Good Bot, Bad Bot: Characterizing Automated Browsing Activity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Study of Web Crawler and Its Different Types
IOSR Journal of Computer Engineering (IOSR-JCE) e-ISSN: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 1, Ver. VI (Feb. 2014), PP 01-05 www.iosrjournals.org Study of Web Crawler and its Different Types Trupti V. Udapure1, Ravindra D. Kale2, Rajesh C. Dharmik3 1M.E. (Wireless Communication and Computing) student, CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India 2Asst Prof., CSE Department, G.H. Raisoni Institute of Engineering and Technology for Women, Nagpur, India, 3Asso.Prof. & Head, IT Department, Yeshwantrao Chavan College of Engineering, Nagpur, India, Abstract : Due to the current size of the Web and its dynamic nature, building an efficient search mechanism is very important. A vast number of web pages are continually being added every day, and information is constantly changing. Search engines are used to extract valuable Information from the internet. Web crawlers are the principal part of search engine, is a computer program or software that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. It is an essential method for collecting data on, and keeping in touch with the rapidly increasing Internet. This Paper briefly reviews the concepts of web crawler, its architecture and its various types. Keyword: Crawling techniques, Web Crawler, Search engine, WWW I. Introduction In modern life use of internet is growing in rapid way. The World Wide Web provides a vast source of information of almost all type. Now a day’s people use search engines every now and then, large volumes of data can be explored easily through search engines, to extract valuable information from web. -

Application Development with Tocollege.Net
CYAN YELLOW MAGENTA BLACK PANTONE 123 C BOOKS FOR PROFESSIONALS BY PROFESSIONALS® THE EXPERT’S VOICE® IN WEB DEVELOPMENT Companion eBook Available Covers Pro Web 2.0 Application GWT 1.5 Pro Development with GWT 2.0 Web Dear Reader, This book is for developers who are ready to move beyond small proof-of-concept Pro sample applications and want to look at the issues surrounding a real deploy- ment of GWT. If you want to see what the guts of a full-fledged GWT application look like, this is the book for you. GWT 1.5 is a game-changing technology, but it doesn’t exist in a bubble. Real deployments need to connect to your database, enforce authentication, protect against security threats, and allow good search engine optimization. To show you all this, we’ll look at the code behind a real, live web site called Application Development with ToCollege.net. This application specializes in helping students who are applying Web 2.0 to colleges; it allows them to manage their application processes and compare the rankings that they give to schools. It’s a slick application that’s ready for you to sign up for and use. Application Development This book will give you a walking tour of this modern Web 2.0 start-up’s code- base. The included source code will provide a functional demonstration of how to merge together the modern Java stack including Hibernate, Spring Security, Spring MVC 2.5, SiteMesh, and FreeMarker. This fully functioning application is better than treasure if you’re a developer trying to wire GWT into a Maven build environment who just wants to see some code that makes it work. -

It's All About Visibility
8 It’s All About Visibility This chapter looks at the critical tasks for getting your message found on the web. Now that we’ve discussed how to prepare a clear targeted message using the right words (Chapter 5, “The Audience Is Listening (What Will You Say?)”), we describe how online visibility depends on search engine optimization (SEO) “eat your broccoli” basics, such as lightweight and crawlable website code, targeted content with useful labels, and inlinks. In addition, you can raise the visibility of your website, products, and services online through online advertising such as paid search advertising, outreach through social websites, and display advertising. 178 Part II Building the Engine Who Sees What and How Two different tribes visit your website: people, and entities known as web spiders (or crawlers or robots). People will experience your website differently based on their own characteristics (their visual acuity or impairment), their browser (Internet Explorer, Chrome, Firefox, and so on), and the machine they’re using to view your website (a TV, a giant computer monitor, a laptop screen, or a mobile phone). Figure 8.1 shows a page on a website as it appears to website visitors through a browser. Figure 8.1 Screenshot of a story page on Model D, a web magazine about Detroit, Michigan, www.modeldmedia.com. What Search Engine Spiders See The web spiders are computer programs critical to your business because they help people who don’t know about your website through your marketing efforts find it through the search engines. The web spiders “crawl” through your website to learn about what it contains and carry information back to the gigantic servers behind the search engines, so that the search engine can provide relevant results to people searching for your product or service. -
![Google Cheat Sheets [.Pdf]](https://docslib.b-cdn.net/cover/9906/google-cheat-sheets-pdf-999906.webp)
Google Cheat Sheets [.Pdf]
GOOGLE | CHEAT SHEET Key for skill required Novice This two page Google Cheat Sheet lists all Google services and tools as to understand the Intermediate well as background information. The Cheat Sheet offers a great reference underlying concepts to grasp of basic to advance Google query building concepts and ideas. Expert CHEAT SHEET GOOGLE SERVICES Google domains google.co.kr Google Company Information google.ae google.kz Public (NASDAQ: GOOG) and google.com.af google.li (LSE: GGEA) Google AdSense https://www.google.com/adsense/ google.com.ag google.lk google.off.ai google.co.ls Founded Google AdWords https://adwords.google.com/ google.am google.lt Menlo Park, California (1998) Google Analytics http://google.com/analytics/ google.com.ar google.lu google.as google.lv Location Google Answers http://answers.google.com/ google.at google.com.ly Mountain View, California, USA Google Base http://base.google.com/ google.com.au google.mn google.az google.ms Key people Google Blog Search http://blogsearch.google.com/ google.ba google.com.mt Eric E. Schmidt Google Bookmarks http://www.google.com/bookmarks/ google.com.bd google.mu Sergey Brin google.be google.mw Larry E. Page Google Books Search http://books.google.com/ google.bg google.com.mx George Reyes Google Calendar http://google.com/calendar/ google.com.bh google.com.my google.bi google.com.na Revenue Google Catalogs http://catalogs.google.com/ google.com.bo google.com.nf $6.138 Billion USD (2005) Google Code http://code.google.com/ google.com.br google.com.ni google.bs google.nl Net Income Google Code Search http://www.google.com/codesearch/ google.co.bw google.no $1.465 Billion USD (2005) Google Deskbar http://deskbar.google.com/ google.com.bz google.com.np google.ca google.nr Employees Google Desktop http://desktop.google.com/ google.cd google.nu 5,680 (2005) Google Directory http://www.google.com/dirhp google.cg google.co.nz google.ch google.com.om Contact Address Google Earth http://earth.google.com/ google.ci google.com.pa 2400 E. -

The Top 10 Ddos Attack Trends
WHITE PAPER The Top 10 DDoS Attack Trends Discover the Latest DDoS Attacks and Their Implications Introduction The volume, size and sophistication of distributed denial of service (DDoS) attacks are increasing rapidly, which makes protecting against these threats an even bigger priority for all enterprises. In order to better prepare for DDoS attacks, it is important to understand how they work and examine some of the most widely-used tactics. What Are DDoS Attacks? A DDoS attack may sound complicated, but it is actually quite easy to understand. A common approach is to “swarm” a target server with thousands of communication requests originating from multiple machines. In this way the server is completely overwhelmed and cannot respond anymore to legitimate user requests. Another approach is to obstruct the network connections between users and the target server, thus blocking all communication between the two – much like clogging a pipe so that no water can flow through. Attacking machines are often geographically-distributed and use many different internet connections, thereby making it very difficult to control the attacks. This can have extremely negative consequences for businesses, especially those that rely heavily on its website; E-commerce or SaaS-based businesses come to mind. The Open Systems Interconnection (OSI) model defines seven conceptual layers in a communications network. DDoS attacks mainly exploit three of these layers: network (layer 3), transport (layer 4), and application (layer 7). Network (Layer 3/4) DDoS Attacks: The majority of DDoS attacks target the network and transport layers. Such attacks occur when the amount of data packets and other traffic overloads a network or server and consumes all of its available resources. -
Report for Portal Specific
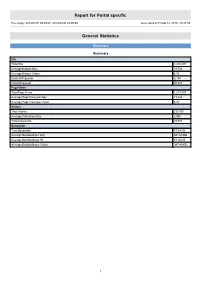
Report for Portal specific Time range: 2013/01/01 00:00:07 - 2013/03/31 23:59:59 Generated on Fri Apr 12, 2013 - 18:27:59 General Statistics Summary Summary Hits Total Hits 1,416,097 Average Hits per Day 15,734 Average Hits per Visitor 6.05 Cached Requests 8,154 Failed Requests 70,823 Page Views Total Page Views 1,217,537 Average Page Views per Day 13,528 Average Page Views per Visitor 5.21 Visitors Total Visitors 233,895 Average Visitors per Day 2,598 Total Unique IPs 49,753 Bandwidth Total Bandwidth 77.49 GB Average Bandwidth per Day 881.68 MB Average Bandwidth per Hit 57.38 KB Average Bandwidth per Visitor 347.40 KB 1 Activity Statistics Daily Daily Visitors 4,000 3,500 3,000 2,500 2,000 Visitors 1,500 1,000 500 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Hits 40,000 35,000 30,000 25,000 Hits 20,000 15,000 10,000 5,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date 2 Daily Bandwidth 1,300,000 1,200,000 1,100,000 1,000,000 900,000 800,000 700,000 600,000 500,000 Bandwidth (KB) 400,000 300,000 200,000 100,000 0 2013/01/01 2013/01/15 2013/02/01 2013/02/15 2013/03/01 2013/03/15 Date Daily Activity Date Hits Page Views Visitors Average Visit Length Bandwidth (KB) Sun 2013/02/10 11,783 10,245 2,280 13:01 648,207 Mon 2013/02/11 16,454 14,146 2,484 10:05 906,702 Tue 2013/02/12 19,572 17,089 3,062 07:47 926,190 Wed 2013/02/13 14,554 12,402 2,824 06:09 958,951 Thu 2013/02/14 12,577 10,666 2,690 05:03 821,129 Fri 2013/02/15 15,806 12,697 2,868 07:02 1,208,095 Sat 2013/02/16 16,811 14,939 -

How Can I Get Deep App Screens Indexed for Google Search?
HOW CAN I GET DEEP APP SCREENS INDEXED FOR GOOGLE SEARCH? Setting up app indexing for Android and iOS apps is pretty straightforward and well documented by Google. Conceptually, it is a three-part process: 1. Enable your app to handle deep links. 2. Add code to your corresponding Web pages that references deep links. 3. Optimize for private indexing. These steps can be taken out of order if the app is still in development, but the second step is crucial. Without it, your app will be set up with deep links but not set up for Google indexing, so the deep links will not show up in Google Search. NOTE: iOS app indexing is still in limited release with Google, so there is a special form submission and approval process even after you have added all the technical elements to your iOS app. That being said, the technical implementations take some time; by the time your company has finished, Google may have opened up indexing to all iOS apps, and this cumbersome approval process may be a thing of the past. Steps For Google Deep Link Indexing Step 1: Add Code To Your App That Establishes The Deep Links A. Pick A URL Scheme To Use When Referencing Deep Screens In Your App App URL schemes are simply a systematic way to reference the deep linked screens within an app, much like a Web URL references a specific page on a website. In iOS, developers are currently limited to using Custom URL Schemes, which are formatted in a way that is more natural for app design but different from Web. -

Diseño De Sistemas Distribuidos: Google
+ Sistemas Distribuidos Diseño de Sistemas Distribuidos: Google Rodrigo Santamaría Diseño de Sistemas +Distribuidos • Introducción: Google como caso de estudio • Servicios • Plataforma • Middleware 2 + 3 Introducción Crear un sistema distribuido no es sencillo Objetivo: obtener un sistema consistente que cumpla con los requisitos identificados Escala, seguridad, disponibilidad, etc. Elección del modelo Tipo de fallos que asumimos Tipo de arquitectura Elección de la infraestructura Middleware (RMI, REST, Kademlia, etc.) Protocolos existentes (LDAP, HTTP, etc.) + 4 Introducción Google como caso de estudio Google es un ejemplo de un diseño distribuido exitoso Ofrece búsquedas en Internet y aplicaciones web Obtiene beneficios principalmente de la publicidad asociada Objetivo: “organizar la información mundial y hacerla universalmente accesible y útil” Nació a partir de un proyecto de investigación en la Universidad de Stanford, convirtiéndose en compañía con sede en California en 1998. Una parte de su éxito radica en el algoritmo de posicionamiento utilizado por su motor de búsqueda El resto, en un sistema distribuido eficiente y altamente escalable + 5 Introducción Requisitos Google se centra en cuatro desafíos Escalabilidad: un sistema distribuido con varios subsistemas, dando servicio a millones de usuarios Fiabilidad: el sistema debe funcionar en todo momento Rendimiento: cuanto más rápida sea la búsqueda, más búsquedas podrá hacer el usuario -> mayor exposición a la publicidad Transparencia: en cuanto a la capacidad -

Applications: G
Applications: G This chapter contains the following sections: • G4, on page 5 • GACP, on page 6 • Gaia Online, on page 7 • Game Center, on page 8 • Game Front, on page 9 • Game Informer, on page 10 • GamerCom, on page 11 • GAMERSKY, on page 12 • GameSpot, on page 13 • GameSpy, on page 14 • GameStop, on page 15 • GameTrailers, on page 16 • Ganglia, on page 17 • Ganji, on page 18 • Gantter, on page 19 • Garmin, on page 20 • Gateway, on page 21 • Gawker, on page 22 • Gazprom Media, on page 23 • Gbridge, on page 24 • gdomap, on page 25 • GDS DataBase, on page 26 • GearBest, on page 27 • Geewa, on page 28 • Geico, on page 29 • generic audio/video, on page 30 • Genesis PPP, on page 31 • Genie, on page 32 • Genieo, on page 33 • Genieo Web Filter, on page 34 • GENRAD, on page 35 • Gfycat, on page 36 Applications: G 1 Applications: G • GG, on page 37 • GG Media, on page 38 • GGP, on page 39 • Ghaneely, on page 40 • GIFSoup.com, on page 41 • giFT, on page 42 • Giganews, on page 43 • ginad, on page 44 • GIOP, on page 45 • GIPHY, on page 46 • GISMETEO, on page 47 • GIST, on page 48 • GitHub, on page 49 • Gizmodo, on page 50 • GKrellM, on page 51 • Glide, on page 52 • Globo, on page 53 • Glympse, on page 54 • Glype, on page 55 • Glype Proxy, on page 56 • Gmail, on page 57 • Gmail attachment, on page 58 • GMTP, on page 59 • GMX Mail, on page 60 • GNOME, on page 61 • GNU Generation Foundation NCP 678, on page 62 • GNU Project, on page 63 • Gnucleus, on page 64 • GnucleusLAN, on page 65 • Gnutella, on page 66 • Gnutella2, on page 67 • GO.com, on page -

Field Vs. Google, Inc
Case 2:04-cv-00413-RCJ-GWF Document 64 Filed 01/19/2006 Page 1 of 25 1 2 3 4 5 6 7 8 9 10 . 11 UNITED STATES DISTRICT COURT 12 DISTRICT OF NEVADA 13 14 BLAKE A. FIELD, ) NO. CV-S-04-0413-RCJ-LRL ) 15 Plaintiff, ) ) FINDINGS OF FACT AND 16 vs. ) CONCLUSIONS OF LAW ) 17 GOOGLE INC., ) & ) 18 Defendant. ) ) ORDER 19 ) ) 20 ) ) 21 AND RELATED COUNTERCLAIMS. ) ) 22 ) ) 23 ) ) 24 25 26 27 28 FINDINGS OF FACT AND CONCLUSIONS OF LAW Case 2:04-cv-00413-RCJ-GWF Document 64 Filed 01/19/2006 Page 2 of 25 1 FINDINGS OF FACT AND CONCLUSIONS OF LAW 2 This is an action for copyright infringement brought by plaintiff Blake Field (“Field”) 3 against Google Inc. (“Google”). Field contends that by allowing Internet users to access copies 4 of 51 of his copyrighted works stored by Google in an online repository, Google violated Field’s 5 exclusive rights to reproduce copies and distribute copies of those works. On December 19, 6 2005, the Court heard argument on the parties’ cross-motions for summary judgment. 7 Based upon the papers submitted by the parties and the arguments of counsel, the Court 8 finds that Google is entitled to judgment as a matter of law based on the undisputed facts. For 9 the reasons set forth below, the Court will grant Google’s motion for summary judgment: (1) that 10 it has not directly infringed the copyrighted works at issue; (2) that Google held an implied 11 license to reproduce and distribute copies of the copyrighted works at issue; (3) that Field is 12 estopped from asserting a copyright infringement claim against Google with respect to the works 13 at issue in this action; and (4) that Google’s use of the works is a fair use under 17 U.S.C. -

Appendix I: Search Quality and Economies of Scale
Appendix I: search quality and economies of scale Introduction 1. This appendix presents some detailed evidence concerning how general search engines compete on quality. It also examines network effects, scale economies and other barriers to search engines competing effectively on quality and other dimensions of competition. 2. This appendix draws on academic literature, submissions and internal documents from market participants. Comparing quality across search engines 3. As set out in Chapter 3, the main way that search engines compete for consumers is through various dimensions of quality, including relevance of results, privacy and trust, and social purpose or rewards.1 Of these dimensions, the relevance of search results is generally considered to be the most important. 4. In this section, we present consumer research and other evidence regarding how search engines compare on the quality and relevance of search results. Evidence on quality from consumer research 5. We reviewed a range of consumer research produced or commissioned by Google or Bing, to understand how consumers perceive the quality of these and other search engines. The following evidence concerns consumers’ overall quality judgements and preferences for particular search engines: 6. Google submitted the results of its Information Satisfaction tests. Google’s Information Satisfaction tests are quality comparisons that it carries out in the normal course of its business. In these tests, human raters score unbranded search results from mobile devices for a random set of queries from Google’s search logs. • Google submitted the results of 98 tests from the US between 2017 and 2020. Google outscored Bing in each test; the gap stood at 8.1 percentage points in the most recent test and 7.3 percentage points on average over the period. -

Scalability and Efficiency Challenges in Large-Scale Web Search
5/1/14 Scalability and Efficiency Challenges in Large-Scale Web Search Engines " Ricardo Baeza-Yates" B. Barla Cambazoglu! Yahoo Labs" Barcelona, Spain" Disclaimer Dis •# This talk presents the opinions of the authors. It does not necessarily reflect the views of Yahoo Inc. or any other entity." •# Algorithms, techniques, features, etc. mentioned here might or might not be in use by Yahoo or any other company." •# Some non-technical material (e.g., images) provided in this presentation were taken from the Web." 1 5/1/14 Yahoo Labs Barcelona •# Research topics" •# Web retrieval" –# web data mining" –# distributed web retrieval" –# semantic search" –# scalability and efficiency" –# social media" –# opinion/sentiment retrieval" –# web retrieval" –# personalization" Outline of the Tutorial •# Background (35 minutes)" •# Main sections" –# web crawling (75 minutes + 5 minutes Q/A)" –# indexing (75 minutes + 5 minutes Q/A)" –# query processing (90 minutes + 5 minutes Q/A)" –# caching (40 minutes + 5 minutes Q/A)" •# Concluding remarks (10 minutes)" •# Questions and open discussion (15 minutes)" 2 5/1/14 Structure of Main Sections •# Definitions" •# Metrics" •# Issues and techniques" –# single computer" –# cluster of computers" –# multiple search sites" •# Research problems" Background 3 5/1/14 Brief History of Search Engines •# Past" -# Before browsers" -# Gopher" -# Before the bubble" -# Altavista" -# Lycos" -# Infoseek" -# Excite" -# HotBot" •# Current" •# Future" -# After the bubble" •# Global" •# Facebook ?" -# Yahoo" •# Google, Bing" •# …"