A Smart Web Crawler for a Concept Based Semantic Search Engine
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Study of Web Crawler and Its Different Types
IOSR Journal of Computer Engineering (IOSR-JCE) e-ISSN: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 1, Ver. VI (Feb. 2014), PP 01-05 www.iosrjournals.org Study of Web Crawler and its Different Types Trupti V. Udapure1, Ravindra D. Kale2, Rajesh C. Dharmik3 1M.E. (Wireless Communication and Computing) student, CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India 2Asst Prof., CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India, 3Asso.Prof. & Head, IT Department, Yeshwantrao Chavan College of Engineering, Nagpur, India, Abstract : Due to the current size of the Web and its dynamic nature, building an efficient search mechanism is very important. A vast number of web pages are continually being added every day, and information is constantly changing. Search engines are used to extract valuable Information from the internet. Web crawlers are the principal part of search engine, is a computer program or software that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. It is an essential method for collecting data on, and keeping in touch with the rapidly increasing Internet. This Paper briefly reviews the concepts of web crawler, its architecture and its various types. Keyword: Crawling techniques, Web Crawler, Search engine, WWW I. Introduction In modern life use of internet is growing in rapid way. The World Wide Web provides a vast source of information of almost all type. Now a day’s people use search engines every now and then, large volumes of data can be explored easily through search engines, to extract valuable information from web. -

Building a Scalable Index and a Web Search Engine for Music on the Internet Using Open Source Software
Department of Information Science and Technology Building a Scalable Index and a Web Search Engine for Music on the Internet using Open Source software André Parreira Ricardo Thesis submitted in partial fulfillment of the requirements for the degree of Master in Computer Science and Business Management Advisor: Professor Carlos Serrão, Assistant Professor, ISCTE-IUL September, 2010 Acknowledgments I should say that I feel grateful for doing a thesis linked to music, an art which I love and esteem so much. Therefore, I would like to take a moment to thank all the persons who made my accomplishment possible and hence this is also part of their deed too. To my family, first for having instigated in me the curiosity to read, to know, to think and go further. And secondly for allowing me to continue my studies, providing the environment and the financial means to make it possible. To my classmate André Guerreiro, I would like to thank the invaluable brainstorming, the patience and the help through our college years. To my friend Isabel Silva, who gave me a precious help in the final revision of this document. Everyone in ADETTI-IUL for the time and the attention they gave me. Especially the people over Caixa Mágica, because I truly value the expertise transmitted, which was useful to my thesis and I am sure will also help me during my professional course. To my teacher and MSc. advisor, Professor Carlos Serrão, for embracing my will to master in this area and for being always available to help me when I needed some advice. -

Open Search Environments: the Free Alternative to Commercial Search Services
Open Search Environments: The Free Alternative to Commercial Search Services. Adrian O’Riordan ABSTRACT Open search systems present a free and less restricted alternative to commercial search services. This paper explores the space of open search technology, looking in particular at lightweight search protocols and the issue of interoperability. A description of current protocols and formats for engineering open search applications is presented. The suitability of these technologies and issues around their adoption and operation are discussed. This open search approach is especially useful in applications involving the harvesting of resources and information integration. Principal among the technological solutions are OpenSearch, SRU, and OAI-PMH. OpenSearch and SRU realize a federated model to enable content providers and search clients communicate. Applications that use OpenSearch and SRU are presented. Connections are made with other pertinent technologies such as open-source search software and linking and syndication protocols. The deployment of these freely licensed open standards in web and digital library applications is now a genuine alternative to commercial and proprietary systems. INTRODUCTION Web search has become a prominent part of the Internet experience for millions of users. Companies such as Google and Microsoft offer comprehensive search services to users free with advertisements and sponsored links, the only reminder that these are commercial enterprises. Businesses and developers on the other hand are restricted in how they can use these search services to add search capabilities to their own websites or for developing applications with a search feature. The closed nature of the leading web search technology places barriers in the way of developers who want to incorporate search functionality into applications. -

Efficient Focused Web Crawling Approach for Search Engine
Ayar Pranav et al, International Journal of Computer Science and Mobile Computing, Vol.4 Issue.5, May- 2015, pg. 545-551 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320–088X IJCSMC, Vol. 4, Issue. 5, May 2015, pg.545 – 551 RESEARCH ARTICLE Efficient Focused Web Crawling Approach for Search Engine 1 2 Ayar Pranav , Sandip Chauhan Computer & Science Engineering, Kalol Institute of Technology and Research Canter, Kalol, Gujarat, India 1 [email protected]; 2 [email protected] Abstract— a focused crawler traverses the web, selecting out relevant pages to a predefined topic and neglecting those out of concern. Collecting domain specific documents using focused crawlers has been considered one of most important strategies to find relevant information. While surfing the internet, it is difficult to deal with irrelevant pages and to predict which links lead to quality pages. However most focused crawler use local search algorithm to traverse the web space, but they could easily trapped within limited a sub graph of the web that surrounds the starting URLs also there is problem related to relevant pages that are miss when no links from the starting URLs. There is some relevant pages are miss. To address this problem we design a focused crawler where calculating the frequency of the topic keyword also calculate the synonyms and sub synonyms of the keyword. The weight table is constructed according to the user query. To check the similarity of web pages with respect to topic keywords and priority of extracted link is calculated. -

Distributed Indexing/Searching Workshop Agenda, Attendee List, and Position Papers
Distributed Indexing/Searching Workshop Agenda, Attendee List, and Position Papers Held May 28-19, 1996 in Cambridge, Massachusetts Sponsored by the World Wide Web Consortium Workshop co-chairs: Michael Schwartz, @Home Network Mic Bowman, Transarc Corp. This workshop brings together a cross-section of people concerned with distributed indexing and searching, to explore areas of common concern where standards might be defined. The Call For Participation1 suggested particular focus on repository interfaces that support efficient and powerful distributed indexing and searching. There was a great deal of interest in this workshop. Because of our desire to limit attendance to a workable size group while maximizing breadth of attendee backgrounds, we limited attendance to one person per position paper, and furthermore we limited attendance to one person per institution. In some cases, attendees submitted multiple position papers, with the intention of discussing each of their projects or ideas that were relevant to the workshop. We had not anticipated this interpretation of the Call For Participation; our intention was to use the position papers to select participants, not to provide a forum for enumerating ideas and projects. As a compromise, we decided to choose among the submitted papers and allow multiple position papers per person and per institution, but to restrict attendance as noted above. Hence, in the paper list below there are some cases where one author or institution has multiple position papers. 1 http://www.w3.org/pub/WWW/Search/960528/cfp.html 1 Agenda The Distributed Indexing/Searching Workshop will span two days. The first day's goal is to identify areas for potential standardization through several directed discussion sessions. -

Natural Language Processing Technique for Information Extraction and Analysis
International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 2, Issue 8, August 2015, PP 32-40 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Natural Language Processing Technique for Information Extraction and Analysis T. Sri Sravya1, T. Sudha2, M. Soumya Harika3 1 M.Tech (C.S.E) Sri Padmavati Mahila Visvavidyalayam (Women’s University), School of Engineering and Technology, Tirupati. [email protected] 2 Head (I/C) of C.S.E & IT Sri Padmavati Mahila Visvavidyalayam (Women’s University), School of Engineering and Technology, Tirupati. [email protected] 3 M. Tech C.S.E, Assistant Professor, Sri Padmavati Mahila Visvavidyalayam (Women’s University), School of Engineering and Technology, Tirupati. [email protected] Abstract: In the current internet era, there are a large number of systems and sensors which generate data continuously and inform users about their status and the status of devices and surroundings they monitor. Examples include web cameras at traffic intersections, key government installations etc., seismic activity measurement sensors, tsunami early warning systems and many others. A Natural Language Processing based activity, the current project is aimed at extracting entities from data collected from various sources such as social media, internet news articles and other websites and integrating this data into contextual information, providing visualization of this data on a map and further performing co-reference analysis to establish linkage amongst the entities. Keywords: Apache Nutch, Solr, crawling, indexing 1. INTRODUCTION In today’s harsh global business arena, the pace of events has increased rapidly, with technological innovations occurring at ever-increasing speed and considerably shorter life cycles. -

Distributed Web Crawling Using Network Coordinates
Distributed Web Crawling Using Network Coordinates Barnaby Malet Department of Computing Imperial College London [email protected] Supervisor: Peter Pietzuch Second Marker: Emil Lupu June 16, 2009 2 Abstract In this report we will outline the relevant background research, the design, the implementation and the evaluation of a distributed web crawler. Our system is innovative in that it assigns Euclidean coordinates to crawlers and web servers such that the distances in the space give an accurate prediction of download times. We will demonstrate that our method gives the crawler the ability to adapt and compensate for changes in the underlying network topology, and in doing so can achieve significant decreases in download times when compared with other approaches. 3 4 Acknowledgements Firstly, I would like to thank Peter Pietzuch for the help that he has given me throughout the course of the project as well as showing me support when things did not go to plan. Secondly, I would like to thank Johnathan Ledlie for helping me with some aspects of the implemen- tation involving the Pyxida library. I would also like to thank the PlanetLab support team for giving me extensive help in dealing with complaints from web masters. Finally, I would like to thank Emil Lupu for providing me with feedback about my Outsourcing Report. 5 6 Contents 1 Introduction 9 2 Background 13 2.1 Web Crawling . 13 2.1.1 Web Crawler Architecture . 14 2.1.2 Issues in Web Crawling . 16 2.1.3 Discussion . 17 2.2 Crawler Assignment Strategies . 17 2.2.1 Hash Based . -

Panacea D4.1
SEVENTH FRAMEWORK PROGRAMME THEME 3 Information and communication Technologies PANACEA Project Grant Agreement no.: 248064 Platform for Automatic, Normalized Annotation and Cost-Effective Acquisition of Language Resources for Human Language Technologies D4.1 Technologies and tools for corpus creation, normalization and annotation Dissemination Level: Public Delivery Date: July 16, 2010 Status – Version: Final Author(s) and Affiliation: Prokopis Prokopidis, Vassilis Papavassiliou (ILSP), Pavel Pecina (DCU), Laura Rimel, Thierry Poibeau (UCAM), Roberto Bartolini, Tommaso Caselli, Francesca Frontini (ILC- CNR), Vera Aleksic, Gregor Thurmair (Linguatec), Marc Poch Riera, Núria Bel (UPF), Olivier Hamon (ELDA) Technologies and tools for corpus creation, normalization and annotation Table of contents 1 Introduction ........................................................................................................................... 3 2 Terminology .......................................................................................................................... 3 3 Corpus Acquisition Component ............................................................................................ 3 3.1 Task description ........................................................................................................... 4 3.2 State of the art .............................................................................................................. 4 3.3 Existing tools .............................................................................................................. -

Analysis and Evaluation of the Link and Content Based Focused Treasure-Crawler Ali Seyfi 1,2
Analysis and Evaluation of the Link and Content Based Focused Treasure-Crawler Ali Seyfi 1,2 1Department of Computer Science School of Engineering and Applied Sciences The George Washington University Washington, DC, USA. 2Centre of Software Technology and Management (SOFTAM) School of Computer Science Faculty of Information Science and Technology Universiti Kebangsaan Malaysia (UKM) Kuala Lumpur, Malaysia [email protected] Abstract— Indexing the Web is becoming a laborious task for search engines as the Web exponentially grows in size and distribution. Presently, the most effective known approach to overcome this problem is the use of focused crawlers. A focused crawler applies a proper algorithm in order to detect the pages on the Web that relate to its topic of interest. For this purpose we proposed a custom method that uses specific HTML elements of a page to predict the topical focus of all the pages that have an unvisited link within the current page. These recognized on-topic pages have to be sorted later based on their relevance to the main topic of the crawler for further actual downloads. In the Treasure-Crawler, we use a hierarchical structure called the T-Graph which is an exemplary guide to assign appropriate priority score to each unvisited link. These URLs will later be downloaded based on this priority. This paper outlines the architectural design and embodies the implementation, test results and performance evaluation of the Treasure-Crawler system. The Treasure-Crawler is evaluated in terms of information retrieval criteria such as recall and precision, both with values close to 0.5. Gaining such outcome asserts the significance of the proposed approach. -

Effective Focused Crawling Based on Content and Link Structure Analysis
(IJCSIS) International Journal of Computer Science and Information Security, Vol. 2, No. 1, June 2009 Effective Focused Crawling Based on Content and Link Structure Analysis Anshika Pal, Deepak Singh Tomar, S.C. Shrivastava Department of Computer Science & Engineering Maulana Azad National Institute of Technology Bhopal, India Emails: [email protected] , [email protected] , [email protected] Abstract — A focused crawler traverses the web selecting out dependent ontology, which in turn strengthens the metric used relevant pages to a predefined topic and neglecting those out of for prioritizing the URL queue. The Link-Structure-Based concern. While surfing the internet it is difficult to deal with method is analyzing the reference-information among the pages irrelevant pages and to predict which links lead to quality pages. to evaluate the page value. This kind of famous algorithms like In this paper, a technique of effective focused crawling is the Page Rank algorithm [5] and the HITS algorithm [6]. There implemented to improve the quality of web navigation. To check are some other experiments which measure the similarity of the similarity of web pages w.r.t. topic keywords, a similarity page contents with a specific subject using special metrics and function is used and the priorities of extracted out links are also reorder the downloaded URLs for the next crawl [7]. calculated based on meta data and resultant pages generated from focused crawler. The proposed work also uses a method for A major problem faced by the above focused crawlers is traversing the irrelevant pages that met during crawling to that it is frequently difficult to learn that some sets of off-topic improve the coverage of a specific topic. -
Report for Portal Specific
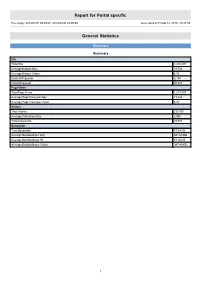
Report for Portal specific Time range: 2013/01/01 00:00:07 - 2013/03/31 23:59:59 Generated on Fri Apr 12, 2013 - 18:27:59 General Statistics Summary Summary Hits Total Hits 1,416,097 Average Hits per Day 15,734 Average Hits per Visitor 6.05 Cached Requests 8,154 Failed Requests 70,823 Page Views Total Page Views 1,217,537 Average Page Views per Day 13,528 Average Page Views per Visitor 5.21 Visitors Total Visitors 233,895 Average Visitors per Day 2,598 Total Unique IPs 49,753 Bandwidth Total Bandwidth 77.49 GB Average Bandwidth per Day 881.68 MB Average Bandwidth per Hit 57.38 KB Average Bandwidth per Visitor 347.40 KB 1 Activity Statistics Daily Daily Visitors 4,000 3,500 3,000 2,500 2,000 Visitors 1,500 1,000 500 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Hits 40,000 35,000 30,000 25,000 Hits 20,000 15,000 10,000 5,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date 2 Daily Bandwidth 1,300,000 1,200,000 1,100,000 1,000,000 900,000 800,000 700,000 600,000 500,000 Bandwidth (KB) 400,000 300,000 200,000 100,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Activity Date Hits Page Views Visitors Average Visit Length Bandwidth (KB) Sun 2013/02/10 11,783 10,245 2,280 13:01 648,207 Mon 2013/02/11 16,454 14,146 2,484 10:05 906,702 Tue 2013/02/12 19,572 17,089 3,062 07:47 926,190 Wed 2013/02/13 14,554 12,402 2,824 06:09 958,951 Thu 2013/02/14 12,577 10,666 2,690 05:03 821,129 Fri 2013/02/15 15,806 12,697 2,868 07:02 1,208,095 Sat 2013/02/16 16,811 14,939 -

The Google Search Engine
University of Business and Technology in Kosovo UBT Knowledge Center Theses and Dissertations Student Work Summer 6-2010 The Google search engine Ganimete Perçuku Follow this and additional works at: https://knowledgecenter.ubt-uni.net/etd Part of the Computer Sciences Commons Faculty of Computer Sciences and Engineering The Google search engine (Bachelor Degree) Ganimete Perçuku – Hasani June, 2010 Prishtinë Faculty of Computer Sciences and Engineering Bachelor Degree Academic Year 2008 – 2009 Student: Ganimete Perçuku – Hasani The Google search engine Supervisor: Dr. Bekim Gashi 09/06/2010 This thesis is submitted in partial fulfillment of the requirements for a Bachelor Degree Abstrakt Përgjithësisht makina kërkuese Google paraqitet si sistemi i kompjuterëve të projektuar për kërkimin e informatave në ueb. Google mundohet t’i kuptojë kërkesat e njerëzve në mënyrë “njerëzore”, dhe t’iu kthej atyre përgjigjen në formën të qartë. Por, ky synim nuk është as afër ideales dhe realizimi i tij sa vjen e vështirësohet me zgjerimin eksponencial që sot po përjeton ueb-i. Google, paraqitet duke ngërthyer në vetvete shqyrtimin e pjesëve që e përbëjnë, atyre në të cilat sistemi mbështetet, dhe rrethinave tjera që i mundësojnë sistemit të funksionojë pa probleme apo të përtërihet lehtë nga ndonjë dështim eventual. Procesi i grumbullimit të të dhënave ne Google dhe paraqitja e tyre në rezultatet e kërkimit ngërthen në vete regjistrimin e të dhënave nga ueb-faqe të ndryshme dhe vendosjen e tyre në rezervuarin e sistemit, përkatësisht në bazën e të dhënave ku edhe realizohen pyetësorët që kthejnë rezultatet e radhitura në mënyrën e caktuar nga algoritmi i Google.