Detection and Classification of Web Robots with Honeypots
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Study of Web Crawler and Its Different Types
IOSR Journal of Computer Engineering (IOSR-JCE) e-ISSN: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 1, Ver. VI (Feb. 2014), PP 01-05 www.iosrjournals.org Study of Web Crawler and its Different Types Trupti V. Udapure1, Ravindra D. Kale2, Rajesh C. Dharmik3 1M.E. (Wireless Communication and Computing) student, CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India 2Asst Prof., CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India, 3Asso.Prof. & Head, IT Department, Yeshwantrao Chavan College of Engineering, Nagpur, India, Abstract : Due to the current size of the Web and its dynamic nature, building an efficient search mechanism is very important. A vast number of web pages are continually being added every day, and information is constantly changing. Search engines are used to extract valuable Information from the internet. Web crawlers are the principal part of search engine, is a computer program or software that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. It is an essential method for collecting data on, and keeping in touch with the rapidly increasing Internet. This Paper briefly reviews the concepts of web crawler, its architecture and its various types. Keyword: Crawling techniques, Web Crawler, Search engine, WWW I. Introduction In modern life use of internet is growing in rapid way. The World Wide Web provides a vast source of information of almost all type. Now a day’s people use search engines every now and then, large volumes of data can be explored easily through search engines, to extract valuable information from web. -
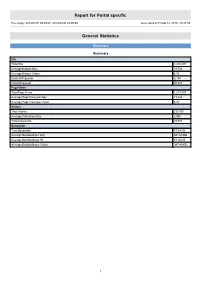
Report for Portal Specific
Report for Portal specific Time range: 2013/01/01 00:00:07 - 2013/03/31 23:59:59 Generated on Fri Apr 12, 2013 - 18:27:59 General Statistics Summary Summary Hits Total Hits 1,416,097 Average Hits per Day 15,734 Average Hits per Visitor 6.05 Cached Requests 8,154 Failed Requests 70,823 Page Views Total Page Views 1,217,537 Average Page Views per Day 13,528 Average Page Views per Visitor 5.21 Visitors Total Visitors 233,895 Average Visitors per Day 2,598 Total Unique IPs 49,753 Bandwidth Total Bandwidth 77.49 GB Average Bandwidth per Day 881.68 MB Average Bandwidth per Hit 57.38 KB Average Bandwidth per Visitor 347.40 KB 1 Activity Statistics Daily Daily Visitors 4,000 3,500 3,000 2,500 2,000 Visitors 1,500 1,000 500 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Hits 40,000 35,000 30,000 25,000 Hits 20,000 15,000 10,000 5,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date 2 Daily Bandwidth 1,300,000 1,200,000 1,100,000 1,000,000 900,000 800,000 700,000 600,000 500,000 Bandwidth (KB) 400,000 300,000 200,000 100,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Activity Date Hits Page Views Visitors Average Visit Length Bandwidth (KB) Sun 2013/02/10 11,783 10,245 2,280 13:01 648,207 Mon 2013/02/11 16,454 14,146 2,484 10:05 906,702 Tue 2013/02/12 19,572 17,089 3,062 07:47 926,190 Wed 2013/02/13 14,554 12,402 2,824 06:09 958,951 Thu 2013/02/14 12,577 10,666 2,690 05:03 821,129 Fri 2013/02/15 15,806 12,697 2,868 07:02 1,208,095 Sat 2013/02/16 16,811 14,939 -

Crawling Frontier Controls
Nutch – ApacheCon US '09 Web-scale search engine toolkit search Web-scale Today and tomorrow Today Apache Andrzej Białecki [email protected] Nutch – ApacheCon US '09 • • • Questions answers and future Nutch present and solutions)some (and Challenges Nutchworkflow: Nutcharchitecture overview general Web in crawling project the About Searching Crawling Setup Agenda 2 Nutch – ApacheCon US '09 • • Collections typically 1 mln - 200 mln documents mln Collections -typically 200 1 mln search mostly vertical in operation, installations Many Spin-offs: (sub-project Lucene) of Apache project since 2004 Mike Cafarella creator, and Lucene bythe Cutting, Doug 2003 in Founded Content type detection and parsing Tika → Map-Reduce and distributed → Hadoop FS Apache Nutch project 3 Nutch – ApacheCon US '09 4 Nutch – ApacheCon US '09 first, random Traversal: depth- breadth-first, edges, the follow listsas Oftenadjacency represented (neighbor) <alabels: href=”..”>anchor Edge text</a> Edges (links): hyperlinks like <a href=”targetUrl”/> Nodes (vertices):URL-s identifiers as unique 6 2 8 1 3 Web as a directed graph 5 4 7 9 7 →3, 4, 8, 9 5 →6, 9 1 →2, 3, 4, 5, 6 5 Nutch – ApacheCon US '09 … What's in a search engine? a fewa things may surprisethat you! 6 Nutch – ApacheCon US '09 Injector -links(in/out) - Web graph pageinfo Search engine building blocks Scheduler Updater Crawling frontierCrawling controls Crawler repository Content Searcher Indexer Parser 7 Nutch – ApacheCon US '09 Robust API and integration options Robust APIintegration and Full-text&indexer search engine processingdata framework Scalable Robustcontrols frontier crawling processing (parsing, content filtering) Plugin-based crawler distributed multi-threaded, Multi-protocol, modular: highly Plugin-based, graph) (web link database and database Page − − − − Support Support for search distributed or Using Lucene Solr Map-reduce processing Mostvia plugins be behavior can changed Nutch features at a glance 8 Hadoop foundation File system abstraction • Local FS, or • Distributed FS − also Amazon S3, Kosmos and other FS impl. -

The Google Search Engine
University of Business and Technology in Kosovo UBT Knowledge Center Theses and Dissertations Student Work Summer 6-2010 The Google search engine Ganimete Perçuku Follow this and additional works at: https://knowledgecenter.ubt-uni.net/etd Part of the Computer Sciences Commons Faculty of Computer Sciences and Engineering The Google search engine (Bachelor Degree) Ganimete Perçuku – Hasani June, 2010 Prishtinë Faculty of Computer Sciences and Engineering Bachelor Degree Academic Year 2008 – 2009 Student: Ganimete Perçuku – Hasani The Google search engine Supervisor: Dr. Bekim Gashi 09/06/2010 This thesis is submitted in partial fulfillment of the requirements for a Bachelor Degree Abstrakt Përgjithësisht makina kërkuese Google paraqitet si sistemi i kompjuterëve të projektuar për kërkimin e informatave në ueb. Google mundohet t’i kuptojë kërkesat e njerëzve në mënyrë “njerëzore”, dhe t’iu kthej atyre përgjigjen në formën të qartë. Por, ky synim nuk është as afër ideales dhe realizimi i tij sa vjen e vështirësohet me zgjerimin eksponencial që sot po përjeton ueb-i. Google, paraqitet duke ngërthyer në vetvete shqyrtimin e pjesëve që e përbëjnë, atyre në të cilat sistemi mbështetet, dhe rrethinave tjera që i mundësojnë sistemit të funksionojë pa probleme apo të përtërihet lehtë nga ndonjë dështim eventual. Procesi i grumbullimit të të dhënave ne Google dhe paraqitja e tyre në rezultatet e kërkimit ngërthen në vete regjistrimin e të dhënave nga ueb-faqe të ndryshme dhe vendosjen e tyre në rezervuarin e sistemit, përkatësisht në bazën e të dhënave ku edhe realizohen pyetësorët që kthejnë rezultatet e radhitura në mënyrën e caktuar nga algoritmi i Google. -

Web Crawling, Analysis and Archiving
Web Crawling, Analysis and Archiving Vangelis Banos Aristotle University of Thessaloniki Faculty of Sciences School of Informatics Doctoral dissertation under the supervision of Professor Yannis Manolopoulos October 2015 Ανάκτηση, Ανάλυση και Αρχειοθέτηση του Παγκόσμιου Ιστού Ευάγγελος Μπάνος Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης Σχολή Θετικών Επιστημών Τμήμα Πληροφορικής Διδακτορική Διατριβή υπό την επίβλεψη του Καθηγητή Ιωάννη Μανωλόπουλου Οκτώβριος 2015 i Web Crawling, Analysis and Archiving PhD Dissertation ©Copyright by Vangelis Banos, 2015. All rights reserved. The Doctoral Dissertation was submitted to the the School of Informatics, Faculty of Sci- ences, Aristotle University of Thessaloniki. Defence Date: 30/10/2015. Examination Committee Yannis Manolopoulos, Professor, Department of Informatics, Aristotle University of Thes- saloniki, Greece. Supervisor Apostolos Papadopoulos, Assistant Professor, Department of Informatics, Aristotle Univer- sity of Thessaloniki, Greece. Advisory Committee Member Dimitrios Katsaros, Assistant Professor, Department of Electrical & Computer Engineering, University of Thessaly, Volos, Greece. Advisory Committee Member Athena Vakali, Professor, Department of Informatics, Aristotle University of Thessaloniki, Greece. Anastasios Gounaris, Assistant Professor, Department of Informatics, Aristotle University of Thessaloniki, Greece. Georgios Evangelidis, Professor, Department of Applied Informatics, University of Mace- donia, Greece. Sarantos Kapidakis, Professor, Department of Archives, Library Science and Museology, Ionian University, Greece. Abstract The Web is increasingly important for all aspects of our society, culture and economy. Web archiving is the process of gathering digital materials from the Web, ingesting it, ensuring that these materials are preserved in an archive, and making the collected materials available for future use and research. Web archiving is a difficult problem due to organizational and technical reasons. We focus on the technical aspects of Web archiving. -

Scalability and Efficiency Challenges in Large-Scale Web Search
5/1/14 Scalability and Efficiency Challenges in Large-Scale Web Search Engines " Ricardo Baeza-Yates" B. Barla Cambazoglu! Yahoo Labs" Barcelona, Spain" Disclaimer Dis •# This talk presents the opinions of the authors. It does not necessarily reflect the views of Yahoo Inc. or any other entity." •# Algorithms, techniques, features, etc. mentioned here might or might not be in use by Yahoo or any other company." •# Some non-technical material (e.g., images) provided in this presentation were taken from the Web." 1 5/1/14 Yahoo Labs Barcelona •# Research topics" •# Web retrieval" –# web data mining" –# distributed web retrieval" –# semantic search" –# scalability and efficiency" –# social media" –# opinion/sentiment retrieval" –# web retrieval" –# personalization" Outline of the Tutorial •# Background (35 minutes)" •# Main sections" –# web crawling (75 minutes + 5 minutes Q/A)" –# indexing (75 minutes + 5 minutes Q/A)" –# query processing (90 minutes + 5 minutes Q/A)" –# caching (40 minutes + 5 minutes Q/A)" •# Concluding remarks (10 minutes)" •# Questions and open discussion (15 minutes)" 2 5/1/14 Structure of Main Sections •# Definitions" •# Metrics" •# Issues and techniques" –# single computer" –# cluster of computers" –# multiple search sites" •# Research problems" Background 3 5/1/14 Brief History of Search Engines •# Past" -# Before browsers" -# Gopher" -# Before the bubble" -# Altavista" -# Lycos" -# Infoseek" -# Excite" -# HotBot" •# Current" •# Future" -# After the bubble" •# Global" •# Facebook ?" -# Yahoo" •# Google, Bing" •# …" -

Detecting Malicious Websites with Low-Interaction Honeyclients
Monkey-Spider: Detecting Malicious Websites with Low-Interaction Honeyclients Ali Ikinci Thorsten Holz Felix Freiling University of Mannheim Mannheim, Germany Abstract: Client-side attacks are on the rise: malicious websites that exploit vulner- abilities in the visitor’s browser are posing a serious threat to client security, compro- mising innocent users who visit these sites without having a patched web browser. Currently, there is neither a freely available comprehensive database of threats on the Web nor sufficient freely available tools to build such a database. In this work, we in- troduce the Monkey-Spider project [Mon]. Utilizing it as a client honeypot, we portray the challenge in such an approach and evaluate our system as a high-speed, Internet- scale analysis tool to build a database of threats found in the wild. Furthermore, we evaluate the system by analyzing different crawls performed during a period of three months and present the lessons learned. 1 Introduction The Internet is growing and evolving every day. More and more people are becoming part of the so-called Internet community. With this growth, also the amount of threats for these people is increasing. Online criminals who want to destroy, cheat, con others, or steal goods are evolving rapidly [Ver03]. Currently, there is no comprehensive and free database to study malicious websites found on the Internet. Malicious websites are websites which have any kind of content that could be a threat for the security of the clients requesting these sites. For example, a malicious website could exploit a vulnerability in the visitor’s web browser and use this to compromise the system and install malware on it. -

Web Manifestations of Knowledge-Based Innovation Systems in the U.K
Web Manifestations of Knowledge-based Innovation Systems in the U.K. David Patrick Stuart B.A.(hons) A thesis submitted in partial fulfilment of the requirements of the University of Wolverhampton for the degree of Doctor of Philosophy January 2008 This work or any part thereof has not previously been presented in any form to the University or to any other body whether for the purposes of assessment, publication or for any other purpose (unless otherwise indicated). Save for any express acknowledgments, references and/or bibliographies cited in the work, I confirm that the intellectual content of the work is the result of my own efforts and of no other person. The right of David Stuart to be identified as author of this work is asserted in accordance with ss.77 and 78 of the Copyright, Designs and Patents Act 1988. At this date copyright is owned by the author. Signature……………………………………….. Date…………………………………………….. Publication List Journal Papers: Stuart, D., & Thelwall, M. (2006). Investigating triple helix relationships using URL citations: a case study of the UK West Midlands automobile industry. Research Evaluation, 15(2), 97-106. Stuart, D., Thelwall, M., & Harries, G. (2007). UK academic web links and collaboration – an exploratory study. Journal of Information Science, 33(2), 231-246. Thelwall, M., & Stuart, D. (2006). Web crawling ethics revisited: Cost, privacy, and denial of service. Journal of the American Society for Information Science and Technology, 57(13), 1771-1779. Conference Papers: Stuart, D., & Thelwall, M. (2005). What can university-to-government web links reveal about university-government collaborations? In P. Ingwersen, & B. -

A Focused Web Crawler Driven by Self-Optimizing Classifiers
A Focused Web Crawler Driven by Self-Optimizing Classifiers Master’s Thesis Dominik Sobania Original title: A Focused Web Crawler Driven by Self-Optimizing Classifiers German title: Fokussiertes Webcrawling mit selbstorganisierenden Klassifizierern Master’s Thesis Submitted by Dominik Sobania Submission date: 09/25/2015 Supervisor: Prof. Dr. Chris Biemann Coordinator: Steffen Remus TU Darmstadt Department of Computer Science, Language Technology Group Erklärung Hiermit versichere ich, die vorliegende Master’s Thesis ohne Hilfe Dritter und nur mit den angegebe- nen Quellen und Hilfsmitteln angefertigt zu haben. Alle Stellen, die aus den Quellen entnommen wur- den, sind als solche kenntlich gemacht worden. Diese Arbeit hat in dieser oder ähnlicher Form noch keiner Prüfungsbehörde vorgelegen. Die schriftliche Fassung stimmt mit der elektronischen Fassung überein. Darmstadt, den 25. September 2015 Dominik Sobania i Zusammenfassung Üblicherweise laden Web-Crawler alle Dokumente herunter, die von einer begrenzten Menge Seed- URLs aus erreichbar sind. Für die Generierung von Corpora ist eine Breitensuche allerdings nicht effizient, da uns hier nur ein bestimmtes Thema interessiert. Ein fokussierter Crawler besucht verlinkte Dokumente, die von einer Entscheidungsfunktion ausgewählt wurden, mit höherer Priorität. Dieser Ansatz fokussiert sich selbst auf das gesuchte Thema. In dieser Masterarbeit beschreiben wir einen Ansatz für fokussiertes Crawling, der als erster Schritt für die Generierung von Corpora genutzt werden kann. Basierend auf einem kleinen Satz an Textdoku- menten, die das gesuchte Thema definieren, erstellt eine Pipeline, bestehend aus mehreren Klassifizier- ern, die Trainingsdaten für einen Hyperlink-Klassifizierer – die Entscheidungsfunktion des fokussierten Crawlers. Für die Optimierung der Klassifizierer benutzen wir einen evolutionären Algorithmus für die Feature Subset Selection. Die Chromosomen des evolutionären Algorithmus basieren auf einer serial- isierbaren Baumstruktur. -

Data-Intensive Text Processing with Mapreduce
Data-Intensive Text Processing with MapReduce Synthesis Lectures on Human Language Technologies Editor Graeme Hirst, University of Toronto Synthesis Lectures on Human Language Technologies is edited by Graeme Hirst of the University of Toronto.The series consists of 50- to 150-page monographs on topics relating to natural language processing, computational linguistics, information retrieval, and spoken language understanding. Emphasis is on important new techniques, on new applications, and on topics that combine two or more HLT subfields. Data-Intensive Text Processing with MapReduce Jimmy Lin and Chris Dyer 2010 Semantic Role Labeling Martha Palmer, Daniel Gildea, and Nianwen Xue 2010 Spoken Dialogue Systems Kristiina Jokinen and Michael McTear 2009 Introduction to Chinese Natural Language Processing Kam-Fai Wong, Wenjie Li, Ruifeng Xu, and Zheng-sheng Zhang 2009 Introduction to Linguistic Annotation and Text Analytics Graham Wilcock 2009 Dependency Parsing Sandra Kübler, Ryan McDonald, and Joakim Nivre 2009 Statistical Language Models for Information Retrieval ChengXiang Zhai 2008 Copyright © 2010 by Morgan & Claypool All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means—electronic, mechanical, photocopy, recording, or any other except for brief quotations in printed reviews, without the prior permission of the publisher. Data-Intensive Text Processing with MapReduce Jimmy Lin and Chris Dyer www.morganclaypool.com ISBN: 9781608453429 paperback ISBN: -

Bachelor of Library and Information Science (Blisc.)
Bachelor of Library and Information Science (B.L.I.Sc.) Goa University Goa University Library, Taleigao Plateau Goa PIN 403 206 Website: www.unigoa.ac.in Tel: 0832-6519072/272/087, Fax: 0832-2451184 Bachelor of Library and Information Science (B.L.I.Sc.) Programme Duration of the Programme : One Year Programme (Credit based two semesters) Objectives of the Programme : • To train students for a professional career in Library and Information Services • To produce a quality manpower for collection, compilation and dissemination of information products and services in and beyond conventional libraries and information centres Number of seats : 25 Availability and Reservation of Seats Total number seats available for admission are 25. University shall allocate seats as per State Government/University policy. Accordingly, the distribution of seats will be as follows. Sl No Category Seats 1 OBC 7 2 SC 1 3 ST 3 4 Differentially abled 1 5 General 11 6 Other Universities 2 Total 25 Qualification for admission : Graduates in any faculty like Languages and Literature, Social sciences, Commerce, Natural Sciences, Life Sciences and Environment, Engineering, Medicine, etc with minimum 40% aggregate marks at their graduation from any recognized university in India or abroad are eligible to apply for the B.L.I.Sc. Evaluation : The assessment of the Programmes comprises of continuous Intra-Semester Assessment (ISA) and Semester End Assessment (SEA) and is done fully internally. Fee details : For Outside Item For Goa University Students Students Tuition Fee 18900 18900 Reg. Fee (GU Students) 500 0 (Outside Students) 0 2300 Gym, Stud. Union, ID Card 410 410 Student Aid Fund 120 120 Computer Lab facility 810 810 Annual Internet Fee 230 230 Annual Library Fee 460 460 Caution Deposit (Refundable) 1750 1750 Total 23180 24980 Curriculum details : Curriculum details for B.L.I.Sc. -

Report Per Parmadaily 2009 PDF
Report per ParmaDaily 2009 PDF Intervallo di tempo: 01/01/2009 01:00:01 - 31/12/2009 23:59:54 Generato Lun Apr 12, 2010 - 18:58:58 Statistiche Generali Sommario Sommario Hits Hits Totali 54,508,672 Media Hits per Giorno 149,338 Media Hits per Visitatore 18.40 Richieste Memorizzate 16,245,901 Richieste Fallite 174,116 Pagine Viste Pagine Visitate Totali 6,764,252 Media Pagine Visitate per Giorno 18,532 Media Pagine Visitate per Visitatore 2.28 Visitatori Visitatori Totali 2,961,644 Media Visitatori per Giorno 8,114 IP Univoci Totali 1,608,739 Banda Banda Totale 632.65 GB Banda Media per Giorno 1.73 GB Banda Media per Hit 12.17 KB Banda Media per Visitatore 223.99 KB 1 Statistiche Attività Giornaliera Visitatori Giornalieri 20,000 18,000 16,000 14,000 12,000 10,000 Visitatori 8,000 6,000 4,000 2,000 0 01/02/2009 01/04/2009 01/06/2009 01/08/2009 01/10/2009 01/12/2009 Data Hits Giornaliere 400,000 350,000 300,000 250,000 Hits 200,000 150,000 100,000 50,000 0 01/02/2009 01/04/2009 01/06/2009 01/08/2009 01/10/2009 01/12/2009 Data 2 Banda Giornaliera 4,000,000 3,500,000 3,000,000 2,500,000 2,000,000 Banda (KB) 1,500,000 1,000,000 500,000 0 01/02/2009 01/04/2009 01/06/2009 01/08/2009 01/10/2009 01/12/2009 Data Attività Giornaliera Data Hits Pagine Viste Visitatori Lunghezza Media della Visita Banda (KB) Gio 12/11/2009 181,857 24,969 11,221 02:24 2,181,207 Ven 13/11/2009 183,722 26,136 10,937 02:38 2,232,270 Sab 14/11/2009 102,799 18,120 10,470 02:03 1,532,877 Dom 15/11/2009 99,988 18,326 11,300 02:02 1,529,790 Lun 16/11/2009 166,856 23,796 10,204