Brotli: a General-Purpose Data Compressor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Data Compression: Dictionary-Based Coding 2 / 37 Dictionary-Based Coding Dictionary-Based Coding
Dictionary-based Coding already coded not yet coded search buffer look-ahead buffer cursor (N symbols) (L symbols) We know the past but cannot control it. We control the future but... Last Lecture Last Lecture: Predictive Lossless Coding Predictive Lossless Coding Simple and effective way to exploit dependencies between neighboring symbols / samples Optimal predictor: Conditional mean (requires storage of large tables) Affine and Linear Prediction Simple structure, low-complex implementation possible Optimal prediction parameters are given by solution of Yule-Walker equations Works very well for real signals (e.g., audio, images, ...) Efficient Lossless Coding for Real-World Signals Affine/linear prediction (often: block-adaptive choice of prediction parameters) Entropy coding of prediction errors (e.g., arithmetic coding) Using marginal pmf often already yields good results Can be improved by using conditional pmfs (with simple conditions) Heiko Schwarz (Freie Universität Berlin) — Data Compression: Dictionary-based Coding 2 / 37 Dictionary-based Coding Dictionary-Based Coding Coding of Text Files Very high amount of dependencies Affine prediction does not work (requires linear dependencies) Higher-order conditional coding should work well, but is way to complex (memory) Alternative: Do not code single characters, but words or phrases Example: English Texts Oxford English Dictionary lists less than 230 000 words (including obsolete words) On average, a word contains about 6 characters Average codeword length per character would be limited by 1 -

Package 'Brotli'
Package ‘brotli’ May 13, 2018 Type Package Title A Compression Format Optimized for the Web Version 1.2 Description A lossless compressed data format that uses a combination of the LZ77 algorithm and Huffman coding. Brotli is similar in speed to deflate (gzip) but offers more dense compression. License MIT + file LICENSE URL https://tools.ietf.org/html/rfc7932 (spec) https://github.com/google/brotli#readme (upstream) http://github.com/jeroen/brotli#read (devel) BugReports http://github.com/jeroen/brotli/issues VignetteBuilder knitr, R.rsp Suggests spelling, knitr, R.rsp, microbenchmark, rmarkdown, ggplot2 RoxygenNote 6.0.1 Language en-US NeedsCompilation yes Author Jeroen Ooms [aut, cre] (<https://orcid.org/0000-0002-4035-0289>), Google, Inc [aut, cph] (Brotli C++ library) Maintainer Jeroen Ooms <[email protected]> Repository CRAN Date/Publication 2018-05-13 20:31:43 UTC R topics documented: brotli . .2 Index 4 1 2 brotli brotli Brotli Compression Description Brotli is a compression algorithm optimized for the web, in particular small text documents. Usage brotli_compress(buf, quality = 11, window = 22) brotli_decompress(buf) Arguments buf raw vector with data to compress/decompress quality value between 0 and 11 window log of window size Details Brotli decompression is at least as fast as for gzip while significantly improving the compression ratio. The price we pay is that compression is much slower than gzip. Brotli is therefore most effective for serving static content such as fonts and html pages. For binary (non-text) data, the compression ratio of Brotli usually does not beat bz2 or xz (lzma), however decompression for these algorithms is too slow for browsers in e.g. -
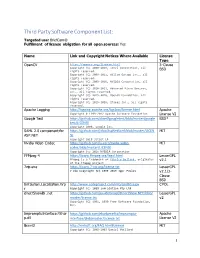
Third Party Software Component List: Targeted Use: Briefcam® Fulfillment of License Obligation for All Open Sources: Yes
Third Party Software Component List: Targeted use: BriefCam® Fulfillment of license obligation for all open sources: Yes Name Link and Copyright Notices Where Available License Type OpenCV https://opencv.org/license.html 3-Clause Copyright (C) 2000-2019, Intel Corporation, all BSD rights reserved. Copyright (C) 2009-2011, Willow Garage Inc., all rights reserved. Copyright (C) 2009-2016, NVIDIA Corporation, all rights reserved. Copyright (C) 2010-2013, Advanced Micro Devices, Inc., all rights reserved. Copyright (C) 2015-2016, OpenCV Foundation, all rights reserved. Copyright (C) 2015-2016, Itseez Inc., all rights reserved. Apache Logging http://logging.apache.org/log4cxx/license.html Apache Copyright © 1999-2012 Apache Software Foundation License V2 Google Test https://github.com/abseil/googletest/blob/master/google BSD* test/LICENSE Copyright 2008, Google Inc. SAML 2.0 component for https://github.com/jitbit/AspNetSaml/blob/master/LICEN MIT ASP.NET SE Copyright 2018 Jitbit LP Nvidia Video Codec https://github.com/lu-zero/nvidia-video- MIT codec/blob/master/LICENSE Copyright (c) 2016 NVIDIA Corporation FFMpeg 4 https://www.ffmpeg.org/legal.html LesserGPL FFmpeg is a trademark of Fabrice Bellard, originator v2.1 of the FFmpeg project 7zip.exe https://www.7-zip.org/license.txt LesserGPL 7-Zip Copyright (C) 1999-2019 Igor Pavlov v2.1/3- Clause BSD Infralution.Localization.Wp http://www.codeproject.com/info/cpol10.aspx CPOL f Copyright (C) 2018 Infralution Pty Ltd directShowlib .net https://github.com/pauldotknopf/DirectShow.NET/blob/ LesserGPL -

ROOT I/O Compression Improvements for HEP Analysis
EPJ Web of Conferences 245, 02017 (2020) https://doi.org/10.1051/epjconf/202024502017 CHEP 2019 ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, enhancing it by improving its performance and interaction with other data analysis ecosys- tems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased over the last couple of years. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly, because there are significant trade-offs between the increased CPU cost for reading and writing files and the reduces storage space. 1 Introduction In the past years, Large Hadron Collider (LHC) experiments are managing about an exabyte of storage for analysis purposes, approximately half of which is stored on tape storages for archival purposes, and half is used for traditional disk storage. Meanwhile for High Lumi- nosity Large Hadron Collider (HL-LHC) storage requirements per year are expected to be increased by a factor of 10 [1]. -

The Perceptual Impact of Different Quantization Schemes in G.719
The perceptual impact of different quantization schemes in G.719 BOTE LIU Master’s Degree Project Stockholm, Sweden May 2013 XR-EE-SIP 2013:001 Abstract In this thesis, three kinds of quantization schemes, Fast Lattice Vector Quantization (FLVQ), Pyramidal Vector Quantization (PVQ) and Scalar Quantization (SQ) are studied in the framework of audio codec G.719. FLVQ is composed of an RE8 -based low-rate lattice vector quantizer and a D8 -based high-rate lattice vector quantizer. PVQ uses pyramidal points in multi-dimensional space and is very suitable for the compression of Laplacian-like sources generated from transform. SQ scheme applies a combination of uniform SQ and entropy coding. Subjective tests of these three versions of audio codecs show that FLVQ and PVQ versions of audio codecs are both better than SQ version for music signals and SQ version of audio codec performs well on speech signals, especially for male speakers. I Acknowledgements I would like to express my sincere gratitude to Ericsson Research, which provides me with such a good thesis work to do. I am indebted to my supervisor, Sebastian Näslund, for sparing time to communicate with me about my work every week and giving me many valuable suggestions. I am also very grateful to Volodya Grancharov and Eric Norvell for their advice and patience as well as consistent encouragement throughout the thesis. My thanks are extended to some other Ericsson researchers for attending the subjective listening evaluation in the thesis. Finally, I want to thank my examiner, Professor Arne Leijon of Royal Institute of Technology (KTH) for reviewing my report very carefully and supporting my work very much. -
![Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020](https://docslib.b-cdn.net/cover/5419/arxiv-2004-10531v1-cs-oh-8-apr-2020-215419.webp)
Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020
ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, increasing per- formance and enhancing it and improving its interaction with other data analy- sis ecosystems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly to improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased during the LHC era. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly: there are sig- nificant trade-offs between the increased CPU cost for reading and writing files and the reduce storage space. 1 Introduction In the past years LHC experiments are commissioned and now manages about an exabyte of storage for analysis purposes, approximately half of which is used for archival purposes, and half is used for traditional disk storage. Meanwhile for HL-LHC storage requirements per year are expected to be increased by factor 10 [1]. arXiv:2004.10531v1 [cs.OH] 8 Apr 2020 Looking at these predictions, we would like to state that storage will remain one of the major cost drivers and at the same time the bottlenecks for HEP computing. -

A New Way of Accelerating Web by Compressing Data with Back Reference-Prefer Geflochtener
442 The International Arab Journal of Information Technology, Vol. 14, No. 4, July 2017 A New Way of Accelerating Web by Compressing Data with Back Reference-Prefer Geflochtener Kushwaha Singh1, Challa Krishna2, and Saini Kumar1 1Department of Computer Science and Engineering, Rajasthan Technical University, India 2Department of Computer Science and Engineering, Panjab University, India Abstract: This research focused on the synthesis of an iterative approach to improve speed of the web and also learning the new methodology to compress the large data with enhanced backward reference preference. In addition, observations on the outcomes obtained from experimentation, group-benchmarks compressions, and time splays for transmissions, the proposed system have been analysed. This resulted in improving the compression of textual data in the Web pages and with this it also gains an interest in hardening the cryptanalysis of the data by maximum reducing the redundancies. This removes unnecessary redundancies with 70% efficiency and compress pages with the 23.75-35% compression ratio. Keywords: Backward references, shortest path technique, HTTP, iterative compression, web, LZSS and LZ77. Received April 25, 2014; accepted August 13, 2014 1. Introduction Algorithm 1: LZ77 Compression Compression is the reduction in data size of if a sufficient length is matched or it may correlate better with next input. information to save space and bandwidth. This can be While (! empty lookaheadBuffer) done on Web data or the entire page including the { header. Data compression is a technique of removing get a remission (position, length) to longer match from search white spaces, inserting a single repeater for the repeated buffer; bytes and replace smaller bits for frequent characters if (length>0) Data Compression (DC) is not only the cost effective { Output (position, length, nextsymbol); technique due to its small size for data storage but it transpose the window length+1 position along; also increases the data transfer rate in data } communication [2]. -

Arithmetic Coding
Arithmetic Coding Arithmetic coding is the most efficient method to code symbols according to the probability of their occurrence. The average code length corresponds exactly to the possible minimum given by information theory. Deviations which are caused by the bit-resolution of binary code trees do not exist. In contrast to a binary Huffman code tree the arithmetic coding offers a clearly better compression rate. Its implementation is more complex on the other hand. In arithmetic coding, a message is encoded as a real number in an interval from one to zero. Arithmetic coding typically has a better compression ratio than Huffman coding, as it produces a single symbol rather than several separate codewords. Arithmetic coding differs from other forms of entropy encoding such as Huffman coding in that rather than separating the input into component symbols and replacing each with a code, arithmetic coding encodes the entire message into a single number, a fraction n where (0.0 ≤ n < 1.0) Arithmetic coding is a lossless coding technique. There are a few disadvantages of arithmetic coding. One is that the whole codeword must be received to start decoding the symbols, and if there is a corrupt bit in the codeword, the entire message could become corrupt. Another is that there is a limit to the precision of the number which can be encoded, thus limiting the number of symbols to encode within a codeword. There also exist many patents upon arithmetic coding, so the use of some of the algorithms also call upon royalty fees. Arithmetic coding is part of the JPEG data format. -

The Basic Principles of Data Compression
The Basic Principles of Data Compression Author: Conrad Chung, 2BrightSparks Introduction Internet users who download or upload files from/to the web, or use email to send or receive attachments will most likely have encountered files in compressed format. In this topic we will cover how compression works, the advantages and disadvantages of compression, as well as types of compression. What is Compression? Compression is the process of encoding data more efficiently to achieve a reduction in file size. One type of compression available is referred to as lossless compression. This means the compressed file will be restored exactly to its original state with no loss of data during the decompression process. This is essential to data compression as the file would be corrupted and unusable should data be lost. Another compression category which will not be covered in this article is “lossy” compression often used in multimedia files for music and images and where data is discarded. Lossless compression algorithms use statistic modeling techniques to reduce repetitive information in a file. Some of the methods may include removal of spacing characters, representing a string of repeated characters with a single character or replacing recurring characters with smaller bit sequences. Advantages/Disadvantages of Compression Compression of files offer many advantages. When compressed, the quantity of bits used to store the information is reduced. Files that are smaller in size will result in shorter transmission times when they are transferred on the Internet. Compressed files also take up less storage space. File compression can zip up several small files into a single file for more convenient email transmission. -

Encryption Introduction to Using 7-Zip
IT Services Training Guide Encryption Introduction to using 7-Zip It Services Training Team The University of Manchester email: [email protected] www.itservices.manchester.ac.uk/trainingcourses/coursesforstaff Version: 5.3 Training Guide Introduction to Using 7-Zip Page 2 IT Services Training Introduction to Using 7-Zip Table of Contents Contents Introduction ......................................................................................................................... 4 Compress/encrypt individual files ....................................................................................... 5 Email compressed/encrypted files ....................................................................................... 8 Decrypt an encrypted file ..................................................................................................... 9 Create a self-extracting encrypted file .............................................................................. 10 Decrypt/un-zip a file .......................................................................................................... 14 APPENDIX A Downloading and installing 7-Zip ................................................................. 15 Help and Further Reference ............................................................................................... 18 Page 3 Training Guide Introduction to Using 7-Zip Introduction 7-Zip is an application that allows you to: Compress a file – for example a file that is 5MB can be compressed to 3MB Secure the -

Pack, Encrypt, Authenticate Document Revision: 2021 05 02
PEA Pack, Encrypt, Authenticate Document revision: 2021 05 02 Author: Giorgio Tani Translation: Giorgio Tani This document refers to: PEA file format specification version 1 revision 3 (1.3); PEA file format specification version 2.0; PEA 1.01 executable implementation; Present documentation is released under GNU GFDL License. PEA executable implementation is released under GNU LGPL License; please note that all units provided by the Author are released under LGPL, while Wolfgang Ehrhardt’s crypto library units used in PEA are released under zlib/libpng License. PEA file format and PCOMPRESS specifications are hereby released under PUBLIC DOMAIN: the Author neither has, nor is aware of, any patents or pending patents relevant to this technology and do not intend to apply for any patents covering it. As far as the Author knows, PEA file format in all of it’s parts is free and unencumbered for all uses. Pea is on PeaZip project official site: https://peazip.github.io , https://peazip.org , and https://peazip.sourceforge.io For more information about the licenses: GNU GFDL License, see http://www.gnu.org/licenses/fdl.txt GNU LGPL License, see http://www.gnu.org/licenses/lgpl.txt 1 Content: Section 1: PEA file format ..3 Description ..3 PEA 1.3 file format details ..5 Differences between 1.3 and older revisions ..5 PEA 2.0 file format details ..7 PEA file format’s and implementation’s limitations ..8 PCOMPRESS compression scheme ..9 Algorithms used in PEA format ..9 PEA security model .10 Cryptanalysis of PEA format .12 Data recovery from -

Hardware Based Compression in Ceph OSD with BTRFS
Hardware Based Compression in Ceph OSD with BTRFS Weigang Li ([email protected]) Tushar Gohad ([email protected]) Data Center Group Intel Corporation 2016 Storage Developer Conference. © Intel Corp. All Rights Reserved. Credits This work wouldn’t have been possible without contributions from – Reddy Chagam ([email protected]) Brian Will ([email protected]) Praveen Mosur ([email protected]) Edward Pullin ([email protected]) 2 2016 Storage Developer Conference. © Intel Corp. All Rights Reserved. Agenda Ceph A Quick Primer Storage Efficiency and Security Features Offload Mechanisms – Software and Hardware Compression in Ceph OSD with BTRFS Compression in BTRFS and Ceph Hardware Acceleration with QAT PoC implementation Performance Results Key Takeaways 3 2016 Storage Developer Conference. © Intel Corp. All Rights Reserved. Ceph Open-source, object-based scale-out storage system Software-defined, hardware-agnostic – runs on commodity hardware Object, Block and File support in a unified storage cluster Highly durable, available – replication, erasure coding Replicates and re-balances dynamically 4 Image source: http://ceph.com/ceph-storage 2016 Storage Developer Conference. © Intel Corp. All Rights Reserved. Ceph Scalability – CRUSH data placement, no single POF Enterprise features – snapshots, cloning, mirroring Most popular block storage for Openstack use cases 10 years of hardening, vibrant community 5 Source: http://www.openstack.org/assets/survey/April-2016-User-Survey-Report.pdf 2016 Storage Developer Conference. © Intel Corp. All Rights Reserved. Ceph: Architecture OSD OSD OSD OSD OSD btrfs xfs ext4 POSIX Backend Backend Backend Backend Backend Bluestore KV DISK DISK DISK DISK DISK Commodity Servers M M M 6 2016 Storage Developer Conference.