State of the Art and Future Trends in Data Reduction for High-Performance Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Data Compression: Dictionary-Based Coding 2 / 37 Dictionary-Based Coding Dictionary-Based Coding
Dictionary-based Coding already coded not yet coded search buffer look-ahead buffer cursor (N symbols) (L symbols) We know the past but cannot control it. We control the future but... Last Lecture Last Lecture: Predictive Lossless Coding Predictive Lossless Coding Simple and effective way to exploit dependencies between neighboring symbols / samples Optimal predictor: Conditional mean (requires storage of large tables) Affine and Linear Prediction Simple structure, low-complex implementation possible Optimal prediction parameters are given by solution of Yule-Walker equations Works very well for real signals (e.g., audio, images, ...) Efficient Lossless Coding for Real-World Signals Affine/linear prediction (often: block-adaptive choice of prediction parameters) Entropy coding of prediction errors (e.g., arithmetic coding) Using marginal pmf often already yields good results Can be improved by using conditional pmfs (with simple conditions) Heiko Schwarz (Freie Universität Berlin) — Data Compression: Dictionary-based Coding 2 / 37 Dictionary-based Coding Dictionary-Based Coding Coding of Text Files Very high amount of dependencies Affine prediction does not work (requires linear dependencies) Higher-order conditional coding should work well, but is way to complex (memory) Alternative: Do not code single characters, but words or phrases Example: English Texts Oxford English Dictionary lists less than 230 000 words (including obsolete words) On average, a word contains about 6 characters Average codeword length per character would be limited by 1 -
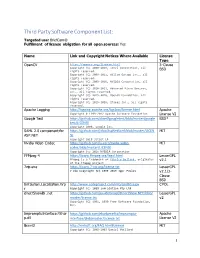
Third Party Software Component List: Targeted Use: Briefcam® Fulfillment of License Obligation for All Open Sources: Yes
Third Party Software Component List: Targeted use: BriefCam® Fulfillment of license obligation for all open sources: Yes Name Link and Copyright Notices Where Available License Type OpenCV https://opencv.org/license.html 3-Clause Copyright (C) 2000-2019, Intel Corporation, all BSD rights reserved. Copyright (C) 2009-2011, Willow Garage Inc., all rights reserved. Copyright (C) 2009-2016, NVIDIA Corporation, all rights reserved. Copyright (C) 2010-2013, Advanced Micro Devices, Inc., all rights reserved. Copyright (C) 2015-2016, OpenCV Foundation, all rights reserved. Copyright (C) 2015-2016, Itseez Inc., all rights reserved. Apache Logging http://logging.apache.org/log4cxx/license.html Apache Copyright © 1999-2012 Apache Software Foundation License V2 Google Test https://github.com/abseil/googletest/blob/master/google BSD* test/LICENSE Copyright 2008, Google Inc. SAML 2.0 component for https://github.com/jitbit/AspNetSaml/blob/master/LICEN MIT ASP.NET SE Copyright 2018 Jitbit LP Nvidia Video Codec https://github.com/lu-zero/nvidia-video- MIT codec/blob/master/LICENSE Copyright (c) 2016 NVIDIA Corporation FFMpeg 4 https://www.ffmpeg.org/legal.html LesserGPL FFmpeg is a trademark of Fabrice Bellard, originator v2.1 of the FFmpeg project 7zip.exe https://www.7-zip.org/license.txt LesserGPL 7-Zip Copyright (C) 1999-2019 Igor Pavlov v2.1/3- Clause BSD Infralution.Localization.Wp http://www.codeproject.com/info/cpol10.aspx CPOL f Copyright (C) 2018 Infralution Pty Ltd directShowlib .net https://github.com/pauldotknopf/DirectShow.NET/blob/ LesserGPL -

ROOT I/O Compression Improvements for HEP Analysis
EPJ Web of Conferences 245, 02017 (2020) https://doi.org/10.1051/epjconf/202024502017 CHEP 2019 ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, enhancing it by improving its performance and interaction with other data analysis ecosys- tems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased over the last couple of years. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly, because there are significant trade-offs between the increased CPU cost for reading and writing files and the reduces storage space. 1 Introduction In the past years, Large Hadron Collider (LHC) experiments are managing about an exabyte of storage for analysis purposes, approximately half of which is stored on tape storages for archival purposes, and half is used for traditional disk storage. Meanwhile for High Lumi- nosity Large Hadron Collider (HL-LHC) storage requirements per year are expected to be increased by a factor of 10 [1]. -

Melinda's Marks Merit Main Mantle SYDNEY STRIDERS
SYDNEY STRIDERS ROAD RUNNERS’ CLUB AUSTRALIA EDITION No 108 MAY - AUGUST 2009 Melinda’s marks merit main mantle This is proving a “best-so- she attained through far” year for Melinda. To swimming conflicted with date she has the fastest her transition to running. time in Australia over 3000m. With a smart 2nd Like all top runners she at the State Open 5000m does well over 100k a champs, followed by a week in training, win at the State Open 10k consisting of a variety of Road Champs, another sessions: steady pace, win at the Herald Half medium pace, long slow which doubles as the runs, track work, fartlek, State Half Champs and a hills, gym work and win at the State Cross swimming! country Champs, our Melinda is looking like Springs under her shoes give hot property. Melinda extra lift Melinda began her sports Continued Page 3 career as a swimmer. By 9 years of age she was representing her club at State level. She held numerous records for INSIDE BLISTER 108 Breaststroke and Lisa facing racing pacing Butterfly. Her switch to running came after the McKinney makes most of death of her favourite marvellous mud moment Coach and because she Weather woe means Mo wasn’t growing as big as can’t crow though not slow! her fellow competitors. She managed some pretty fast times at inter-schools Brent takes tumble at Trevi champs and Cross Country before making an impression in the Open category where she has Champion Charles cheered steadily improved. by chance & chase challenge N’Lotsa Uthastuff Melinda credits her swimming background for endurance -
![Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020](https://docslib.b-cdn.net/cover/5419/arxiv-2004-10531v1-cs-oh-8-apr-2020-215419.webp)
Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020
ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, increasing per- formance and enhancing it and improving its interaction with other data analy- sis ecosystems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly to improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased during the LHC era. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly: there are sig- nificant trade-offs between the increased CPU cost for reading and writing files and the reduce storage space. 1 Introduction In the past years LHC experiments are commissioned and now manages about an exabyte of storage for analysis purposes, approximately half of which is used for archival purposes, and half is used for traditional disk storage. Meanwhile for HL-LHC storage requirements per year are expected to be increased by factor 10 [1]. arXiv:2004.10531v1 [cs.OH] 8 Apr 2020 Looking at these predictions, we would like to state that storage will remain one of the major cost drivers and at the same time the bottlenecks for HEP computing. -

Compressed Transitive Delta Encoding 1. Introduction
Compressed Transitive Delta Encoding Dana Shapira Department of Computer Science Ashkelon Academic College Ashkelon 78211, Israel [email protected] Abstract Given a source file S and two differencing files ∆(S; T ) and ∆(T;R), where ∆(X; Y ) is used to denote the delta file of the target file Y with respect to the source file X, the objective is to be able to construct R. This is intended for the scenario of upgrading soft- ware where intermediate releases are missing, or for the case of file system backups, where non consecutive versions must be recovered. The traditional way is to decompress ∆(S; T ) in order to construct T and then apply ∆(T;R) on T and obtain R. The Compressed Transitive Delta Encoding (CTDE) paradigm, introduced in this paper, is to construct a delta file ∆(S; R) working directly on the two given delta files, ∆(S; T ) and ∆(T;R), without any decompression or the use of the base file S. A new algorithm for solving CTDE is proposed and its compression performance is compared against the traditional \double delta decompression". Not only does it use constant additional space, as opposed to the traditional method which uses linear additional memory storage, but experiments show that the size of the delta files involved is reduced by 15% on average. 1. Introduction Differential file compression represents a target file T with respect to a source file S. That is, both the encoder and decoder have available identical copies of S. A new file T is encoded and subsequently decoded by making use of S. -

A New Way of Accelerating Web by Compressing Data with Back Reference-Prefer Geflochtener
442 The International Arab Journal of Information Technology, Vol. 14, No. 4, July 2017 A New Way of Accelerating Web by Compressing Data with Back Reference-Prefer Geflochtener Kushwaha Singh1, Challa Krishna2, and Saini Kumar1 1Department of Computer Science and Engineering, Rajasthan Technical University, India 2Department of Computer Science and Engineering, Panjab University, India Abstract: This research focused on the synthesis of an iterative approach to improve speed of the web and also learning the new methodology to compress the large data with enhanced backward reference preference. In addition, observations on the outcomes obtained from experimentation, group-benchmarks compressions, and time splays for transmissions, the proposed system have been analysed. This resulted in improving the compression of textual data in the Web pages and with this it also gains an interest in hardening the cryptanalysis of the data by maximum reducing the redundancies. This removes unnecessary redundancies with 70% efficiency and compress pages with the 23.75-35% compression ratio. Keywords: Backward references, shortest path technique, HTTP, iterative compression, web, LZSS and LZ77. Received April 25, 2014; accepted August 13, 2014 1. Introduction Algorithm 1: LZ77 Compression Compression is the reduction in data size of if a sufficient length is matched or it may correlate better with next input. information to save space and bandwidth. This can be While (! empty lookaheadBuffer) done on Web data or the entire page including the { header. Data compression is a technique of removing get a remission (position, length) to longer match from search white spaces, inserting a single repeater for the repeated buffer; bytes and replace smaller bits for frequent characters if (length>0) Data Compression (DC) is not only the cost effective { Output (position, length, nextsymbol); technique due to its small size for data storage but it transpose the window length+1 position along; also increases the data transfer rate in data } communication [2]. -

The Basic Principles of Data Compression
The Basic Principles of Data Compression Author: Conrad Chung, 2BrightSparks Introduction Internet users who download or upload files from/to the web, or use email to send or receive attachments will most likely have encountered files in compressed format. In this topic we will cover how compression works, the advantages and disadvantages of compression, as well as types of compression. What is Compression? Compression is the process of encoding data more efficiently to achieve a reduction in file size. One type of compression available is referred to as lossless compression. This means the compressed file will be restored exactly to its original state with no loss of data during the decompression process. This is essential to data compression as the file would be corrupted and unusable should data be lost. Another compression category which will not be covered in this article is “lossy” compression often used in multimedia files for music and images and where data is discarded. Lossless compression algorithms use statistic modeling techniques to reduce repetitive information in a file. Some of the methods may include removal of spacing characters, representing a string of repeated characters with a single character or replacing recurring characters with smaller bit sequences. Advantages/Disadvantages of Compression Compression of files offer many advantages. When compressed, the quantity of bits used to store the information is reduced. Files that are smaller in size will result in shorter transmission times when they are transferred on the Internet. Compressed files also take up less storage space. File compression can zip up several small files into a single file for more convenient email transmission. -

Encryption Introduction to Using 7-Zip
IT Services Training Guide Encryption Introduction to using 7-Zip It Services Training Team The University of Manchester email: [email protected] www.itservices.manchester.ac.uk/trainingcourses/coursesforstaff Version: 5.3 Training Guide Introduction to Using 7-Zip Page 2 IT Services Training Introduction to Using 7-Zip Table of Contents Contents Introduction ......................................................................................................................... 4 Compress/encrypt individual files ....................................................................................... 5 Email compressed/encrypted files ....................................................................................... 8 Decrypt an encrypted file ..................................................................................................... 9 Create a self-extracting encrypted file .............................................................................. 10 Decrypt/un-zip a file .......................................................................................................... 14 APPENDIX A Downloading and installing 7-Zip ................................................................. 15 Help and Further Reference ............................................................................................... 18 Page 3 Training Guide Introduction to Using 7-Zip Introduction 7-Zip is an application that allows you to: Compress a file – for example a file that is 5MB can be compressed to 3MB Secure the -

Implementing Compression on Distributed Time Series Database
Implementing compression on distributed time series database Michael Burman School of Science Thesis submitted for examination for the degree of Master of Science in Technology. Espoo 05.11.2017 Supervisor Prof. Kari Smolander Advisor Mgr. Jiri Kremser Aalto University, P.O. BOX 11000, 00076 AALTO www.aalto.fi Abstract of the master’s thesis Author Michael Burman Title Implementing compression on distributed time series database Degree programme Major Computer Science Code of major SCI3042 Supervisor Prof. Kari Smolander Advisor Mgr. Jiri Kremser Date 05.11.2017 Number of pages 70+4 Language English Abstract Rise of microservices and distributed applications in containerized deployments are putting increasing amount of burden to the monitoring systems. They push the storage requirements to provide suitable performance for large queries. In this paper we present the changes we made to our distributed time series database, Hawkular-Metrics, and how it stores data more effectively in the Cassandra. We show that using our methods provides significant space savings ranging from 50 to 95% reduction in storage usage, while reducing the query times by over 90% compared to the nominal approach when using Cassandra. We also provide our unique algorithm modified from Gorilla compression algorithm that we use in our solution, which provides almost three times the throughput in compression with equal compression ratio. Keywords timeseries compression performance storage Aalto-yliopisto, PL 11000, 00076 AALTO www.aalto.fi Diplomityön tiivistelmä Tekijä Michael Burman Työn nimi Pakkausmenetelmät hajautetussa aikasarjatietokannassa Koulutusohjelma Pääaine Computer Science Pääaineen koodi SCI3042 Työn valvoja ja ohjaaja Prof. Kari Smolander Päivämäärä 05.11.2017 Sivumäärä 70+4 Kieli Englanti Tiivistelmä Hajautettujen järjestelmien yleistyminen on aiheuttanut valvontajärjestelmissä tiedon määrän kasvua, sillä aikasarjojen määrä on kasvanut ja niihin talletetaan useammin tietoa. -

In-Place Reconstruction of Delta Compressed Files
In-Place Reconstruction of Delta Compressed Files Randal C. Burns Darrell D. E. Long’ IBM Almaden ResearchCenter Departmentof Computer Science 650 Harry Rd., San Jose,CA 95 120 University of California, SantaCruz, CA 95064 [email protected] [email protected] Abstract results in high latency and low bandwidth to web-enabled clients and prevents the timely delivery of software. We present an algorithm for modifying delta compressed Differential or delta compression [5, 11, compactly en- files so that the compressedversions may be reconstructed coding a new version of a file using only the changedbytes without scratchspace. This allows network clients with lim- from a previous version, can be usedto reducethe size of the ited resources to efficiently update software by retrieving file to be transmitted and consequently the time to perform delta compressedversions over a network. software update. Currently, decompressingdelta encoded Delta compressionfor binary files, compactly encoding a files requires scratch space,additional disk or memory stor- version of data with only the changedbytes from a previous age, used to hold a required second copy of the file. Two version, may be used to efficiently distribute software over copiesof the compressedfile must be concurrently available, low bandwidth channels, such as the Internet. Traditional as the delta file contains directives to read data from the old methods for rebuilding these delta files require memory or file version while the new file version is being materialized storagespace on the target machinefor both the old and new in another region of storage. This presentsa problem. Net- version of the file to be reconstructed. -

CALIFORNIA STATE UNIVERSITY, NORTHRIDGE Optimized AV1 Inter
CALIFORNIA STATE UNIVERSITY, NORTHRIDGE Optimized AV1 Inter Prediction using Binary classification techniques A graduate project submitted in partial fulfillment of the requirements for the degree of Master of Science in Software Engineering by Alex Kit Romero May 2020 The graduate project of Alex Kit Romero is approved: ____________________________________ ____________ Dr. Katya Mkrtchyan Date ____________________________________ ____________ Dr. Kyle Dewey Date ____________________________________ ____________ Dr. John J. Noga, Chair Date California State University, Northridge ii Dedication This project is dedicated to all of the Computer Science professors that I have come in contact with other the years who have inspired and encouraged me to pursue a career in computer science. The words and wisdom of these professors are what pushed me to try harder and accomplish more than I ever thought possible. I would like to give a big thanks to the open source community and my fellow cohort of computer science co-workers for always being there with answers to my numerous questions and inquiries. Without their guidance and expertise, I could not have been successful. Lastly, I would like to thank my friends and family who have supported and uplifted me throughout the years. Thank you for believing in me and always telling me to never give up. iii Table of Contents Signature Page ................................................................................................................................ ii Dedication .....................................................................................................................................