Nemətli Nemət Vüqar Oğlu
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -

Study of Web Crawler and Its Different Types
IOSR Journal of Computer Engineering (IOSR-JCE) e-ISSN: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 1, Ver. VI (Feb. 2014), PP 01-05 www.iosrjournals.org Study of Web Crawler and its Different Types Trupti V. Udapure1, Ravindra D. Kale2, Rajesh C. Dharmik3 1M.E. (Wireless Communication and Computing) student, CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India 2Asst Prof., CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India, 3Asso.Prof. & Head, IT Department, Yeshwantrao Chavan College of Engineering, Nagpur, India, Abstract : Due to the current size of the Web and its dynamic nature, building an efficient search mechanism is very important. A vast number of web pages are continually being added every day, and information is constantly changing. Search engines are used to extract valuable Information from the internet. Web crawlers are the principal part of search engine, is a computer program or software that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. It is an essential method for collecting data on, and keeping in touch with the rapidly increasing Internet. This Paper briefly reviews the concepts of web crawler, its architecture and its various types. Keyword: Crawling techniques, Web Crawler, Search engine, WWW I. Introduction In modern life use of internet is growing in rapid way. The World Wide Web provides a vast source of information of almost all type. Now a day’s people use search engines every now and then, large volumes of data can be explored easily through search engines, to extract valuable information from web. -

Easy Slackware
1 Создание легкой системы на базе Slackware I - Введение Slackware пользуется заслуженной популярностью как классический linux дистрибутив, и поговорка "кто знает Red Hat тот знает только Red Hat, кто знает Slackware тот знает linux" несмотря на явный снобизм поклонников "бога Патре га" все же имеет под собой основания. Одним из преимуществ Slackware является возможность простого создания на ее основе практически любой системы, в том числе быстрой и легкой десктопной, о чем далее и пойдет речь. Есть дис трибутивы, клоны Slackware, созданные именно с этой целью, типа Аbsolute, но все же лучше создавать систему под себя, с максимальным учетом именно своих потребностей, и Slackware пожалуй как никакой другой дистрибутив подходит именно для этой цели. Легкость и быстрота системы определяется выбором WM (DM) , набором программ и оптимизацией программ и системы в целом. Первое исключает KDE, Gnome, даже новые версии XFCЕ, остается разве что LXDE, но набор программ в нем совершенно не устраивает. Оптимизация наиболее часто используемых про грамм и нескольких базовых системных пакетов осуществляется их сборкой из сорцов компилятором, оптимизированным именно под Ваш комп, причем каж дая программа конфигурируется исходя из Ваших потребностей к ее возможно стям. Оптимизация системы в целом осуществляется ее настройкой согласно спе цифическим требованиям к десктопу. Такой подход был выбран по банальной причине, возиться с gentoo нет ни какого желания, комп все таки создан для того чтобы им пользоваться, а не для компиляции программ, в тоже время у каждого есть минимальный набор из не большого количества наиболее часто используемых программ, на которые стоит потратить некоторое, не такое уж большое, время, чтобы довести их до ума. Кро ме того, такой подход позволяет иметь самые свежие версии наиболее часто ис пользуемых программ. -

Awareness and Utilization of Search Engines for Information Retrieval by Students of National Open University of Nigeria in Enugu Study Centre Library
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Library Philosophy and Practice (e-journal) Libraries at University of Nebraska-Lincoln 2020 Awareness and Utilization of Search Engines for Information Retrieval by Students of National Open University of Nigeria in Enugu Study Centre Library SUNDAY JUDE ONUH National Open University of Nigeria, [email protected] OGOEGBUNAM LOVETH EKWUEME National Open University of Nigeria, [email protected] Follow this and additional works at: https://digitalcommons.unl.edu/libphilprac Part of the Library and Information Science Commons ONUH, SUNDAY JUDE and EKWUEME, OGOEGBUNAM LOVETH, "Awareness and Utilization of Search Engines for Information Retrieval by Students of National Open University of Nigeria in Enugu Study Centre Library" (2020). Library Philosophy and Practice (e-journal). 4650. https://digitalcommons.unl.edu/libphilprac/4650 Awareness and Utilization of Search Engines for Information Retrieval by Students of National Open University of Nigeria in Enugu Study Centre Library By Jude Sunday Onuh Enugu Study Centre Library National Open University of Nigeria [email protected] & Loveth Ogoegbunam Ekwueme Department of Library and Information Science National Open University of Nigeria [email protected] Abstract This study dwelt on awareness and utilization of search engines for information retrieval by students of National Open University of Nigeria (NOUN) Enugu Study centre. Descriptive survey research was adopted for the study. Two research questions were drawn from the two purposes that guided the study. The population consists of 5855 undergraduate students of NOUN Enugu Study Centre. A sample size of 293 students was used as 5% of the entire population. -

Further Reading and What's Next
APPENDIX Further Reading and What’s Next I hope you have gotten an idea of how, as a penetration tester, you could test a web application and find its security flaws by hunting bugs. In this concluding chapter, we will see how we can extend our knowledge of what we have learned so far. In the previous chapter, we saw how SQL injection has been done; however, we have not seen the automated part of SQL injection, which can be done by other tools alongside Burp Suite. We will use sqlmap, a very useful tool, for this purpose. Tools that Can Be Used Alongside Burp Suite We have seen earlier that the best alternative to Burp Suite is OWASP ZAP. Where Burp Community edition has some limitations, ZAP can help you overcome them. Moreover, ZAP is an open source free tool; it is community-based, so you don’t have to pay for it for using any kind of advanced technique. We have also seen how ZAP works. Here, we will therefore concentrate on sqlmap only, another very useful tool we need for bug hunting. The sqlmap is command line based. It comes with Kali Linux by default. You can just open your terminal and start scanning by using sqlmap. However, as always, be careful about using it against any live © Sanjib Sinha 2019 197 S. Sinha, Bug Bounty Hunting for Web Security, https://doi.org/10.1007/978-1-4842-5391-5 APPENDIX FuRtHeR Reading and What’s Next system; don’t use it without permission. If your client’s web application has vulnerabilities, you can use sqlmap to detect the database, table names, columns, and even read the contents inside. -

Special Report Internet Portal Sites in Korea
www.ica.or.kr March~April 2006 (ISSUE 18) Special Report Internet Portal Sites in Korea Review Korea Mobile Communications in 2005 Marketing & Strategy Focus on LBS Industry Hwiyoung Chae International Cooperation NHN CEO Agency for Korea IT Publisher’s Column IT Korea journal March~April 2006 1 Booming Internet Portals Soon to Go Global That Korea is the world’s broadband leader is organized into sections by media types. The video no longer an arguable fact. The internet wave, search, a feature that has recently been added on, is sweeping across Korea since the 1990s, has made it generating a tremendous buzz, and setting a whole- into the world’s most networked nation. Korea’s new trend in the worldwide search market. reputation is especially peerless in online gaming. Korea’s state-of-the-art mobile infrastructure Needless to say, this amazing internet boom could technology provides its search portals yet another not have been possible without Korea’s advanced platform with a potentially vast market. The wide Sunbae Kim broadband environment. Meanwhile, Korean penetration of mobile phone, PDA and other wire- ICA President internet users, savvier than their counterparts else- less devices in the country has been accelerating where in the world, are also more demanding growth in its wireless portal market in recent years. when it comes to service quality. Korea’s hard-to- Many Korean portals, judging the time now ripe for please consumers were indeed instrumental in overseas expansion, are laying out the game plan. taking the country’s internet industry to its present Heavyweights like Naver and SK Communications heyday, providing sticks as well as carrots to spur have already opened or are in the process of R&D and force innovations in businesses. -

Creating Permanent Test Collections of Web Pages for Information Extraction Research*
Creating Permanent Test Collections of Web Pages for Information Extraction Research* Bernhard Pollak and Wolfgang Gatterbauer Database and Artificial Intelligence Group Vienna University of Technology, Austria {pollak, gatter}@dbai.tuwien.ac.at Abstract. In the research area of automatic web information extraction, there is a need for permanent and annotated web page collections enabling objective performance evaluation of different algorithms. Currently, researchers are suffering from the absence of such representative and contemporary test collections, especially on web tables. At the same time, creating your own sharable web page collections is not trivial nowadays because of the dynamic and diverse nature of modern web technologies employed to create often short- lived online content. In this paper, we cover the problem of creating static representations of web pages in order to build sharable ground truth test sets. We explain the principal difficulties of the problem, discuss possible approaches and introduce our solution: WebPageDump, a Firefox extension capable of saving web pages exactly as they are rendered online. Finally, we benchmark our system with current alternatives using an innovative automatic method based on image snapshots. Keywords: saving web pages, web information extraction, test data, Firefox, web table ground truth, performance evaluation 1 Introduction In the visions of a future Semantic Web, agents will crawl the web for information related to a given task. With the current web lacking semantic annotation, researchers are working on automatic information extraction systems that allow transforming heterogonous and semi-structured information into structured databases that can be later queried for data analysis. For testing purposes researchers need representative and annotated ground truth test data sets in order to benchmark different extraction algorithms against each other. -

Digicult.Info Issue 6
.Info Issue 6 A Newsletter on Digital Culture ISSN 1609-3941 December 2003 INTRODUCTION his is a rich issue of DigiCULT.Info covering topics in such Tareas as digitisation, asset management and publication, virtual reality, documentation, digital preservation, and the development of the knowledge society. n October the Italian Presidency of the European Union pro- Imoted, in cooperation with the European Commission and the ERPANET (http://www.erpanet.org) and MINERVA Continued next page (UofGlasgow),© HATII Ross, Seamus 2003 Technology explained and applied ... Challenges, strategic issues, new initiatives ... 6 3D-ArchGIS:Archiving Cultural Heritage 16 New Open-source Software for Content in a 3D Multimedia Space and Repository Management 10 Zope at Duke University: Open Source Content 19 The IRCAM Digital Sound Archive in Context Management in a Higher Education Context 55 Towards a Knowledge Society 16 PLEADE – EAD for the Web 31 Metadata Debate:Two Perspectives on Dublin Core News from DigiCULT´s Regional Correspondents ... 34 Cistercians in Yorkshire: Creating a Virtual Heritage Learning Package 37 Bulgaria 45 SMIL Explained 38 Czech Republic 47 Finding Names with the Autonom Parser 40 France 49 The Object of Learning:Virtual and Physical 41 Greece Cultural Heritage Interactions 42 Italy News, events ... 44 Poland 44 Serbia and Montenegro 23 Delivering The Times Digital Archive 30 NZ Electronic Text Centre 37 Cultural Heritage Events Action in the Preservation of Memory ... 52 New Project Highlights the Growing Use of DOIs 24 PANDORA,Australia’s -

2008 Asia Web Trends
btrax White Papers 2008 Asia Web Trends btrax, Inc. San Francisco, CA btrax White Papers ASIA OVERVIEW Summary A long-standing pioneer in mobile technology, the Asian region has matured into a dominant force in the growing online economy. This voracious rise has been fueled by the dropping cost of web access and exten- sive new infrastructure investments. An increased focus on web strategies by Asian businesses has also sparked a wave of native startups capable of taking on and beating giants such as Google. China, Japan and Korea have all experienced rapid increases in broadband con- nectivity and the number of Internet users. Key trend indicators only point upwards as Asia’s Internet penetration rates still average only 15% compared to 30% in the rest of the world. These three countries also collectively represent the largest mobile phone subscriber base in the world, mirroring their break- neck growth in desktop-based Internet usage. Economists have highlighted that more people online does not automatically translate to Asian users follow- ing the online habits of their Western counterparts. As businesses’ reliance on online revenue climbs, user ex- perience, localization and cross-cultural branding become increasingly critical for growth and success. Engaging non-English speaking audiences not only reaches target country audi- ences, but also taps the large pools of immigrants and expatriates abroad. The business opportunities stemming from that are most apparent in the United Want to know more? Please visit www.btrax.com or email us at [email protected] ©2008 btrax, Inc. All rights reserved. Reproduction in whole or in part in any form or 2 medium without express written permission of btrax, Inc. -

Cluster Setup Guide
Frontera Documentation Release 0.8.0.1 ScrapingHub Jul 30, 2018 Contents 1 Introduction 3 1.1 Frontera at a glance...........................................3 1.2 Run modes................................................5 1.3 Quick start single process........................................6 1.4 Quick start distributed mode.......................................8 1.5 Cluster setup guide............................................ 10 2 Using Frontera 15 2.1 Installation Guide............................................ 15 2.2 Crawling strategies............................................ 16 2.3 Frontier objects.............................................. 16 2.4 Middlewares............................................... 19 2.5 Canonical URL Solver.......................................... 22 2.6 Backends................................................. 23 2.7 Message bus............................................... 27 2.8 Writing custom crawling strategy.................................... 30 2.9 Using the Frontier with Scrapy...................................... 35 2.10 Settings.................................................. 37 3 Advanced usage 51 3.1 What is a Crawl Frontier?........................................ 51 3.2 Graph Manager.............................................. 52 3.3 Recording a Scrapy crawl........................................ 58 3.4 Fine tuning of Frontera cluster...................................... 59 3.5 DNS Service............................................... 60 4 Developer documentation 63 4.1 -

Frontera Documentation Release 0.4.0
Frontera Documentation Release 0.4.0 ScrapingHub December 30, 2015 Contents 1 Introduction 3 1.1 Frontera at a glance...........................................3 1.2 Run modes................................................5 1.3 Quick start single process........................................6 1.4 Quick start distributed mode.......................................8 2 Using Frontera 11 2.1 Installation Guide............................................ 11 2.2 Frontier objects.............................................. 11 2.3 Middlewares............................................... 12 2.4 Canonical URL Solver.......................................... 13 2.5 Backends................................................. 14 2.6 Message bus............................................... 16 2.7 Crawling strategy............................................. 17 2.8 Using the Frontier with Scrapy...................................... 17 2.9 Settings.................................................. 20 3 Advanced usage 31 3.1 What is a Crawl Frontier?........................................ 31 3.2 Graph Manager.............................................. 32 3.3 Recording a Scrapy crawl........................................ 38 3.4 Production broad crawling........................................ 40 4 Developer documentation 45 4.1 Architecture overview.......................................... 45 4.2 Frontera API............................................... 47 4.3 Using the Frontier with Requests.................................... 49 4.4 -
Report for Portal Specific
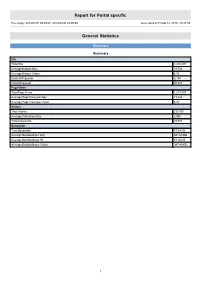
Report for Portal specific Time range: 2013/01/01 00:00:07 - 2013/03/31 23:59:59 Generated on Fri Apr 12, 2013 - 18:27:59 General Statistics Summary Summary Hits Total Hits 1,416,097 Average Hits per Day 15,734 Average Hits per Visitor 6.05 Cached Requests 8,154 Failed Requests 70,823 Page Views Total Page Views 1,217,537 Average Page Views per Day 13,528 Average Page Views per Visitor 5.21 Visitors Total Visitors 233,895 Average Visitors per Day 2,598 Total Unique IPs 49,753 Bandwidth Total Bandwidth 77.49 GB Average Bandwidth per Day 881.68 MB Average Bandwidth per Hit 57.38 KB Average Bandwidth per Visitor 347.40 KB 1 Activity Statistics Daily Daily Visitors 4,000 3,500 3,000 2,500 2,000 Visitors 1,500 1,000 500 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Hits 40,000 35,000 30,000 25,000 Hits 20,000 15,000 10,000 5,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date 2 Daily Bandwidth 1,300,000 1,200,000 1,100,000 1,000,000 900,000 800,000 700,000 600,000 500,000 Bandwidth (KB) 400,000 300,000 200,000 100,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Activity Date Hits Page Views Visitors Average Visit Length Bandwidth (KB) Sun 2013/02/10 11,783 10,245 2,280 13:01 648,207 Mon 2013/02/11 16,454 14,146 2,484 10:05 906,702 Tue 2013/02/12 19,572 17,089 3,062 07:47 926,190 Wed 2013/02/13 14,554 12,402 2,824 06:09 958,951 Thu 2013/02/14 12,577 10,666 2,690 05:03 821,129 Fri 2013/02/15 15,806 12,697 2,868 07:02 1,208,095 Sat 2013/02/16 16,811 14,939