The Case of Coeliac Disease
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genome-Wide Characterization of PRE-1 Reveals a Hidden Evolutionary Relationship Between Suidae and Primates
bioRxiv preprint doi: https://doi.org/10.1101/025791; this version posted August 31, 2015. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Genome-wide characterization of PRE-1 reveals a hidden evolutionary relationship between suidae and primates Hao Yu1,, Qingyan Wu1, Jing Zhag1, Ying zhang1, Chao Lu1, Yunyun Cheng1, Zhihui Zhao1, Andreas Windemuth3, Di Liu2,, Linlin Hao1 1 College of Animal Science, Jilin University, Changchun 130062, China 2 Heilongjiang Academy of Agricultural Sciences, Harbin 150086, China 3 Abcam, Firefly BioWorks Inc, United States Corresponding author: Linlin Hao ([email protected]); Di liu ([email protected]); Andreas Windemuth ([email protected]) Abstract We identified and characterized a free PRE-1 element inserted into the promoter region of the porcine IGFBP7 gene whose integration mechanisms into the genome, including copy number, distribution preferences, capacity to exonize and phyloclustering pattern are similar to that of the primate Alu element. 98% of these PRE-1 elements also contain two conserved internal AluI restriction enzyme recognition sites, and the RNA structure of PRE1 can be folded into a two arms model like the Alu RNA structure. It is more surprising that the length of the PRE-1 fragments is nearly the same in 20 chromosomes and positively correlated to its fracture site frequency. All of these fracture sites are close to the mutation hot spots of PRE-1 families, and most of these hot spots are located in the non-complementary fragile regions of the PRE-1 RNA structure. -

The Title of the Article
Mechanism-Anchored Profiling Derived from Epigenetic Networks Predicts Outcome in Acute Lymphoblastic Leukemia Xinan Yang, PhD1, Yong Huang, MD1, James L Chen, MD1, Jianming Xie, MSc2, Xiao Sun, PhD2, Yves A Lussier, MD1,3,4§ 1Center for Biomedical Informatics and Section of Genetic Medicine, Department of Medicine, The University of Chicago, Chicago, IL 60637 USA 2State Key Laboratory of Bioelectronics, Southeast University, 210096 Nanjing, P.R.China 3The University of Chicago Cancer Research Center, and The Ludwig Center for Metastasis Research, The University of Chicago, Chicago, IL 60637 USA 4The Institute for Genomics and Systems Biology, and the Computational Institute, The University of Chicago, Chicago, IL 60637 USA §Corresponding author Email addresses: XY: [email protected] YH: [email protected] JC: [email protected] JX: [email protected] XS: [email protected] YL: [email protected] - 1 - Abstract Background Current outcome predictors based on “molecular profiling” rely on gene lists selected without consideration for their molecular mechanisms. This study was designed to demonstrate that we could learn about genes related to a specific mechanism and further use this knowledge to predict outcome in patients – a paradigm shift towards accurate “mechanism-anchored profiling”. We propose a novel algorithm, PGnet, which predicts a tripartite mechanism-anchored network associated to epigenetic regulation consisting of phenotypes, genes and mechanisms. Genes termed as GEMs in this network meet all of the following criteria: (i) they are co-expressed with genes known to be involved in the biological mechanism of interest, (ii) they are also differentially expressed between distinct phenotypes relevant to the study, and (iii) as a biomodule, genes correlate with both the mechanism and the phenotype. -

An Order Estimation Based Approach to Identify Response Genes
AN ORDER ESTIMATION BASED APPROACH TO IDENTIFY RESPONSE GENES FOR MICRO ARRAY TIME COURSE DATA A Thesis Presented to The Faculty of Graduate Studies of The University of Guelph by ZHIHENG LU In partial fulfilment of requirements for the degree of Doctor of Philosophy September, 2008 © Zhiheng Lu, 2008 Library and Bibliotheque et 1*1 Archives Canada Archives Canada Published Heritage Direction du Branch Patrimoine de I'edition 395 Wellington Street 395, rue Wellington Ottawa ON K1A0N4 Ottawa ON K1A0N4 Canada Canada Your file Votre reference ISBN: 978-0-494-47605-5 Our file Notre reference ISBN: 978-0-494-47605-5 NOTICE: AVIS: The author has granted a non L'auteur a accorde une licence non exclusive exclusive license allowing Library permettant a la Bibliotheque et Archives and Archives Canada to reproduce, Canada de reproduire, publier, archiver, publish, archive, preserve, conserve, sauvegarder, conserver, transmettre au public communicate to the public by par telecommunication ou par Plntemet, prefer, telecommunication or on the Internet, distribuer et vendre des theses partout dans loan, distribute and sell theses le monde, a des fins commerciales ou autres, worldwide, for commercial or non sur support microforme, papier, electronique commercial purposes, in microform, et/ou autres formats. paper, electronic and/or any other formats. The author retains copyright L'auteur conserve la propriete du droit d'auteur ownership and moral rights in et des droits moraux qui protege cette these. this thesis. Neither the thesis Ni la these ni des extraits substantiels de nor substantial extracts from it celle-ci ne doivent etre imprimes ou autrement may be printed or otherwise reproduits sans son autorisation. -
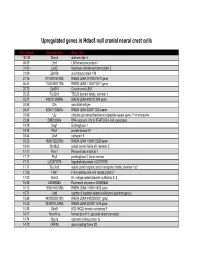
Supp Table 1.Pdf
Upregulated genes in Hdac8 null cranial neural crest cells fold change Gene Symbol Gene Title 134.39 Stmn4 stathmin-like 4 46.05 Lhx1 LIM homeobox protein 1 31.45 Lect2 leukocyte cell-derived chemotaxin 2 31.09 Zfp108 zinc finger protein 108 27.74 0710007G10Rik RIKEN cDNA 0710007G10 gene 26.31 1700019O17Rik RIKEN cDNA 1700019O17 gene 25.72 Cyb561 Cytochrome b-561 25.35 Tsc22d1 TSC22 domain family, member 1 25.27 4921513I08Rik RIKEN cDNA 4921513I08 gene 24.58 Ofa oncofetal antigen 24.47 B230112I24Rik RIKEN cDNA B230112I24 gene 23.86 Uty ubiquitously transcribed tetratricopeptide repeat gene, Y chromosome 22.84 D8Ertd268e DNA segment, Chr 8, ERATO Doi 268, expressed 19.78 Dag1 Dystroglycan 1 19.74 Pkn1 protein kinase N1 18.64 Cts8 cathepsin 8 18.23 1500012D20Rik RIKEN cDNA 1500012D20 gene 18.09 Slc43a2 solute carrier family 43, member 2 17.17 Pcm1 Pericentriolar material 1 17.17 Prg2 proteoglycan 2, bone marrow 17.11 LOC671579 hypothetical protein LOC671579 17.11 Slco1a5 solute carrier organic anion transporter family, member 1a5 17.02 Fbxl7 F-box and leucine-rich repeat protein 7 17.02 Kcns2 K+ voltage-gated channel, subfamily S, 2 16.93 AW493845 Expressed sequence AW493845 16.12 1600014K23Rik RIKEN cDNA 1600014K23 gene 15.71 Cst8 cystatin 8 (cystatin-related epididymal spermatogenic) 15.68 4922502D21Rik RIKEN cDNA 4922502D21 gene 15.32 2810011L19Rik RIKEN cDNA 2810011L19 gene 15.08 Btbd9 BTB (POZ) domain containing 9 14.77 Hoxa11os homeo box A11, opposite strand transcript 14.74 Obp1a odorant binding protein Ia 14.72 ORF28 open reading -

A B-Cell Receptor-Related Gene Signature Predicts Survival in Mantle
Published Ahead of Print on February 22, 2018, as doi:10.3324/haematol.2017.184325. Copyright 2018 Ferrata Storti Foundation. A B-cell receptor-related gene signature predicts survival in mantle cell lymphoma: results from the “Fondazione Italiana Linfomi” MCL-0208 trial by Riccardo Bomben, Simone Ferrero, Tiziana D'Agaro, Michele Dal Bo, Alessandro Re, Andrea Evangelista, Angelo Michele Carella, Alberto Zamò, Umberto Vitolo, Paola Omedè, Chiara Rusconi, Luca Arcaini, Luigi Rigacci, Stefano Luminari, Andrea Piccin, Delong Liu, Adrien Wiestner, Gianluca Gaidano, Sergio Cortelazzo, Marco Ladetto, and Valter Gattei Haematologica 2018 [Epub ahead of print] Citation: Riccardo Bomben, Simone Ferrero, Tiziana D'Agaro, Michele Dal Bo, Alessandro Re, Andrea Evangelista, Angelo Michele Carella, Alberto Zamò, Umberto Vitolo, Paola Omedè, Chiara Rusconi, Luca Arcaini, Luigi Rigacci, Stefano Luminari, Andrea Piccin, Delong Liu, Adrien Wiestner, Gianluca Gaidano, Sergio Cortelazzo, Marco Ladetto, and Valter Gattei. A B-cell receptor-related gene signature predicts survival in mantle cell lymphoma: results from the “Fondazione Italiana Linfomi” MCL-0208 trial. Haematologica. 2018; 103:xxx doi:10.3324/haematol.2017.184325 Publisher's Disclaimer. E-publishing ahead of print is increasingly important for the rapid dissemination of science. Haematologica is, therefore, E-publishing PDF files of an early version of manuscripts that have completed a regular peer review and have been accepted for publication. E-publishing of this PDF file has been approved by the authors. After having E-published Ahead of Print, manuscripts will then undergo technical and English editing, typesetting, proof correction and be presented for the authors' final approval; the final version of the manuscript will then appear in print on a regular issue of the journal. -

Association of Gene Ontology Categories with Decay Rate for Hepg2 Experiments These Tables Show Details for All Gene Ontology Categories
Supplementary Table 1: Association of Gene Ontology Categories with Decay Rate for HepG2 Experiments These tables show details for all Gene Ontology categories. Inferences for manual classification scheme shown at the bottom. Those categories used in Figure 1A are highlighted in bold. Standard Deviations are shown in parentheses. P-values less than 1E-20 are indicated with a "0". Rate r (hour^-1) Half-life < 2hr. Decay % GO Number Category Name Probe Sets Group Non-Group Distribution p-value In-Group Non-Group Representation p-value GO:0006350 transcription 1523 0.221 (0.009) 0.127 (0.002) FASTER 0 13.1 (0.4) 4.5 (0.1) OVER 0 GO:0006351 transcription, DNA-dependent 1498 0.220 (0.009) 0.127 (0.002) FASTER 0 13.0 (0.4) 4.5 (0.1) OVER 0 GO:0006355 regulation of transcription, DNA-dependent 1163 0.230 (0.011) 0.128 (0.002) FASTER 5.00E-21 14.2 (0.5) 4.6 (0.1) OVER 0 GO:0006366 transcription from Pol II promoter 845 0.225 (0.012) 0.130 (0.002) FASTER 1.88E-14 13.0 (0.5) 4.8 (0.1) OVER 0 GO:0006139 nucleobase, nucleoside, nucleotide and nucleic acid metabolism3004 0.173 (0.006) 0.127 (0.002) FASTER 1.28E-12 8.4 (0.2) 4.5 (0.1) OVER 0 GO:0006357 regulation of transcription from Pol II promoter 487 0.231 (0.016) 0.132 (0.002) FASTER 6.05E-10 13.5 (0.6) 4.9 (0.1) OVER 0 GO:0008283 cell proliferation 625 0.189 (0.014) 0.132 (0.002) FASTER 1.95E-05 10.1 (0.6) 5.0 (0.1) OVER 1.50E-20 GO:0006513 monoubiquitination 36 0.305 (0.049) 0.134 (0.002) FASTER 2.69E-04 25.4 (4.4) 5.1 (0.1) OVER 2.04E-06 GO:0007050 cell cycle arrest 57 0.311 (0.054) 0.133 (0.002) -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Complement Factor H and Interleukin Gene Polymorphisms in Patients with Non-Infectious Intermediate and Posterior Uveitis
Molecular Vision 2012; 18:1865-1873 <http://www.molvis.org/molvis/v18/a193> © 2012 Molecular Vision Received 22 March 2012 | Accepted 7 July 2012 | Published 11 July 2012 Complement factor H and interleukin gene polymorphisms in patients with non-infectious intermediate and posterior uveitis Ming-ming Yang, Timothy Y.Y. Lai, Pancy O.S. Tam, Sylvia W.Y. Chiang, Carmen K.M. Chan, Fiona O.J. Luk, Tsz-Kin Ng, Chi-Pui Pang Department of Ophthalmology and Visual Sciences, The Chinese University of Hong Kong, Hong Kong, China Objective: To investigate the associations of complement factor H (CFH), KIAA1109, and interleukin-27 (IL-27) gene polymorphisms in patients with non-infectious intermediate and posterior uveitis. Methods: The study cohort consisted of a total of 95 Chinese non-infectious uveitis patients, including 38 patients with intermediate uveitis (IU), 38 patients with Vogt–Koyanagi–Harada disease (VKH), and 19 patients with Behçet’s disease and 308 healthy controls. The genotypes of CFH-rs800292, KIAA1109-rs4505848, and IL27-rs4788084 were determined using TaqMan single nucleotide polymorphism genotyping assays. Results: The frequency of carriers of G allele for CFH-rs800292 was significantly higher in patients with non-infectious intermediate and posterior uveitis than in controls (GG/AG versus AA; p=0.02). No significant association was found between uveitis and both KIAA1109-rs4505848 and IL27-rs4788084. In stratified analysis by gender, the frequency of carriers with G allele for KIAA1109-rs4505848 was significantly higher in male uveitis patients than in male controls (GG/AG versus AA; p=0.034). There was no significant difference in allelic and genotypic frequencies for CFH-rs800292 and IL27-rs4788084 in either male or female groups. -

Metastatic Adrenocortical Carcinoma Displays Higher Mutation Rate and Tumor Heterogeneity Than Primary Tumors
ARTICLE DOI: 10.1038/s41467-018-06366-z OPEN Metastatic adrenocortical carcinoma displays higher mutation rate and tumor heterogeneity than primary tumors Sudheer Kumar Gara1, Justin Lack2, Lisa Zhang1, Emerson Harris1, Margaret Cam2 & Electron Kebebew1,3 Adrenocortical cancer (ACC) is a rare cancer with poor prognosis and high mortality due to metastatic disease. All reported genetic alterations have been in primary ACC, and it is 1234567890():,; unknown if there is molecular heterogeneity in ACC. Here, we report the genetic changes associated with metastatic ACC compared to primary ACCs and tumor heterogeneity. We performed whole-exome sequencing of 33 metastatic tumors. The overall mutation rate (per megabase) in metastatic tumors was 2.8-fold higher than primary ACC tumor samples. We found tumor heterogeneity among different metastatic sites in ACC and discovered recurrent mutations in several novel genes. We observed 37–57% overlap in genes that are mutated among different metastatic sites within the same patient. We also identified new therapeutic targets in recurrent and metastatic ACC not previously described in primary ACCs. 1 Endocrine Oncology Branch, National Cancer Institute, National Institutes of Health, Bethesda, MD 20892, USA. 2 Center for Cancer Research, Collaborative Bioinformatics Resource, National Cancer Institute, National Institutes of Health, Bethesda, MD 20892, USA. 3 Department of Surgery and Stanford Cancer Institute, Stanford University, Stanford, CA 94305, USA. Correspondence and requests for materials should be addressed to E.K. (email: [email protected]) NATURE COMMUNICATIONS | (2018) 9:4172 | DOI: 10.1038/s41467-018-06366-z | www.nature.com/naturecommunications 1 ARTICLE NATURE COMMUNICATIONS | DOI: 10.1038/s41467-018-06366-z drenocortical carcinoma (ACC) is a rare malignancy with types including primary ACC from the TCGA to understand our A0.7–2 cases per million per year1,2. -

Identifying Lineage Relationships in Human T Cell Populations
Identifying lineage relationships in human T cell populations by Celia Lara Menckeberg A thesis submitted to The University of Birmingham for the degree of DOCTOR OF PHILOSOPHY School of Immunity and Infection College of Medical and Dental Sciences The University of Birmingham December 2010 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ii ABSTRACT CD4+ and CD8+ T cell populations can be divided into subpopulations based on expression of surface markers CCR7 and CD45RA. The resulting populations are referred to as naive, central memory, effector memory and effector memory RA+ (EMRA). The aim of this study was to identify potential lineage relationships between these subpopulations for both CD4+ and CD8+ T cells through microarray analysis. The genes found to distinguish between these subpopulations include many molecules with known functions in T cell differentiation, including CCR7, CD45RA, granzymes, L-selectin and TNF receptors. Several genes from the tetraspanin family of proteins were found to be differentially expressed at mRNA and protein level; suggesting a possible role for these genes in CD4+ and CD8+ T cell activation, migration and lysosomal function. -

View / Download 3.3 Mb
Identification of Mechanisms and Pathways Involved in MLL2-Mediated Tumorigenesis by Chun-Chi Chang Department of Pathology Duke University Date:_______________________ Approved: ___________________________ Yiping He, Supervisor ___________________________ Salvatore Pizzo ___________________________ Hai Yan Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in the Department of Pathology in the Graduate School of Duke University 2013 ABSTRACT Identification of Mechanisms and Pathways Involved in MLL2-Mediated Tumorigenesis by Chun-Chi Chang Department of Pathology Duke University Date:_______________________ Approved: ___________________________ Yiping He, Supervisor ___________________________ Salvatore Pizzo ___________________________ Hai Yan An abstract of a thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in the Department of Pathology in the Graduate School of Duke University 2013 Copyright by Chun-Chi Chang 2013 Abstract Myeloid/lymphoid or mixed-lineage leukemia (MLL)-family genes encode histone lysine methyltransferases that play important roles in epigenetic regulation of gene transcription, and these genes are frequently mutated in human cancers. While MLL1 and MLL4 have been the most extensively studied, MLL2 and its homolog MLL3 are not well-understood. Specifically, little is known regarding the extent of global MLL2 involvement in the regulation of gene expression and the mechanism underlying its alterations in mediating tumorigenesis. To study the role of MLL2 in tumorigenesis, we somatically knocked out MLL2 in a colorectal carcinoma cell line, HCT116. We observed that the MLL2 loss of function results in significant reduction of cell growth and multinuclear morphology. We further profiled MLL2 regulated genes and pathways by analyzing gene expression in MLL2 wild-type versus MLL2-null isogenic cell lines. -

Supp Table 6.Pdf
Supplementary Table 6. Processes associated to the 2037 SCL candidate target genes ID Symbol Entrez Gene Name Process NM_178114 AMIGO2 adhesion molecule with Ig-like domain 2 adhesion NM_033474 ARVCF armadillo repeat gene deletes in velocardiofacial syndrome adhesion NM_027060 BTBD9 BTB (POZ) domain containing 9 adhesion NM_001039149 CD226 CD226 molecule adhesion NM_010581 CD47 CD47 molecule adhesion NM_023370 CDH23 cadherin-like 23 adhesion NM_207298 CERCAM cerebral endothelial cell adhesion molecule adhesion NM_021719 CLDN15 claudin 15 adhesion NM_009902 CLDN3 claudin 3 adhesion NM_008779 CNTN3 contactin 3 (plasmacytoma associated) adhesion NM_015734 COL5A1 collagen, type V, alpha 1 adhesion NM_007803 CTTN cortactin adhesion NM_009142 CX3CL1 chemokine (C-X3-C motif) ligand 1 adhesion NM_031174 DSCAM Down syndrome cell adhesion molecule adhesion NM_145158 EMILIN2 elastin microfibril interfacer 2 adhesion NM_001081286 FAT1 FAT tumor suppressor homolog 1 (Drosophila) adhesion NM_001080814 FAT3 FAT tumor suppressor homolog 3 (Drosophila) adhesion NM_153795 FERMT3 fermitin family homolog 3 (Drosophila) adhesion NM_010494 ICAM2 intercellular adhesion molecule 2 adhesion NM_023892 ICAM4 (includes EG:3386) intercellular adhesion molecule 4 (Landsteiner-Wiener blood group)adhesion NM_001001979 MEGF10 multiple EGF-like-domains 10 adhesion NM_172522 MEGF11 multiple EGF-like-domains 11 adhesion NM_010739 MUC13 mucin 13, cell surface associated adhesion NM_013610 NINJ1 ninjurin 1 adhesion NM_016718 NINJ2 ninjurin 2 adhesion NM_172932 NLGN3 neuroligin