Proposal to Annotate Brahmi Sign Anusvara Vinodh Rajan [email protected] Shriramana Sharma [email protected]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

75 Characters Maximum
Kannada Script LGR Proposal Introduction, Current Analysis and Next Steps Dr. U.B. Pavanaja NBGP F2F Meeting, Colombo 14 December 2017 | 1 Agenda 1 2 3 Introduction to Repertoire Analysis Within Script Kannada Script Variants 4 5 6 Cross-Script WLE Rules Current Status and Variants Next Steps for Completion | 2 Introduction to Kannada Script Population – there are about 60 million speakers of Kannada language which uses Kannada script. Geographical area - Kannada is spoken predominantly by the people of Karnataka State of India. It is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad Languages written in Kannada script – Kannada, Tulu, Kodava (Coorgi), Konkani, Havyaka, Sanketi, Beary (byaari), Arebaase, Koraga | 3 Classification of Characters Swaras (vowels) Letter ಅ ಆ ಇ ಈ ಉ ಊ ಋ ಎ ಏ ಐ ಒ ಓ ಔ Vowel sign/ N/Aಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ matra Yogavahas In Kannada, all consonants Anusvara ಅಂ (vyanjanas) when written as ಕ (ka), ಖ (kha), ಗ (ga), etc. actually have a built-in vowel sign (matra) Visarga ಅಃ of vowel ಅ (a) in them. | 4 Classification of Characters Vargeeya vyanjana (structured consonants) voiceless voiceless aspirate voiced voiced aspirate nasal Velars ಕ ಖ ಗ ಘ ಙ Palatals ಚ ಛ ಜ ಝ ಞ Retroflex ಟ ಠ ಡ ಢ ಣ Dentals ತ ಥ ದ ಧ ನ Labials ಪ ಫ ಬ ಭ ಮ Avargeeya vyanjana (unstructured consonants) ಯ ರ ಱ (obsolete) ಲ ವ ಶ ಷ ಸ ಹ ಳ ೞ (obsolete) | 5 Repertoire Included-1 Sr. Unicode Glyph Character Name Unicode Indic Ref Widespread No. Code General Syllabic use ? Point Category Category [Yes/No] 1 0C82 ಂ KANNADA SIGN ANUSVARA Mc Anusvara Yes 2 0C83 ಂ KANNADA SIGN VISARGA Mc Visarga Yes 3 0C85 ಅ KANNADA LETTER A Lo Vowel Yes 4 0C86 ಆ KANNADA LETTER AA Lo Vowel Yes 5 0C87 ಇ KANNADA LETTER I Lo Vowel Yes 6 0C88 ಈ KANNADA LETTER II Lo Vowel Yes 7 0C89 ಉ KANNADA LETTER U Lo Vowel Yes 8 0C8A ಊ KANNADA LETTER UU Lo Vowel Yes KANNADA LETTER VOCALIC 9 0C8B ಋ R Lo Vowel Yes 10 0C8E ಎ KANNADA LETTER E Lo Vowel Yes | 6 Repertoire Included-2 Sr. -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

The Taittirtyaprtiakhya As on Antjsvara
THE TAITTIRTYAPRTIAKHYA AS 密 ON ANTJSVARA 教 文 Nobuhiko Kobayasi 化 A The dot at the left upper corner of an Indian letter1) represents a nasal element called anusvara (that which follows a vowel).2) The descriptions of anusvara as found in the works of ancient Indian phoneticians3) are so inconsistent and confusing that modern Sanskrit scholars are still confused. Some represented by the author of the Atharvavedapratiaakhya hold that it is a pure nasalized vowel,4) and others represented by the author of the RkpratiS'akhya say that it is either a vowel and a consonant.5) There is also another school, according to which it is a pure consonant.6) B An Indo-aryan syllable (aksara)7) is heavy (guru) or light (laghu). It is heavy, when the vowel is long8) or followed by a conjunction of con- sonants,9) and it is light when the vowel is short or not followed by a con- junction of consonants.10) An important feature of the phonetic element called anusvara is that it affects meter. According to the Taittiriyapratisakhya (TP), a letter with the anusvara sign represents a metrically long syllable." On the basis of this, description of the TP, Whitney adopts the view that anusvara is a lengthened nasal vowel.12) He seeks support for his interpretation from the fact that the anusvara sign is written over the vowel -112- of the first syllable.131 So the phonetic value of vamsa is interpreted as [Qa:sa]. This interpretation seems to be supported by such Hindi develop- THE TAITTIRIYAPRATISAKHYA ON ANUSVARA ment of anusvara as in vamsa>bas. -

15178-Devanagari-Spacing-Anusvara
Proposal to encode A8FE DEVANAGARI SIGN SPACING ANUSVARA Shriramana Sharma, jamadagni-at-gmail-dot-com, India 2015-Jun-06 This is a proposal to encode one character in the Devanagari Extended block for Samavedic: ◌० A8FE DEVANAGARI SIGN SPACING ANUSVARA This is in contrast to the regular anusvara for this script 0902 ◌ं DEVANAGARI SIGN ANUSVARA as also to the various Vedic anusvara-s seen in Samavedic. On the other hand, this is parallel to the spacing anusvara-s in other Indic scripts which are attested for Vedic (0982 Bengali, 0B02 Oriya, 0C02 Telugu, 0C82 Kannada, 0D02 Malayalam, 11302 Grantha) and glyphically identical to all of them except Bengali. However it should be positioned vertically centered with the Devanagari digits identical to 0966 ० DEVANAGARI DIGIT ZERO. §1. Discussion The regular Devanagari anusvara 0902 ◌ं is non-spacing. This poses a problem when composing texts of the Sama Veda since these use digits on the mainline to denote svara-s: (Below, we refer to the written representation of the linguistic pattern [C*]V as “syllable”.) 1) In the Ṛc-s (verses) a kampa or “aggravated” svarita svara is marked by a 2 above the syllable (or inferred as continued from a previous syllable), a KA or avagraha above the syllable, and a digit 3 following the syllable (see L2/09-372 pp 13 and 14 and L2/15-162 p 4). The digit 3 here denotes the anudātta svara in the latter part of the kampa. 2) In the Sāman-s (melodies), secondary svara-s in which a syllable’s vowel should be continued to be sung are marked by digits following the syllable. -

Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 3.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1 General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Gujarati LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-gujarati-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: gujarati-test-labels-06mar19-en.txt 2 Script for which the LGR is proposed ISO 15924 Code: Gujr ISO 15924 Key N°: 320 ISO 15924 English Name: Gujarati Latin transliteration of native script name: gujarâtî Native name of the script: ગજુ રાતી Maximal Starting Repertoire (MSR) version: MSR-4 1 Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel 3 Background on the Script and the Principal Languages Using it1 Gujarati (ગજુ રાતી) [also sometimes written as Gujerati, Gujarathi, Guzratee, Guujaratee, Gujrathi, and Gujerathi2] is an Indo-Aryan language native to the Indian state of Gujarat. It is part of the greater Indo-European language family. It is so named because Gujarati is the language of the Gujjars. Gujarati's origins can be traced back to Old Gujarati (circa 1100– 1500 AD). -
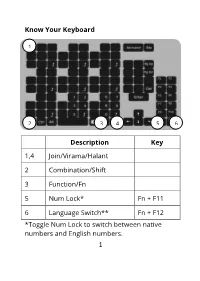
Know Your Keyboard Description Key 1,4 Join/Virama/Halant 2
Know Your Keyboard 1 2 3 4 5 6 Description Key 1,4 Join/Virama/Halant 2 Combination/Shift 3 Function/Fn 5 Num Lock* Fn + F11 6 Language Switch** Fn + F12 *Toggle Num Lock to switch between native numbers and English numbers. 1 ** Language Switch works on Windows, Linux and Android. For macOS, a configuration in settings is required. Note: If numbers are appearing in English, turn off Num Lock. Connecting Your Keyboard To Computer – Plug-in the cable to USB port on your computer. To Android Phone/Tablet 3 2 1 Use USB-to-OTG connector to plug-in keyboard. 2 Language and Layout You can use one keyboard to type multiple languages. You need to install at least one language to type. Language Layout Bengali Ka-Naada Bengali Keyboard Assamese Devanagari Sanskrit Hindi Ka-Naada Hindi Keyboard Marathi Neapli English Ka-Naada English Keyboard Guajarati Ka-Naada Guajarati Keyboard Kannada Ka-Naada Kannada Keyboard Malayalam Ka-Naada Malayalam Keyboard Tulu Odiya Ka-Naada Odiya Keyboard Panjabi Ka-Naada Gurmukhi Keyboard Telugu Ka-Naada Telugu Keyboard 3 Note: You need to switch to Ka-Naada input language before typing. Note: To switch between the languages you’re using, repeatedly press Language Switch key to cycle through all your installed languages. Language Pack Installation Go to https://ka-naada.com/downloads/ and click on the “Download” button in front of your operating system. Installation – Windows 1. Open your “Downloads” folder and locate “kanaada_keyboards.zip”. 2. Right click on zip file and choose “Extract Here” from the option menu. 3. -

Analysis of Comments for Telugu Script LGR Proposal for the Root Zone Revision: June 30, 2019
Neo-Brahmi Generation Panel: Analysis of comments for Telugu script LGR Proposal for the Root Zone Revision: June 30, 2019 Neo-Brahmi Generation Panel (NBGP) published the Telugu script LGR Propsoal for the Root Zone for public comment on 8 August 2018. This document is an additional document of the public comment report, collecting NBGP analyses as well as the concluded responses. There is 1 (one) comment submission. The analysis is as follow: No. 1 From Liang Hai Subject A Quick review of the Telugu proposal Comment 2, “telɯgɯ”: This is probably a phonetic transcription, not an accurate transliteration that should be used in this document. NBGP The NBGP acknowledges the comment. Analysis NBGP Updated the proposal in section 2 to use ‘Telugu’ Response Comment 3.5, “… and 16 dependent signs”: 15. NBGP There are 16 Matras: 14 Matras are in the repertoire, 2 Matras are Analysis excluded from the repertoire. NBGP No action required. Response Comment 3.5.1: Vocalic l should be categorized with vocalic rr and vocalic ll. Transliteration of vocalic ll is wrong. NBGP Agree. Analysis NBGP Update as suggested. Response 1 Comment 3.5.1, R1, “ca= a consonant with an inherent ‘a’”: When discussing text encoding, Indic consonants naturally are with an inherent vowel. Try to distinguish phonetic seQuence and written forms and encoded character sequence. The 3 lines under R1 are not helpful. NBGP The comment does not affect the normative part of the LGR. Analysis NBGP No action required. Response Comment 3.5.3: The introduction of arasunna usage is unclear. Is it commonly used today or not? NBGP The arsunna is not used frequently and it is not in the MSR. -

The Unicode Standard, Version 4.0--Online Edition
This PDF file is an excerpt from The Unicode Standard, Version 4.0, issued by the Unicode Consor- tium and published by Addison-Wesley. The material has been modified slightly for this online edi- tion, however the PDF files have not been modified to reflect the corrections found on the Updates and Errata page (http://www.unicode.org/errata/). For information on more recent versions of the standard, see http://www.unicode.org/standard/versions/enumeratedversions.html. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The Unicode® Consortium is a registered trademark, and Unicode™ is a trademark of Unicode, Inc. The Unicode logo is a trademark of Unicode, Inc., and may be registered in some jurisdictions. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

Table of Contents I
L2/21-130 TO: UTC FROM: Deborah Anderson, Ken Whistler, Roozbeh Pournader, and Liang Hai1 SUBJECT: Recommendations to UTC #168 July 2021 on Script Proposals DATE: July 26, 2021 The Script Ad Hoc group met on May 21, June 11, and July 16, 2021, in order to review proposals. The following represents feedback on proposals that were available when the group met. Table of Contents I. EUROPE ...................................................................................................................................................... 3 1 Cyrillic ..................................................................................................................................................... 3 1a. Cyrillic Phonetic Letters ................................................................................................................... 3 1b. Addendum to L2/21-107 Cyrillic modifier letters ........................................................................... 3 2 Old Hungarian ........................................................................................................................................ 4 3 Sidetic ..................................................................................................................................................... 4 II. AMERICAS ................................................................................................................................................. 5 4 Unified Canadian Aboriginal Syllabics ................................................................................................... -

The Evolution of the Printed Bengali Character
The Evolution of the Printed Bengali Character from 1778 to 1978 by Fiona Georgina Elisabeth Ross School of Oriental and African Studies University of London Thesis presented for the degree of Doctor of Philosophy 1988 ProQuest Number: 10731406 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. ProQuest 10731406 Published by ProQuest LLC (2017). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States Code Microform Edition © ProQuest LLC. ProQuest LLC. 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, MI 48106 - 1346 20618054 2 The Evolution of the Printed Bengali Character from 1778 to 1978 Abstract The thesis traces the evolution of the printed image of the Bengali script from its inception in movable metal type to its current status in digital photocomposition. It is concerned with identifying the factors that influenced the shaping of the Bengali character by examining the most significant Bengali type designs in their historical context, and by analyzing the composing techniques employed during the past two centuries for printing the script. Introduction: The thesis is divided into three parts according to the different methods of type manufacture and composition: 1. The Development of Movable Metal Types for the Bengali Script Particular emphasis is placed on the early founts which lay the foundations of Bengali typography. -

N4185 Preliminary Proposal to Encode Siddham in ISO/IEC 10646
ISO/IEC JTC1/SC2/WG2 N4185 L2/12-011R 2012-05-03 Preliminary Proposal to Encode Siddham in ISO/IEC 10646 Anshuman Pandey Department of History University of Michigan Ann Arbor, Michigan, U.S.A. [email protected] May 3, 2012 1 Introduction This is a preliminary proposal to encode the Siddham script in the Universal Character Set (ISO/IEC 10646). It is a collaborative effort between the Script Encoding Initiative (SEI) at the University of California, Berke- ley and the Shingon Buddhist International Institute, Fresno, California. Feedback is requested from experts and users of the script. Comments may be submitted to the author at the email address given above. Siddham is a Brahmi-based writing system that originated in India, but which is used primarily in East Asia. At present it is associated with esoteric Buddhist traditions in Japan. Nevertheless, Siddham is structurally an Indic script and its proposed encoding adheres to the UCS model for Brahmi-based writing systems, such as Devanagari and similar scripts. The technical description for Siddham given here may differ from the traditional analysis and philosophical interpretations of the script and its constituent characters and glyphs. An attempt has been made to encode all distinct characters attested in Siddham records, although more characters may be uncovered through additional research. The characters that are proposed for encoding have been analyzed in accordance with the character-glyph model of the UCS. As a result, the proposed encoding may contain characters that are not part of traditional character repertoires. It may also exclude characters that are traditionally regarded as independent letters, such as conjuncts, which are to be represented in the manner specified by the UCS encoding model.