Hidden Meaning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Privacy Protection for Smartphones: an Ontology-Based Firewall Johanne Vincent, Christine Porquet, Maroua Borsali, Harold Leboulanger
Privacy Protection for Smartphones: An Ontology-Based Firewall Johanne Vincent, Christine Porquet, Maroua Borsali, Harold Leboulanger To cite this version: Johanne Vincent, Christine Porquet, Maroua Borsali, Harold Leboulanger. Privacy Protection for Smartphones: An Ontology-Based Firewall. 5th Workshop on Information Security Theory and Prac- tices (WISTP), Jun 2011, Heraklion, Crete, Greece. pp.371-380, 10.1007/978-3-642-21040-2_27. hal-00801738 HAL Id: hal-00801738 https://hal.archives-ouvertes.fr/hal-00801738 Submitted on 18 Mar 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License Privacy Protection for Smartphones: An Ontology-Based Firewall Johann Vincent, Christine Porquet, Maroua Borsali, and Harold Leboulanger GREYC Laboratory, ENSICAEN - CNRS University of Caen-Basse-Normandie, 14000 Caen, France {johann.vincent,christine.porquet}@greyc.ensicaen.fr, {maroua.borsali,harold.leboulanger}@ecole.ensicaen.fr Abstract. With the outbreak of applications for smartphones, attempts to collect personal data without their user’s consent are multiplying and the protection of users privacy has become a major issue. In this paper, an approach based on semantic web languages (OWL and SWRL) and tools (DL reasoners and ontology APIs) is described. -

Requirements, Design and Applications to Semantic Integration and Knowledge Discovery
Practical Ontologies: Requirements, Design and Applications to Semantic Integration and Knowledge Discovery by Daniela Rosu A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Graduate Department of Computer Science University of Toronto © Copyright by Daniela Rosu 2013 Practical Ontologies: Requirements, Design and Applications to Semantic Integration and Knowledge Discovery Daniela Rosu Doctor of Philosophy Graduate Department of Computer Science University of Toronto 2013 Abstract Due to their role in describing the semantics of information, knowledge representations, from formal ontologies to informal representations such as folksonomies, are becoming increasingly important in facilitating the exchange of information, as well as the semantic integration of information systems and knowledge discovery in a large number of areas, from e-commerce to bioinformatics. In this thesis we present several studies related to the development and application of knowledge representations, in the form of practical ontologies. In Chapter 2, we examine representational challenges and requirements for describing practical domain knowledge. We present representational requirements we collected by surveying current and potential ontology users, discuss current approaches to codifying knowledge and give formal representation solutions to some of the issues we identified. In Chapter 3 we introduce a practical ontology for representing data exchanges, discuss its relationship with existing standards and its role in facilitating the interoperability between information producing and consuming services. ii We also consider the problem of assessing similarity between ontological concepts and propose three novel measures of similarity, detailed in Chapter 4. Two of our proposals estimate semantic similarity between concepts in the same ontology, while the third measures similarity between concepts belonging to different ontologies. -

Mapping Spatiotemporal Data to RDF: a SPARQL Endpoint for Brussels
International Journal of Geo-Information Article Mapping Spatiotemporal Data to RDF: A SPARQL Endpoint for Brussels Alejandro Vaisman 1, * and Kevin Chentout 2 1 Instituto Tecnológico de Buenos Aires, Buenos Aires 1424, Argentina 2 Sopra Banking Software, Avenue de Tevuren 226, B-1150 Brussels, Belgium * Correspondence: [email protected]; Tel.: +54-11-3457-4864 Received: 20 June 2019; Accepted: 7 August 2019; Published: 10 August 2019 Abstract: This paper describes how a platform for publishing and querying linked open data for the Brussels Capital region in Belgium is built. Data are provided as relational tables or XML documents and are mapped into the RDF data model using R2RML, a standard language that allows defining customized mappings from relational databases to RDF datasets. In this work, data are spatiotemporal in nature; therefore, R2RML must be adapted to allow producing spatiotemporal Linked Open Data.Data generated in this way are used to populate a SPARQL endpoint, where queries are submitted and the result can be displayed on a map. This endpoint is implemented using Strabon, a spatiotemporal RDF triple store built by extending the RDF store Sesame. The first part of the paper describes how R2RML is adapted to allow producing spatial RDF data and to support XML data sources. These techniques are then used to map data about cultural events and public transport in Brussels into RDF. Spatial data are stored in the form of stRDF triples, the format required by Strabon. In addition, the endpoint is enriched with external data obtained from the Linked Open Data Cloud, from sites like DBpedia, Geonames, and LinkedGeoData, to provide context for analysis. -

A Review of Openstreetmap Data Peter Mooney* and Marco Minghini† *Department of Computer Science, Maynooth University, Maynooth, Co
CHAPTER 3 A Review of OpenStreetMap Data Peter Mooney* and Marco Minghini† *Department of Computer Science, Maynooth University, Maynooth, Co. Kildare, Ireland, [email protected] †Department of Civil and Environmental Engineering, Politecnico di Milano, Piazza Leonardo da Vinci 32, 20133 Milano, Italy Abstract While there is now a considerable variety of sources of Volunteered Geo- graphic Information (VGI) available, discussion of this domain is often exem- plified by and focused around OpenStreetMap (OSM). In a little over a decade OSM has become the leading example of VGI on the Internet. OSM is not just a crowdsourced spatial database of VGI; rather, it has grown to become a vast ecosystem of data, software systems and applications, tools, and Web-based information stores such as wikis. An increasing number of developers, indus- try actors, researchers and other end users are making use of OSM in their applications. OSM has been shown to compare favourably with other sources of spatial data in terms of data quality. In addition to this, a very large OSM community updates data within OSM on a regular basis. This chapter provides an introduction to and review of OSM and the ecosystem which has grown to support the mission of creating a free, editable map of the whole world. The chapter is especially meant for readers who have no or little knowledge about the range, maturity and complexity of the tools, services, applications and organisations working with OSM data. We provide examples of tools and services to access, edit, visualise and make quality assessments of OSM data. We also provide a number of examples of applications, such as some of those How to cite this book chapter: Mooney, P and Minghini, M. -

Wiki Semantics Via Wiki Templating
Chapter XXXIV Wiki Semantics via Wiki Templating Angelo Di Iorio Department of Computer Science, University of Bologna, Italy Fabio Vitali Department of Computer Science, University of Bologna, Italy Stefano Zacchiroli Universitè Paris Diderot, PPS, UMR 7126, Paris, France ABSTRACT A foreseeable incarnation of Web 3.0 could inherit machine understandability from the Semantic Web, and collaborative editing from Web 2.0 applications. We review the research and development trends which are getting today Web nearer to such an incarnation. We present semantic wikis, microformats, and the so-called “lowercase semantic web”: they are the main approaches at closing the technological gap between content authors and Semantic Web technologies. We discuss a too often neglected aspect of the associated technologies, namely how much they adhere to the wiki philosophy of open editing: is there an intrinsic incompatibility between semantic rich content and unconstrained editing? We argue that the answer to this question can be “no”, provided that a few yet relevant shortcomings of current Web technologies will be fixed soon. INTRODUCTION Web 3.0 can turn out to be many things, it is hard to state what will be the most relevant while still debating on what Web 2.0 [O’Reilly (2007)] has been. We postulate that a large slice of Web 3.0 will be about the synergies between Web 2.0 and the Semantic Web [Berners-Lee et al. (2001)], synergies that only very recently have begun to be discovered and exploited. We base our foresight on the observation that Web 2.0 and the Semantic Web are converging to a common point in their initially split evolution lines. -

Le Microformat Hproduct C'est Quoi ? Pourquoi Utiliser Le Microformat
Apprendre à utiliser les microformats : hProduct 2017-02-21 23:02:01 Nicolaseo Le microformat hProduct c’est quoi ? hProduct est un microformat approprié pour publier et embarquer les données de vos produits. C’est une sorte de méta tags qui permet de structurer vos données pour permettre aux robots des moteurs de recherche de mieux référencer votre contenu. Pourquoi utiliser le microformat hProduct Le microformat hProduct est basé sur un ensemble de champs très important pour communiquer avec les robots des moteurs de recherche comme Google. Utiliser les {meta- tags|richsnippets|microformats} (et tout ce qui peut permettre aux moteurs de recherche de mieux classer votre contenu) vous apportera plus de visibilité sur internet grâce à un meilleur référencement de votre site et de son contenu. Comment utiliser le microformat hProduct Le schéma hProduct se compose de ce qui suit : hproduct brand. optionnel. texte. peut aussi utiliser hCard pour les fabricants. category. optionnel. texte. peut aussi utiliser rel-tag. ré-utilisé à partir de hCard. price. optionnel. floating point number. peut utiliser un format de devise. description. optionnel. texte. peut aussi inclure un marquage HTML valide. réutilisé à partir de hReview. fn. requis. texte. nom du produit ou titre. réutilisé de hCard. photo. optionnel. élément image ou lien. réutilisé de hCard. url. optionnel. href. peut contenir rel-tag rel=’product’. ré-utilisé de hCard. review. optionnel. hReview, ou hReview-aggregate. listing. optionnel. hListing, ou hListing-aggregate. identifier. optionnel. type. requis. – exemples : model mpn upc isbn issn ean jan sn vin sku value. requis. – l’étiquette peut être implicite. Détails des champs du microformat hProduct Les noms de classe category, fn, photo, url sont réutilisés à partir de hCard. -

Where Is the Semantic Web? – an Overview of the Use of Embeddable Semantics in Austria
Where Is The Semantic Web? – An Overview of the Use of Embeddable Semantics in Austria Wilhelm Loibl Institute for Service Marketing and Tourism Vienna University of Economics and Business, Austria [email protected] Abstract Improving the results of search engines and enabling new online applications are two of the main aims of the Semantic Web. For a machine to be able to read and interpret semantic information, this content has to be offered online first. With several technologies available the question arises which one to use. Those who want to build the software necessary to interpret the offered data have to know what information is available and in which format. In order to answer these questions, the author analysed the business websites of different Austrian industry sectors as to what semantic information is embedded. Preliminary results show that, although overall usage numbers are still small, certain differences between individual sectors exist. Keywords: semantic web, RDFa, microformats, Austria, industry sectors 1 Introduction As tourism is a very information-intense industry (Werthner & Klein, 1999), especially novel users resort to well-known generic search engines like Google to find travel related information (Mitsche, 2005). Often, these machines do not provide satisfactory search results as their algorithms match a user’s query against the (weighted) terms found in online documents (Berry and Browne, 1999). One solution to this problem lies in “Semantic Searches” (Maedche & Staab, 2002). In order for them to work, web resources must first be annotated with additional metadata describing the content (Davies, Studer & Warren., 2006). Therefore, anyone who wants to provide data online must decide on which technology to use. -

Microformats the Next (Small) Thing on the Semantic Web?
Standards Editor: Jim Whitehead • [email protected] Microformats The Next (Small) Thing on the Semantic Web? Rohit Khare • CommerceNet “Designed for humans first and machines second, microformats are a set of simple, open data formats built upon existing and widely adopted standards.” — Microformats.org hen we speak of the “evolution of the is precisely encoding the great variety of person- Web,” it might actually be more appropri- al, professional, and genealogical relationships W ate to speak of “intelligent design” — we between people and organizations. By contrast, can actually point to a living, breathing, and an accidental challenge is that any blogger with actively involved Creator of the Web. We can even some knowledge of HTML can add microformat consult Tim Berners-Lee’s stated goals for the markup to a text-input form, but uploading an “promised land,” dubbed the Semantic Web. Few external file dedicated to machine-readable use presume we could reach those objectives by ran- remains forbiddingly complex with most blog- domly hacking existing Web standards and hop- ging tools. ing that “natural selection” by authors, software So, although any intelligent designer ought to developers, and readers would ensure powerful be able to rely on the long-established facility of enough abstractions for it. file transfer to publish the “right” model of a social Indeed, the elegant and painstakingly inter- network, the path of least resistance might favor locked edifice of technologies, including RDF, adding one of a handful of fixed tags to an exist- XML, and query languages is now growing pow- ing indirect form — the “blogroll” of hyperlinks to erful enough to attack massive information chal- other people’s sites. -

Data Models for Home Services
__________________________________________PROCEEDING OF THE 13TH CONFERENCE OF FRUCT ASSOCIATION Data Models for Home Services Vadym Kramar, Markku Korhonen, Yury Sergeev Oulu University of Applied Sciences, School of Engineering Raahe, Finland {vadym.kramar, markku.korhonen, yury.sergeev}@oamk.fi Abstract An ultimate penetration of communication technologies allowing web access has enriched a conception of smart homes with new paradigms of home services. Modern home services range far beyond such notions as Home Automation or Use of Internet. The services expose their ubiquitous nature by being integrated into smart environments, and provisioned through a variety of end-user devices. Computational intelligence require a use of knowledge technologies, and within a given domain, such requirement as a compliance with modern web architecture is essential. This is where Semantic Web technologies excel. A given work presents an overview of important terms, vocabularies, and data models that may be utilised in data and knowledge engineering with respect to home services. Index Terms: Context, Data engineering, Data models, Knowledge engineering, Semantic Web, Smart homes, Ubiquitous computing. I. INTRODUCTION In recent years, a use of Semantic Web technologies to build a giant information space has shown certain benefits. Rapid development of Web 3.0 and a use of its principle in web applications is the best evidence of such benefits. A traditional database design in still and will be widely used in web applications. One of the most important reason for that is a vast number of databases developed over years and used in a variety of applications varying from simple web services to enterprise portals. In accordance to Forrester Research though a growing number of document, or knowledge bases, such as NoSQL is not a hype anymore [1]. -
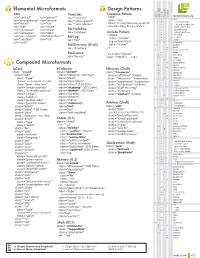
Microformats Cheat Sheet
Elemental Microformats Design Patterns tom eview Datetime Pattern esume XFN VoteLinks microformats.org hR hR hCard hCalendar rel="contact" rel="parent" rev="vote-for" <abbr hA rel="acquaintance" rel="spouse" class="foo" • adr rev="vote-against" + country-name title="YYYY-MM-DDTHH:MM:SS+ZZ:ZZ" rel="friend" rel="kin" rev="vote-abstain" • extended-address rel="met" rel="muse" >Human Date Time</abbr> + post-office-box rel="co-worker" rel="crush" Rel-Nofollow + postal-code rel="colleague" rel="date" rel="nofollow" Include Pattern • street-address + locality rel="co-resident" rel="sweetheart" <object Rel-Tag class="include" + region rel="neighbor" rel="me" rel="tag" • type rel="child" type="text/html" • affiliation Rel-Directory (Draft) data="#idref" ¤ author rel="directory" /> + best × + bookmark (rel) Rel-License + bday <a class="include" • • category rel="license" href="#idref">...</a> + + class × contact Compound Microformats + description + dtend + dtreviewed hCard hCalendar hResume (Draft) × dtstart class="vcard" class="vevent" class="hresume" × dtstamp class="adr" class="category" rel="tag" class="affiliation" (hcard) duration class="type" class="class" class="education" (hcalendar) • education [work|home|pref|postal|dom|intl] class="description" • email class="experience" (hcalendar) • type class="post-office-box" class="dtend" (ISO Date) class="publication" (citation) • value class="street-address" class="dtstamp" (ISO Date) class="skill" rel="tag" × entry-content class="extended-address" class="dtstart" (ISO Date) class="summary" • entry-summary -

Using Wordpress to Manage Geocontent and Promote Regional Food Products
Farm2.0: Using Wordpress to Manage Geocontent and Promote Regional Food Products Amenity Applewhite Farm2.0: Using Wordpress to Manage Geocontent and Promote Regional Food Products Dissertation supervised by Ricardo Quirós PhD Dept. Lenguajes y Sistemas Informaticos Universitat Jaume I, Castellón, Spain Co-supervised by Werner Kuhn, PhD Institute for Geoinformatics Westfälische Wilhelms-Universität, Münster, Germany Miguel Neto, PhD Instituto Superior de Estatística e Gestão da Informação Universidade Nova de Lisboa, Lisbon, Portugal March 2009 Farm2.0: Using Wordpress to Manage Geocontent and Promote Regional Food Products Abstract Recent innovations in geospatial technology have dramatically increased the utility and ubiquity of cartographic interfaces and spatially-referenced content on the web. Capitalizing on these developments, the Farm2.0 system demonstrates an approach to manage user-generated geocontent pertaining to European protected designation of origin (PDO) food products. Wordpress, a popular open-source publishing platform, supplies the framework for a geographic content management system, or GeoCMS, to promote PDO products in the Spanish province of Valencia. The Wordpress platform is modified through a suite of plug-ins and customizations to create an extensible application that could be easily deployed in other regions and administrated cooperatively by distributed regulatory councils. Content, either regional recipes or map locations for vendors and farms, is available for syndication as a GeoRSS feed and aggregated with outside feeds in a dynamic web map. To Dad, Thanks for being 2TUF: MTLI 4 EVA. Acknowledgements Without encouragement from Dr. Emilio Camahort, I never would have had the confidence to ensure my thesis handled the topics I was most passionate about studying - sustainable agriculture and web mapping. -

Microformats: Empowering Your Markup for Web 2.0
Microformats: Empowering Your Markup for Web 2.0 John Allsopp Microformats: Empowering Your Markup for Web 2.0 Copyright © 2007 by John Allsopp All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage or retrieval system, without the prior written permission of the copyright owner and the publisher. ISBN-13 (pbk): 978-1-59059814-6 ISBN-10 (pbk): 1-59059-814-8 Printed and bound in the United States of America 9 8 7 6 5 4 3 2 1 Trademarked names may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, we use the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. Distributed to the book trade worldwide by Springer-Verlag New York, Inc., 233 Spring Street, 6th Floor, New York, NY 10013. Phone 1-800-SPRINGER, fax 201-348-4505, e-mail [email protected],or visit www.springeronline.com. For information on translations, please contact Apress directly at 2560 Ninth Street, Suite 219, Berkeley, CA 94710. Phone 510-549-5930, fax 510-549-5939, e-mail [email protected], or visit www.apress.com. The information in this book is distributed on an “as is” basis, without warranty. Although every precaution has been taken in the preparation of this work, neither the author(s) nor Apress shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the information contained in this work.