From Atom's to OWL S: the New Ecology of The
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Trust on the World Wide Web: a Survey Full Text Available At
Full text available at: http://dx.doi.org/10.1561/0400000006 Trust on the World Wide Web: A Survey Full text available at: http://dx.doi.org/10.1561/0400000006 Trust on the World Wide Web: A Survey Jennifer Golbeck University of Maryland College Park MA 20742 USA [email protected] Boston – Delft Full text available at: http://dx.doi.org/10.1561/0400000006 Foundations and Trends R in Web Science Published, sold and distributed by: now Publishers Inc. PO Box 1024 Hanover, MA 02339 USA Tel. +1-781-985-4510 www.nowpublishers.com [email protected] Outside North America: now Publishers Inc. PO Box 179 2600 AD Delft The Netherlands Tel. +31-6-51115274 The preferred citation for this publication is J. Golbeck, Trust on the World Wide Web: A Survey, Foundation and Trends R in Web Science, vol 1, no 2, pp 131–197, 2006 ISBN: 978-1-60198-116-5 c 2008 J. Golbeck All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, mechanical, photocopying, recording or otherwise, without prior written permission of the publishers. Photocopying. In the USA: This journal is registered at the Copyright Clearance Cen- ter, Inc., 222 Rosewood Drive, Danvers, MA 01923. Authorization to photocopy items for internal or personal use, or the internal or personal use of specific clients, is granted by now Publishers Inc. for users registered with the Copyright Clearance Center (CCC). The ‘services’ for users can be found on the internet at: www.copyright.com For those organizations that have been granted a photocopy license, a separate system of payment has been arranged. -

Hidden Meaning
FEATURES Microdata and Microformats Kit Sen Chin, 123RF.com Chin, Sen Kit Working with microformats and microdata Hidden Meaning Programs aren’t as smart as humans when it comes to interpreting the meaning of web information. If you want to maximize your search rank, you might want to dress up your HTML documents with microformats and microdata. By Andreas Möller TML lets you mark up sections formats and microdata into your own source code for the website shown in of text as headings, body text, programs. Figure 1 – an HTML5 document with a hyperlinks, and other web page business card. The Heading text block is H elements. However, these defi- Microformats marked up with the element h1. The text nitions have nothing to do with the HTML was originally designed for hu- for the business card is surrounded by meaning of the data: Does the text refer mans to read, but with the explosive the div container element, and <br/> in- to a person, an organization, a product, growth of the web, programs such as troduces a line break. or an event? Microformats [1] and their search engines also process HTML data. It is easy for a human reader to see successor, microdata [2] make the mean- What do programs that read HTML data that the data shown in Figure 1 repre- ing a bit more clear by pointing to busi- typically find? Listing 1 shows the HTML sents a business card – even if the text is ness cards, product descriptions, offers, and event data in a machine-readable LISTING 1: HTML5 Document with Business Card way. -

Awareness Watch™ Newsletter V16N2 February 2018
Awareness Watch™ Newsletter By Marcus P. Zillman, M.S., A.M.H.A. http://www.AwarenessWatch.com/ V16N2 February 2018 Welcome to the V16N2 February 2018 issue of the Awareness Watch™ Newsletter. This newsletter is available as a complimentary subscription and will be issued monthly. Each newsletter will feature the following: Awareness Watch™ Featured Report Awareness Watch™ Spotters Awareness Watch™ Book/Paper/Article Review Subject Tracer™ Information Blogs I am always open to feedback from readers so please feel free to email with all suggestions, reviews and new resources that you feel would be appropriate for inclusion in an upcoming issue of Awareness Watch™. This is an ongoing work of creativity and you will be observing constant changes, constant updates knowing that “change” is the only thing that will remain constant!! Awareness Watch™ Featured Report This month’s featured report covers my Deep Web Research and Discovery Resources 2018 and is a comprehensive listing of deep web resources including search engines, directories, subject guides and index resources and sites on the Internet. The below list of sources is taken from my Subject Tracer™ white paper titled Deep Web Research and Discovery Resources 2018 and is constantly updated with Subject Tracer™ bots at the following URLs: http://www.DeepWeb.us/ These resources and sources will help you to discover the many pathways available through the Internet to find the latest deep web resources and sites. As this site is constantly updated it would be to your benefit to bookmark and return to the above URL frequently. The true way to search the Internet and social media is to include the deep web and these resources will be your pathfinder to all the important and ever changing resources including the New Economy! 1 Awareness Watch V16N2 February 2018 Newsletter http://www.AwarenessWatch.com/ [email protected] eVoice: 800-858-1462 © 2018 Marcus P. -

Le Microformat Hproduct C'est Quoi ? Pourquoi Utiliser Le Microformat
Apprendre à utiliser les microformats : hProduct 2017-02-21 23:02:01 Nicolaseo Le microformat hProduct c’est quoi ? hProduct est un microformat approprié pour publier et embarquer les données de vos produits. C’est une sorte de méta tags qui permet de structurer vos données pour permettre aux robots des moteurs de recherche de mieux référencer votre contenu. Pourquoi utiliser le microformat hProduct Le microformat hProduct est basé sur un ensemble de champs très important pour communiquer avec les robots des moteurs de recherche comme Google. Utiliser les {meta- tags|richsnippets|microformats} (et tout ce qui peut permettre aux moteurs de recherche de mieux classer votre contenu) vous apportera plus de visibilité sur internet grâce à un meilleur référencement de votre site et de son contenu. Comment utiliser le microformat hProduct Le schéma hProduct se compose de ce qui suit : hproduct brand. optionnel. texte. peut aussi utiliser hCard pour les fabricants. category. optionnel. texte. peut aussi utiliser rel-tag. ré-utilisé à partir de hCard. price. optionnel. floating point number. peut utiliser un format de devise. description. optionnel. texte. peut aussi inclure un marquage HTML valide. réutilisé à partir de hReview. fn. requis. texte. nom du produit ou titre. réutilisé de hCard. photo. optionnel. élément image ou lien. réutilisé de hCard. url. optionnel. href. peut contenir rel-tag rel=’product’. ré-utilisé de hCard. review. optionnel. hReview, ou hReview-aggregate. listing. optionnel. hListing, ou hListing-aggregate. identifier. optionnel. type. requis. – exemples : model mpn upc isbn issn ean jan sn vin sku value. requis. – l’étiquette peut être implicite. Détails des champs du microformat hProduct Les noms de classe category, fn, photo, url sont réutilisés à partir de hCard. -

Where Is the Semantic Web? – an Overview of the Use of Embeddable Semantics in Austria
Where Is The Semantic Web? – An Overview of the Use of Embeddable Semantics in Austria Wilhelm Loibl Institute for Service Marketing and Tourism Vienna University of Economics and Business, Austria [email protected] Abstract Improving the results of search engines and enabling new online applications are two of the main aims of the Semantic Web. For a machine to be able to read and interpret semantic information, this content has to be offered online first. With several technologies available the question arises which one to use. Those who want to build the software necessary to interpret the offered data have to know what information is available and in which format. In order to answer these questions, the author analysed the business websites of different Austrian industry sectors as to what semantic information is embedded. Preliminary results show that, although overall usage numbers are still small, certain differences between individual sectors exist. Keywords: semantic web, RDFa, microformats, Austria, industry sectors 1 Introduction As tourism is a very information-intense industry (Werthner & Klein, 1999), especially novel users resort to well-known generic search engines like Google to find travel related information (Mitsche, 2005). Often, these machines do not provide satisfactory search results as their algorithms match a user’s query against the (weighted) terms found in online documents (Berry and Browne, 1999). One solution to this problem lies in “Semantic Searches” (Maedche & Staab, 2002). In order for them to work, web resources must first be annotated with additional metadata describing the content (Davies, Studer & Warren., 2006). Therefore, anyone who wants to provide data online must decide on which technology to use. -

Microformats the Next (Small) Thing on the Semantic Web?
Standards Editor: Jim Whitehead • [email protected] Microformats The Next (Small) Thing on the Semantic Web? Rohit Khare • CommerceNet “Designed for humans first and machines second, microformats are a set of simple, open data formats built upon existing and widely adopted standards.” — Microformats.org hen we speak of the “evolution of the is precisely encoding the great variety of person- Web,” it might actually be more appropri- al, professional, and genealogical relationships W ate to speak of “intelligent design” — we between people and organizations. By contrast, can actually point to a living, breathing, and an accidental challenge is that any blogger with actively involved Creator of the Web. We can even some knowledge of HTML can add microformat consult Tim Berners-Lee’s stated goals for the markup to a text-input form, but uploading an “promised land,” dubbed the Semantic Web. Few external file dedicated to machine-readable use presume we could reach those objectives by ran- remains forbiddingly complex with most blog- domly hacking existing Web standards and hop- ging tools. ing that “natural selection” by authors, software So, although any intelligent designer ought to developers, and readers would ensure powerful be able to rely on the long-established facility of enough abstractions for it. file transfer to publish the “right” model of a social Indeed, the elegant and painstakingly inter- network, the path of least resistance might favor locked edifice of technologies, including RDF, adding one of a handful of fixed tags to an exist- XML, and query languages is now growing pow- ing indirect form — the “blogroll” of hyperlinks to erful enough to attack massive information chal- other people’s sites. -
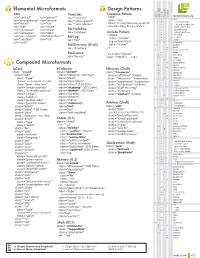
Microformats Cheat Sheet
Elemental Microformats Design Patterns tom eview Datetime Pattern esume XFN VoteLinks microformats.org hR hR hCard hCalendar rel="contact" rel="parent" rev="vote-for" <abbr hA rel="acquaintance" rel="spouse" class="foo" • adr rev="vote-against" + country-name title="YYYY-MM-DDTHH:MM:SS+ZZ:ZZ" rel="friend" rel="kin" rev="vote-abstain" • extended-address rel="met" rel="muse" >Human Date Time</abbr> + post-office-box rel="co-worker" rel="crush" Rel-Nofollow + postal-code rel="colleague" rel="date" rel="nofollow" Include Pattern • street-address + locality rel="co-resident" rel="sweetheart" <object Rel-Tag class="include" + region rel="neighbor" rel="me" rel="tag" • type rel="child" type="text/html" • affiliation Rel-Directory (Draft) data="#idref" ¤ author rel="directory" /> + best × + bookmark (rel) Rel-License + bday <a class="include" • • category rel="license" href="#idref">...</a> + + class × contact Compound Microformats + description + dtend + dtreviewed hCard hCalendar hResume (Draft) × dtstart class="vcard" class="vevent" class="hresume" × dtstamp class="adr" class="category" rel="tag" class="affiliation" (hcard) duration class="type" class="class" class="education" (hcalendar) • education [work|home|pref|postal|dom|intl] class="description" • email class="experience" (hcalendar) • type class="post-office-box" class="dtend" (ISO Date) class="publication" (citation) • value class="street-address" class="dtstamp" (ISO Date) class="skill" rel="tag" × entry-content class="extended-address" class="dtstart" (ISO Date) class="summary" • entry-summary -

Microformats: Empowering Your Markup for Web 2.0
Microformats: Empowering Your Markup for Web 2.0 John Allsopp Microformats: Empowering Your Markup for Web 2.0 Copyright © 2007 by John Allsopp All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage or retrieval system, without the prior written permission of the copyright owner and the publisher. ISBN-13 (pbk): 978-1-59059814-6 ISBN-10 (pbk): 1-59059-814-8 Printed and bound in the United States of America 9 8 7 6 5 4 3 2 1 Trademarked names may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, we use the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. Distributed to the book trade worldwide by Springer-Verlag New York, Inc., 233 Spring Street, 6th Floor, New York, NY 10013. Phone 1-800-SPRINGER, fax 201-348-4505, e-mail [email protected],or visit www.springeronline.com. For information on translations, please contact Apress directly at 2560 Ninth Street, Suite 219, Berkeley, CA 94710. Phone 510-549-5930, fax 510-549-5939, e-mail [email protected], or visit www.apress.com. The information in this book is distributed on an “as is” basis, without warranty. Although every precaution has been taken in the preparation of this work, neither the author(s) nor Apress shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the information contained in this work. -

Rdfa Versus Microformats: Exploring the Potential for Semantic Interoperability of Mash-Up Personal Learning Environments
RDFa versus Microformats: Exploring the Potential for Semantic Interoperability of Mash-up Personal Learning Environments Vladimir Tomberg, Mart Laanpere Tallinn University, Narva mnt. 25, 10120 Tallinn, Estonia [email protected], [email protected] Abstract. This paper addresses the possibilities for increasing semantic interoperability of mash-up learning environments through the use of automatically processed metadata associated with both learning resources and learning process. We analyze and compare potential of two competing technologies for this purpose: microformats and RDFa. 1 Introduction Mash-up Personal Learning Environments have become a fast developing trend in the world of technology-enhanced learning, partly because of their flexibility and lightweight integration features. Although it is quite easy to aggregate the RSS feeds from the blogs of learners, it is more difficult to get an overview of course and its learning activities. A course is not just a syllabus, it also involves various dynamic processes that can be described in many aspects. The course always has certain learning goals, a schedule that consists learning activities (assignments, discussions), registered participants like teachers and students, and different types of resources. It would be useful, if we would be able to extract such information also from mash-up personal learning environments (just like it can be done in traditional Learning Management Systems) and allow exchanging it between the course participants. Today for semantic tagging of Web content in general and learning content as special case various technologies are used. But there are no tools and ways exist for semantic annotation of learning process that takes place in a distributed network of mash-up personal learning environments. -

A Journal for Human and Machine
EDITORIAL A Journal for Human and Machine James Hendler1†, Ying Ding2† & Barend Mons3 1 Rensselaer Institute for Data Exploration and Applications, Rensselaer Polytechnic Institute, Troy, NY12180, USA 2 School of Informatics, Computing, and Engineering, Indiana University, Bloomington, IN 47408, USA 3 Leiden University Medical Centre, The Netherlands, Poortgebouw N-01, Rijnsburgerweg 10 2333 AA Leiden, The Netherlands Citation: J. Hendler, Y. Ding, & B. Mons. A journal for human and machine. Data Intelligence 1(2019), 1-5. doi: 10.1162/dint_e_00001 It is with great pride to bring you this new journal of Data Intelligence. This journal has at least two major purposes that we hope embrace. First, it will embrace the traditional role of a journal in helping to facilitate the communication of research and best practices in scientific data sharing, especially across disciplines, an area that is continually growing in importance for the modern practice of science. Second, we will be experimenting with new methods of enhancing the sharing of this communication, and examples of the field, by utilizing the increasing power of intelligent computing systems to further facilitate the growth of the field. The journal’s title, combining “data,” the field we will support, and “intelligence,” a means to that end, is meant to connote this growing interaction. Since the establishment of the first academic journals in the mid 1600’s, academic publishing has been a key part of scientific infrastructure, facilitating knowledge sharing and scholarly communication. Journals, at their best, publish high-quality scientific articles so that researchers can be aware of recent advancements in their fields and can have access to archival publications of the “giants” whose shoulders they stand on. -

An Introduction to the Semantic Web
An Introduction To The Semantic Web Fernando de Souza 1 “The Semantic Web is an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation.” Tim Berners-Lee, James Hendler and Ora Lassila, The Semantic Web, Scientific American, May 2001 2 1 An Introduction To The Semantic Web …extension of the current web… “. .information on the web needs to be in a form that machines can ‘understand’ rather than simply display. The concept of machine-understandable documents does not imply some magical artificial intelligence allowing machines to comprehend human mumblings. It relies solely on a machine’s ability to solve well-defined problems by performing well- defined operations on well-defined data.” From Berners-Lee, Hendler; Nature, 2001 3 http://www.nature.com/nature/debates/e-access/Articles/bernerslee.htm …extension of the current web… “Most of the Web's content today is designed for humans to read, not for computer programs to manipulate meaningfully.” Tim Berners-Lee, James Hendler and Ora Lassila, The Semantic Web, Scientific American, May 2001 4 2 An Introduction To The Semantic Web …well-defined meaning… There are lots of ways in which our machines can use our web content when they can understand it. •When my personal digital assistant's calendar program understands dates, it can alert me when an appointment is coming up. •When my email program's address book understands that something is a phone number or an email address, it can set up communication with that person with a click. -

Knowing What AI Systems Don't Know and Why It Matters
JHUVIRTUAL IAA SEMINARSEMINAR ANNOUNCEMENTSERIES Johns Hopkins Institute for Assured Autonomy and the Department of Computer Science Present Knowing what AI Systems Don’t Know and Why it Matters October 29, 2020 | 11:00 am–Noon Click here to access this virtual event <http://bit.ly/Jim-Hendler> Password: 962515 Jim Hendler Tetherless World Chair of Computer, Web and Cognitive Sciences Rensselaer Polytechnic Institute ABSTRACT The meteoric rise in performance of modern AI raises many concerns when it comes to autonomous systems, their use, and their ethics. In this talk, Jim Hendler reviews some of the challenges emerging, with a particular emphasis on one of the issues faced by current deep learning technology (including neural symbolic approaches) – how do AI systems know what they don’t know? Hendler avoids the generic issue, which has been raised by philosophers of AI, and looks more specifically at where the failures are coming from. The limitations of current systems, issues such as ‘personalization’ that increase the challenge, and some of the governance issues that arise from these limitations will be covered. BIO James Hendler is the Director of the Institute for Data Exploration and Applications and the Tetherless World Professor of Computer, Web and Cognitive Sciences at RPI. He also heads the RPI-IBM Center for Health Empowerment by Analytics, Learning and Semantics (HEALS). Hendler has authored over 400 books, technical papers and articles in the areas of Semantic Web, artificial intelligence, agent-based computing and high-performance processing. One of the originators of the “Semantic Web,” Hendler was the recipient of a 1995 Fulbright Foundation Fellowship, is a former member of the US Air Force Science Advisory Board, and is a Fellow of the AAAI, BCS, the IEEE, the AAAS and the ACM.