Study of Web Crawler and Its Different Types
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Distributed Web Crawling Using Network Coordinates
Distributed Web Crawling Using Network Coordinates Barnaby Malet Department of Computing Imperial College London [email protected] Supervisor: Peter Pietzuch Second Marker: Emil Lupu June 16, 2009 2 Abstract In this report we will outline the relevant background research, the design, the implementation and the evaluation of a distributed web crawler. Our system is innovative in that it assigns Euclidean coordinates to crawlers and web servers such that the distances in the space give an accurate prediction of download times. We will demonstrate that our method gives the crawler the ability to adapt and compensate for changes in the underlying network topology, and in doing so can achieve significant decreases in download times when compared with other approaches. 3 4 Acknowledgements Firstly, I would like to thank Peter Pietzuch for the help that he has given me throughout the course of the project as well as showing me support when things did not go to plan. Secondly, I would like to thank Johnathan Ledlie for helping me with some aspects of the implemen- tation involving the Pyxida library. I would also like to thank the PlanetLab support team for giving me extensive help in dealing with complaints from web masters. Finally, I would like to thank Emil Lupu for providing me with feedback about my Outsourcing Report. 5 6 Contents 1 Introduction 9 2 Background 13 2.1 Web Crawling . 13 2.1.1 Web Crawler Architecture . 14 2.1.2 Issues in Web Crawling . 16 2.1.3 Discussion . 17 2.2 Crawler Assignment Strategies . 17 2.2.1 Hash Based . -

Panacea D4.1
SEVENTH FRAMEWORK PROGRAMME THEME 3 Information and communication Technologies PANACEA Project Grant Agreement no.: 248064 Platform for Automatic, Normalized Annotation and Cost-Effective Acquisition of Language Resources for Human Language Technologies D4.1 Technologies and tools for corpus creation, normalization and annotation Dissemination Level: Public Delivery Date: July 16, 2010 Status – Version: Final Author(s) and Affiliation: Prokopis Prokopidis, Vassilis Papavassiliou (ILSP), Pavel Pecina (DCU), Laura Rimel, Thierry Poibeau (UCAM), Roberto Bartolini, Tommaso Caselli, Francesca Frontini (ILC- CNR), Vera Aleksic, Gregor Thurmair (Linguatec), Marc Poch Riera, Núria Bel (UPF), Olivier Hamon (ELDA) Technologies and tools for corpus creation, normalization and annotation Table of contents 1 Introduction ........................................................................................................................... 3 2 Terminology .......................................................................................................................... 3 3 Corpus Acquisition Component ............................................................................................ 3 3.1 Task description ........................................................................................................... 4 3.2 State of the art .............................................................................................................. 4 3.3 Existing tools .............................................................................................................. -
Report for Portal Specific
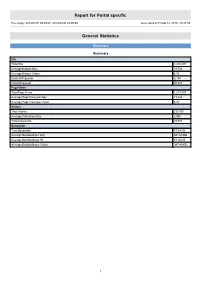
Report for Portal specific Time range: 2013/01/01 00:00:07 - 2013/03/31 23:59:59 Generated on Fri Apr 12, 2013 - 18:27:59 General Statistics Summary Summary Hits Total Hits 1,416,097 Average Hits per Day 15,734 Average Hits per Visitor 6.05 Cached Requests 8,154 Failed Requests 70,823 Page Views Total Page Views 1,217,537 Average Page Views per Day 13,528 Average Page Views per Visitor 5.21 Visitors Total Visitors 233,895 Average Visitors per Day 2,598 Total Unique IPs 49,753 Bandwidth Total Bandwidth 77.49 GB Average Bandwidth per Day 881.68 MB Average Bandwidth per Hit 57.38 KB Average Bandwidth per Visitor 347.40 KB 1 Activity Statistics Daily Daily Visitors 4,000 3,500 3,000 2,500 2,000 Visitors 1,500 1,000 500 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Hits 40,000 35,000 30,000 25,000 Hits 20,000 15,000 10,000 5,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date 2 Daily Bandwidth 1,300,000 1,200,000 1,100,000 1,000,000 900,000 800,000 700,000 600,000 500,000 Bandwidth (KB) 400,000 300,000 200,000 100,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Activity Date Hits Page Views Visitors Average Visit Length Bandwidth (KB) Sun 2013/02/10 11,783 10,245 2,280 13:01 648,207 Mon 2013/02/11 16,454 14,146 2,484 10:05 906,702 Tue 2013/02/12 19,572 17,089 3,062 07:47 926,190 Wed 2013/02/13 14,554 12,402 2,824 06:09 958,951 Thu 2013/02/14 12,577 10,666 2,690 05:03 821,129 Fri 2013/02/15 15,806 12,697 2,868 07:02 1,208,095 Sat 2013/02/16 16,811 14,939 -

Scalability and Efficiency Challenges in Large-Scale Web Search
5/1/14 Scalability and Efficiency Challenges in Large-Scale Web Search Engines " Ricardo Baeza-Yates" B. Barla Cambazoglu! Yahoo Labs" Barcelona, Spain" Disclaimer Dis •# This talk presents the opinions of the authors. It does not necessarily reflect the views of Yahoo Inc. or any other entity." •# Algorithms, techniques, features, etc. mentioned here might or might not be in use by Yahoo or any other company." •# Some non-technical material (e.g., images) provided in this presentation were taken from the Web." 1 5/1/14 Yahoo Labs Barcelona •# Research topics" •# Web retrieval" –# web data mining" –# distributed web retrieval" –# semantic search" –# scalability and efficiency" –# social media" –# opinion/sentiment retrieval" –# web retrieval" –# personalization" Outline of the Tutorial •# Background (35 minutes)" •# Main sections" –# web crawling (75 minutes + 5 minutes Q/A)" –# indexing (75 minutes + 5 minutes Q/A)" –# query processing (90 minutes + 5 minutes Q/A)" –# caching (40 minutes + 5 minutes Q/A)" •# Concluding remarks (10 minutes)" •# Questions and open discussion (15 minutes)" 2 5/1/14 Structure of Main Sections •# Definitions" •# Metrics" •# Issues and techniques" –# single computer" –# cluster of computers" –# multiple search sites" •# Research problems" Background 3 5/1/14 Brief History of Search Engines •# Past" -# Before browsers" -# Gopher" -# Before the bubble" -# Altavista" -# Lycos" -# Infoseek" -# Excite" -# HotBot" •# Current" •# Future" -# After the bubble" •# Global" •# Facebook ?" -# Yahoo" •# Google, Bing" •# …" -

Towards a Distributed Web Search Engine
Towards a Distributed Web Search Engine Ricardo Baeza-Yates Yahoo! Research Barcelona, Spain Joint work with Barla Cambazoglu, Aristides Gionis, Flavio Junqueira, Mauricio Marín, Vanessa Murdock (Yahoo! Research) and many other people Web Search Web Context 4 Web Search • This is one of the most complex data engineering challenges today: – Distributed in nature – Large volume of data – Highly concurrent service – Users expect very good & fast answers • Current solution: Replicated centralized system 5 WR Logical Architecture Web Crawlers 6 A Typical Web Search Engine • Caching – result cache – posting list cache – document cache • Replication – multiple clusters – improve throughput • Parallel query processing – partitioned index • document-based • term-based – Online query processing Search Engine Architectures • Architectures differ in – number of data centers – assignment of users to data centers – assignment of index to data centers System Size • 20 billion Web pages implies at least 100Tb of text • The index in RAM implies at least a cluster of 10,000 PCs • Assume we can answer 1,000 queries/sec • 350 million queries a day imply 4,000 queries/sec • Decide that the peak load plus a fault tolerance margin is 3 • This implies a replication factor of 12 giving 120,000 PCs • Total deployment cost of over 100 million US$ plus maintenance cost • In 201x, being conservative, we would need over 1 million computers! 10 Questions • Should we use a centralized system? • Can we have a (cheaper) distributed search system in spite of network latency? -

Distributed Web Crawlers Using Hadoop
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 12, Number 24 (2017) pp. 15187-15195 © Research India Publications. http://www.ripublication.com Distributed Web Crawlers using Hadoop Pratiba D Assistant Professor, Department of Computer Science and Engineering, R V College of Engineering, R V Vidyanikethan Post, Mysuru Road Bengaluru, Karnataka, India. Orcid Id: 0000-0001-9123-8687 Shobha G Professor, Department of Computer Science and Engineering, R V College of Engineering, R V Vidyanikethan Post, Mysuru Road Bengaluru, Karnataka, India. LalithKumar H Student, Department of Computer Science and Engineering, R V College of Engineering, R V Vidyanikethan Post, Mysuru Road Bengaluru, Karnataka, India. Samrudh J Student, Department of Information Science and Engineering, R V College of Engineering, R V Vidyanikethan Post, Mysuru Road Bengaluru, Karnataka, India. Abstract With the increasing size of web content, it is very difficult to index the entire WWW. So, efforts must be put to limit the Web Crawler is a software, which crawls through the WWW amount of data indexed and at the same time maximize the to build database for a search engine. In recent years, web coverage. To minimize the amount of data indexed, Natural crawling has started facing many challenges. Firstly, the web Language Processing techniques need to be applied to filter pages are highly unstructured which makes it difficult to and summarize the web page and store only the essential maintain a generic schema for storage. Secondly, the WWW details. By doing so, a search can yield the most accurate and is too huge and it is impossible to index it as it is. -

Design and Implementation of Distributed Web Crawler for Drug Website Search Using Hefty Based Enhanced Bandwidth Algorithms
Turkish Journal of Computer and Mathematics Education Vol.12 No.9 (2021), 123-129 Research Article Design and Implementation of Distributed Web Crawler for Drug Website Search using Hefty based Enhanced Bandwidth Algorithms a b c Saran Raj S , Aarif Ahamed S , and R. Rajmohan a,b Vel Tech Rangarajan Dr Sagunthala R & D Institute of Science and Technology cIFET College of Engineering, Villupuram, Tamil Nadu, India Article History: Received: 10 January 2021; Revised: 12 February 2021; Accepted: 27 March 2021; Published online: 20 April 2021 Abstract: The development of an expert system based search tool needs a superficial structure to satisfy the requirements of current web scale. Search engines and the internet crawler are used to mine the required information from the web and surf the internet in an efficient fashion. Distributed crawler is one of the types of a web crawler, which is a dispersed computation method. In this paper, we design and implement the concept of Efficient Distributed Web Crawler using enhanced bandwidth and hefty algorithms. Mostly Web Crawler doesn’t have any distributed cluster performance system and any implemented algorithm. In this paper, a novel Hefty Algorithm and enhanced bandwidth algorithm are combined for a better-distributed crawling system. The hefty algorithm is implemented to provide strong and efficient surfing results while applying on the drug web search. We also concentrate on the efficiency of the proposed distributed web crawler by implementing Enhanced Bandwidth algorithm. Keywords: Distributed crawler, Page surfs, Bandwidth ___________________________________________________________________________ 1. Introduction Internet Page swarmer is a meta- hunt engine, which combines the top search results from the represented search engines. -

A Practical Geographically Distributed Web Crawler
UniCrawl: A Practical Geographically Distributed Web Crawler Do Le Quoc, Christof Fetzer Pierre Sutra, Valerio Schiavoni, Systems Engineering Group Etienne´ Riviere,` Pascal Felber Dresden University of Technology, Germany University of Neuchatel,ˆ Switzerland Abstract—As the wealth of information available on the web can be repeated until a given depth, and pages are periodically keeps growing, being able to harvest massive amounts of data has re-fetched to discover new pages and to detect updated content. become a major challenge. Web crawlers are the core components to retrieve such vast collections of publicly available data. The Due to the size of the web, it is mandatory to make the key limiting factor of any crawler architecture is however its crawling process parallel [23] on a large number of machines large infrastructure cost. To reduce this cost, and in particular to achieve a reasonable collection time. This requirement the high upfront investments, we present in this paper a geo- implies provisioning large computing infrastructures. Existing distributed crawler solution, UniCrawl. UniCrawl orchestrates commercial crawlers, such as Google or Bing rely on big data several geographically distributed sites. Each site operates an centers. However, this approach imposes heavy requirements, independent crawler and relies on well-established techniques notably on the cost of the network infrastructure. Furthermore, for fetching and parsing the content of the web. UniCrawl splits the high upfront investment necessary to set up appropriate the crawled domain space across the sites and federates their storage and computing resources, while minimizing thee inter-site data centers can only be made by few large Internet companies, communication cost. -

A Focused Web Crawler Driven by Self-Optimizing Classifiers
A Focused Web Crawler Driven by Self-Optimizing Classifiers Master’s Thesis Dominik Sobania Original title: A Focused Web Crawler Driven by Self-Optimizing Classifiers German title: Fokussiertes Webcrawling mit selbstorganisierenden Klassifizierern Master’s Thesis Submitted by Dominik Sobania Submission date: 09/25/2015 Supervisor: Prof. Dr. Chris Biemann Coordinator: Steffen Remus TU Darmstadt Department of Computer Science, Language Technology Group Erklärung Hiermit versichere ich, die vorliegende Master’s Thesis ohne Hilfe Dritter und nur mit den angegebe- nen Quellen und Hilfsmitteln angefertigt zu haben. Alle Stellen, die aus den Quellen entnommen wur- den, sind als solche kenntlich gemacht worden. Diese Arbeit hat in dieser oder ähnlicher Form noch keiner Prüfungsbehörde vorgelegen. Die schriftliche Fassung stimmt mit der elektronischen Fassung überein. Darmstadt, den 25. September 2015 Dominik Sobania i Zusammenfassung Üblicherweise laden Web-Crawler alle Dokumente herunter, die von einer begrenzten Menge Seed- URLs aus erreichbar sind. Für die Generierung von Corpora ist eine Breitensuche allerdings nicht effizient, da uns hier nur ein bestimmtes Thema interessiert. Ein fokussierter Crawler besucht verlinkte Dokumente, die von einer Entscheidungsfunktion ausgewählt wurden, mit höherer Priorität. Dieser Ansatz fokussiert sich selbst auf das gesuchte Thema. In dieser Masterarbeit beschreiben wir einen Ansatz für fokussiertes Crawling, der als erster Schritt für die Generierung von Corpora genutzt werden kann. Basierend auf einem kleinen Satz an Textdoku- menten, die das gesuchte Thema definieren, erstellt eine Pipeline, bestehend aus mehreren Klassifizier- ern, die Trainingsdaten für einen Hyperlink-Klassifizierer – die Entscheidungsfunktion des fokussierten Crawlers. Für die Optimierung der Klassifizierer benutzen wir einen evolutionären Algorithmus für die Feature Subset Selection. Die Chromosomen des evolutionären Algorithmus basieren auf einer serial- isierbaren Baumstruktur. -

UCYMICRA: Distributed Indexing of the Web Using Migrating Crawlers
UCYMICRA: Distributed Indexing of the Web Using Migrating Crawlers Odysseas Papapetrou, Stavros Papastavrou, George Samaras Computer Science Department, University of Cyprus, 75 Kallipoleos Str., P.O.Box 20537 {cs98po1, stavrosp, cssamara}@cs.ucy.ac.cy Abstract. Due to the tremendous increase rate and the high change frequency of Web documents, maintaining an up-to-date index for searching purposes (search engines) is becoming a challenge. The traditional crawling methods are no longer able to catch up with the constantly updating and growing Web. Real- izing the problem, in this paper we suggest an alternative distributed crawling method with the use of mobile agents. Our goal is a scalable crawling scheme that minimizes network utilization, keeps up with document changes, employs time realization, and is easily upgradeable. 1 Introduction Indexing the Web has become a challenge due to the Web’s growing and dynamic na- ture. A study released in late 2000 reveals that the static and publicly available Web (also mentioned as surface web) exceeds 2.5 billion documents while the deep Web (dynamically generated documents, intranet pages, web-connected databases etc) is almost three orders of magnitude larger [20]. Another study shows that the Web is growing and changing rapidly [17, 19], while no search engine succeeds coverage of more than 16% of the estimated Web size [19]. Web crawling (or traditional crawling) has been the dominant practice for Web in- dexing by popular search engines and research organizations since 1993, but despite the vast computational and network resources thrown into it, traditional crawling is no longer able to catch up with the dynamic Web. -

DATA20021 Information Retrieval Lecture 5: Web Crawling Simon J
DATA20021 University of Helsinki, Department of Computer Science Information Retrieval Lecture 5: Web Crawling Simon J. Puglisi [email protected] Spring 2020 Today’s lecture… 16.1: Introduction to Indexing - Boolean Retrieval model - Inverted Indexes 21.1: Index Compression - unary, gamma, variable-byte coding - (Partitioned) Elias-Fano coding (used by Google, facebook) 23.1: Index Construction - preprocessing documents prior to search - building the index efficiently 28.1: Web Crawling - getting documents off the web at scale - architecture of a large scale web search engine 30.1: Query Processing - scoring and ranking search results - Vector-Space model • Web search engines create web repositories – They cache the Web on their local machines • Web repositories provide fast access to copies of the pages on the Web, allowing faster indexing and better search quality • A search engine aims to minimize the potential differences between it’s local repo and the Web – Coverage and freshness allow better quality answers – Very challenging due to fast and continuous evolution of the web: huge changes in pages and content every second • The Web repository maintains only the most recently crawled versions of web pages – Raw HTML, but compressed, on a filesystem (not a DBMS) – Also a catalog containing location on disk, size, timestamp • Mechanisms for both bulk and random access to stored pages are provided – Bulk access is used, e.g., by the indexing system – Random access for, e.g., query-biased snippet generation <Some slides on query -

Analysis, Modeling, and Algorithms for Scalable Web Crawling
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Texas A&M Repository ANALYSIS, MODELING, AND ALGORITHMS FOR SCALABLE WEB CRAWLING A Dissertation by SARKER TANZIR AHMED Submitted to the Office of Graduate and Professional Studies of Texas A&M University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY Chair of Committee, Dmitri Loguinov Committee Members, Riccardo Bettati James Caverlee A. L. Narasimha Reddy Head of Department, Dilma Da Silva August 2016 Major Subject: Computer Science Copyright 2016 Sarker Tanzir Ahmed ABSTRACT This dissertation presents a modeling framework for the intermediate data gener- ated by external-memory sorting algorithms (e.g., merge sort, bucket sort, hash sort, replacement selection) that are well-known, yet without accurate models of produced data volume. The motivation comes from the IRLbot crawl experience in June 2007, where a collection of scalable and high-performance external sorting methods are used to handle such problems as URL uniqueness checking, real-time frontier rank- ing, budget allocation, spam avoidance, all being monumental tasks, especially when limited to the resources of a single-machine. We discuss this crawl experience in detail, use novel algorithms to collect data from the crawl image, and then advance to a broader problem – sorting arbitrarily large-scale data using limited resources and accurately capturing the required cost (e.g., time and disk usage). To solve these problems, we present an accurate model of uniqueness probabil- ity the probability to encounter previous unseen data and use that to analyze the amount of intermediate data generated the above-mentioned sorting methods.