Annexe 5. Éléments D'interprétation Du Topic Model
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

C Powerclmlluling
C PowerClmlluling Everything you need to know about setting up and operating your PowerTower Pro™ system Ma(OS Mac and the Mac OS logo are trademal1<s of Apple Computer, Inc., used under license. Part number 72810 Rev. number 960823 erPro User' ide Part number 72810 Rev. number 960823 Power Computing Corporation © 1996 Power Computing Corporation. All rights reserved. Under copyright laws, this manual may not be copied, in whole or in part, without the written consent of Power Computing. Your rights to the software are governed by the accompanying software license agreement. Power Computing Corporation 2555 North Interstate 35 Round Rock, Texas 78664-2015 (512) 388-6868 Power Computing, the Power Computing logo, PowerTower, and PowerTower Pro are trademarks of Power Computing Corporation. Mac and the Mac as logo are trademarks of Apple Computer, Inc. All other trademarks mentioned are the property of their respective holders. Every effort has been made in this book to distinguish proprietary trademarks from descriptive terms by following the capitalization style used by the manufacturer. Every effort has been made to ensure that the information in this manual is accurate. Power Computing is not responsible for printing or clerical errors. Warranty information about your system may be found beginning on page xv. Other legal notices are found in "Regulatory Information" on page 151. PowerTower Pro User's Guide For Technical Support, Call 1-800-708-6227 Support Information For basic customer and technical support information, as well as product information and other news, visit our Web Site at: http://www.powercc.com Direct or Dealer Support? Customers who purchased systems directly from Power Computing should contact Power Computing for assistance. -

Factors and Impacts in the Information Society a Prospective Analysis in the Candidate Countries
FACTORS AND IMPACTS IN THE INFORMATION SOCIETY A PROSPECTIVE ANALYSIS IN THE CANDIDATE COUNTRIES REPORT ON ROMANIA Authors: Alexandru Caragea, Radu Gheorghiu, and Geomina Turlea The authors of this report are solely responsible for the content, style, language and editorial control. The views expressed do not necessarily reflect those of the European Commission. January, 2003 Technical Report EUR 21279 EN European Commission Joint Research Centre (DG JRC) Institute for Prospective Technological Studies http://www.jrc.es Legal notice Neither the European Commission nor any person acting on behalf of the Commission is responsible for the use which might be made of the following information. Technical Report EUR 21279 EN © European Communities, 2004 Reproduction is authorised provided the source is acknowledged. Printed in Spain 2 FACTORS AND IMPACTS IN THE INFORMATION SOCIETY A PROSPECTIVE ANALYSIS IN THE CANDIDATE COUNTRIES Acknowledgements Acknowledgements: We are indebted to RALUCA MIRON (Raiffaisen Bank), for her valuable contribution to this work. REPORT ON ROMANIA 3 Preface Preface The Institute for Prospective Technological Studies (IPTS) of the Directorate General Joint Research Centre of the European Commission contracted the International Centre for Economic Growth, European Centre (ICEG EC) to act as the coordinator of a consortium of 11 research institutes to carry out this project. The main objective of the project was to provide a series of national monographs studying the development of the Information Society (IS), including both the positive and negative impacts, in each of the candidate countries. These monographs offer an assessment of the strengths and weaknesses of each country regarding the development of IS, and a view on their possible outcomes; both strongly rooted in factual quantitative data. -

List of British Entities That Are No Longer Authorised to Provide Services in Spain As from 1 January 2021
LIST OF BRITISH ENTITIES THAT ARE NO LONGER AUTHORISED TO PROVIDE SERVICES IN SPAIN AS FROM 1 JANUARY 2021 Below is the list of entities and collective investment schemes that are no longer authorised to provide services in Spain as from 1 January 20211 grouped into five categories: Collective Investment Schemes domiciled in the United Kingdom and marketed in Spain Collective Investment Schemes domiciled in the European Union, managed by UK management companies, and marketed in Spain Entities operating from the United Kingdom under the freedom to provide services regime UK entities operating through a branch in Spain UK entities operating through an agent in Spain ---------------------- The list of entities shown below is for information purposes only and includes a non- exhaustive list of entities that are no longer authorised to provide services in accordance with this document. To ascertain whether or not an entity is authorised, consult the "Registration files” section of the CNMV website. 1 Article 13(3) of Spanish Royal Decree-Law 38/2020: "The authorisation or registration initially granted by the competent UK authority to the entities referred to in subparagraph 1 will remain valid on a provisional basis, until 30 June 2021, in order to carry on the necessary activities for an orderly termination or transfer of the contracts, concluded prior to 1 January 2021, to entities duly authorised to provide financial services in Spain, under the contractual terms and conditions envisaged”. List of entities and collective investment -

Speaker Book
Table of Contents Program 5 Speakers 9 NOAH Infographic 130 Trading Comparables 137 2 3 The NOAH Bible, an up-to-date valuation and industry KPI publication. This is the most comprehensive set of valuation comps you'll find in the industry. Reach out to us if you spot any companies or deals we've missed! March 2018 Edition (PDF) Sign up Here 4 Program 5 COLOSSEUM - Day 1 6 June 2018 SESSION TITLE COMPANY TIME COMPANY SPEAKER POSITION Breakfast 8:00 - 10:00 9:00 - 9:15 Between Tradition and Digitisation: What Old and New Economy can Learn from One Another? NOAH Advisors Marco Rodzynek Founder & CEO K ® AUTO1 Group Gerhard Cromme Chairman Facebook Martin Ott VP, MD Central Europe 9:15 - 9:25 Evaneos Eric La Bonnardière CEO CP 9:25 - 9:35 Kiwi.com Oliver Dlouhý CEO 9:35 - 9:45 HomeToGo Dr. Patrick Andrae Co-Founder & CEO FC MR Insight Venture Partners Harley Miller Vice President CP 9:45 - 9:55 GetYourGuide Johannes Reck Co-Founder & CEO MR Travel & Tourism Travel 9:55 - 10:05 Revolution Precrafted Robbie Antonio CEO FC MR FC 10:05 - 10:15 Axel Springer Dr. Mathias Döpfner CEO 10:15 - 10:40 Uber Dara Khosrowshahi CEO FC hy Christoph Keese CEO CP 10:40 - 10:50 Moovit Nir Erez Founder & CEO 10:50 - 11:00 BlaBlaCar Nicolas Brusson MR Co-Founder & CEO FC 11:00 - 11:10 Taxify Markus Villig MR Founder & CEO 11:10 - 11:20 Porsche Sebastian Wohlrapp VP Digital Business Platform 11:20 - 11:30 Drivy Paulin Dementhon CEO 11:30 - 11:40 Optibus Amos Haggiag Co-Founder & CEO 11:40 - 11:50 Blacklane Dr. -

Bloomberg Briefs
Wednesday June 8, 2016 www.bloombergbriefs.com MedMen Seeks $100 Million for Marijuana Investments QUOTED BY AINSLIE CHANDLER, BLOOMBERG BRIEF Medical cannabis management company MedMen is raising its first institutional fund "This is the toughest decision- as it tries to capitalize on investors' interest in legal marijuana enterprises. making environment that I MedMen is trying to raise $100 million for MedMen Opportunity Fund, according to think we have ever been in.... firm founder and Chief Executive Adam Bierman. Yesterday, JPMorgan comes MedMen, founded in 2009, previously acted as a management company for out and they say there is a 36 businesses with medical marijuana licenses. It also invested money from family offices and venture funds in special purpose vehicles where the investors held the cannabis percent chance of a licenses, Bierman said in a May 26 interview. recession. As a CIO or head Existing investors pushed the firm to raise a fund to allow for greater diversification in of private equity, what do you their portfolios, he said. do with that?" “If you are a multi-billion dollar family office or an institutional quality investor, you are — Glenn Youngkin, President and COO of not making one-off investments in the $3 million to $5 million range with single-asset Carlyle Group, at a conference June 7 exposure in a market that is complicated from a regulatory environment,” Bierman said. The Los Angeles-based firm held a first close on the WEEK IN NUMBERS fund in May and hopes to have a final close within six months, Bierman said. $13.5 billion — Extra return MedMen The fund will invest in cannabis-related projects, he Calstrs calculates it earned from its said. -

Die Meilensteine Der Computer-, Elek
Das Poster der digitalen Evolution – Die Meilensteine der Computer-, Elektronik- und Telekommunikations-Geschichte bis 1977 1977 1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 und ... Von den Anfängen bis zu den Geburtswehen des PCs PC-Geburt Evolution einer neuen Industrie Business-Start PC-Etablierungsphase Benutzerfreundlichkeit wird gross geschrieben Durchbruch in der Geschäftswelt Das Zeitalter der Fensterdarstellung Online-Zeitalter Internet-Hype Wireless-Zeitalter Web 2.0/Start Cloud Computing Start des Tablet-Zeitalters AI (CC, Deep- und Machine-Learning), Internet der Dinge (IoT) und Augmented Reality (AR) Zukunftsvisionen Phasen aber A. Bowyer Cloud Wichtig Zählhilfsmittel der Frühzeit Logarithmische Rechenhilfsmittel Einzelanfertigungen von Rechenmaschinen Start der EDV Die 2. Computergeneration setzte ab 1955 auf die revolutionäre Transistor-Technik Der PC kommt Jobs mel- All-in-One- NAS-Konzept OLPC-Projekt: Dass Computer und Bausteine immer kleiner, det sich Konzepte Start der entwickelt Computing für die AI- schneller, billiger und energieoptimierter werden, Hardware Hände und Finger sind die ersten Wichtige "PC-Vorläufer" finden wir mit dem werden Massenpro- den ersten Akzeptanz: ist bekannt. Bei diesen Visionen geht es um die Symbole für die Mengendarstel- schon sehr früh bei Lernsystemen. iMac und inter- duktion des Open Source Unterstüt- möglichen zukünftigen Anwendungen, die mit 3D-Drucker zung und lung. Ägyptische Illustration des Beispiele sind: Berkley Enterprice mit neuem essant: XO-1-Laptops: neuen Technologien und Konzepte ermöglicht Veriton RepRap nicht Ersatz werden. -

Game-Tech-Whitepaper
Type & Color October, 2020 INSIGHTS Game Tech How Technology is Transforming Gaming, Esports and Online Gambling Elena Marcus, Partner Sean Tucker, Partner Jonathan Weibrecht,AGC Partners Partner TableType of& ContentsColor 1 Game Tech Defined & Market Overview 2 Game Development Tools Landscape & Segment Overview 3 Online Gambling & Esports Landscape & Segment Overview 4 Public Comps & Investment Trends 5 Appendix a) Game Tech M&A Activity 2015 to 2020 YTD b) Game Tech Private Placement Activity 2015 to 2020 YTD c) AGC Update AGCAGC Partners Partners 2 ExecutiveType & Color Summary During the COVID-19 pandemic, as people are self-isolating and socially distancing, online and mobile entertainment is booming: gaming, esports, and online gambling . According to Newzoo, the global games market is expected to reach $159B in revenue in 2020, up 9.3% versus 5.3% growth in 2019, a substantial acceleration for a market this large. Mobile gaming continues to grow at an even faster pace and is expected to reach $77B in 2020, up 13.3% YoY . According to Research and Markets, the global online gambling market is expected to grow to $66 billion in 2020, an increase of 13.2% vs. 2019 spurred by the COVID-19 crisis . Esports is projected to generate $974M of revenue globally in 2020 according to Newzoo. This represents an increase of 2.5% vs. 2019. Growth was muted by the cancellation of live events; however, the explosion in online engagement bodes well for the future Tectonic shifts in technology and continued innovation have enabled access to personalized digital content anywhere . Gaming and entertainment technologies has experienced amazing advances in the past few years with billions of dollars invested in virtual and augmented reality, 3D computer graphics, GPU and CPU processing power, and real time immersive experiences Numerous disruptors are shaking up the market . -

Binary Capital Investment Management
Binary Capital Investment Management Whitepaper Disruption as an asset class: what is it, how to invest in it. Long-termism shapes our relationships and our investments January 2021 binarycapital.co.uk Disruption investing: a thematic view Summary Authored by: Is disruption a thing, a theme, an asset class? If so, what exactly is it and how can we access real disruptive investments, having it all aligned to our investment philosophy and importantly it being relevant to all client types? Real genuine opportunities that are transformative and highly exceptional. This paper sets out our thinking around disruption investing, and how we bring together such thinking into investable investment ideas and solutions. We Saftar Sarwar do not just talk about disruption in academic and entrepreneurship Chief Investment Officer terms but within an investment perspective in real active, investable portfolio management. We are active, long-term investors; this gives us an edge, a real edge – we can take a longer-term view and take positions in such disruption areas in a more optimal manner than other investment professionals. This methodology of thinking is new in wealth and asset management, we like to believe we lead the way in some of these areas. We ourselves are a ‘disruptor’ investment firm. We have alignment to how we are as a business, and how we actually invest for clients. Amir Miah Junior Portfolio Manager We believe that investment thinking should not be in narrow silos, focused on next quarters earnings or about weekly jobs data, but it should be broader, much broader. A deeper understanding of innovation and entrepreneurship can be a competitive advantage for investment professionals. -

Cryptocurrency Coin Model
Cryptocurrency Coin Model v.16 About Unikrn Unikrn was established in November of 2014. We are the only fully-regulated, licensed and dedicated esports bookmaker on the planet. Our amazing partnerships include our close relationship with Australia’s largest betting company, Tabcorp.. In 2015, we raised a total of $10,000,000 from the likes of Ashton Kutcher, Guy O’Seary, Mark Cuban, Shari Redstone, Elisabeth Murdoch, 500 Startups, Tabcorp, Indicator Ventures and Hyperspeed Ventures. Our lead investor is well-known for their early investment in Snapchat, and the partners were early to invest in many other Silicon Valley success stories, including Twitter and Instagram. They also recently launched a Financial Division, which is already one of the largest movers of cryptocurrency in the world. Unikrn has built the most technologically-advanced wagering platform for esports, including both skill-based and spectator betting products. We have also thoroughly tested the efficacy of real-money wagering in our esportsbook for both the UK and Australia. Two years ago, we created a token called “Unikoin.” Users love Unikoin because it gives them an opportunity to bet on esports, ladder up and win prizes in markets where Unikrn is not yet licensed to conduct real-money wagering. We’ve spent the past two years honing this product and enhancing the user experience. With over a quarter of a billion Unikoins turned over to date, we feel it’s time to take the platform to the next level by introducing our cryptocurrency: UnikoinGold. Our investors are excited about this coin offering and they’re putting their weight behind it – however, we are saving room for the crypto community and our userbase. -

Lnternetting -P
April 1994 $2.95 The Journal of Washington Apple Pi, Ltd. Volume 16, Number 4 lnternetting -p. 9 WordPerfect 3.0-p. 14 ~ Laser Printers -p. 18 Washington Apple Pi General Meeting 4th Saturday • 9:00 a.m. • Burning Tree Elementary School • 7900 Beech Tree Rd. Bethesda, Maryland April 23, 1994 Microsoft: FoxPro May21, 1994 Ares Software Burning• Tree E.S. DATES CHANGE! Bethesda, MD ~@W~ ~om the Beltway (I-495f take Exit 39 onto River lRoad (MD 190) inward toward DC and Bethesda approx. 1 mile. Tum left onto Beech Tree Road. ...A... Burning Tree Elementary 11111 School will be approx. 1/ 4 mile on the left . Northern Virginia ommunity College (NOVA) Table of Contents From the President Volume 16 April 1994 Number 4 TheTCS As It Evolves Club News Artist on Exhibit ........................ 26 by Lorin Evans by Blake Lange WAPHotline ........................ 39, 42 Macintosh Tutorials ................... 28 he operation of an electronic WAP Calendar ..................... 40, 41 Tutorial Registration Form ........ 29 bulletin board such as ours is a ln:dex to Advertisers .................... 2 Special Computer Offer ............. 30 T Classified Advertisements ......... 79 never-ending cycle of moderniza WAP Membership Form ............ 80 tion, expansion, and upgrade. The current TCS is a full replacement Apple II Articles for the Corvus network that was SIGs and Slices Teach a New Trick to a Venerable cajoled and coerced into the 20th Computer century. This first year of opera Stock SIG ..................................... 7 Dave & Joan Jernigan ........... 35 tion has given us a good idea as to by Morris Pelham Notes from the Apple II Vice what our members would like to see Mac Programmers' SIG .............. -

Miscellaneous Device Information
Miscellaneous Device Information Intro. Discont’d Weight Device Name Device Type Date Date (lbs.) Dimensions (inches) Device Code Name Apple PowerCD CD Player Jan 93 3.1 6.5 H x 8.6 W x 4.9 D Tulip Order #: KB #: Apple Pro Speakers Speakers Jan 01 Order #: M8282LL/A KB #: Airport BaseStation Networking Jul 99 Dec 01 1.7 3.2 H x 6.9 W x D Order #: M7601LL/B KB #: 58727 Airport Card Networking Jul 99 Order #: M7600LL/A KB #: Apple Pro Mouse Mouse Jul 00 Order #: M7697LL/A KB #: Apple Pro Keyboard Keyboard Jul 00 Order #: M7696LL/A KB #: Harman Kardon SoundSticks Speakers Order #: T2587LL/A KB #: Harman Kardon iSub Speakers 6.0 10.16 H x 9.15 W x D Order #: T2321LL/A KB #: Apple Color OneScanner 600/27 Scanner Jan 95 13.2 3.11 H x 11.29 W x 16.29 D Rio Order #: M4496LL/A KB #: 19327 Apple Desktop Bus Keyboard Keyboard 2.3 1.75 H x 16.5 W x 5.6 D Order #: KB #: 115 Apple Desktop Bus Mouse Mouse Jan 87 Dec 93 Order #: KB #: 902 Apple Extended Keyboard Keyboard Dörfer, Saratoga Order #: M0115LL/A KB #: Apple Extended Keyboard II Keyboard Jan 93 Jan 99 4.8 .75 H x 18.7 W x 7.7 D Elmer, Nimitz Order #: M0312LL/A KB #: 5214 OCTOBER 15, 2016 12:58 AM Note: n/a = information not available or not applicablePAGE 1 Database Last Modified On Miscellaneous Device Information Intro. Discont’d Weight Device Name Device Type Date Date (lbs.) Dimensions (inches) Device Code Name Apple QuickTake 100 Camera Jan 94 1.1 2.16 H x 5.31 W x 6.1 D Venus Order #: M2613LL/A KB #: 14659 Apple QuickTake 150 Camera 1.1 2.16 H x 5.31 W x 6.1 D Mars Order #: M3791LL/A -
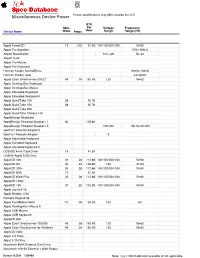
Miscellaneous Device Power Power Specifications May Differ Outside the U.S
Miscellaneous Device Power Power specifications may differ outside the U.S. BTU Max. Per Voltage Frequency Device Name Watts Amps Hour Range Range (Hz) Apple PowerCD 15 .125 51.30 100-125/200-240 50-60 Apple Pro Speakers 70Hz-20kHz Airport BaseStation 100–120 50–60 Airport Card Apple Pro Mouse Apple Pro Keyboard Harman Kardon SoundSticks 200Hz-15kHz Harman Kardon iSub 44-180Hz Apple Color OneScanner 600/27 45 .38 153.90 120 58-62 Apple Desktop Bus Keyboard Apple Desktop Bus Mouse Apple Extended Keyboard Apple Extended Keyboard II Apple QuickTake 100 28 95.76 Apple QuickTake 150 28 95.76 Apple QuickTake 200 Apple QuickTime Camera 100 AppleDesign Keyboard AppleDesign Powered Speakers I 40 136.80 AppleDesign Powered Speakers II 100-240 150 Hz-20 kHz GeoPort Telecom Adapter II GeoPort Telecom Adapter 5 Apple Adjustable Keyboard Apple Standard Keyboard Apple Standard Keyboard II DDS-DC 4mm Tape Drive 15 51.30 UniDisk-Apple 5.25 Drive AppleCD 300 33 .28 112.86 100-125/200-240 50-60 AppleCD SC 40 .33 136.80 120 47-64 AppleCD 300+ 33 .28 112.86 100-125/200-240 50-60 AppleCD 600i 15 51.30 AppleCD 600e Plus 33 .28 112.86 100-125/200-240 50-60 AppleCD 1200i AppleCD 150 30 .25 102.60 100-125/200-240 50-60 Apple Joystick //e Apple Modem 1200 Numeric Keypad IIe Apple Fax Modem 9600 10 .08 34.20 120 60 Apple Desktop Bus Mouse II Apple USB Mouse Apple USB Keyboard AppleCD 800 Apple Color OneScanner 1200/30 45 .38 153.90 120 58-62 Apple Color OneScanner for Windows 45 .38 153.90 120 58-62 AppleCD 300e Apple 3.5 Drive Apple 5.25 Drive Macintosh 800K External Disk Drive Macintosh HDI-20 External 1.4MB Floppy OCTOBER 15, 2016 12:58 AM Note: n/a = information not available or not applicable Miscellaneous Device Power Power specifications may differ outside the U.S.