, you may only use one collation method at a time. USING STANDARD COLLATIONS, TRANSLATION TABLES AND ENCODINGS A long time ago, SAS would allow you to sort data using ASCII rules on an EBCDIC system, and vice versa. -

75 Characters Maximum
Kannada Script LGR Proposal Introduction, Current Analysis and Next Steps Dr. U.B. Pavanaja NBGP F2F Meeting, Colombo 14 December 2017 | 1 Agenda 1 2 3 Introduction to Repertoire Analysis Within Script Kannada Script Variants 4 5 6 Cross-Script WLE Rules Current Status and Variants Next Steps for Completion | 2 Introduction to Kannada Script Population – there are about 60 million speakers of Kannada language which uses Kannada script. Geographical area - Kannada is spoken predominantly by the people of Karnataka State of India. It is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad Languages written in Kannada script – Kannada, Tulu, Kodava (Coorgi), Konkani, Havyaka, Sanketi, Beary (byaari), Arebaase, Koraga | 3 Classification of Characters Swaras (vowels) Letter ಅ ಆ ಇ ಈ ಉ ಊ ಋ ಎ ಏ ಐ ಒ ಓ ಔ Vowel sign/ N/Aಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ matra Yogavahas In Kannada, all consonants Anusvara ಅಂ (vyanjanas) when written as ಕ (ka), ಖ (kha), ಗ (ga), etc. actually have a built-in vowel sign (matra) Visarga ಅಃ of vowel ಅ (a) in them. | 4 Classification of Characters Vargeeya vyanjana (structured consonants) voiceless voiceless aspirate voiced voiced aspirate nasal Velars ಕ ಖ ಗ ಘ ಙ Palatals ಚ ಛ ಜ ಝ ಞ Retroflex ಟ ಠ ಡ ಢ ಣ Dentals ತ ಥ ದ ಧ ನ Labials ಪ ಫ ಬ ಭ ಮ Avargeeya vyanjana (unstructured consonants) ಯ ರ ಱ (obsolete) ಲ ವ ಶ ಷ ಸ ಹ ಳ ೞ (obsolete) | 5 Repertoire Included-1 Sr. Unicode Glyph Character Name Unicode Indic Ref Widespread No. Code General Syllabic use ? Point Category Category [Yes/No] 1 0C82 ಂ KANNADA SIGN ANUSVARA Mc Anusvara Yes 2 0C83 ಂ KANNADA SIGN VISARGA Mc Visarga Yes 3 0C85 ಅ KANNADA LETTER A Lo Vowel Yes 4 0C86 ಆ KANNADA LETTER AA Lo Vowel Yes 5 0C87 ಇ KANNADA LETTER I Lo Vowel Yes 6 0C88 ಈ KANNADA LETTER II Lo Vowel Yes 7 0C89 ಉ KANNADA LETTER U Lo Vowel Yes 8 0C8A ಊ KANNADA LETTER UU Lo Vowel Yes KANNADA LETTER VOCALIC 9 0C8B ಋ R Lo Vowel Yes 10 0C8E ಎ KANNADA LETTER E Lo Vowel Yes | 6 Repertoire Included-2 Sr. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -

Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-04-22 Document version: 2.7 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract This document lays down the Label Generation Ruleset for Gurmukhi script. Three main components of the Gurmukhi Script LGR i.e. Code point repertoire, Variants and Whole Label Evaluation Rules have been described in detail here. All these components have been incorporated in a machine-readable format in the accompanying XML file named "proposal-gurmukhi-lgr-22apr19-en.xml". In addition, a document named “gurmukhi-test-labels-22apr19-en.txt” has been provided. It provides a list of labels which can produce variants as laid down in Section 6 of this document and it also provides valid and invalid labels as per the Whole Label Evaluation laid down in Section 7. 2. Script for which the LGR is proposed ISO 15924 Code: Guru ISO 15924 Key N°: 310 ISO 15924 English Name: Gurmukhi Latin transliteration of native script name: gurmukhī Native name of the script: ਗੁਰਮੁਖੀ Maximal Starting Repertoire [MSR] version: 4 1 3. Background on Script and Principal Languages Using It 3.1. The Evolution of the Script Like most of the North Indian writing systems, the Gurmukhi script is a descendant of the Brahmi script. The Proto-Gurmukhi letters evolved through the Gupta script from 4th to 8th century, followed by the Sharda script from 8th century onwards and finally adapted their archaic form in the Devasesha stage of the later Sharda script, dated between the 10th and 14th centuries. -

Computer Science II
Computer Science II Dr. Chris Bourke Department of Computer Science & Engineering University of Nebraska|Lincoln Lincoln, NE 68588, USA http://chrisbourke.unl.edu [email protected] 2019/08/15 13:02:17 Version 0.2.0 This book is a draft covering Computer Science II topics as presented in CSCE 156 (Computer Science II) at the University of Nebraska|Lincoln. This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License i Contents 1 Introduction1 2 Object Oriented Programming3 2.1 Introduction.................................... 3 2.2 Objects....................................... 4 2.3 The Four Pillars.................................. 4 2.3.1 Abstraction................................. 4 2.3.2 Encapsulation................................ 4 2.3.3 Inheritance ................................. 4 2.3.4 Polymorphism................................ 4 2.4 SOLID Principles................................. 4 2.4.1 Inversion of Control............................. 4 3 Relational Databases5 3.1 Introduction.................................... 5 3.2 Tables ....................................... 9 3.2.1 Creating Tables...............................10 3.2.2 Primary Keys................................16 3.2.3 Foreign Keys & Relating Tables......................18 3.2.4 Many-To-Many Relations .........................22 3.2.5 Other Keys .................................24 3.3 Structured Query Language ...........................26 3.3.1 Creating Data................................28 3.3.2 Retrieving Data...............................30 -

Unicode Collators
Title stata.com unicode collator — Language-specific Unicode collators Description Syntax Remarks and examples Also see Description unicode collator list lists the subset of locales that have language-specific collators for the Unicode string comparison functions: ustrcompare(), ustrcompareex(), ustrsortkey(), and ustrsortkeyex(). Syntax unicode collator list pattern pattern is one of all, *, *name*, *name, or name*. If you specify nothing, all, or *, then all results will be listed. *name* lists all results containing name; *name lists all results ending with name; and name* lists all results starting with name. Remarks and examples stata.com Remarks are presented under the following headings: Overview of collation The role of locales in collation Further controlling collation Overview of collation Collation is the process of comparing and sorting Unicode character strings as a human might logically order them. We call this ordering strings in a language-sensitive manner. To do this, Stata uses a Unicode tool known as the Unicode collation algorithm, or UCA. To perform language-sensitive string sorts, you must combine ustrsortkey() or ustr- sortkeyex() with sort. It is a complicated process and there are several issues about which you need to be aware. For details, see [U] 12.4.2.5 Sorting strings containing Unicode characters. To perform language-sensitive string comparisons, you can use ustrcompare() or ustrcompareex(). For details about the UCA, see http://www.unicode.org/reports/tr10/. The role of locales in collation During collation, Stata can use the default collator or it can perform language-sensitive string comparisons or sorts that require knowledge of a locale. A locale identifies a community with a certain set of preferences for how their language should be written; see [U] 12.4.2.4 Locales in Unicode. -

"9-41516)9? "9787:)4 ;7 -6+7,- )=1 16 ;0- & $
L2/20-256 "9-41516)9?"9787:)4;7-6+7,-)=116;0-&$ ᭛᭜᭛ <;079 ,1;?))?<"-9,)6)215-14,7;3755/5)14+75 40)5 <9=)6:)0140)56<9=)6:)0/5)14+75 );- ;0$-8;-5*-9 6;97,<+;176 ,=:#6L>H8G>EI>H6=>HIDG>86AG6=B>76H:9H8G>EI;DJC9>CK6G>DJH>CH8G>EI>DCH6C96GI:;68IHEGD9J8:97:IL::CI=: I=6C9I=: I=8:CIJGN>C>CHJA6G+DJI=:6HIH>6A6G<:EDGI>DCD;>IH8DGEJH>H;DJC9>C"6K67JI#6L>B6I:G>6AH =6K:6AHD7::C;DJC9>C+JB6IG6%6A6N(:C>CHJA66A>6C9I=:(=>A>EE>C:H,=:H8G>EI>H;G:FJ:CIAN6HHD8>6I:9L>I= I=:'A9"6K6C:H:A6C<J6<:7JIB6I:G>6AHLG>II:C>C+6CH@G>I'A9%6A6N'A96A>C:H:6C9'A9+JC96C:H:A6C<J6<: =6H6AHD7::C;DJC9>CI=:#6L>H8G>EIGDBI=:B>9I=8:CIJGNH>BEA:;JC8I>DC6A#6L>L6HL>9:ANJH:9IDG:8DG9 A6C9 <G6CIH GDN6A :9>8IH 6C9 H>B>A6G 8=6C8:GN 9D8JB:CIH ,DL6G9H I=: :C9 D; I=: ;>GHI B>AA:CC>JB I=: H8G>EI 7:86B:>C8G:6H>C<AN9:8DG6I>K:6C986AA><G6E=>89J:ID>IHJH:6HI=:B6>CK:=>8A:D;'A9"6K6C:H:A>I:G6GNA6C<J6<: L>I=ADC<A6HI>C<A:<68N>CI=:A>I:G6GNIG69>I>DCD;I=:BD9:GC"6K6C:H:6C96A>C:H:A6C<J6<:H$6I:G#6L>H=DLH B6CNK6G>6I>DCHDK:G6L>9:<:D<G6E=>89>HIG>7JI>DC'K:GI>B:I=:H:K6G>6CIH=6K::KDAK:9>G:8IANDG>C9>G:8IAN >CIDI=:B6CNBD9:GCG6=B>8H8G>EIHD;>CHJA6G+H>6HJ8=6H6A>C:H:6I6@"6K6C:H:$DCI6G6:I8 /=>A:I=:68I>K:JH:D;#6L>H8G>EI=6H7::CG:EA68:97NDI=:GH8G>EIHH>C8:I=: I=8:CIJGNI=:G:6G:6CJB7:GD; BD9:GC96N:CI=JH>6HIH6C98DBBJC>I>:HL=DJH:I=:H8G>EIID96N;DGDI=:GEJGEDH:HI=6C6C8>:CIG:EGD9J8I>DC ;DG:M6BEA:ID8=6I>CHD8>6A6EEA>86I>DC6C98G:6I:>B6<:EDHIH!CI=>HG:K>K6AINE:D;JH:I=:#6L>H8G>EIB6N7: JH:9IDLG>I:A6C<J6<:HI=6I6G:CDI;DJC9>C‘6JI=:CI>8’#6L>8DGEJHHJ8=6HI=:BD9:GC"6K6C:H:A6C<J6<:DG I=: !C9DC:H>6C A6C<J6<: H#6L>=6H CDI 7::C :C8D9:9>C I=: -C>8D9: N:I I=: -

Braille Decoding Device Employing Microcontroller
International Journal of Recent Technology and Engineering (IJRTE) ISSN: 2277-3878, Volume-8, Issue-2S11, September 2019 Braille Decoding Device Employing Microcontroller Kanika Jindal, Adittee Mattoo, Bhupendra Kumar Abstract—The Braille decoding method has been The proposed circuit has primary objective to recognize conventionally used by the visually challenged persons to read Braille character inputs from a visually challenged user and books etc. The designed system in the current paper has transmit them to another similar Braille device. This system implemented a method to interface the Braille characters and has been embedded onto a glove that can be worn by the blind English text characters. The system will help to communicate the Braille message from one visually challenged person to another as person. The first four fingers of the glove, starting from the well as help us to transform the Braille language to English text thumb will fitted with tactile micro switches and a vibration through a microcontroller and a PC in order to communicate with motor. This circuit is then connected with a microcontroller the visually challenged persons and PC via RS232C cable to interface the Braille words with the PC based text language. The switch pressed by any person Keyword: Universal synchronous/Asynchronous will create a Braille code that should be converted to ASCII receiver/transmitter, braille, PWM, Vibration Motor, Transistor, form by ASCII conversion program for microcontroller and Diode. these letters will be seen on computer screen. This is used in I. INTRODUCTION order to make the characters USART compatible. Similarly, the computer text word will be reverse programmed into Braille mechanism was founded by Louis Braille in 1821. -

Design of Javanese Text to Speech Application
Design of Javanese Text to Speech Application Yulia, Liliana, Rudy Adipranata, Gregorius Satia Budhi Informatics Department, Industrial Technology Faculty, Petra Christian University Surabaya, Indonesia [email protected] Abstract—Javanese is one of the many regional languages used in Indonesia. Javanese language is used by most of the population in Java. But now along with the development of the era, the use of regional languages including Javanese language is to be re- duced especially among the younger generation. One way to help conserve the use of Javanese language is to utilize information technologies, one of them is by developing a text to speech appli- cation that can be used to find out how the pronunciation of Ja- vanese language. In this paper, we discussed the design for Java- nese text to speech applications uses finite state automata. The design result will be used as rules to separate syllables when im- plementing text to speech application. Index Terms—Javanese language; Finite state automata; Text to speech. Figure 1: Basic Javanese characters I. INTRODUCTION In addition to the basic characters, the Javanese character Javanese language is a language widely spoken by the peo- has supplementary characters, consist of symbols for express- ple of Java. It is one of the regional languages of many region- ing vowels as well as a combination of two specific conso- al languages spoken in Indonesia. As one of the assets of na- nants. This supplementary characters is called sandhangan tional culture, Javanese language needs to be preserved. The and can be seen in Figure 2 [5]. younger generation is now more interested in learning a for- Symbol Example Read eign language, rather than the native Indonesian local lan- guage. -

Program Details
Home Program Hotel Be an Exhibitor Be a Sponsor Review Committee Press Room Past Events Contact Us Program Details Monday, November 3, 2014 08:30-10:00 MORNING TUTORIALS Track 1: An Introduction to Writing Systems & Unicode Presenter: This tutorial will provide you with a good understanding of the many unique characteristics of non-Latin Richard Ishida writing systems, and illustrate the problems involved in implementing such scripts in products. It does not Internationalization provide detailed coding advice, but does provide the essential background information you need to Activity Lead, W3C understand the fundamental issues related to Unicode deployment, across a wide range of scripts. It has proved to be an excellent orientation for newcomers to the conference, providing the background needed to assist understanding of the other talks! The tutorial goes beyond encoding issues to discuss characteristics related to input of ideographs, combining characters, context-dependent shape variation, text direction, vowel signs, ligatures, punctuation, wrapping and editing, font issues, sorting and indexing, keyboards, and more. The concepts are introduced through the use of examples from Chinese, Japanese, Korean, Arabic, Hebrew, Thai, Hindi/Tamil, Russian and Greek. While the tutorial is perfectly accessible to beginners, it has also attracted very good reviews from people at an intermediate and advanced level, due to the breadth of scripts discussed. No prior knowledge is needed. Presenters: Track 2: Localization Workshop Daniel Goldschmidt Two highly experienced industry experts will illuminate the basics of localization for session participants Sr. International over the course of three one-hour blocks. This instruction is particularly oriented to participants who are Program Manager, new to localization. -

MSDB Foundation Provides Digital Braille Access Family Learning Weekends Have Become a Successful Tradition
MONTANA SCHOOL for the DEAF & BLIND ExpressVolume XIII, Issue 3, Summer 2015 giving kids the building blocks to independence MSDB Foundation Provides Digital Braille Access PAGES 8-9 Family Learning Weekends Have Become a Successful Tradition PAGE 16 Russian Peer to Peer Exchange By Pam Boespflug, Outreach Consultant n late April the MSDB family had an opportunity to host a group of staff and students from the Lipetsk school for the Blind in Russia. Four adults and five students arrived in Great Falls, where they observed MSDB classes and toured local sites for a week. I In exchange, an MSDB contingent traveled to Russia the following month. Superintendent Donna Sorensen, Outreach Supervisor and instigator of this awesome project Carol Clayton-Bye, teacher Diane Blake, student Seri Brammer, and I left for Russia on May 11. We flew into Moscow and were met by the Lipetsk School van and staff. We had plenty of time to visit on our 6 hour drive with our English teacher/ Interpreter Oksana and our host Svetlana, whom Carol had worked with for three years. We were introduced to our host families that evening and arrived the next morning at school to a jazz band serenade and the traditional bread and salt ceremony. The week in Lipetsk went fast as we visited many classes at the school of over Left to right: Donna Sorensen, Igor Batishcheva, Carol 500 students including those in distance education. Clayton-Bye, Pam Boespflug, Seri Brammer, Diana Blake, We also toured the local city, statues and cathedrals, and Svetlana Veretennikova. We are standing in front of a museums, a zoo, summer camps, and got to know our fountain for preserving eyesight just outside of Lipetsk. -
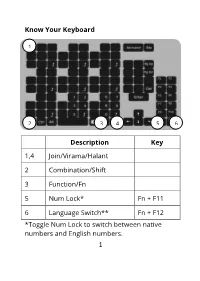
Know Your Keyboard Description Key 1,4 Join/Virama/Halant 2
Know Your Keyboard 1 2 3 4 5 6 Description Key 1,4 Join/Virama/Halant 2 Combination/Shift 3 Function/Fn 5 Num Lock* Fn + F11 6 Language Switch** Fn + F12 *Toggle Num Lock to switch between native numbers and English numbers. 1 ** Language Switch works on Windows, Linux and Android. For macOS, a configuration in settings is required. Note: If numbers are appearing in English, turn off Num Lock. Connecting Your Keyboard To Computer – Plug-in the cable to USB port on your computer. To Android Phone/Tablet 3 2 1 Use USB-to-OTG connector to plug-in keyboard. 2 Language and Layout You can use one keyboard to type multiple languages. You need to install at least one language to type. Language Layout Bengali Ka-Naada Bengali Keyboard Assamese Devanagari Sanskrit Hindi Ka-Naada Hindi Keyboard Marathi Neapli English Ka-Naada English Keyboard Guajarati Ka-Naada Guajarati Keyboard Kannada Ka-Naada Kannada Keyboard Malayalam Ka-Naada Malayalam Keyboard Tulu Odiya Ka-Naada Odiya Keyboard Panjabi Ka-Naada Gurmukhi Keyboard Telugu Ka-Naada Telugu Keyboard 3 Note: You need to switch to Ka-Naada input language before typing. Note: To switch between the languages you’re using, repeatedly press Language Switch key to cycle through all your installed languages. Language Pack Installation Go to https://ka-naada.com/downloads/ and click on the “Download” button in front of your operating system. Installation – Windows 1. Open your “Downloads” folder and locate “kanaada_keyboards.zip”. 2. Right click on zip file and choose “Extract Here” from the option menu. 3.