Asymmetric Numeral Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

FLAC Decoder Using ARM920T Using S3C2440
International Journal of Engineering Research and Development e-ISSN: 2278-067X, p-ISSN: 2278-800X, www.ijerd.com Volume 4, Issue 7 (November 2012), PP. 21-24 FLAC Decoder using ARM920T using S3C2440 J. L. DivyaShivani1, M. Madan Gopal 2 1M.Tech (Embedded Systems) Student, 2Assoc.Professor Aurora’s Technological & Research Institute Uppal, Hyderabad, INDIA Abstract: In this paper, an embedded FLAC decoder system was designed, and the embedded development platform of ARM920T was built for the design. Furthermore, the IIS bus of S3C2440 in Linux which were used in designing the decoder system. Results show that the FLAC format sound can play well in the decoder system. The decoding solution can be applied to many high-end audio devices. With the development of multimedia technology, as well as the people's requirements to higher sound quality, the Lossy compression coding audio format such as MP3 cannot satisfy many music lovers. Therefore, many R & D staffs have research on how to develop Lossless Audio Decoding systems based on embedded devices with lower price and better sound quality. FLAC stands for Free Lossless Audio Codec, an audio format similar to MP3, but lossless, meaning that audio is compressed in FLAC without any loss in quality. This is similar to how Zip works, except with FLAC you will get much better compression because it is designed specifically for audio, and you can play back compressed FLAC files in your favorite player (or your car or home stereo) just like you would an MP3 file. FLAC stands out as the fastest and most widely supported lossless audio codec, and the only one that at once is non-proprietary, is unencumbered by patents, has an open- source reference implementation, has a well-documented format and API, and has several other independent implementations. -

Package 'Brotli'
Package ‘brotli’ May 13, 2018 Type Package Title A Compression Format Optimized for the Web Version 1.2 Description A lossless compressed data format that uses a combination of the LZ77 algorithm and Huffman coding. Brotli is similar in speed to deflate (gzip) but offers more dense compression. License MIT + file LICENSE URL https://tools.ietf.org/html/rfc7932 (spec) https://github.com/google/brotli#readme (upstream) http://github.com/jeroen/brotli#read (devel) BugReports http://github.com/jeroen/brotli/issues VignetteBuilder knitr, R.rsp Suggests spelling, knitr, R.rsp, microbenchmark, rmarkdown, ggplot2 RoxygenNote 6.0.1 Language en-US NeedsCompilation yes Author Jeroen Ooms [aut, cre] (<https://orcid.org/0000-0002-4035-0289>), Google, Inc [aut, cph] (Brotli C++ library) Maintainer Jeroen Ooms <[email protected]> Repository CRAN Date/Publication 2018-05-13 20:31:43 UTC R topics documented: brotli . .2 Index 4 1 2 brotli brotli Brotli Compression Description Brotli is a compression algorithm optimized for the web, in particular small text documents. Usage brotli_compress(buf, quality = 11, window = 22) brotli_decompress(buf) Arguments buf raw vector with data to compress/decompress quality value between 0 and 11 window log of window size Details Brotli decompression is at least as fast as for gzip while significantly improving the compression ratio. The price we pay is that compression is much slower than gzip. Brotli is therefore most effective for serving static content such as fonts and html pages. For binary (non-text) data, the compression ratio of Brotli usually does not beat bz2 or xz (lzma), however decompression for these algorithms is too slow for browsers in e.g. -

Lossless Audio Codec Comparison
Contents Introduction 3 1 CD-audio test 4 1.1 CD's used . .4 1.2 Results all CD's together . .4 1.3 Interesting quirks . .7 1.3.1 Mono encoded as stereo (Dan Browns Angels and Demons) . .7 1.3.2 Compressibility . .9 1.4 Convergence of the results . 10 2 High-resolution audio 13 2.1 Nine Inch Nails' The Slip . 13 2.2 Howard Shore's soundtrack for The Lord of the Rings: The Return of the King . 16 2.3 Wasted bits . 18 3 Multichannel audio 20 3.1 Howard Shore's soundtrack for The Lord of the Rings: The Return of the King . 20 A Motivation for choosing these CDs 23 B Test setup 27 B.1 Scripting and graphing . 27 B.2 Codecs and parameters used . 27 B.3 MD5 checksumming . 28 C Revision history 30 Bibliography 31 2 Introduction While testing the efficiency of lossy codecs can be quite cumbersome (as results differ for each person), comparing lossless codecs is much easier. As the last well documented and comprehensive test available on the internet has been a few years ago, I thought it would be a good idea to update. Beside comparing with CD-audio (which is often done to assess codec performance) and spitting out a grand total, this comparison also looks at extremes that occurred during the test and takes a look at 'high-resolution audio' and multichannel/surround audio. While the comparison was made to update the comparison-page on the FLAC website, it aims to be fair and unbiased. -

Data Preparation & Descriptive Statistics
Data Preparation & Descriptive Statistics (ver. 2.4) Oscar Torres-Reyna Data Consultant [email protected] PU/DSS/OTR http://dss.princeton.edu/training/ Basic definitions… For statistical analysis we think of data as a collection of different pieces of information or facts. These pieces of information are called variables. A variable is an identifiable piece of data containing one or more values. Those values can take the form of a number or text (which could be converted into number) In the table below variables var1 thru var5 are a collection of seven values, ‘id’ is the identifier for each observation. This dataset has information for seven cases (in this case people, but could also be states, countries, etc) grouped into five variables. id var1 var2 var3 var4 var5 1 7.3 32.27 0.1 Yes Male 2 8.28 40.68 0.56 No Female 3 3.35 5.62 0.55 Yes Female 4 4.08 62.8 0.83 Yes Male 5 9.09 22.76 0.26 No Female 6 8.15 90.85 0.23 Yes Female 7 7.59 54.94 0.42 Yes Male PU/DSS/OTR Data structure… For data analysis your data should have variables as columns and observations as rows. The first row should have the column headings. Make sure your dataset has at least one identifier (for example, individual id, family id, etc.) id var1 var2 var3 var4 var5 First row should have the variable names 1 7.3 32.27 0.1 Yes Male 2 8.28 40.68 0.56 No Female Cross-sectional data 3 3.35 5.62 0.55 Yes Female 4 4.08 62.8 0.83 Yes Male 5 9.09 22.76 0.26 No Female 6 8.15 90.85 0.23 Yes Female 7 7.59 54.94 0.42 Yes Male id year var1 var2 var3 1 2000 7 74.03 0.55 Group 1 1 2001 2 4.6 0.44 At least one identifier 1 2002 2 25.56 0.77 2 2000 7 59.52 0.05 Cross-sectional time series data Group 2 2 2001 2 16.95 0.94 or panel data 2 2002 9 1.2 0.08 3 2000 9 85.85 0.5 Group 3 3 2001 3 98.85 0.32 3 2002 3 69.2 0.76 PU/DSS/OTR NOTE: See: http://www.statistics.com/resources/glossary/c/crossdat.php Data format (ASCII)… ASCII (American Standard Code for Information Interchange). -
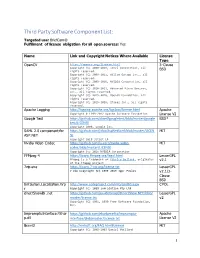
Third Party Software Component List: Targeted Use: Briefcam® Fulfillment of License Obligation for All Open Sources: Yes
Third Party Software Component List: Targeted use: BriefCam® Fulfillment of license obligation for all open sources: Yes Name Link and Copyright Notices Where Available License Type OpenCV https://opencv.org/license.html 3-Clause Copyright (C) 2000-2019, Intel Corporation, all BSD rights reserved. Copyright (C) 2009-2011, Willow Garage Inc., all rights reserved. Copyright (C) 2009-2016, NVIDIA Corporation, all rights reserved. Copyright (C) 2010-2013, Advanced Micro Devices, Inc., all rights reserved. Copyright (C) 2015-2016, OpenCV Foundation, all rights reserved. Copyright (C) 2015-2016, Itseez Inc., all rights reserved. Apache Logging http://logging.apache.org/log4cxx/license.html Apache Copyright © 1999-2012 Apache Software Foundation License V2 Google Test https://github.com/abseil/googletest/blob/master/google BSD* test/LICENSE Copyright 2008, Google Inc. SAML 2.0 component for https://github.com/jitbit/AspNetSaml/blob/master/LICEN MIT ASP.NET SE Copyright 2018 Jitbit LP Nvidia Video Codec https://github.com/lu-zero/nvidia-video- MIT codec/blob/master/LICENSE Copyright (c) 2016 NVIDIA Corporation FFMpeg 4 https://www.ffmpeg.org/legal.html LesserGPL FFmpeg is a trademark of Fabrice Bellard, originator v2.1 of the FFmpeg project 7zip.exe https://www.7-zip.org/license.txt LesserGPL 7-Zip Copyright (C) 1999-2019 Igor Pavlov v2.1/3- Clause BSD Infralution.Localization.Wp http://www.codeproject.com/info/cpol10.aspx CPOL f Copyright (C) 2018 Infralution Pty Ltd directShowlib .net https://github.com/pauldotknopf/DirectShow.NET/blob/ LesserGPL -

Download Media Player Codec Pack Version 4.1 Media Player Codec Pack
download media player codec pack version 4.1 Media Player Codec Pack. Description: In Microsoft Windows 10 it is not possible to set all file associations using an installer. Microsoft chose to block changes of file associations with the introduction of their Zune players. Third party codecs are also blocked in some instances, preventing some files from playing in the Zune players. A simple workaround for this problem is to switch playback of video and music files to Windows Media Player manually. In start menu click on the "Settings". In the "Windows Settings" window click on "System". On the "System" pane click on "Default apps". On the "Choose default applications" pane click on "Films & TV" under "Video Player". On the "Choose an application" pop up menu click on "Windows Media Player" to set Windows Media Player as the default player for video files. Footnote: The same method can be used to apply file associations for music, by simply clicking on "Groove Music" under "Media Player" instead of changing Video Player in step 4. Media Player Codec Pack Plus. Codec's Explained: A codec is a piece of software on either a device or computer capable of encoding and/or decoding video and/or audio data from files, streams and broadcasts. The word Codec is a portmanteau of ' co mpressor- dec ompressor' Compression types that you will be able to play include: x264 | x265 | h.265 | HEVC | 10bit x265 | 10bit x264 | AVCHD | AVC DivX | XviD | MP4 | MPEG4 | MPEG2 and many more. File types you will be able to play include: .bdmv | .evo | .hevc | .mkv | .avi | .flv | .webm | .mp4 | .m4v | .m4a | .ts | .ogm .ac3 | .dts | .alac | .flac | .ape | .aac | .ogg | .ofr | .mpc | .3gp and many more. -

Full Document
R&D Centre for Mobile Applications (RDC) FEE, Dept of Telecommunications Engineering Czech Technical University in Prague RDC Technical Report TR-13-4 Internship report Evaluation of Compressibility of the Output of the Information-Concealing Algorithm Julien Mamelli, [email protected] 2nd year student at the Ecole´ des Mines d'Al`es (N^ımes,France) Internship supervisor: Luk´aˇsKencl, [email protected] August 2013 Abstract Compression is a key element to exchange files over the Internet. By generating re- dundancies, the concealing algorithm proposed by Kencl and Loebl [?], appears at first glance to be particularly designed to be combined with a compression scheme [?]. Is the output of the concealing algorithm actually compressible? We have tried 16 compression techniques on 1 120 files, and the result is that we have not found a solution which could advantageously use repetitions of the concealing method. Acknowledgments I would like to express my gratitude to my supervisor, Dr Luk´aˇsKencl, for his guidance and expertise throughout the course of this work. I would like to thank Prof. Robert Beˇst´akand Mr Pierre Runtz, for giving me the opportunity to carry out my internship at the Czech Technical University in Prague. I would also like to thank all the members of the Research and Development Center for Mobile Applications as well as my colleagues for the assistance they have given me during this period. 1 Contents 1 Introduction 3 2 Related Work 4 2.1 Information concealing method . 4 2.2 Archive formats . 5 2.3 Compression algorithms . 5 2.3.1 Lempel-Ziv algorithm . -

Encryption Introduction to Using 7-Zip
IT Services Training Guide Encryption Introduction to using 7-Zip It Services Training Team The University of Manchester email: [email protected] www.itservices.manchester.ac.uk/trainingcourses/coursesforstaff Version: 5.3 Training Guide Introduction to Using 7-Zip Page 2 IT Services Training Introduction to Using 7-Zip Table of Contents Contents Introduction ......................................................................................................................... 4 Compress/encrypt individual files ....................................................................................... 5 Email compressed/encrypted files ....................................................................................... 8 Decrypt an encrypted file ..................................................................................................... 9 Create a self-extracting encrypted file .............................................................................. 10 Decrypt/un-zip a file .......................................................................................................... 14 APPENDIX A Downloading and installing 7-Zip ................................................................. 15 Help and Further Reference ............................................................................................... 18 Page 3 Training Guide Introduction to Using 7-Zip Introduction 7-Zip is an application that allows you to: Compress a file – for example a file that is 5MB can be compressed to 3MB Secure the -

Pack, Encrypt, Authenticate Document Revision: 2021 05 02
PEA Pack, Encrypt, Authenticate Document revision: 2021 05 02 Author: Giorgio Tani Translation: Giorgio Tani This document refers to: PEA file format specification version 1 revision 3 (1.3); PEA file format specification version 2.0; PEA 1.01 executable implementation; Present documentation is released under GNU GFDL License. PEA executable implementation is released under GNU LGPL License; please note that all units provided by the Author are released under LGPL, while Wolfgang Ehrhardt’s crypto library units used in PEA are released under zlib/libpng License. PEA file format and PCOMPRESS specifications are hereby released under PUBLIC DOMAIN: the Author neither has, nor is aware of, any patents or pending patents relevant to this technology and do not intend to apply for any patents covering it. As far as the Author knows, PEA file format in all of it’s parts is free and unencumbered for all uses. Pea is on PeaZip project official site: https://peazip.github.io , https://peazip.org , and https://peazip.sourceforge.io For more information about the licenses: GNU GFDL License, see http://www.gnu.org/licenses/fdl.txt GNU LGPL License, see http://www.gnu.org/licenses/lgpl.txt 1 Content: Section 1: PEA file format ..3 Description ..3 PEA 1.3 file format details ..5 Differences between 1.3 and older revisions ..5 PEA 2.0 file format details ..7 PEA file format’s and implementation’s limitations ..8 PCOMPRESS compression scheme ..9 Algorithms used in PEA format ..9 PEA security model .10 Cryptanalysis of PEA format .12 Data recovery from -

Metadefender Core V4.12.2
MetaDefender Core v4.12.2 © 2018 OPSWAT, Inc. All rights reserved. OPSWAT®, MetadefenderTM and the OPSWAT logo are trademarks of OPSWAT, Inc. All other trademarks, trade names, service marks, service names, and images mentioned and/or used herein belong to their respective owners. Table of Contents About This Guide 13 Key Features of Metadefender Core 14 1. Quick Start with Metadefender Core 15 1.1. Installation 15 Operating system invariant initial steps 15 Basic setup 16 1.1.1. Configuration wizard 16 1.2. License Activation 21 1.3. Scan Files with Metadefender Core 21 2. Installing or Upgrading Metadefender Core 22 2.1. Recommended System Requirements 22 System Requirements For Server 22 Browser Requirements for the Metadefender Core Management Console 24 2.2. Installing Metadefender 25 Installation 25 Installation notes 25 2.2.1. Installing Metadefender Core using command line 26 2.2.2. Installing Metadefender Core using the Install Wizard 27 2.3. Upgrading MetaDefender Core 27 Upgrading from MetaDefender Core 3.x 27 Upgrading from MetaDefender Core 4.x 28 2.4. Metadefender Core Licensing 28 2.4.1. Activating Metadefender Licenses 28 2.4.2. Checking Your Metadefender Core License 35 2.5. Performance and Load Estimation 36 What to know before reading the results: Some factors that affect performance 36 How test results are calculated 37 Test Reports 37 Performance Report - Multi-Scanning On Linux 37 Performance Report - Multi-Scanning On Windows 41 2.6. Special installation options 46 Use RAMDISK for the tempdirectory 46 3. Configuring Metadefender Core 50 3.1. Management Console 50 3.2. -

A Novel Coding Architecture for Multi-Line Lidar Point Clouds
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination. IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS 1 A Novel Coding Architecture for Multi-Line LiDAR Point Clouds Based on Clustering and Convolutional LSTM Network Xuebin Sun , Sukai Wang , Graduate Student Member, IEEE, and Ming Liu , Senior Member, IEEE Abstract— Light detection and ranging (LiDAR) plays an preservation of historical relics, 3D sensing for smart city, indispensable role in autonomous driving technologies, such as well as autonomous driving. Especially for autonomous as localization, map building, navigation and object avoidance. driving systems, LiDAR sensors play an indispensable role However, due to the vast amount of data, transmission and storage could become an important bottleneck. In this article, in a large number of key techniques, such as simultaneous we propose a novel compression architecture for multi-line localization and mapping (SLAM) [1], path planning [2], LiDAR point cloud sequences based on clustering and convolu- obstacle avoidance [3], and navigation. A point cloud consists tional long short-term memory (LSTM) networks. LiDAR point of a set of individual 3D points, in accordance with one or clouds are structured, which provides an opportunity to convert more attributes (color, reflectance, surface normal, etc). For the 3D data to 2D array, represented as range images. Thus, we cast the 3D point clouds compression as a range image instance, the Velodyne HDL-64E LiDAR sensor generates a sequence compression problem. Inspired by the high efficiency point cloud of up to 2.2 billion points per second, with a video coding (HEVC) algorithm, we design a novel compression range of up to 120 m. -

Opus, a Free, High-Quality Speech and Audio Codec
Opus, a free, high-quality speech and audio codec Jean-Marc Valin, Koen Vos, Timothy B. Terriberry, Gregory Maxwell 29 January 2014 Xiph.Org & Mozilla What is Opus? ● New highly-flexible speech and audio codec – Works for most audio applications ● Completely free – Royalty-free licensing – Open-source implementation ● IETF RFC 6716 (Sep. 2012) Xiph.Org & Mozilla Why a New Audio Codec? http://xkcd.com/927/ http://imgs.xkcd.com/comics/standards.png Xiph.Org & Mozilla Why Should You Care? ● Best-in-class performance within a wide range of bitrates and applications ● Adaptability to varying network conditions ● Will be deployed as part of WebRTC ● No licensing costs ● No incompatible flavours Xiph.Org & Mozilla History ● Jan. 2007: SILK project started at Skype ● Nov. 2007: CELT project started ● Mar. 2009: Skype asks IETF to create a WG ● Feb. 2010: WG created ● Jul. 2010: First prototype of SILK+CELT codec ● Dec 2011: Opus surpasses Vorbis and AAC ● Sep. 2012: Opus becomes RFC 6716 ● Dec. 2013: Version 1.1 of libopus released Xiph.Org & Mozilla Applications and Standards (2010) Application Codec VoIP with PSTN AMR-NB Wideband VoIP/videoconference AMR-WB High-quality videoconference G.719 Low-bitrate music streaming HE-AAC High-quality music streaming AAC-LC Low-delay broadcast AAC-ELD Network music performance Xiph.Org & Mozilla Applications and Standards (2013) Application Codec VoIP with PSTN Opus Wideband VoIP/videoconference Opus High-quality videoconference Opus Low-bitrate music streaming Opus High-quality music streaming Opus Low-delay