Javanese Influence on Indonesian
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Surrealist Painting in Yogyakarta Martinus Dwi Marianto University of Wollongong
University of Wollongong Research Online University of Wollongong Thesis Collection University of Wollongong Thesis Collections 1995 Surrealist painting in Yogyakarta Martinus Dwi Marianto University of Wollongong Recommended Citation Marianto, Martinus Dwi, Surrealist painting in Yogyakarta, Doctor of Philosophy thesis, Faculty of Creative Arts, University of Wollongong, 1995. http://ro.uow.edu.au/theses/1757 Research Online is the open access institutional repository for the University of Wollongong. For further information contact the UOW Library: [email protected] SURREALIST PAINTING IN YOGYAKARTA A thesis submitted in fulfilment of the requirements for the award of the degree DOCTOR OF PHILOSOPHY from UNIVERSITY OF WOLLONGONG by MARTINUS DWI MARIANTO B.F.A (STSRI 'ASRT, Yogyakarta) M.F.A. (Rhode Island School of Design, USA) FACULTY OF CREATIVE ARTS 1995 CERTIFICATION I certify that this work has not been submitted for a degree to any other university or institution and, to the best of my knowledge and belief, contains no material previously published or written by any other person, except where due reference has been made in the text. Martinus Dwi Marianto July 1995 ABSTRACT Surrealist painting flourished in Yogyakarta around the middle of the 1980s to early 1990s. It became popular amongst art students in Yogyakarta, and formed a significant style of painting which generally is characterised by the use of casual juxtapositions of disparate ideas and subjects resulting in absurd, startling, and sometimes disturbing images. In this thesis, Yogyakartan Surrealism is seen as the expression in painting of various social, cultural, and economic developments taking place rapidly and simultaneously in Yogyakarta's urban landscape. -

From Arabic Style Toward Javanese Style: Comparison Between Accents of Javanese Recitation and Arabic Recitation
From Arabic Style toward Javanese Style: Comparison between Accents of Javanese Recitation and Arabic Recitation Nur Faizin1 Abstract Moslem scholars have acceptedmaqamat in reciting the Quran otherwise they have not accepted macapat as Javanese style in reciting the Quran such as recitationin the State Palace in commemoration of Isra` Miraj 2015. The paper uses a phonological approach to accents in Arabic and Javanese style in recitingthe first verse of Surah Al-Isra`. Themethod used here is analysis of suprasegmental sound (accent) by usingSpeech Analyzer programand the comparison of these accents is analyzed by descriptive method. By doing so, the author found that:first, there is not any ideological reason to reject Javanese style because both of Arabic and Javanese style have some aspects suitable and unsuitable with Ilm Tajweed; second, the suitability of Arabic style was muchthan Javanese style; third, it is not right to reject recitingthe Quran with Javanese style only based on assumption that it evokedmistakes and errors; fourth, the acceptance of Arabic style as the art in reciting the Quran should risedacceptanceof the Javanese stylealso. So, rejection of reciting the Quranwith Javanese style wasnot due to any reason and it couldnot be proofed by any logical argument. Keywords: Recitation, Arabic Style, Javanese Style, Quran. Introduction There was a controversial event in commemoration of Isra‘ Mi‘raj at the State Palacein Jakarta May 15, 2015 ago. The recitation of the Quran in the commemoration was recitedwithJavanese style (langgam).That was not common performance in relation to such as official event. Muhammad 58 Nur Faizin, From Arabic Style toward Javanese Style Yasser Arafat, a lecture of Sunan Kalijaga State Islamic University Yogyakarta has been reciting first verse of Al-Isra` by Javanese style in the front of state officials and delegationsof many countries. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
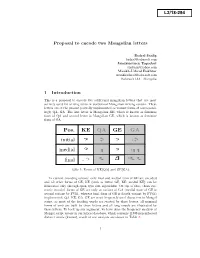
Pos. KE QA GE GA Initial ᠬ ᠭ Medial Final
Proposal to encode two Mongolian letters Badral Sanlig [email protected] Jamiyansuren Togoobat [email protected] Munkh-Uchral Enkhtur [email protected] Bolorsoft LLC, Mongolia 1 Introduction This is a proposal to encode two additional mongolian letters that are most actively used for writing texts in traditional Mongolian writing system. These letters are at the present partially implemented as variant forms of correspond- ingly QA, GA. The first letter is Mongolian KE, which is known as feminine form of QA and second letter is Mongolian GE, which is known as feminine form of GA. Pos. KE QA GE GA ᠬ ᠭ initial medial final - Table 1: Forms of KE(QA) and GE(GA). In current encoding scheme, only final and medial form of GE are encoded and all other forms of GE, KE (such as initial GE, KE, medial KE) can be illustrated only through open type font algorithms. On top of that, those cur- rently encoded forms of GE are only as variant of GA (medial form of GE is second variant by FVS1, whereas final form of GE is fourth variant by FVS3) implemented. QA, KE, GA, GE are most frequently used characters in Mongol script, as most of the heading words are started by these letters, all nominal forms of verb are built by these letters and all long vowels are illustrated by these letters. To back up our argument, we have done the frequency analysis of Mongol script letters in our lexical database, which contains 41808 non-inflected distinct words (lemma), result of our analysis are shown in Table 2. -

Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-04-22 Document version: 2.7 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract This document lays down the Label Generation Ruleset for Gurmukhi script. Three main components of the Gurmukhi Script LGR i.e. Code point repertoire, Variants and Whole Label Evaluation Rules have been described in detail here. All these components have been incorporated in a machine-readable format in the accompanying XML file named "proposal-gurmukhi-lgr-22apr19-en.xml". In addition, a document named “gurmukhi-test-labels-22apr19-en.txt” has been provided. It provides a list of labels which can produce variants as laid down in Section 6 of this document and it also provides valid and invalid labels as per the Whole Label Evaluation laid down in Section 7. 2. Script for which the LGR is proposed ISO 15924 Code: Guru ISO 15924 Key N°: 310 ISO 15924 English Name: Gurmukhi Latin transliteration of native script name: gurmukhī Native name of the script: ਗੁਰਮੁਖੀ Maximal Starting Repertoire [MSR] version: 4 1 3. Background on Script and Principal Languages Using It 3.1. The Evolution of the Script Like most of the North Indian writing systems, the Gurmukhi script is a descendant of the Brahmi script. The Proto-Gurmukhi letters evolved through the Gupta script from 4th to 8th century, followed by the Sharda script from 8th century onwards and finally adapted their archaic form in the Devasesha stage of the later Sharda script, dated between the 10th and 14th centuries. -
![Arxiv:2011.02128V1 [Cs.CL] 4 Nov 2020](https://docslib.b-cdn.net/cover/4203/arxiv-2011-02128v1-cs-cl-4-nov-2020-234203.webp)
Arxiv:2011.02128V1 [Cs.CL] 4 Nov 2020
Cross-Lingual Machine Speech Chain for Javanese, Sundanese, Balinese, and Bataks Speech Recognition and Synthesis Sashi Novitasari1, Andros Tjandra1, Sakriani Sakti1;2, Satoshi Nakamura1;2 1Nara Institute of Science and Technology, Japan 2RIKEN Center for Advanced Intelligence Project AIP, Japan fsashi.novitasari.si3, tjandra.ai6, ssakti,[email protected] Abstract Even though over seven hundred ethnic languages are spoken in Indonesia, the available technology remains limited that could support communication within indigenous communities as well as with people outside the villages. As a result, indigenous communities still face isolation due to cultural barriers; languages continue to disappear. To accelerate communication, speech-to-speech translation (S2ST) technology is one approach that can overcome language barriers. However, S2ST systems require machine translation (MT), speech recognition (ASR), and synthesis (TTS) that rely heavily on supervised training and a broad set of language resources that can be difficult to collect from ethnic communities. Recently, a machine speech chain mechanism was proposed to enable ASR and TTS to assist each other in semi-supervised learning. The framework was initially implemented only for monolingual languages. In this study, we focus on developing speech recognition and synthesis for these Indonesian ethnic languages: Javanese, Sundanese, Balinese, and Bataks. We first separately train ASR and TTS of standard Indonesian in supervised training. We then develop ASR and TTS of ethnic languages by utilizing Indonesian ASR and TTS in a cross-lingual machine speech chain framework with only text or only speech data removing the need for paired speech-text data of those ethnic languages. Keywords: Indonesian ethnic languages, cross-lingual approach, machine speech chain, speech recognition and synthesis. -

M. Ricklefs an Inventory of the Javanese Manuscript Collection in the British Museum
M. Ricklefs An inventory of the Javanese manuscript collection in the British Museum In: Bijdragen tot de Taal-, Land- en Volkenkunde 125 (1969), no: 2, Leiden, 241-262 This PDF-file was downloaded from http://www.kitlv-journals.nl Downloaded from Brill.com09/29/2021 11:29:04AM via free access AN INVENTORY OF THE JAVANESE MANUSCRIPT COLLECTION IN THE BRITISH MUSEUM* he collection of Javanese manuscripts in the British Museum, London, although small by comparison with collections in THolland and Indonesia, is nevertheless of considerable importance. The Crawfurd collection, forming the bulk of the manuscripts, provides a picture of the types of literature being written in Central Java in the late eighteenth and early nineteenth centuries, a period which Dr. Pigeaud has described as a Literary Renaissance.1 Because they were acquired by John Crawfurd during his residence as an official of the British administration on Java, 1811-1815, these manuscripts have a convenient terminus ad quem with regard to composition. A large number of the items are dated, a further convenience to the research worker, and the dates are seen to cluster in the four decades between AD 1775 and AD 1815. A number of the texts were originally obtained from Pakualam I, who was installed as an independent Prince by the British admini- stration. Some of the manuscripts are specifically said to have come from him (e.g. Add. 12281 and 12337), and a statement in a Leiden University Bah ad from the Pakualaman suggests many other volumes in Crawfurd's collection also derive from this source: Tuwan Mister [Crawfurd] asked to be instructed in adat law, with examples of the Javanese usage. -

"9-41516)9? "9787:)4 ;7 -6+7,- )=1 16 ;0- & $
L2/20-256 "9-41516)9?"9787:)4;7-6+7,-)=116;0-&$ ᭛᭜᭛ <;079 ,1;?))?<"-9,)6)215-14,7;3755/5)14+75 40)5 <9=)6:)0140)56<9=)6:)0/5)14+75 );- ;0$-8;-5*-9 6;97,<+;176 ,=:#6L>H8G>EI>H6=>HIDG>86AG6=B>76H:9H8G>EI;DJC9>CK6G>DJH>CH8G>EI>DCH6C96GI:;68IHEGD9J8:97:IL::CI=: I=6C9I=: I=8:CIJGN>C>CHJA6G+DJI=:6HIH>6A6G<:EDGI>DCD;>IH8DGEJH>H;DJC9>C"6K67JI#6L>B6I:G>6AH =6K:6AHD7::C;DJC9>C+JB6IG6%6A6N(:C>CHJA66A>6C9I=:(=>A>EE>C:H,=:H8G>EI>H;G:FJ:CIAN6HHD8>6I:9L>I= I=:'A9"6K6C:H:A6C<J6<:7JIB6I:G>6AHLG>II:C>C+6CH@G>I'A9%6A6N'A96A>C:H:6C9'A9+JC96C:H:A6C<J6<: =6H6AHD7::C;DJC9>CI=:#6L>H8G>EIGDBI=:B>9I=8:CIJGNH>BEA:;JC8I>DC6A#6L>L6HL>9:ANJH:9IDG:8DG9 A6C9 <G6CIH GDN6A :9>8IH 6C9 H>B>A6G 8=6C8:GN 9D8JB:CIH ,DL6G9H I=: :C9 D; I=: ;>GHI B>AA:CC>JB I=: H8G>EI 7:86B:>C8G:6H>C<AN9:8DG6I>K:6C986AA><G6E=>89J:ID>IHJH:6HI=:B6>CK:=>8A:D;'A9"6K6C:H:A>I:G6GNA6C<J6<: L>I=ADC<A6HI>C<A:<68N>CI=:A>I:G6GNIG69>I>DCD;I=:BD9:GC"6K6C:H:6C96A>C:H:A6C<J6<:H$6I:G#6L>H=DLH B6CNK6G>6I>DCHDK:G6L>9:<:D<G6E=>89>HIG>7JI>DC'K:GI>B:I=:H:K6G>6CIH=6K::KDAK:9>G:8IANDG>C9>G:8IAN >CIDI=:B6CNBD9:GCG6=B>8H8G>EIHD;>CHJA6G+H>6HJ8=6H6A>C:H:6I6@"6K6C:H:$DCI6G6:I8 /=>A:I=:68I>K:JH:D;#6L>H8G>EI=6H7::CG:EA68:97NDI=:GH8G>EIHH>C8:I=: I=8:CIJGNI=:G:6G:6CJB7:GD; BD9:GC96N:CI=JH>6HIH6C98DBBJC>I>:HL=DJH:I=:H8G>EIID96N;DGDI=:GEJGEDH:HI=6C6C8>:CIG:EGD9J8I>DC ;DG:M6BEA:ID8=6I>CHD8>6A6EEA>86I>DC6C98G:6I:>B6<:EDHIH!CI=>HG:K>K6AINE:D;JH:I=:#6L>H8G>EIB6N7: JH:9IDLG>I:A6C<J6<:HI=6I6G:CDI;DJC9>C‘6JI=:CI>8’#6L>8DGEJHHJ8=6HI=:BD9:GC"6K6C:H:A6C<J6<:DG I=: !C9DC:H>6C A6C<J6<: H#6L>=6H CDI 7::C :C8D9:9>C I=: -C>8D9: N:I I=: -

The Last Sea Nomads of the Indonesian Archipelago: Genomic
The last sea nomads of the Indonesian archipelago: genomic origins and dispersal Pradiptajati Kusuma, Nicolas Brucato, Murray Cox, Thierry Letellier, Abdul Manan, Chandra Nuraini, Philippe Grangé, Herawati Sudoyo, François-Xavier Ricaut To cite this version: Pradiptajati Kusuma, Nicolas Brucato, Murray Cox, Thierry Letellier, Abdul Manan, et al.. The last sea nomads of the Indonesian archipelago: genomic origins and dispersal. European Journal of Human Genetics, Nature Publishing Group, 2017, 25 (8), pp.1004-1010. 10.1038/ejhg.2017.88. hal-02112755 HAL Id: hal-02112755 https://hal.archives-ouvertes.fr/hal-02112755 Submitted on 27 Apr 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution - NonCommercial - NoDerivatives| 4.0 International License European Journal of Human Genetics (2017) 25, 1004–1010 Official journal of The European Society of Human Genetics www.nature.com/ejhg ARTICLE The last sea nomads of the Indonesian archipelago: genomic origins and dispersal Pradiptajati Kusuma1,2, Nicolas Brucato1, Murray P Cox3, Thierry Letellier1, Abdul Manan4, Chandra Nuraini5, Philippe Grangé5, Herawati Sudoyo2,6 and François-Xavier Ricaut*,1 The Bajo, the world’s largest remaining sea nomad group, are scattered across hundreds of recently settled communities in Island Southeast Asia, along the coasts of Indonesia, Malaysia and the Philippines. -

Design of Javanese Text to Speech Application
Design of Javanese Text to Speech Application Yulia, Liliana, Rudy Adipranata, Gregorius Satia Budhi Informatics Department, Industrial Technology Faculty, Petra Christian University Surabaya, Indonesia [email protected] Abstract—Javanese is one of the many regional languages used in Indonesia. Javanese language is used by most of the population in Java. But now along with the development of the era, the use of regional languages including Javanese language is to be re- duced especially among the younger generation. One way to help conserve the use of Javanese language is to utilize information technologies, one of them is by developing a text to speech appli- cation that can be used to find out how the pronunciation of Ja- vanese language. In this paper, we discussed the design for Java- nese text to speech applications uses finite state automata. The design result will be used as rules to separate syllables when im- plementing text to speech application. Index Terms—Javanese language; Finite state automata; Text to speech. Figure 1: Basic Javanese characters I. INTRODUCTION In addition to the basic characters, the Javanese character Javanese language is a language widely spoken by the peo- has supplementary characters, consist of symbols for express- ple of Java. It is one of the regional languages of many region- ing vowels as well as a combination of two specific conso- al languages spoken in Indonesia. As one of the assets of na- nants. This supplementary characters is called sandhangan tional culture, Javanese language needs to be preserved. The and can be seen in Figure 2 [5]. younger generation is now more interested in learning a for- Symbol Example Read eign language, rather than the native Indonesian local lan- guage. -

The Professionalisation of the Indonesian Military
The Professionalisation of the Indonesian Military Robertus Anugerah Purwoko Putro A thesis submitted to the University of New South Wales In fulfilment of the requirements for the degree of Doctor of Philosophy School of Humanities and Social Sciences July 2012 STATEMENTS Originality Statement I hereby declare that this submission is my own work and to the best of my knowledge it contains no materials previously published or written by another person, or substantial proportions of material which have been accepted for the award of any other degree or diploma at UNSW or any other educational institution, except where due acknowledgement is made in the thesis. Any contribution made to the research by others, with whom I have worked at UNSW or elsewhere, is explicitly acknowledged in the thesis. I also declare that the intellectual content of this thesis is the product of my own work, except to the extent that assistance from others in the project's design and conception or in style, presentation and linguistic expression is acknowledged. Copyright Statement I hereby grant to the University of New South Wales or its agents the right to archive and to make available my thesis or dissertation in whole or in part in all forms of media, now or hereafter known. I retain all property rights, such as patent rights. I also retain the right to use in future works (such as articles or books) all or part of this thesis or dissertation. Authenticity Statement I certify that the Library deposit digital copy is a direct equivalent of the final officially approved version of my thesis. -

Ahom Range: 11700–1174F
Ahom Range: 11700–1174F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation.