Digital Marketing Handbook
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Google Matrix Analysis of Bi-Functional SIGNOR Network of Protein-Protein Interactions Klaus M
bioRxiv preprint doi: https://doi.org/10.1101/750695; this version posted September 1, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Bioinformatics doi.10.1093/bioinformatics/xxxxxx Manuscript Category Systems biology Google matrix analysis of bi-functional SIGNOR network of protein-protein interactions Klaus M. Frahm 1 and Dima L. Shepelyansky 1,∗ 1Laboratoire de Physique Théorique, IRSAMC, Université de Toulouse, CNRS, UPS, 31062 Toulouse, France. ∗To whom correspondence should be addressed. Associate Editor: XXXXXXX Received on August 28, 2019; revised on XXXXX; accepted on XXXXX Abstract Motivation: Directed protein networks with only a few thousand of nodes are rather complex and do not allow to extract easily the effective influence of one protein to another taking into account all indirect pathways via the global network. Furthermore, the different types of activation and inhibition actions between proteins provide a considerable challenge in the frame work of network analysis. At the same time these protein interactions are of crucial importance and at the heart of cellular functioning. Results: We develop the Google matrix analysis of the protein-protein network from the open public database SIGNOR. The developed approach takes into account the bi-functional activation or inhibition nature of interactions between each pair of proteins describing it in the frame work of Ising-spin matrix transitions. We also apply a recently developed linear response theory for the Google matrix which highlights a pathway of proteins whose PageRank probabilities are most sensitive with respect to two proteins selected for the analysis. -

Requirements, Design and Applications to Semantic Integration and Knowledge Discovery
Practical Ontologies: Requirements, Design and Applications to Semantic Integration and Knowledge Discovery by Daniela Rosu A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Graduate Department of Computer Science University of Toronto © Copyright by Daniela Rosu 2013 Practical Ontologies: Requirements, Design and Applications to Semantic Integration and Knowledge Discovery Daniela Rosu Doctor of Philosophy Graduate Department of Computer Science University of Toronto 2013 Abstract Due to their role in describing the semantics of information, knowledge representations, from formal ontologies to informal representations such as folksonomies, are becoming increasingly important in facilitating the exchange of information, as well as the semantic integration of information systems and knowledge discovery in a large number of areas, from e-commerce to bioinformatics. In this thesis we present several studies related to the development and application of knowledge representations, in the form of practical ontologies. In Chapter 2, we examine representational challenges and requirements for describing practical domain knowledge. We present representational requirements we collected by surveying current and potential ontology users, discuss current approaches to codifying knowledge and give formal representation solutions to some of the issues we identified. In Chapter 3 we introduce a practical ontology for representing data exchanges, discuss its relationship with existing standards and its role in facilitating the interoperability between information producing and consuming services. ii We also consider the problem of assessing similarity between ontological concepts and propose three novel measures of similarity, detailed in Chapter 4. Two of our proposals estimate semantic similarity between concepts in the same ontology, while the third measures similarity between concepts belonging to different ontologies. -

Study of Web Crawler and Its Different Types
IOSR Journal of Computer Engineering (IOSR-JCE) e-ISSN: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 1, Ver. VI (Feb. 2014), PP 01-05 www.iosrjournals.org Study of Web Crawler and its Different Types Trupti V. Udapure1, Ravindra D. Kale2, Rajesh C. Dharmik3 1M.E. (Wireless Communication and Computing) student, CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India 2Asst Prof., CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India, 3Asso.Prof. & Head, IT Department, Yeshwantrao Chavan College of Engineering, Nagpur, India, Abstract : Due to the current size of the Web and its dynamic nature, building an efficient search mechanism is very important. A vast number of web pages are continually being added every day, and information is constantly changing. Search engines are used to extract valuable Information from the internet. Web crawlers are the principal part of search engine, is a computer program or software that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. It is an essential method for collecting data on, and keeping in touch with the rapidly increasing Internet. This Paper briefly reviews the concepts of web crawler, its architecture and its various types. Keyword: Crawling techniques, Web Crawler, Search engine, WWW I. Introduction In modern life use of internet is growing in rapid way. The World Wide Web provides a vast source of information of almost all type. Now a day’s people use search engines every now and then, large volumes of data can be explored easily through search engines, to extract valuable information from web. -

Easy Slackware
1 Создание легкой системы на базе Slackware I - Введение Slackware пользуется заслуженной популярностью как классический linux дистрибутив, и поговорка "кто знает Red Hat тот знает только Red Hat, кто знает Slackware тот знает linux" несмотря на явный снобизм поклонников "бога Патре га" все же имеет под собой основания. Одним из преимуществ Slackware является возможность простого создания на ее основе практически любой системы, в том числе быстрой и легкой десктопной, о чем далее и пойдет речь. Есть дис трибутивы, клоны Slackware, созданные именно с этой целью, типа Аbsolute, но все же лучше создавать систему под себя, с максимальным учетом именно своих потребностей, и Slackware пожалуй как никакой другой дистрибутив подходит именно для этой цели. Легкость и быстрота системы определяется выбором WM (DM) , набором программ и оптимизацией программ и системы в целом. Первое исключает KDE, Gnome, даже новые версии XFCЕ, остается разве что LXDE, но набор программ в нем совершенно не устраивает. Оптимизация наиболее часто используемых про грамм и нескольких базовых системных пакетов осуществляется их сборкой из сорцов компилятором, оптимизированным именно под Ваш комп, причем каж дая программа конфигурируется исходя из Ваших потребностей к ее возможно стям. Оптимизация системы в целом осуществляется ее настройкой согласно спе цифическим требованиям к десктопу. Такой подход был выбран по банальной причине, возиться с gentoo нет ни какого желания, комп все таки создан для того чтобы им пользоваться, а не для компиляции программ, в тоже время у каждого есть минимальный набор из не большого количества наиболее часто используемых программ, на которые стоит потратить некоторое, не такое уж большое, время, чтобы довести их до ума. Кро ме того, такой подход позволяет иметь самые свежие версии наиболее часто ис пользуемых программ. -

Further Reading and What's Next
APPENDIX Further Reading and What’s Next I hope you have gotten an idea of how, as a penetration tester, you could test a web application and find its security flaws by hunting bugs. In this concluding chapter, we will see how we can extend our knowledge of what we have learned so far. In the previous chapter, we saw how SQL injection has been done; however, we have not seen the automated part of SQL injection, which can be done by other tools alongside Burp Suite. We will use sqlmap, a very useful tool, for this purpose. Tools that Can Be Used Alongside Burp Suite We have seen earlier that the best alternative to Burp Suite is OWASP ZAP. Where Burp Community edition has some limitations, ZAP can help you overcome them. Moreover, ZAP is an open source free tool; it is community-based, so you don’t have to pay for it for using any kind of advanced technique. We have also seen how ZAP works. Here, we will therefore concentrate on sqlmap only, another very useful tool we need for bug hunting. The sqlmap is command line based. It comes with Kali Linux by default. You can just open your terminal and start scanning by using sqlmap. However, as always, be careful about using it against any live © Sanjib Sinha 2019 197 S. Sinha, Bug Bounty Hunting for Web Security, https://doi.org/10.1007/978-1-4842-5391-5 APPENDIX FuRtHeR Reading and What’s Next system; don’t use it without permission. If your client’s web application has vulnerabilities, you can use sqlmap to detect the database, table names, columns, and even read the contents inside. -

Mathematical Properties and Analysis of Google's Pagerank
o Bol. Soc. Esp. Mat. Apl. n 0 (0000), 1–6 Mathematical Properties and Analysis of Google’s PageRank Ilse C.F. Ipsen, Rebecca S. Wills Department of Mathematics, North Carolina State University, Raleigh, NC 27695-8205, USA [email protected], [email protected] Abstract To determine the order in which to display web pages, the search engine Google computes the PageRank vector, whose entries are the PageRanks of the web pages. The PageRank vector is the stationary distribution of a stochastic matrix, the Google matrix. The Google matrix in turn is a convex combination of two stochastic matrices: one matrix represents the link structure of the web graph and a second, rank-one matrix, mimics the random behaviour of web surfers and can also be used to combat web spamming. As a consequence, PageRank depends mainly the link structure of the web graph, but not on the contents of the web pages. We analyze the sensitivity of PageRank to changes in the Google matrix, including addition and deletion of links in the web graph. Due to the proliferation of web pages, the dimension of the Google matrix most likely exceeds ten billion. One of the simplest and most storage-efficient methods for computing PageRank is the power method. We present error bounds for the iterates of the power method and for their residuals. Palabras clave : Markov matrix, stochastic matrix, stationary distribution, power method, perturbation bounds Clasificaci´on por materias AMS : 15A51,65C40,65F15,65F50,65F10 1. Introduction How does the search engine Google determine the order in which to display web pages? The major ingredient in determining this order is the PageRank vector, which assigns a score to a every web page. -

The Future Computed Artificial Intelligence and Its Role in Society
The Future Computed Artificial Intelligence and its role in society By Microsoft With a foreword by Brad Smith and Harry Shum Published by Microsoft Corporation Redmond, Washington. U.S.A. 2018 First published 2018 by Microsoft Corporation One Microsoft Way Redmond, Washington 98052 © 2018 Microsoft. All rights reserved ISBN 978-0-9997508-1-0 Table of contents Foreword The Future Computed 1 Chapter 1 The Future of Artificial Intelligence 22 Microsoft’s Approach to AI 33 The Potential of Modern AI - 43 Addressing Societal Challenges The Challenges AI Presents 48 Chapter 2 Principles, Policies and Laws for the 50 Responsible Use of AI Ethical and Societal Implications 56 Developing Policy and Law for 73 Artificial Intelligence Fostering Dialogue and the Sharing of 82 Best Practices iii Chapter 3 AI and the Future of Jobs and Work 84 The Impact of Technology on Jobs and Work 91 The Changing Nature of Work, the Workplace 101 and Jobs Preparing Everyone for the Future of Work 107 Changing Norms of Changing Worker Needs 122 Working Together 133 Conclusion AI Amplifying Human Ingenuity 134 Endnotes 138 iv Foreword The Future Computed By Brad Smith and Harry Shum 6 Twenty years ago, we both worked at Microsoft, but on The Future Computed opposite sides of the globe. In 1998, one of us was living and working in China as a founding member of the Microsoft Research Asia lab in Beijing. Five thousand miles away, the other was based at the company’s headquarters, just outside of Seattle, leading the international legal and corporate affairs team. -

EN-Google Hacks.Pdf
Table of Contents Credits Foreword Preface Chapter 1. Searching Google 1. Setting Preferences 2. Language Tools 3. Anatomy of a Search Result 4. Specialized Vocabularies: Slang and Terminology 5. Getting Around the 10 Word Limit 6. Word Order Matters 7. Repetition Matters 8. Mixing Syntaxes 9. Hacking Google URLs 10. Hacking Google Search Forms 11. Date-Range Searching 12. Understanding and Using Julian Dates 13. Using Full-Word Wildcards 14. inurl: Versus site: 15. Checking Spelling 16. Consulting the Dictionary 17. Consulting the Phonebook 18. Tracking Stocks 19. Google Interface for Translators 20. Searching Article Archives 21. Finding Directories of Information 22. Finding Technical Definitions 23. Finding Weblog Commentary 24. The Google Toolbar 25. The Mozilla Google Toolbar 26. The Quick Search Toolbar 27. GAPIS 28. Googling with Bookmarklets Chapter 2. Google Special Services and Collections 29. Google Directory 30. Google Groups 31. Google Images 32. Google News 33. Google Catalogs 34. Froogle 35. Google Labs Chapter 3. Third-Party Google Services 36. XooMLe: The Google API in Plain Old XML 37. Google by Email 38. Simplifying Google Groups URLs 39. What Does Google Think Of... 40. GooglePeople Chapter 4. Non-API Google Applications 41. Don't Try This at Home 42. Building a Custom Date-Range Search Form 43. Building Google Directory URLs 44. Scraping Google Results 45. Scraping Google AdWords 46. Scraping Google Groups 47. Scraping Google News 48. Scraping Google Catalogs 49. Scraping the Google Phonebook Chapter 5. Introducing the Google Web API 50. Programming the Google Web API with Perl 51. Looping Around the 10-Result Limit 52. -

Where Is the Semantic Web? – an Overview of the Use of Embeddable Semantics in Austria
Where Is The Semantic Web? – An Overview of the Use of Embeddable Semantics in Austria Wilhelm Loibl Institute for Service Marketing and Tourism Vienna University of Economics and Business, Austria [email protected] Abstract Improving the results of search engines and enabling new online applications are two of the main aims of the Semantic Web. For a machine to be able to read and interpret semantic information, this content has to be offered online first. With several technologies available the question arises which one to use. Those who want to build the software necessary to interpret the offered data have to know what information is available and in which format. In order to answer these questions, the author analysed the business websites of different Austrian industry sectors as to what semantic information is embedded. Preliminary results show that, although overall usage numbers are still small, certain differences between individual sectors exist. Keywords: semantic web, RDFa, microformats, Austria, industry sectors 1 Introduction As tourism is a very information-intense industry (Werthner & Klein, 1999), especially novel users resort to well-known generic search engines like Google to find travel related information (Mitsche, 2005). Often, these machines do not provide satisfactory search results as their algorithms match a user’s query against the (weighted) terms found in online documents (Berry and Browne, 1999). One solution to this problem lies in “Semantic Searches” (Maedche & Staab, 2002). In order for them to work, web resources must first be annotated with additional metadata describing the content (Davies, Studer & Warren., 2006). Therefore, anyone who wants to provide data online must decide on which technology to use. -

Few Tips for Gatto Murder Investigation Even After $50,000
Los Feliz Ledger Read by 100,000+ Residents and Business Owners in Los Feliz, Silver Lake, Vol 9. No. 10 April 2014 Atwater Village, Echo Park & Hollywood Hills Commissioners Few Tips for to Decide On Gatto Murder Park Baseball Investigation & Performance Even After Stage $50,000 Reward By Hayley Fox LOS ANGELES —The city’s Ledger Senior Contributing Recreation and Park’s Com- Writer missioners will decide on con- struction of two youth base- More than four months ball fields at Griffith Park’s after the Silver Lake murder of Crystal Springs, April 2nd as Joseph Gatto, police still have well as a permanent stage at little new to report even after the Old Zoo for Symphony in a $50,000 reward was offered the Glen and the Independent for information leading to the Shakespeare Co. arrest and conviction of Gat- The hearing was moved to’s killer. from March 5th to provide According to the Los An- more time for public comment. geles Police Dept. (LAPD) At the commissioner’s, Robbery-Homicide Det. Chris March 19th, Los Feliz Ledger Gable fewer than 25 tips have publisher Allison B. Cohen been received since the reward and Los Feliz Neighborhood was offered in January. Council Recreation Represen- EMERSON IN L.A.—Los Angeles Mayor Eric Garcetti Los Angeles City Councilmember Mitch O’Farrell were This may be, Gable said, tative Mark F. Mauceri spoke on hand March 8th to celebrate the grand opening of the Emerson Los Angeles College. Located on Sunset because law enforcement had in favor of the Crystal Springs Boulevard near the Hollywood Palladium, the 10-story building, designed by award winning Los Angeles architect Thom Payne was designed “to expand the interactive, social aspect of education.” The building already spoken to many—such ballfields; Barbara Ferris and exterior features a sun shading system that adapts to changing weather to maintain indoor temperature as Gatto’s neighbors—imme- Arthur Rubenstein—both of and natural light levels among other sustainable, and beautiful, features. -

Awareness Watch™ Newsletter by Marcus P
Awareness Watch™ Newsletter By Marcus P. Zillman, M.S., A.M.H.A. http://www.AwarenessWatch.com/ V6N1 January 2008 Welcome to the V6N1 January 2008 issue of the Awareness Watch™ Newsletter. This newsletter is available as a complimentary subscription and will be issued monthly. Each newsletter will feature the following: Awareness Watch™ Featured Report Awareness Watch™ Spotters Awareness Watch™ Book/Paper/Article Review Subject Tracer™ Information Blogs I am always open to feedback from readers so please feel free to email with all suggestions, reviews and new resources that you feel would be appropriate for inclusion in an upcoming issue of Awareness Watch™. This is an ongoing work of creativity and you will be observing constant changes, constant updates knowing that “change” is the only thing that will remain constant!! Awareness Watch™ Featured Report This month’s featured report will be highlighting my Knowledge Discovery Resources 2008 Internet MiniGuide Annotated Link Compilation. These resources are constantly updated on the Knowledge Discovery Resources Subject Tracer™ Information Blog available at the following URL: http://www.KnowledgeDiscovery.info/ These resources and sites bring you the latest information and happenings in the area of Knowledge Discovery on the Internet and allow you to expand your knowledge both in discovery as well as connected and associated Internet links. 1 Awareness Watch V6N1 January 2008 Newsletter http://www.AwarenessWatch.com/ [email protected] © 2008 Marcus P. Zillman, M.S., A.M.H.A. Knowledge Discovery Resources 2008 An Internet MiniGuide Annotated Link Compilation By Marcus P. Zillman, M.S., A.M.H.A. Executive Director – Virtual Private Library [email protected] This Internet MiniGuide Annotated Link Compilation is dedicated to the latest and most competent resources for knowledge discovery available over the Internet. -
Report for Portal Specific
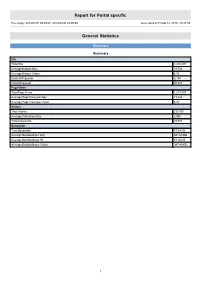
Report for Portal specific Time range: 2013/01/01 00:00:07 - 2013/03/31 23:59:59 Generated on Fri Apr 12, 2013 - 18:27:59 General Statistics Summary Summary Hits Total Hits 1,416,097 Average Hits per Day 15,734 Average Hits per Visitor 6.05 Cached Requests 8,154 Failed Requests 70,823 Page Views Total Page Views 1,217,537 Average Page Views per Day 13,528 Average Page Views per Visitor 5.21 Visitors Total Visitors 233,895 Average Visitors per Day 2,598 Total Unique IPs 49,753 Bandwidth Total Bandwidth 77.49 GB Average Bandwidth per Day 881.68 MB Average Bandwidth per Hit 57.38 KB Average Bandwidth per Visitor 347.40 KB 1 Activity Statistics Daily Daily Visitors 4,000 3,500 3,000 2,500 2,000 Visitors 1,500 1,000 500 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Hits 40,000 35,000 30,000 25,000 Hits 20,000 15,000 10,000 5,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date 2 Daily Bandwidth 1,300,000 1,200,000 1,100,000 1,000,000 900,000 800,000 700,000 600,000 500,000 Bandwidth (KB) 400,000 300,000 200,000 100,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Activity Date Hits Page Views Visitors Average Visit Length Bandwidth (KB) Sun 2013/02/10 11,783 10,245 2,280 13:01 648,207 Mon 2013/02/11 16,454 14,146 2,484 10:05 906,702 Tue 2013/02/12 19,572 17,089 3,062 07:47 926,190 Wed 2013/02/13 14,554 12,402 2,824 06:09 958,951 Thu 2013/02/14 12,577 10,666 2,690 05:03 821,129 Fri 2013/02/15 15,806 12,697 2,868 07:02 1,208,095 Sat 2013/02/16 16,811 14,939