High-Throughput Lossy-To-Lossless 3D Image Compression
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
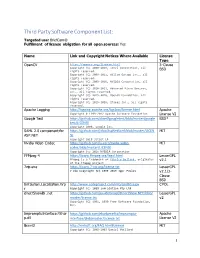
Third Party Software Component List: Targeted Use: Briefcam® Fulfillment of License Obligation for All Open Sources: Yes
Third Party Software Component List: Targeted use: BriefCam® Fulfillment of license obligation for all open sources: Yes Name Link and Copyright Notices Where Available License Type OpenCV https://opencv.org/license.html 3-Clause Copyright (C) 2000-2019, Intel Corporation, all BSD rights reserved. Copyright (C) 2009-2011, Willow Garage Inc., all rights reserved. Copyright (C) 2009-2016, NVIDIA Corporation, all rights reserved. Copyright (C) 2010-2013, Advanced Micro Devices, Inc., all rights reserved. Copyright (C) 2015-2016, OpenCV Foundation, all rights reserved. Copyright (C) 2015-2016, Itseez Inc., all rights reserved. Apache Logging http://logging.apache.org/log4cxx/license.html Apache Copyright © 1999-2012 Apache Software Foundation License V2 Google Test https://github.com/abseil/googletest/blob/master/google BSD* test/LICENSE Copyright 2008, Google Inc. SAML 2.0 component for https://github.com/jitbit/AspNetSaml/blob/master/LICEN MIT ASP.NET SE Copyright 2018 Jitbit LP Nvidia Video Codec https://github.com/lu-zero/nvidia-video- MIT codec/blob/master/LICENSE Copyright (c) 2016 NVIDIA Corporation FFMpeg 4 https://www.ffmpeg.org/legal.html LesserGPL FFmpeg is a trademark of Fabrice Bellard, originator v2.1 of the FFmpeg project 7zip.exe https://www.7-zip.org/license.txt LesserGPL 7-Zip Copyright (C) 1999-2019 Igor Pavlov v2.1/3- Clause BSD Infralution.Localization.Wp http://www.codeproject.com/info/cpol10.aspx CPOL f Copyright (C) 2018 Infralution Pty Ltd directShowlib .net https://github.com/pauldotknopf/DirectShow.NET/blob/ LesserGPL -

ROOT I/O Compression Improvements for HEP Analysis
EPJ Web of Conferences 245, 02017 (2020) https://doi.org/10.1051/epjconf/202024502017 CHEP 2019 ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, enhancing it by improving its performance and interaction with other data analysis ecosys- tems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased over the last couple of years. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly, because there are significant trade-offs between the increased CPU cost for reading and writing files and the reduces storage space. 1 Introduction In the past years, Large Hadron Collider (LHC) experiments are managing about an exabyte of storage for analysis purposes, approximately half of which is stored on tape storages for archival purposes, and half is used for traditional disk storage. Meanwhile for High Lumi- nosity Large Hadron Collider (HL-LHC) storage requirements per year are expected to be increased by a factor of 10 [1]. -
![Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020](https://docslib.b-cdn.net/cover/5419/arxiv-2004-10531v1-cs-oh-8-apr-2020-215419.webp)
Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020
ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, increasing per- formance and enhancing it and improving its interaction with other data analy- sis ecosystems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly to improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased during the LHC era. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly: there are sig- nificant trade-offs between the increased CPU cost for reading and writing files and the reduce storage space. 1 Introduction In the past years LHC experiments are commissioned and now manages about an exabyte of storage for analysis purposes, approximately half of which is used for archival purposes, and half is used for traditional disk storage. Meanwhile for HL-LHC storage requirements per year are expected to be increased by factor 10 [1]. arXiv:2004.10531v1 [cs.OH] 8 Apr 2020 Looking at these predictions, we would like to state that storage will remain one of the major cost drivers and at the same time the bottlenecks for HEP computing. -

Unfoldr Dstep
Asymmetric Numeral Systems Jeremy Gibbons WG2.11#19 Salem ANS 2 1. Coding Huffman coding (HC) • efficient; optimally effective for bit-sequence-per-symbol arithmetic coding (AC) • Shannon-optimal (fractional entropy); but computationally expensive asymmetric numeral systems (ANS) • efficiency of Huffman, effectiveness of arithmetic coding applications of streaming (another story) • ANS introduced by Jarek Duda (2006–2013). Now: Facebook (Zstandard), Apple (LZFSE), Google (Draco), Dropbox (DivANS). ANS 3 2. Intervals Pairs of rationals type Interval (Rational, Rational) = with operations unit (0, 1) = weight (l, r) x l (r l) x = + − ⇥ narrow i (p, q) (weight i p, weight i q) = scale (l, r) x (x l)/(r l) = − − widen i (p, q) (scale i p, scale i q) = so that narrow and unit form a monoid, and inverse relationships: weight i x i x unit 2 () 2 weight i x y scale i y x = () = narrow i j k widen i k j = () = ANS 4 3. Models Given counts :: [(Symbol, Integer)] get encodeSym :: Symbol Interval ! decodeSym :: Rational Symbol ! such that decodeSym x s x encodeSym s = () 2 1 1 1 1 Eg alphabet ‘a’, ‘b’, ‘c’ with counts 2, 3, 5 encoded as (0, /5), ( /5, /2), and ( /2, 1). { } ANS 5 4. Arithmetic coding encode1 :: [Symbol ] Rational ! encode1 pick foldl estep unit where = ◦ 1 estep :: Interval Symbol Interval 1 ! ! estep is narrow i (encodeSym s) 1 = decode1 :: Rational [Symbol ] ! decode1 unfoldr dstep where = 1 dstep :: Rational Maybe (Symbol, Rational) 1 ! dstep x let s decodeSym x in Just (s, scale (encodeSym s) x) 1 = = where pick :: Interval Rational satisfies pick i i. -

Compresso: Efficient Compression of Segmentation Data for Connectomics
Compresso: Efficient Compression of Segmentation Data For Connectomics Brian Matejek, Daniel Haehn, Fritz Lekschas, Michael Mitzenmacher, Hanspeter Pfister Harvard University, Cambridge, MA 02138, USA bmatejek,haehn,lekschas,michaelm,[email protected] Abstract. Recent advances in segmentation methods for connectomics and biomedical imaging produce very large datasets with labels that assign object classes to image pixels. The resulting label volumes are bigger than the raw image data and need compression for efficient stor- age and transfer. General-purpose compression methods are less effective because the label data consists of large low-frequency regions with struc- tured boundaries unlike natural image data. We present Compresso, a new compression scheme for label data that outperforms existing ap- proaches by using a sliding window to exploit redundancy across border regions in 2D and 3D. We compare our method to existing compression schemes and provide a detailed evaluation on eleven biomedical and im- age segmentation datasets. Our method provides a factor of 600-2200x compression for label volumes, with running times suitable for practice. Keywords: compression, encoding, segmentation, connectomics 1 Introduction Connectomics|reconstructing the wiring diagram of a mammalian brain at nanometer resolution|results in datasets at the scale of petabytes [21,8]. Ma- chine learning methods find cell membranes and create cell body labelings for every neuron [18,12,14] (Fig. 1). These segmentations are stored as label volumes that are typically encoded in 32 bits or 64 bits per voxel to support labeling of millions of different nerve cells (neurons). Storing such data is expensive and transferring the data is slow. To cut costs and delays, we need compression methods to reduce data sizes. -

The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on Iot Nodes in Smart Cities
sensors Article The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on IoT Nodes in Smart Cities Ammar Nasif *, Zulaiha Ali Othman and Nor Samsiah Sani Center for Artificial Intelligence Technology (CAIT), Faculty of Information Science & Technology, University Kebangsaan Malaysia, Bangi 43600, Malaysia; [email protected] (Z.A.O.); [email protected] (N.S.S.) * Correspondence: [email protected] Abstract: Networking is crucial for smart city projects nowadays, as it offers an environment where people and things are connected. This paper presents a chronology of factors on the development of smart cities, including IoT technologies as network infrastructure. Increasing IoT nodes leads to increasing data flow, which is a potential source of failure for IoT networks. The biggest challenge of IoT networks is that the IoT may have insufficient memory to handle all transaction data within the IoT network. We aim in this paper to propose a potential compression method for reducing IoT network data traffic. Therefore, we investigate various lossless compression algorithms, such as entropy or dictionary-based algorithms, and general compression methods to determine which algorithm or method adheres to the IoT specifications. Furthermore, this study conducts compression experiments using entropy (Huffman, Adaptive Huffman) and Dictionary (LZ77, LZ78) as well as five different types of datasets of the IoT data traffic. Though the above algorithms can alleviate the IoT data traffic, adaptive Huffman gave the best compression algorithm. Therefore, in this paper, Citation: Nasif, A.; Othman, Z.A.; we aim to propose a conceptual compression method for IoT data traffic by improving an adaptive Sani, N.S. -

Forcepoint DLP Supported File Formats and Size Limits
Forcepoint DLP Supported File Formats and Size Limits Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 This article provides a list of the file formats that can be analyzed by Forcepoint DLP, file formats from which content and meta data can be extracted, and the file size limits for network, endpoint, and discovery functions. See: ● Supported File Formats ● File Size Limits © 2021 Forcepoint LLC Supported File Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 The following tables lists the file formats supported by Forcepoint DLP. File formats are in alphabetical order by format group. ● Archive For mats, page 3 ● Backup Formats, page 7 ● Business Intelligence (BI) and Analysis Formats, page 8 ● Computer-Aided Design Formats, page 9 ● Cryptography Formats, page 12 ● Database Formats, page 14 ● Desktop publishing formats, page 16 ● eBook/Audio book formats, page 17 ● Executable formats, page 18 ● Font formats, page 20 ● Graphics formats - general, page 21 ● Graphics formats - vector graphics, page 26 ● Library formats, page 29 ● Log formats, page 30 ● Mail formats, page 31 ● Multimedia formats, page 32 ● Object formats, page 37 ● Presentation formats, page 38 ● Project management formats, page 40 ● Spreadsheet formats, page 41 ● Text and markup formats, page 43 ● Word processing formats, page 45 ● Miscellaneous formats, page 53 Supported file formats are added and updated frequently. Key to support tables Symbol Description Y The format is supported N The format is not supported P Partial metadata -

Compression: Putting the Squeeze on Storage
Compression: Putting the Squeeze on Storage Live Webcast September 2, 2020 11:00 am PT 1 | ©2020 Storage Networking Industry Association. All Rights Reserved. Today’s Presenters Ilker Cebeli John Kim Brian Will Moderator Chair, SNIA Networking Storage Forum Intel® QuickAssist Technology Samsung NVIDIA Software Architect Intel 2 | ©2020 Storage Networking Industry Association. All Rights Reserved. SNIA-At-A-Glance 3 3 | ©2020 Storage Networking Industry Association. All Rights Reserved. NSF Technologies 4 4 | ©2020 Storage Networking Industry Association. All Rights Reserved. SNIA Legal Notice § The material contained in this presentation is copyrighted by the SNIA unless otherwise noted. § Member companies and individual members may use this material in presentations and literature under the following conditions: § Any slide or slides used must be reproduced in their entirety without modification § The SNIA must be acknowledged as the source of any material used in the body of any document containing material from these presentations. § This presentation is a project of the SNIA. § Neither the author nor the presenter is an attorney and nothing in this presentation is intended to be, or should be construed as legal advice or an opinion of counsel. If you need legal advice or a legal opinion please contact your attorney. § The information presented herein represents the author's personal opinion and current understanding of the relevant issues involved. The author, the presenter, and the SNIA do not assume any responsibility or liability for damages arising out of any reliance on or use of this information. NO WARRANTIES, EXPRESS OR IMPLIED. USE AT YOUR OWN RISK. 5 | ©2020 Storage Networking Industry Association. -

In-Core Compression: How to Shrink Your Database Size in Several Times
In-core compression: how to shrink your database size in several times Aleksander Alekseev Anastasia Lubennikova www.postgrespro.ru Agenda ● What does Postgres store? • A couple of words about storage internals ● Check list for your schema • A set of tricks to optimize database size ● In-core block level compression • Out-of-box feature of Postgres Pro EE ● ZSON • Extension for transparent JSONB compression What this talk doesn’t cover ● MVCC bloat • Tune autovacuum properly • Drop unused indexes • Use pg_repack • Try pg_squeeze ● Catalog bloat • Create less temporary tables ● WAL-log size • Enable wal_compression ● FS level compression • ZFS, btrfs, etc Data layout Empty tables are not that empty ● Imagine we have no data create table tbl(); insert into tbl select from generate_series(0,1e07); select pg_size_pretty(pg_relation_size('tbl')); pg_size_pretty --------------- ??? Empty tables are not that empty ● Imagine we have no data create table tbl(); insert into tbl select from generate_series(0,1e07); select pg_size_pretty(pg_relation_size('tbl')); pg_size_pretty --------------- 268 MB Meta information db=# select * from heap_page_items(get_raw_page('tbl',0)); -[ RECORD 1 ]------------------- lp | 1 lp_off | 8160 lp_flags | 1 lp_len | 32 t_xmin | 720 t_xmax | 0 t_field3 | 0 t_ctid | (0,1) t_infomask2 | 2 t_infomask | 2048 t_hoff | 24 t_bits | t_oid | t_data | Order matters ● Attributes must be aligned inside the row create table bad (i1 int, b1 bigint, i1 int); create table good (i1 int, i1 int, b1 bigint); Safe up to 20% of space. -

RFC 8878: Zstandard Compression and the 'Application/Zstd'
Stream: Internet Engineering Task Force (IETF) RFC: 8878 Obsoletes: 8478 Category: Informational Published: February 2021 ISSN: 2070-1721 Authors: Y. Collet M. Kucherawy, Ed. Facebook Facebook RFC 8878 Zstandard Compression and the 'application/zstd' Media Type Abstract Zstandard, or "zstd" (pronounced "zee standard"), is a lossless data compression mechanism. This document describes the mechanism and registers a media type, content encoding, and a structured syntax suffix to be used when transporting zstd-compressed content via MIME. Despite use of the word "standard" as part of Zstandard, readers are advised that this document is not an Internet Standards Track specification; it is being published for informational purposes only. This document replaces and obsoletes RFC 8478. Status of This Memo This document is not an Internet Standards Track specification; it is published for informational purposes. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Not all documents approved by the IESG are candidates for any level of Internet Standard; see Section 2 of RFC 7841. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at https://www.rfc-editor.org/info/rfc8878. Copyright Notice Copyright (c) 2021 IETF Trust and the persons identified as the document authors. All rights reserved. Collet & Kucherawy Informational Page 1 RFC 8878 application/zstd February 2021 This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (https://trustee.ietf.org/license-info) in effect on the date of publication of this document. -

I Came to Drop Bombs Auditing the Compression Algorithm Weapons Cache
I Came to Drop Bombs Auditing the Compression Algorithm Weapons Cache Cara Marie NCC Group Blackhat USA 2016 About Me • NCC Group Senior Security Consultant Pentested numerous networks, web applications, mobile applications, etc. • Hackbright Graduate • Ticket scalper in a previous life • @bones_codes | [email protected] What is a Decompression Bomb? A decompression bomb is a file designed to crash or render useless the program or system reading it. Vulnerable Vectors • Chat clients • Image hosting • Web browsers • Web servers • Everyday web-services software • Everyday client software • Embedded devices (especially vulnerable due to weak hardware) • Embedded documents • Gzip’d log uploads A History Lesson early 90’s • ARC/LZH/ZIP/RAR bombs were used to DoS FidoNet systems 2002 • Paul L. Daniels publishes Arbomb (Archive “Bomb” detection utility) 2003 • Posting by Steve Wray on FullDisclosure about a bzip2 bomb antivirus software DoS 2004 • AERAsec Network Services and Security publishes research on the various reactions of antivirus software against decompression bombs, includes a comparison chart 2014 • Several CVEs for PIL are issued — first release July 2010 (CVE-2014-3589, CVE-2014-3598, CVE-2014-9601) 2015 • CVE for libpng — first release Aug 2004 (CVE-2015-8126) Why Are We Still Talking About This?!? Why Are We Still Talking About This?!? Compression is the New Hotness Who This Is For Who This Is For The Archives An archive bomb, a.k.a. zip bomb, is often employed to disable antivirus software, in order to create an opening for more traditional viruses • Singly compressed large file • Self-reproducing compressed files, i.e. Russ Cox’s Zips All The Way Down • Nested compressed files, i.e. -

A Novel Coding Architecture for Lidar Point Cloud Sequence
IEEE Robotics and Automation Letters (RAL) paper presented at the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) October 25-29, 2020, Las Vegas, NV, USA (Virtual) A Novel Coding Architecture for LiDAR Point Cloud Sequence Xuebin Sun1*, Sukai Wang2*, Miaohui Wang3, Zheng Wang4 and Ming Liu2, Senior Member, IEEE Abstract— In this paper, we propose a novel coding architec- the point cloud data. However, these methods are unsuitable ture for LiDAR point cloud sequences based on clustering and for unmanned vehicles. Traditional image or video encoding prediction neural networks. LiDAR point clouds are structured, algorithms, such as JPEG2000 , JPEG-LS [3], and HEVC which provides an opportunity to convert the 3D data to a 2D array, represented as range images. Thus, we cast the [4], were designed mostly for encoding integer pixel values, LiDAR point clouds compression as a range images coding and using them to encode floating-point LiDAR data will problem. Inspired by the high efficiency video coding (HEVC) cause significant distortion. Furthermore, the range image is algorithm, we design a novel coding architecture for the point characterized by sharp edges and homogeneous regions with cloud sequence. The scans are divided into two categories: nearly constant values, which is quite different from textured intra-frames and inter-frames. For intra-frames, a cluster-based intra-prediction technique is utilized to remove the spatial video. Thus, coding the range image with traditional tools redundancy. For inter-frames, we design a prediction network such as the block-based discrete cosine transform (DCT) model using convolutional LSTM cells, which is capable of followed by coarse quantization can result in significant predicting future inter-frames according to the encoded intra- coding errors at sharp edges, causing a safety hazard in frames.