Usage-Based Testing for Event-Driven Software Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Study of Web Crawler and Its Different Types
IOSR Journal of Computer Engineering (IOSR-JCE) e-ISSN: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 1, Ver. VI (Feb. 2014), PP 01-05 www.iosrjournals.org Study of Web Crawler and its Different Types Trupti V. Udapure1, Ravindra D. Kale2, Rajesh C. Dharmik3 1M.E. (Wireless Communication and Computing) student, CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India 2Asst Prof., CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India, 3Asso.Prof. & Head, IT Department, Yeshwantrao Chavan College of Engineering, Nagpur, India, Abstract : Due to the current size of the Web and its dynamic nature, building an efficient search mechanism is very important. A vast number of web pages are continually being added every day, and information is constantly changing. Search engines are used to extract valuable Information from the internet. Web crawlers are the principal part of search engine, is a computer program or software that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. It is an essential method for collecting data on, and keeping in touch with the rapidly increasing Internet. This Paper briefly reviews the concepts of web crawler, its architecture and its various types. Keyword: Crawling techniques, Web Crawler, Search engine, WWW I. Introduction In modern life use of internet is growing in rapid way. The World Wide Web provides a vast source of information of almost all type. Now a day’s people use search engines every now and then, large volumes of data can be explored easily through search engines, to extract valuable information from web. -
Report for Portal Specific
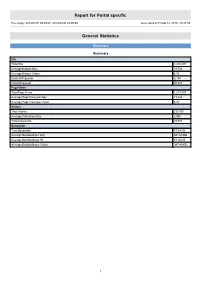
Report for Portal specific Time range: 2013/01/01 00:00:07 - 2013/03/31 23:59:59 Generated on Fri Apr 12, 2013 - 18:27:59 General Statistics Summary Summary Hits Total Hits 1,416,097 Average Hits per Day 15,734 Average Hits per Visitor 6.05 Cached Requests 8,154 Failed Requests 70,823 Page Views Total Page Views 1,217,537 Average Page Views per Day 13,528 Average Page Views per Visitor 5.21 Visitors Total Visitors 233,895 Average Visitors per Day 2,598 Total Unique IPs 49,753 Bandwidth Total Bandwidth 77.49 GB Average Bandwidth per Day 881.68 MB Average Bandwidth per Hit 57.38 KB Average Bandwidth per Visitor 347.40 KB 1 Activity Statistics Daily Daily Visitors 4,000 3,500 3,000 2,500 2,000 Visitors 1,500 1,000 500 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Hits 40,000 35,000 30,000 25,000 Hits 20,000 15,000 10,000 5,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date 2 Daily Bandwidth 1,300,000 1,200,000 1,100,000 1,000,000 900,000 800,000 700,000 600,000 500,000 Bandwidth (KB) 400,000 300,000 200,000 100,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Activity Date Hits Page Views Visitors Average Visit Length Bandwidth (KB) Sun 2013/02/10 11,783 10,245 2,280 13:01 648,207 Mon 2013/02/11 16,454 14,146 2,484 10:05 906,702 Tue 2013/02/12 19,572 17,089 3,062 07:47 926,190 Wed 2013/02/13 14,554 12,402 2,824 06:09 958,951 Thu 2013/02/14 12,577 10,666 2,690 05:03 821,129 Fri 2013/02/15 15,806 12,697 2,868 07:02 1,208,095 Sat 2013/02/16 16,811 14,939 -

Scalability and Efficiency Challenges in Large-Scale Web Search
5/1/14 Scalability and Efficiency Challenges in Large-Scale Web Search Engines " Ricardo Baeza-Yates" B. Barla Cambazoglu! Yahoo Labs" Barcelona, Spain" Disclaimer Dis •# This talk presents the opinions of the authors. It does not necessarily reflect the views of Yahoo Inc. or any other entity." •# Algorithms, techniques, features, etc. mentioned here might or might not be in use by Yahoo or any other company." •# Some non-technical material (e.g., images) provided in this presentation were taken from the Web." 1 5/1/14 Yahoo Labs Barcelona •# Research topics" •# Web retrieval" –# web data mining" –# distributed web retrieval" –# semantic search" –# scalability and efficiency" –# social media" –# opinion/sentiment retrieval" –# web retrieval" –# personalization" Outline of the Tutorial •# Background (35 minutes)" •# Main sections" –# web crawling (75 minutes + 5 minutes Q/A)" –# indexing (75 minutes + 5 minutes Q/A)" –# query processing (90 minutes + 5 minutes Q/A)" –# caching (40 minutes + 5 minutes Q/A)" •# Concluding remarks (10 minutes)" •# Questions and open discussion (15 minutes)" 2 5/1/14 Structure of Main Sections •# Definitions" •# Metrics" •# Issues and techniques" –# single computer" –# cluster of computers" –# multiple search sites" •# Research problems" Background 3 5/1/14 Brief History of Search Engines •# Past" -# Before browsers" -# Gopher" -# Before the bubble" -# Altavista" -# Lycos" -# Infoseek" -# Excite" -# HotBot" •# Current" •# Future" -# After the bubble" •# Global" •# Facebook ?" -# Yahoo" •# Google, Bing" •# …" -

A Focused Web Crawler Driven by Self-Optimizing Classifiers
A Focused Web Crawler Driven by Self-Optimizing Classifiers Master’s Thesis Dominik Sobania Original title: A Focused Web Crawler Driven by Self-Optimizing Classifiers German title: Fokussiertes Webcrawling mit selbstorganisierenden Klassifizierern Master’s Thesis Submitted by Dominik Sobania Submission date: 09/25/2015 Supervisor: Prof. Dr. Chris Biemann Coordinator: Steffen Remus TU Darmstadt Department of Computer Science, Language Technology Group Erklärung Hiermit versichere ich, die vorliegende Master’s Thesis ohne Hilfe Dritter und nur mit den angegebe- nen Quellen und Hilfsmitteln angefertigt zu haben. Alle Stellen, die aus den Quellen entnommen wur- den, sind als solche kenntlich gemacht worden. Diese Arbeit hat in dieser oder ähnlicher Form noch keiner Prüfungsbehörde vorgelegen. Die schriftliche Fassung stimmt mit der elektronischen Fassung überein. Darmstadt, den 25. September 2015 Dominik Sobania i Zusammenfassung Üblicherweise laden Web-Crawler alle Dokumente herunter, die von einer begrenzten Menge Seed- URLs aus erreichbar sind. Für die Generierung von Corpora ist eine Breitensuche allerdings nicht effizient, da uns hier nur ein bestimmtes Thema interessiert. Ein fokussierter Crawler besucht verlinkte Dokumente, die von einer Entscheidungsfunktion ausgewählt wurden, mit höherer Priorität. Dieser Ansatz fokussiert sich selbst auf das gesuchte Thema. In dieser Masterarbeit beschreiben wir einen Ansatz für fokussiertes Crawling, der als erster Schritt für die Generierung von Corpora genutzt werden kann. Basierend auf einem kleinen Satz an Textdoku- menten, die das gesuchte Thema definieren, erstellt eine Pipeline, bestehend aus mehreren Klassifizier- ern, die Trainingsdaten für einen Hyperlink-Klassifizierer – die Entscheidungsfunktion des fokussierten Crawlers. Für die Optimierung der Klassifizierer benutzen wir einen evolutionären Algorithmus für die Feature Subset Selection. Die Chromosomen des evolutionären Algorithmus basieren auf einer serial- isierbaren Baumstruktur. -

Report Per Parmadaily 2009 PDF
Report per ParmaDaily 2009 PDF Intervallo di tempo: 01/01/2009 01:00:01 - 31/12/2009 23:59:54 Generato Lun Apr 12, 2010 - 18:58:58 Statistiche Generali Sommario Sommario Hits Hits Totali 54,508,672 Media Hits per Giorno 149,338 Media Hits per Visitatore 18.40 Richieste Memorizzate 16,245,901 Richieste Fallite 174,116 Pagine Viste Pagine Visitate Totali 6,764,252 Media Pagine Visitate per Giorno 18,532 Media Pagine Visitate per Visitatore 2.28 Visitatori Visitatori Totali 2,961,644 Media Visitatori per Giorno 8,114 IP Univoci Totali 1,608,739 Banda Banda Totale 632.65 GB Banda Media per Giorno 1.73 GB Banda Media per Hit 12.17 KB Banda Media per Visitatore 223.99 KB 1 Statistiche Attività Giornaliera Visitatori Giornalieri 20,000 18,000 16,000 14,000 12,000 10,000 Visitatori 8,000 6,000 4,000 2,000 0 01/02/2009 01/04/2009 01/06/2009 01/08/2009 01/10/2009 01/12/2009 Data Hits Giornaliere 400,000 350,000 300,000 250,000 Hits 200,000 150,000 100,000 50,000 0 01/02/2009 01/04/2009 01/06/2009 01/08/2009 01/10/2009 01/12/2009 Data 2 Banda Giornaliera 4,000,000 3,500,000 3,000,000 2,500,000 2,000,000 Banda (KB) 1,500,000 1,000,000 500,000 0 01/02/2009 01/04/2009 01/06/2009 01/08/2009 01/10/2009 01/12/2009 Data Attività Giornaliera Data Hits Pagine Viste Visitatori Lunghezza Media della Visita Banda (KB) Gio 12/11/2009 181,857 24,969 11,221 02:24 2,181,207 Ven 13/11/2009 183,722 26,136 10,937 02:38 2,232,270 Sab 14/11/2009 102,799 18,120 10,470 02:03 1,532,877 Dom 15/11/2009 99,988 18,326 11,300 02:02 1,529,790 Lun 16/11/2009 166,856 23,796 10,204 -

Application of ARIMA(1,1,0) Model for Predicting Time Delay of Search Engine Crawlers
26 Informatica Economică vol. 17, no. 4/2013 Application of ARIMA(1,1,0) Model for Predicting Time Delay of Search Engine Crawlers Jeeva JOSE1, P. Sojan LAL2 1 Department of Computer Applications, BPC College, Piravom, Kerala, India 2 School of Computer Sciences, Mahatma Gandhi University, Kottayam, Kerala, India [email protected], [email protected] World Wide Web is growing at a tremendous rate in terms of the number of visitors and num- ber of web pages. Search engine crawlers are highly automated programs that periodically visit the web and index web pages. The behavior of search engines could be used in analyzing server load, quality of search engines, dynamics of search engine crawlers, ethics of search engines etc. The more the number of visits of a crawler to a web site, the more it contributes to the workload. The time delay between two consecutive visits of a crawler determines the dynamicity of the crawlers. The ARIMA(1,1,0) Model in time series analysis works well with the forecasting of the time delay between the visits of search crawlers at web sites. We con- sidered 5 search engine crawlers, all of which could be modeled using ARIMA(1,1,0).The re- sults of this study is useful in analyzing the server load. Keywords: ARIMA, Search Engine Crawler, Web logs, Time delay, Prediction Introduction before it crawls the web pages. The crawlers 1 Crawlers also known as ‘bots’, ‘robots’ or which access this file first and proceeds to ‘spiders’ are highly automated programs crawling are known as ethical crawlers and which are seldom regulated manually[1][2]. -
Scalability and Efficiency Challenges in Large-Scale Web Search
7/9/14 Scalability and Efficiency Challenges in Large-Scale Web Search Engines " Ricardo Baeza-Yates" B. Barla Cambazoglu! Yahoo Labs" Barcelona, Spain" Tutorial at SIGIR 2014, Gold Coast, Australia Disclaimer Dis •# This talk presents the opinions of the authors. It does not necessarily reflect the views of Yahoo Inc. or any other entity." •# Algorithms, techniques, features, etc. mentioned here might or might not be in use by Yahoo or any other company." •# Some non-technical material (e.g., images) provided in this presentation were taken from the Web." Ricardo Baeza-Yates & B. Barla Cambazoglu, Yahoo Labs - 2 - Tutorial at SIGIR 2014, Gold Coast, Australia 1 7/9/14 Yahoo Labs Barcelona •# Research topics" •# Web retrieval" –# web data mining" –# distributed web retrieval" –# semantic web" –# scalability and efficiency" –# social media" –# opinion/sentiment retrieval" –# web retrieval" –# personalization" Ricardo Baeza-Yates & B. Barla Cambazoglu, Yahoo Labs - 3 - Tutorial at SIGIR 2014, Gold Coast, Australia Outline of the Tutorial •# Background (35 minutes)" •# Main sections" –# web crawling (75 minutes + 5 minutes Q/A)" –# indexing (75 minutes + 5 minutes Q/A)" –# query processing (90 minutes + 5 minutes Q/A)" –# caching (40 minutes + 5 minutes Q/A)" •# Concluding remarks (10 minutes)" •# Questions and open discussion (15 minutes)" Ricardo Baeza-Yates & B. Barla Cambazoglu, Yahoo Labs - 4 - Tutorial at SIGIR 2014, Gold Coast, Australia 2 7/9/14 Structure of Main Sections •# Definitions" •# Metrics" •# Issues and techniques" –# single computer" –# cluster of computers" –# multiple search sites" •# Research problems" Ricardo Baeza-Yates & B. Barla Cambazoglu, Yahoo Labs - 5 - Tutorial at SIGIR 2014, Gold Coast, Australia Background Ricardo Baeza-Yates & B. -

Digital Marketing Handbook
Digital Marketing Handbook PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 17 Mar 2012 10:33:23 UTC Contents Articles Search Engine Reputation Management 1 Semantic Web 7 Microformat 17 Web 2.0 23 Web 1.0 36 Search engine optimization 37 Search engine 45 Search engine results page 52 Search engine marketing 53 Image search 57 Video search 59 Local search 65 Web presence 67 Internet marketing 70 Web crawler 74 Backlinks 83 Keyword stuffing 85 Article spinning 86 Link farm 87 Spamdexing 88 Index 93 Black hat 102 Danny Sullivan 103 Meta element 105 Meta tags 110 Inktomi 115 Larry Page 118 Sergey Brin 123 PageRank 131 Inbound link 143 Matt Cutts 145 nofollow 146 Open Directory Project 151 Sitemap 160 Robots Exclusion Standard 162 Robots.txt 165 301 redirect 169 Google Instant 179 Google Search 190 Cloaking 201 Web search engine 203 Bing 210 Ask.com 224 Yahoo! Search 228 Tim Berners-Lee 232 Web search query 239 Web crawling 241 Social search 250 Vertical search 252 Web analytics 253 Pay per click 262 Social media marketing 265 Affiliate marketing 269 Article marketing 280 Digital marketing 281 Hilltop algorithm 282 TrustRank 283 Latent semantic indexing 284 Semantic targeting 290 Canonical meta tag 292 Keyword research 293 Latent Dirichlet allocation 293 Vanessa Fox 300 Search engines 302 Site map 309 Sitemaps 311 Methods of website linking 315 Deep linking 317 Backlink 319 URL redirection 321 References Article Sources and Contributors 331 Image Sources, Licenses and Contributors 345 Article Licenses License 346 Search Engine Reputation Management 1 Search Engine Reputation Management Reputation management, is the process of tracking an entity's actions and other entities' opinions about those actions; reporting on those actions and opinions; and reacting to that report creating a feedback loop. -
A Smart Web Crawler for a Concept Based Semantic Search Engine
San Jose State University SJSU ScholarWorks Master's Projects Master's Theses and Graduate Research Fall 12-2014 A Smart Web Crawler for a Concept Based Semantic Search Engine Vinay Kancherla San Jose State University Follow this and additional works at: https://scholarworks.sjsu.edu/etd_projects Part of the Databases and Information Systems Commons Recommended Citation Kancherla, Vinay, "A Smart Web Crawler for a Concept Based Semantic Search Engine" (2014). Master's Projects. 380. DOI: https://doi.org/10.31979/etd.ubfy-s3es https://scholarworks.sjsu.edu/etd_projects/380 This Master's Project is brought to you for free and open access by the Master's Theses and Graduate Research at SJSU ScholarWorks. It has been accepted for inclusion in Master's Projects by an authorized administrator of SJSU ScholarWorks. For more information, please contact [email protected]. A Smart Web Crawler for a Concept Based Semantic Search Engine Presented to The Faculty of Department of computer Science San Jose State University In Partial Fulfillment of the Requirements for the Degree Master of Computer Science By Vinay Kancherla Fall 2014 Copyright © 2014 Vinay Kancherla ALL RIGHTS RESERVED SAN JOSE STATE UNIVERSITY The Designated Thesis Committee Approves the Thesis Titled A Smart Web Crawler for a Concept Based Semantic Search Engine by Vinay Kancherla APPROVED FOR THE DEPARTMENT OF COMPUTER SCIENCE SAN JOSÉ STATE UNIVERSITY December 2014 ________________________________________________________ Dr. T. Y. Lin, Department of Computer Science Date ________________________________________________________ Dr. Suneuy Kim, Department of Computer Science Date ________________________________________________________ Mr. Eric Louie, DBA at IBM Corporation Date ABSTRACT A Smart Web Crawler for a Concept Based Semantic Search Engine By Vinay Kancherla The internet is a vast collection of billions of web pages containing terabytes of information arranged in thousands of servers using HTML. -

Crawlers and Crawling
Crawlers and Crawling There are Many Crawlers • A web crawler is a computer program that visits web pages in an organized way – Sometimes called a spider or robot • A list of web crawlers can be found at http://en.wikipedia.org/wiki/Web_crawler Google’s crawler is called googlebot, see http://support.google.com/webmasters/bin/answer.py?hl=en&answer=182072 • Yahoo’s web crawler is/was called Yahoo! Slurp, see http://en.wikipedia.org/wiki/Yahoo!_Search • Bing uses five crawlers – Bingbot, standard crawler – Adidxbot, used by Bing Ads – MSNbot, remnant from MSN, but still in use – MSNBotMedia, crawls images and video – BingPreview, generates page snapshots • For details see: http://www.bing.com/webmaster/help/which-crawlers-does-bing-use-8c184ec0 Copyright Ellis Horowitz, 2011-2020 2 Web Crawling Issues • How to crawl? – Quality: how to find the “Best” pages first – Efficiency: how to avoid duplication (or near duplication) – Etiquette: behave politely by not disturbing a website’s performance • How much to crawl? How much to index? – Coverage: What percentage of the web should be covered? – Relative Coverage: How much do competitors have? • How often to crawl? – Freshness: How much has changed? – How much has really changed? Copyright Ellis Horowitz, 2011-2020 3 Simplest Crawler Operation • Begin with known “seed” pages • Fetch and parse a page – Place the page in a database – Extract the URLs within the page – Place the extracted URLs on a queue • Fetch each URL on the queue and repeat Copyright Ellis Horowitz, 2011-2020 4 Crawling Picture -

Statistics for Sdo2.Oma.Be (2020) - Main
Statistics for sdo2.oma.be (2020) - main Statistics for: sdo2.oma.be Last Update: 01 Jan 2021 - 00:00 Reported period: Year 2020 When: Monthly history Days of month Days of week Hours Who: Countries Full list Hosts Full list Last visit Unresolved IP Address Robots/Spiders visitors Full list Last visit Navigation: Visits duration File type Downloads Full list Viewed Full list Entry Exit Operating Systems Versions Unknown Browsers Versions Unknown Referrers: Origin Referring search engines Referring sites Search Search Keyphrases Search Keywords Others: Miscellaneous HTTP Status codes Pages not found Summary Reported period Year 2020 First visit 01 Jan 2020 - 00:46 Last visit 31 Dec 2020 - 23:48 Unique visitors Number of visits Pages Hits Bandwidth <= 7,930 11,893 263,683 749,762 5568.50 GB Viewed traffic * Exact value not available in (1.49 visits/visitor) (22.17 Pages/Visit) (63.04 Hits/Visit) (490960.94 KB/Visit) 'Year' view Not viewed traffic * 412,304 571,894 1681.96 GB * Not viewed traffic includes traffic generated by robots, worms, or replies with special HTTP status codes. Monthly history Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2020 2020 2020 2020 2020 2020 2020 2020 2020 2020 2020 2020 Month Unique visitors Number of visits Pages Hits Bandwidth Jan 2020 792 1,300 119,456 168,080 1121.86 GB Feb 2020 631 807 7,068 65,546 80.94 GB Mar 2020 679 972 13,936 206,344 2781.04 GB Apr 2020 656 976 12,423 102,984 288.49 GB May 2020 643 940 14,919 20,992 346.36 GB Jun 2020 656 950 21,666 26,144 196.77 GB Jul 2020 575 943 1,800 7,315 -

A Methodical Study of Web Crawler
VandanaShrivastava Journal of Engineering Research and Applicatio www.ijera.com ISSN : 2248-9622 Vol. 8, Issue 11 (Part -I) Nov 2018, pp 01-08 RESEARCH ARTICLE OPEN ACCESS A Methodical Study of Web Crawler Vandana Shrivastava Assistant Professor, S.S. Jain Subodh P.G. (Autonomous) College Jaipur, Research Scholar, Jaipur National University, Jaipur ABSTRACT World Wide Web (or simply web) is a massive, wealthy, preferable, effortlessly available and appropriate source of information and its users are increasing very swiftly now a day. To salvage information from web, search engines are used which access web pages as per the requirement of the users. The size of the web is very wide and contains structured, semi structured and unstructured data. Most of the data present in the web is unmanaged so it is not possible to access the whole web at once in a single attempt, so search engine use web crawler. Web crawler is a vital part of the search engine. It is a program that navigates the web and downloads the references of the web pages. Search engine runs several instances of the crawlers on wide spread servers to get diversified information from them. The web crawler crawls from one page to another in the World Wide Web, fetch the webpage, load the content of the page to search engine’s database and index it. Index is a huge database of words and text that occur on different webpage. This paper presents a systematic study of the web crawler. The study of web crawler is very important because properly designed web crawlers always yield well results most of the time.