Lzfse 10 Zlib Lzma Encode Speed 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
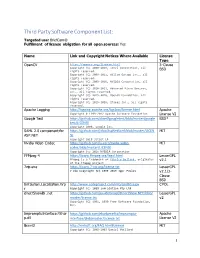
Third Party Software Component List: Targeted Use: Briefcam® Fulfillment of License Obligation for All Open Sources: Yes
Third Party Software Component List: Targeted use: BriefCam® Fulfillment of license obligation for all open sources: Yes Name Link and Copyright Notices Where Available License Type OpenCV https://opencv.org/license.html 3-Clause Copyright (C) 2000-2019, Intel Corporation, all BSD rights reserved. Copyright (C) 2009-2011, Willow Garage Inc., all rights reserved. Copyright (C) 2009-2016, NVIDIA Corporation, all rights reserved. Copyright (C) 2010-2013, Advanced Micro Devices, Inc., all rights reserved. Copyright (C) 2015-2016, OpenCV Foundation, all rights reserved. Copyright (C) 2015-2016, Itseez Inc., all rights reserved. Apache Logging http://logging.apache.org/log4cxx/license.html Apache Copyright © 1999-2012 Apache Software Foundation License V2 Google Test https://github.com/abseil/googletest/blob/master/google BSD* test/LICENSE Copyright 2008, Google Inc. SAML 2.0 component for https://github.com/jitbit/AspNetSaml/blob/master/LICEN MIT ASP.NET SE Copyright 2018 Jitbit LP Nvidia Video Codec https://github.com/lu-zero/nvidia-video- MIT codec/blob/master/LICENSE Copyright (c) 2016 NVIDIA Corporation FFMpeg 4 https://www.ffmpeg.org/legal.html LesserGPL FFmpeg is a trademark of Fabrice Bellard, originator v2.1 of the FFmpeg project 7zip.exe https://www.7-zip.org/license.txt LesserGPL 7-Zip Copyright (C) 1999-2019 Igor Pavlov v2.1/3- Clause BSD Infralution.Localization.Wp http://www.codeproject.com/info/cpol10.aspx CPOL f Copyright (C) 2018 Infralution Pty Ltd directShowlib .net https://github.com/pauldotknopf/DirectShow.NET/blob/ LesserGPL -

The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on Iot Nodes in Smart Cities
sensors Article The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on IoT Nodes in Smart Cities Ammar Nasif *, Zulaiha Ali Othman and Nor Samsiah Sani Center for Artificial Intelligence Technology (CAIT), Faculty of Information Science & Technology, University Kebangsaan Malaysia, Bangi 43600, Malaysia; [email protected] (Z.A.O.); [email protected] (N.S.S.) * Correspondence: [email protected] Abstract: Networking is crucial for smart city projects nowadays, as it offers an environment where people and things are connected. This paper presents a chronology of factors on the development of smart cities, including IoT technologies as network infrastructure. Increasing IoT nodes leads to increasing data flow, which is a potential source of failure for IoT networks. The biggest challenge of IoT networks is that the IoT may have insufficient memory to handle all transaction data within the IoT network. We aim in this paper to propose a potential compression method for reducing IoT network data traffic. Therefore, we investigate various lossless compression algorithms, such as entropy or dictionary-based algorithms, and general compression methods to determine which algorithm or method adheres to the IoT specifications. Furthermore, this study conducts compression experiments using entropy (Huffman, Adaptive Huffman) and Dictionary (LZ77, LZ78) as well as five different types of datasets of the IoT data traffic. Though the above algorithms can alleviate the IoT data traffic, adaptive Huffman gave the best compression algorithm. Therefore, in this paper, Citation: Nasif, A.; Othman, Z.A.; we aim to propose a conceptual compression method for IoT data traffic by improving an adaptive Sani, N.S. -

Forcepoint DLP Supported File Formats and Size Limits
Forcepoint DLP Supported File Formats and Size Limits Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 This article provides a list of the file formats that can be analyzed by Forcepoint DLP, file formats from which content and meta data can be extracted, and the file size limits for network, endpoint, and discovery functions. See: ● Supported File Formats ● File Size Limits © 2021 Forcepoint LLC Supported File Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 The following tables lists the file formats supported by Forcepoint DLP. File formats are in alphabetical order by format group. ● Archive For mats, page 3 ● Backup Formats, page 7 ● Business Intelligence (BI) and Analysis Formats, page 8 ● Computer-Aided Design Formats, page 9 ● Cryptography Formats, page 12 ● Database Formats, page 14 ● Desktop publishing formats, page 16 ● eBook/Audio book formats, page 17 ● Executable formats, page 18 ● Font formats, page 20 ● Graphics formats - general, page 21 ● Graphics formats - vector graphics, page 26 ● Library formats, page 29 ● Log formats, page 30 ● Mail formats, page 31 ● Multimedia formats, page 32 ● Object formats, page 37 ● Presentation formats, page 38 ● Project management formats, page 40 ● Spreadsheet formats, page 41 ● Text and markup formats, page 43 ● Word processing formats, page 45 ● Miscellaneous formats, page 53 Supported file formats are added and updated frequently. Key to support tables Symbol Description Y The format is supported N The format is not supported P Partial metadata -

In-Core Compression: How to Shrink Your Database Size in Several Times
In-core compression: how to shrink your database size in several times Aleksander Alekseev Anastasia Lubennikova www.postgrespro.ru Agenda ● What does Postgres store? • A couple of words about storage internals ● Check list for your schema • A set of tricks to optimize database size ● In-core block level compression • Out-of-box feature of Postgres Pro EE ● ZSON • Extension for transparent JSONB compression What this talk doesn’t cover ● MVCC bloat • Tune autovacuum properly • Drop unused indexes • Use pg_repack • Try pg_squeeze ● Catalog bloat • Create less temporary tables ● WAL-log size • Enable wal_compression ● FS level compression • ZFS, btrfs, etc Data layout Empty tables are not that empty ● Imagine we have no data create table tbl(); insert into tbl select from generate_series(0,1e07); select pg_size_pretty(pg_relation_size('tbl')); pg_size_pretty --------------- ??? Empty tables are not that empty ● Imagine we have no data create table tbl(); insert into tbl select from generate_series(0,1e07); select pg_size_pretty(pg_relation_size('tbl')); pg_size_pretty --------------- 268 MB Meta information db=# select * from heap_page_items(get_raw_page('tbl',0)); -[ RECORD 1 ]------------------- lp | 1 lp_off | 8160 lp_flags | 1 lp_len | 32 t_xmin | 720 t_xmax | 0 t_field3 | 0 t_ctid | (0,1) t_infomask2 | 2 t_infomask | 2048 t_hoff | 24 t_bits | t_oid | t_data | Order matters ● Attributes must be aligned inside the row create table bad (i1 int, b1 bigint, i1 int); create table good (i1 int, i1 int, b1 bigint); Safe up to 20% of space. -

I Came to Drop Bombs Auditing the Compression Algorithm Weapons Cache
I Came to Drop Bombs Auditing the Compression Algorithm Weapons Cache Cara Marie NCC Group Blackhat USA 2016 About Me • NCC Group Senior Security Consultant Pentested numerous networks, web applications, mobile applications, etc. • Hackbright Graduate • Ticket scalper in a previous life • @bones_codes | [email protected] What is a Decompression Bomb? A decompression bomb is a file designed to crash or render useless the program or system reading it. Vulnerable Vectors • Chat clients • Image hosting • Web browsers • Web servers • Everyday web-services software • Everyday client software • Embedded devices (especially vulnerable due to weak hardware) • Embedded documents • Gzip’d log uploads A History Lesson early 90’s • ARC/LZH/ZIP/RAR bombs were used to DoS FidoNet systems 2002 • Paul L. Daniels publishes Arbomb (Archive “Bomb” detection utility) 2003 • Posting by Steve Wray on FullDisclosure about a bzip2 bomb antivirus software DoS 2004 • AERAsec Network Services and Security publishes research on the various reactions of antivirus software against decompression bombs, includes a comparison chart 2014 • Several CVEs for PIL are issued — first release July 2010 (CVE-2014-3589, CVE-2014-3598, CVE-2014-9601) 2015 • CVE for libpng — first release Aug 2004 (CVE-2015-8126) Why Are We Still Talking About This?!? Why Are We Still Talking About This?!? Compression is the New Hotness Who This Is For Who This Is For The Archives An archive bomb, a.k.a. zip bomb, is often employed to disable antivirus software, in order to create an opening for more traditional viruses • Singly compressed large file • Self-reproducing compressed files, i.e. Russ Cox’s Zips All The Way Down • Nested compressed files, i.e. -

State of the Art and Future Trends in Data Reduction for High-Performance Computing
DOI: 10.14529/jsfi200101 State of the Art and Future Trends in Data Reduction for High-Performance Computing Kira Duwe1, Jakob L¨uttgau1, Georgiana Mania2, Jannek Squar1, Anna Fuchs1, Michael Kuhn1, Eugen Betke3, Thomas Ludwig3 c The Authors 2020. This paper is published with open access at SuperFri.org Research into data reduction techniques has gained popularity in recent years as storage ca- pacity and performance become a growing concern. This survey paper provides an overview of leveraging points found in high-performance computing (HPC) systems and suitable mechanisms to reduce data volumes. We present the underlying theories and their application throughout the HPC stack and also discuss related hardware acceleration and reduction approaches. After intro- ducing relevant use-cases, an overview of modern lossless and lossy compression algorithms and their respective usage at the application and file system layer is given. In anticipation of their increasing relevance for adaptive and in situ approaches, dimensionality reduction techniques are summarized with a focus on non-linear feature extraction. Adaptive approaches and in situ com- pression algorithms and frameworks follow. The key stages and new opportunities to deduplication are covered next. An unconventional but promising method is recomputation, which is proposed at last. We conclude the survey with an outlook on future developments. Keywords: data reduction, lossless compression, lossy compression, dimensionality reduction, adaptive approaches, deduplication, in situ, recomputation, scientific data set. Introduction Breakthroughs in science are increasingly enabled by supercomputers and large scale data collection operations. Applications span the spectrum of scientific domains from fluid-dynamics in climate simulations and engineering, to particle simulations in astrophysics, quantum mechan- ics and molecular dynamics, to high-throughput computing in biology for genome sequencing and protein-folding. -
Coding with Asymmetric Numeral Systems (Long Version)
Coding with Asymmetric Numeral Systems (long version) Jeremy Gibbons University of Oxford Abstract. Asymmetric Numeral Systems (ANS) are an entropy-based encoding method introduced by Jarek Duda, combining the Shannon- optimal compression effectiveness of arithmetic coding with the execu- tion efficiency of Huffman coding. Existing presentations of the ANS encoding and decoding algorithms are somewhat obscured by the lack of suitable presentation techniques; we present here an equational deriva- tion, calculational where it can be, and highlighting the creative leaps where it cannot. 1 Introduction Entropy encoding techniques compress symbols according to a model of their expected frequencies, with common symbols being represented by fewer bits than rare ones. The best known entropy encoding technique is Huffman coding (HC) [20], taught in every undergraduate course on algorithms and data structures: a classic greedy algorithm uses the symbol frequencies to construct a trie, from which an optimal prefix-free binary code can be read off. For example, suppose an alphabet of n = 3 symbols s0 = 'a'; s1 = 'b'; s2 = 'c' with respective expected 2 relative frequencies c0 = 2; c1 = 3; c2 = 5 (that is, 'a' is expected =2+3+5 = 20% of the time, and so on); then HC might construct the trie and prefix-free code shown in Figure 1. A text is then encoded as the concatenation of its symbol codes; thus, the text "cbcacbcacb" encodes to 1 01 1 00 1 01 1 00 1 01. This is optimal, in the sense that no prefix-free binary code yields a shorter encoding of any text that matches the expected symbol frequencies. -
Compression Method LZFSE Student: Martin Hron Supervisor: Ing
ASSIGNMENT OF BACHELOR’S THESIS Title: Compression method LZFSE Student: Martin Hron Supervisor: Ing. Jan Baier Study Programme: Informatics Study Branch: Computer Science Department: Department of Theoretical Computer Science Validity: Until the end of summer semester 2018/19 Instructions Introduce yourself with LZ family compression methods. Analyze compression method LZFSE [1] and explain its main enhancements. Implement this method and/or these enhancements into the ExCom library [2], perform evaluation tests using the standard test suite and compare performance with other implemented LZ methods. References [1] https://github.com/lzfse/lzfse [2] http://www.stringology.org/projects/ExCom/ doc. Ing. Jan Janoušek, Ph.D. doc. RNDr. Ing. Marcel Jiřina, Ph.D. Head of Department Dean Prague January 17, 2018 Bachelor’s thesis Compression method LZFSE Martin Hron Department of Theoretical Computer Science Supervisor: Ing. Jan Baier May 12, 2018 Acknowledgements I would like to thank my supervisor, Ing. Jan Baier, for guiding this thesis and for all his valuable advice. Declaration I hereby declare that the presented thesis is my own work and that I have cited all sources of information in accordance with the Guideline for adhering to ethical principles when elaborating an academic final thesis. I acknowledge that my thesis is subject to the rights and obligations stip- ulated by the Act No. 121/2000 Coll., the Copyright Act, as amended. In accordance with Article 46(6) of the Act, I hereby grant a nonexclusive au- thorization (license) to utilize this thesis, including any and all computer pro- grams incorporated therein or attached thereto and all corresponding docu- mentation (hereinafter collectively referred to as the “Work”), to any and all persons that wish to utilize the Work. -
A Novel Encoding Algorithm for Textual Data Compression
bioRxiv preprint doi: https://doi.org/10.1101/2020.08.24.264366; this version posted August 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. A Novel Encoding Algorithm for Textual Data Compression Anas Al-okaily1,* and Abdelghani Tbakhi1 1Department of Cell Therapy and Applied Genomics, King Hussein Cancer Center, Amman, 11941, Jordan *[email protected] ABSTRACT Data compression is a fundamental problem in the fields of computer science, information theory, and coding theory. The need for compressing data is to reduce the size of the data so that the storage and the transmission of them become more efficient. Motivated from resolving the compression of DNA data, we introduce a novel encoding algorithm that works for any textual data including DNA data. Moreover, the design of this algorithm paves a novel approach so that researchers can build up on and resolve better the compression problem of DNA or textual data. Introduction The aim of compression process is to reduce the size of data as much as possible to save space and speed up transmission of data. There are two forms of compression processes: lossless and lossy. Lossless algorithms guarantee exact restoration of the original data, while lossy do not (due, for instance, to exclude unnecessary data such as data in video and audio where their loss will not be detected by users). The focus in this paper is the lossless compression. Data can be in different formats such as text, numeric, images, audios, and videos. -

Asymmetric Numeral Systems
Old and new coding techniques for data compression, error correction and nonstandard situations Lecture I: data compression … data encoding Efficient information encoding to: - reduce storage requirements, - reduce transmission requirements, - often reduce access time for storage and transmission (decompression is usually faster than HDD, e.g. 500 vs 100MB/s) Jarosław Duda Nokia, Kraków 25. IV. 2016 1 Symbol frequencies from a version of the British National Corpus containing 67 million words ( http://www.yorku.ca/mack/uist2011.html#f1 ): Brute: 풍품(ퟐퟕ) ≈ ퟒ. ퟕퟓ bits/symbol (푥 → 27푥 + 푠) ′ Huffman uses: 퐻 = ∑푖 푝푖 풓풊 ≈ ퟒ. ퟏퟐ bits/symbol Shannon: 퐻 = ∑푖 푝푖퐥퐠(ퟏ/풑풊) ≈ ퟒ. ퟎퟖ bits/symbol We can theoretically improve by ≈ ퟏ% here 횫푯 ≈ ퟎ. ퟎퟒ bits/symbol Order 1 Markov: ~ 3.3 bits/symbol (~gzip) Order 2: ~3.1 bps, word: ~2.1 bps (~ZSTD) Currently best compression: cmix-v9 (PAQ) (http://mattmahoney.net/dc/text.html ) 109 bytes of text from Wikipedia (enwik9) into 123874398 bytes: ≈ ퟏ bit/symbol 108 → ퟏퟓퟔ27636 106 → ퟏퟖퟏ476 Hilberg conjecture: 퐻(푛) ~ 푛훽, 훽 < 0.9 … lossy video compression: > 100× reduction 2 Lossless compression – fully reversible, e.g. gzip, gif, png, JPEG-LS, FLAC, lossless mode in h.264, h.265 (~50%) Lossy – better compression at cost of distortion Stronger distortion – better compression (rate distortion theory, psychoacoustics) General purpose (lossless, e.g. gzip, rar, lzma, bzip, zpaq, Brotli, ZSTD) vs specialized compressors (e.g. audiovisual, text, DNA, numerical, mesh,…) For example audio (http://www.bobulous.org.uk/misc/audioFormats.html -

Iraspa: GPU-Accelerated Visualization Software for Materials Scientists
Delft University of Technology iRASPA GPU-accelerated visualization software for materials scientists Dubbeldam, David; Calero, S.; Vlugt, Thijs J.H. DOI 10.1080/08927022.2018.1426855 Publication date 2018 Document Version Final published version Published in Molecular Simulation Citation (APA) Dubbeldam, D., Calero, S., & Vlugt, T. J. H. (2018). iRASPA: GPU-accelerated visualization software for materials scientists. Molecular Simulation, 44(8), 653-676. https://doi.org/10.1080/08927022.2018.1426855 Important note To cite this publication, please use the final published version (if applicable). Please check the document version above. Copyright Other than for strictly personal use, it is not permitted to download, forward or distribute the text or part of it, without the consent of the author(s) and/or copyright holder(s), unless the work is under an open content license such as Creative Commons. Takedown policy Please contact us and provide details if you believe this document breaches copyrights. We will remove access to the work immediately and investigate your claim. This work is downloaded from Delft University of Technology. For technical reasons the number of authors shown on this cover page is limited to a maximum of 10. Molecular Simulation ISSN: 0892-7022 (Print) 1029-0435 (Online) Journal homepage: http://www.tandfonline.com/loi/gmos20 iRASPA: GPU-accelerated visualization software for materials scientists David Dubbeldam, Sofía Calero & Thijs J.H. Vlugt To cite this article: David Dubbeldam, Sofía Calero & Thijs J.H. Vlugt (2018): iRASPA: GPU-accelerated visualization software for materials scientists, Molecular Simulation, DOI: 10.1080/08927022.2018.1426855 To link to this article: https://doi.org/10.1080/08927022.2018.1426855 © 2018 The Author(s). -
Encoding of Probability Distributions for Asymmetric Numeral Systems Jarek Duda Jagiellonian University, Golebia 24, 31-007 Krakow, Poland, Email: [email protected]
1 Encoding of probability distributions for Asymmetric Numeral Systems Jarek Duda Jagiellonian University, Golebia 24, 31-007 Krakow, Poland, Email: [email protected] Abstract—Many data compressors regularly encode probability distributions for entropy coding - requiring minimal description length type of optimizations. Canonical prefix/Huffman coding usually just writes lengths of bit sequences, this way approximat- ing probabilities with powers-of-2. Operating on more accurate probabilities usually allows for better compression ratios, and is possible e.g. using arithmetic coding and Asymmetric Numeral Systems family. Especially the multiplication-free tabled variant of the latter (tANS) builds automaton often replacing Huffman cod- ing due to better compression at similar computational cost - e.g. in popular Facebook Zstandard and Apple LZFSE compressors. There is discussed encoding of probability distributions for such applications, especially using Pyramid Vector Quantizer(PVQ)- based approach with deformation, also tuned symbol spread for tANS. Keywords: data compression, entropy coding, ANS, quan- tization, PVQ, minimal description length I. INTRODUCTION Entropy/source coding is at heart of many of data com- pressors, transforming sequences of symbols from estimated statistical models, into finally stored or transmitted sequence of bits. Many especially general purpose compressors, like widely used Facebook Zstandard1 and Apple LZFSE2, regularly store probability distribution for the next frame e.g. for byte-wise D = 256 size alphabet for e.g. L = 2048 state tANS automaton: tabled Asymmetric Numeral Systems ([1], [2], [3]). This article focuses on optimization of encoding of such probability distribution for this kind of situations, Fig. 1 summarizes its results. For historical Huffman coding there are usually used canonical prefix codes [4] for this purpose - just store lengths of bit sequences.