A Web Archive Profiling Framework for Efficient Memento Routing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Study of Web Crawler and Its Different Types
IOSR Journal of Computer Engineering (IOSR-JCE) e-ISSN: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 1, Ver. VI (Feb. 2014), PP 01-05 www.iosrjournals.org Study of Web Crawler and its Different Types Trupti V. Udapure1, Ravindra D. Kale2, Rajesh C. Dharmik3 1M.E. (Wireless Communication and Computing) student, CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India 2Asst Prof., CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India, 3Asso.Prof. & Head, IT Department, Yeshwantrao Chavan College of Engineering, Nagpur, India, Abstract : Due to the current size of the Web and its dynamic nature, building an efficient search mechanism is very important. A vast number of web pages are continually being added every day, and information is constantly changing. Search engines are used to extract valuable Information from the internet. Web crawlers are the principal part of search engine, is a computer program or software that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. It is an essential method for collecting data on, and keeping in touch with the rapidly increasing Internet. This Paper briefly reviews the concepts of web crawler, its architecture and its various types. Keyword: Crawling techniques, Web Crawler, Search engine, WWW I. Introduction In modern life use of internet is growing in rapid way. The World Wide Web provides a vast source of information of almost all type. Now a day’s people use search engines every now and then, large volumes of data can be explored easily through search engines, to extract valuable information from web. -

Doing Business in Canada 2019
Doing Business in Canada A disciplined, team-driven approach focused squarely on the success of your business. Lawyers in offices across Canada, the United States, Europe and China — Toronto, Calgary, Vancouver, Montréal, Ottawa, New York, London and Beijing. Among the world’s most respected corporate law firms, with expertise in virtually every area of business law. When it comes to dealmaking, Blakes Means Business. Blakes Guide to Doing Business in Canada Doing Business in Canada is intended as an introductory summary. Specific advice should be sought in connection with particular transactions. If you have any questions with respect to Doing Business in Canada, please contact our Firm Chair, Brock Gibson by email at [email protected]. Blake, Cassels & Graydon LLP produces regular reports and special publications on Canadian legal developments. For further information about these reports and publications, please contact the Blakes Client Relations & Marketing Department at [email protected]. Contents I. Introduction ............................................................................................................... 1 II. Government and Legal System ............................................................................... 2 1. Brief Canadian History ............................................................................................. 2 2. Federal Government ................................................................................................. 3 3. Provincial and Territorial Governments -

Efficient Focused Web Crawling Approach for Search Engine
Ayar Pranav et al, International Journal of Computer Science and Mobile Computing, Vol.4 Issue.5, May- 2015, pg. 545-551 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320–088X IJCSMC, Vol. 4, Issue. 5, May 2015, pg.545 – 551 RESEARCH ARTICLE Efficient Focused Web Crawling Approach for Search Engine 1 2 Ayar Pranav , Sandip Chauhan Computer & Science Engineering, Kalol Institute of Technology and Research Canter, Kalol, Gujarat, India 1 [email protected]; 2 [email protected] Abstract— a focused crawler traverses the web, selecting out relevant pages to a predefined topic and neglecting those out of concern. Collecting domain specific documents using focused crawlers has been considered one of most important strategies to find relevant information. While surfing the internet, it is difficult to deal with irrelevant pages and to predict which links lead to quality pages. However most focused crawler use local search algorithm to traverse the web space, but they could easily trapped within limited a sub graph of the web that surrounds the starting URLs also there is problem related to relevant pages that are miss when no links from the starting URLs. There is some relevant pages are miss. To address this problem we design a focused crawler where calculating the frequency of the topic keyword also calculate the synonyms and sub synonyms of the keyword. The weight table is constructed according to the user query. To check the similarity of web pages with respect to topic keywords and priority of extracted link is calculated. -

Regulation of the Internet a Technological Perspective
Regulation of the Internet A Technological Perspective "As we surge toward a new millennium, the Internet has become more than the overwhelming reality of the technology industry's current existence. It is the foundation for the Information Age, the environment in which we will all be living before long."1 Gerry Miller Gerri Sinclair David Sutherland Julie Zilber March, 1999 1 Dan Gillmor, San Jose Mercury News, December 19,1998, http://www7.mercurycenter.com/business/top/069597.htm Table of Contents PREFACE ...................................................................................................... IV INTRODUCTION............................................................................................. 1 SUMMARY OF CONCLUSIONS .................................................................... 3 PART 1 SETTING THE CONTEXT................................................................. 7 1. An Internet Primer.......................................................................................................................7 1.1 What is it?...............................................................................................................................7 1.2 Who owns it?...........................................................................................................................7 1.3 How does it work? ..................................................................................................................7 1.4 Who governs the Internet? .....................................................................................................8 -

The Role of Civil Society Organizations in the Net Neutrality Debate in Canada and the United States
THE ROLE OF CIVIL SOCIETY ORGANIZATIONS IN THE NET NEUTRALITY DEBATE IN CANADA AND THE UNITED STATES By Bruce Thomas Harpham A thesis submitted in conformity with the requirements for the degree of Master of Information Studies Graduate Department of the Faculty of Information University of Toronto © Copyright by Bruce Thomas Harpham (2009) Thesis title: The role of civil society organizations in the net neutrality debate in Canada and the United States Degree: Master of Information Studies (2009) Author: Bruce Thomas Harpham Graduate Department: Faculty of Information Institution: University of Toronto Abstract: This thesis investigates the policy frames employed by civil society organizations (CSOs) in the network neutrality debate in Canada and the United States. Network neutrality is defined as restrictions on Internet Service Providers (ISPs) to respect freedom of expression on the Internet and not seek to prevent innovative competition nor control the services or content available to users. The primary question under investigation is the policy frames of CSOs in the debate. The second question is whether CSOs have influenced policy outcomes in either legislation or regulation. The focus of the analysis is on regulatory agencies (CRTC and FCC); proposed legislation in Parliament and Congress is also analyzed as well. By examining the arguments advanced by various policy participants (government, ISPs, and CSOs), common points can be identified that may help the participants come to agreement. ii Acknowledgements Over the months of research and writing the thesis, I have greatly benefited from the comments and suggestions from my supervisors, Professors Andrew Clement and Nadia Caidi. Their contributions have allowed me to develop my argument in greater detail and have pointed out errors and other problems. -

Analysis and Evaluation of the Link and Content Based Focused Treasure-Crawler Ali Seyfi 1,2
Analysis and Evaluation of the Link and Content Based Focused Treasure-Crawler Ali Seyfi 1,2 1Department of Computer Science School of Engineering and Applied Sciences The George Washington University Washington, DC, USA. 2Centre of Software Technology and Management (SOFTAM) School of Computer Science Faculty of Information Science and Technology Universiti Kebangsaan Malaysia (UKM) Kuala Lumpur, Malaysia [email protected] Abstract— Indexing the Web is becoming a laborious task for search engines as the Web exponentially grows in size and distribution. Presently, the most effective known approach to overcome this problem is the use of focused crawlers. A focused crawler applies a proper algorithm in order to detect the pages on the Web that relate to its topic of interest. For this purpose we proposed a custom method that uses specific HTML elements of a page to predict the topical focus of all the pages that have an unvisited link within the current page. These recognized on-topic pages have to be sorted later based on their relevance to the main topic of the crawler for further actual downloads. In the Treasure-Crawler, we use a hierarchical structure called the T-Graph which is an exemplary guide to assign appropriate priority score to each unvisited link. These URLs will later be downloaded based on this priority. This paper outlines the architectural design and embodies the implementation, test results and performance evaluation of the Treasure-Crawler system. The Treasure-Crawler is evaluated in terms of information retrieval criteria such as recall and precision, both with values close to 0.5. Gaining such outcome asserts the significance of the proposed approach. -

Regulatory Framework for an Open Internet: the Canadian Approach – the Right Way Forward?
Regulatory Framework for an Open Internet: The Canadian Approach – the Right Way Forward? George N. Addy [email protected] Elisa K. Kearney [email protected] icarus – Fall 2010 Regulatory Framework for an Open Internet: The Canadian Approach – the Right Way Forward? George N. Addy [email protected] Elisa K. Kearney [email protected] Davies Ward Phillips & Vineberg LLP1 Access to the Internet depends on the physical infrastructure over which it operates. Although increasingly becoming a competitive market with the introduction of wireless and satellite technologies for broadband Internet access, in many countries or geographic areas the options available for Internet access may be limited to one or two facilities based carriers and a number of resellers of telecommunications services. For example, in Canada, as in the United States, the “residential broadband market has largely settled into regionalized competition between the incumbent telephone company and local cable provider.”2 The concept of net neutrality embodies the principle that access to the Internet be provided in a neutral manner in that Internet service providers (“ISPs”) do not block, speed up or slow down particular applications or content, and that ISPs do not use infrastructure ownership to favour affiliate offerings, content or applications. Calls for net neutrality regulation are premised on the fear that market competition is insufficient to discipline the 1 George N. Addy is the senior partner leading the Competition and Foreign Investment Review group of Davies Ward Phillips & Vineberg LLP in Toronto, Canada and is also part of the Technology group. Mr. Addy was head of the Canadian Competition Bureau (1993- 1996) and its merger review branch (1989-1993). -

Effective Focused Crawling Based on Content and Link Structure Analysis
(IJCSIS) International Journal of Computer Science and Information Security, Vol. 2, No. 1, June 2009 Effective Focused Crawling Based on Content and Link Structure Analysis Anshika Pal, Deepak Singh Tomar, S.C. Shrivastava Department of Computer Science & Engineering Maulana Azad National Institute of Technology Bhopal, India Emails: [email protected] , [email protected] , [email protected] Abstract — A focused crawler traverses the web selecting out dependent ontology, which in turn strengthens the metric used relevant pages to a predefined topic and neglecting those out of for prioritizing the URL queue. The Link-Structure-Based concern. While surfing the internet it is difficult to deal with method is analyzing the reference-information among the pages irrelevant pages and to predict which links lead to quality pages. to evaluate the page value. This kind of famous algorithms like In this paper, a technique of effective focused crawling is the Page Rank algorithm [5] and the HITS algorithm [6]. There implemented to improve the quality of web navigation. To check are some other experiments which measure the similarity of the similarity of web pages w.r.t. topic keywords, a similarity page contents with a specific subject using special metrics and function is used and the priorities of extracted out links are also reorder the downloaded URLs for the next crawl [7]. calculated based on meta data and resultant pages generated from focused crawler. The proposed work also uses a method for A major problem faced by the above focused crawlers is traversing the irrelevant pages that met during crawling to that it is frequently difficult to learn that some sets of off-topic improve the coverage of a specific topic. -
Report for Portal Specific
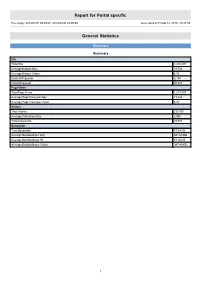
Report for Portal specific Time range: 2013/01/01 00:00:07 - 2013/03/31 23:59:59 Generated on Fri Apr 12, 2013 - 18:27:59 General Statistics Summary Summary Hits Total Hits 1,416,097 Average Hits per Day 15,734 Average Hits per Visitor 6.05 Cached Requests 8,154 Failed Requests 70,823 Page Views Total Page Views 1,217,537 Average Page Views per Day 13,528 Average Page Views per Visitor 5.21 Visitors Total Visitors 233,895 Average Visitors per Day 2,598 Total Unique IPs 49,753 Bandwidth Total Bandwidth 77.49 GB Average Bandwidth per Day 881.68 MB Average Bandwidth per Hit 57.38 KB Average Bandwidth per Visitor 347.40 KB 1 Activity Statistics Daily Daily Visitors 4,000 3,500 3,000 2,500 2,000 Visitors 1,500 1,000 500 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Hits 40,000 35,000 30,000 25,000 Hits 20,000 15,000 10,000 5,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date 2 Daily Bandwidth 1,300,000 1,200,000 1,100,000 1,000,000 900,000 800,000 700,000 600,000 500,000 Bandwidth (KB) 400,000 300,000 200,000 100,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Activity Date Hits Page Views Visitors Average Visit Length Bandwidth (KB) Sun 2013/02/10 11,783 10,245 2,280 13:01 648,207 Mon 2013/02/11 16,454 14,146 2,484 10:05 906,702 Tue 2013/02/12 19,572 17,089 3,062 07:47 926,190 Wed 2013/02/13 14,554 12,402 2,824 06:09 958,951 Thu 2013/02/14 12,577 10,666 2,690 05:03 821,129 Fri 2013/02/15 15,806 12,697 2,868 07:02 1,208,095 Sat 2013/02/16 16,811 14,939 -

Broadband Study
Appendix A TORONTO BROADBAND STUDY Prepared for the City of Toronto by: FONTUR International Inc. MDB Insight Inc. October 2017 [FINAL v4] Table of Contents GLOSSARY .............................................................................................................................................................. 4 EXECUTIVE SUMMARY ........................................................................................................................................... 6 1 WHAT IS BROADBAND, AND WHY IS IT IMPORTANT? ................................................................................... 8 DEFINING BROADBAND ................................................................................................................................................... 8 INVESTMENT IN BROADBAND ACCESSIBILITY & AFFORDABILITY AS A KEY ELEMENT TO SMART CITY DEVELOPMENT & JOB CREATION .... 9 RESPONDING TO THE PRESSURES OF THE DIGITAL ECONOMY ................................................................................................ 12 2 BROADBAND TRENDS .................................................................................................................................. 14 BROADBAND OVER LTE (WIRELESS)................................................................................................................................. 14 5TH GENERATION CARRIER WIRELESS (5G) ........................................................................................................................ 15 INTERNET OF THINGS (IOT) ........................................................................................................................................... -

The Google Search Engine
University of Business and Technology in Kosovo UBT Knowledge Center Theses and Dissertations Student Work Summer 6-2010 The Google search engine Ganimete Perçuku Follow this and additional works at: https://knowledgecenter.ubt-uni.net/etd Part of the Computer Sciences Commons Faculty of Computer Sciences and Engineering The Google search engine (Bachelor Degree) Ganimete Perçuku – Hasani June, 2010 Prishtinë Faculty of Computer Sciences and Engineering Bachelor Degree Academic Year 2008 – 2009 Student: Ganimete Perçuku – Hasani The Google search engine Supervisor: Dr. Bekim Gashi 09/06/2010 This thesis is submitted in partial fulfillment of the requirements for a Bachelor Degree Abstrakt Përgjithësisht makina kërkuese Google paraqitet si sistemi i kompjuterëve të projektuar për kërkimin e informatave në ueb. Google mundohet t’i kuptojë kërkesat e njerëzve në mënyrë “njerëzore”, dhe t’iu kthej atyre përgjigjen në formën të qartë. Por, ky synim nuk është as afër ideales dhe realizimi i tij sa vjen e vështirësohet me zgjerimin eksponencial që sot po përjeton ueb-i. Google, paraqitet duke ngërthyer në vetvete shqyrtimin e pjesëve që e përbëjnë, atyre në të cilat sistemi mbështetet, dhe rrethinave tjera që i mundësojnë sistemit të funksionojë pa probleme apo të përtërihet lehtë nga ndonjë dështim eventual. Procesi i grumbullimit të të dhënave ne Google dhe paraqitja e tyre në rezultatet e kërkimit ngërthen në vete regjistrimin e të dhënave nga ueb-faqe të ndryshme dhe vendosjen e tyre në rezervuarin e sistemit, përkatësisht në bazën e të dhënave ku edhe realizohen pyetësorët që kthejnë rezultatet e radhitura në mënyrën e caktuar nga algoritmi i Google. -

Scalability and Efficiency Challenges in Large-Scale Web Search
5/1/14 Scalability and Efficiency Challenges in Large-Scale Web Search Engines " Ricardo Baeza-Yates" B. Barla Cambazoglu! Yahoo Labs" Barcelona, Spain" Disclaimer Dis •# This talk presents the opinions of the authors. It does not necessarily reflect the views of Yahoo Inc. or any other entity." •# Algorithms, techniques, features, etc. mentioned here might or might not be in use by Yahoo or any other company." •# Some non-technical material (e.g., images) provided in this presentation were taken from the Web." 1 5/1/14 Yahoo Labs Barcelona •# Research topics" •# Web retrieval" –# web data mining" –# distributed web retrieval" –# semantic search" –# scalability and efficiency" –# social media" –# opinion/sentiment retrieval" –# web retrieval" –# personalization" Outline of the Tutorial •# Background (35 minutes)" •# Main sections" –# web crawling (75 minutes + 5 minutes Q/A)" –# indexing (75 minutes + 5 minutes Q/A)" –# query processing (90 minutes + 5 minutes Q/A)" –# caching (40 minutes + 5 minutes Q/A)" •# Concluding remarks (10 minutes)" •# Questions and open discussion (15 minutes)" 2 5/1/14 Structure of Main Sections •# Definitions" •# Metrics" •# Issues and techniques" –# single computer" –# cluster of computers" –# multiple search sites" •# Research problems" Background 3 5/1/14 Brief History of Search Engines •# Past" -# Before browsers" -# Gopher" -# Before the bubble" -# Altavista" -# Lycos" -# Infoseek" -# Excite" -# HotBot" •# Current" •# Future" -# After the bubble" •# Global" •# Facebook ?" -# Yahoo" •# Google, Bing" •# …"