Enriching a Terminology for Under-Resourced Languages Using Knowledge Graphs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Some Principles of the Use of Macro-Areas Language Dynamics &A
Online Appendix for Harald Hammarstr¨om& Mark Donohue (2014) Some Principles of the Use of Macro-Areas Language Dynamics & Change Harald Hammarstr¨om& Mark Donohue The following document lists the languages of the world and their as- signment to the macro-areas described in the main body of the paper as well as the WALS macro-area for languages featured in the WALS 2005 edi- tion. 7160 languages are included, which represent all languages for which we had coordinates available1. Every language is given with its ISO-639-3 code (if it has one) for proper identification. The mapping between WALS languages and ISO-codes was done by using the mapping downloadable from the 2011 online WALS edition2 (because a number of errors in the mapping were corrected for the 2011 edition). 38 WALS languages are not given an ISO-code in the 2011 mapping, 36 of these have been assigned their appropri- ate iso-code based on the sources the WALS lists for the respective language. This was not possible for Tasmanian (WALS-code: tsm) because the WALS mixes data from very different Tasmanian languages and for Kualan (WALS- code: kua) because no source is given. 17 WALS-languages were assigned ISO-codes which have subsequently been retired { these have been assigned their appropriate updated ISO-code. In many cases, a WALS-language is mapped to several ISO-codes. As this has no bearing for the assignment to macro-areas, multiple mappings have been retained. 1There are another couple of hundred languages which are attested but for which our database currently lacks coordinates. -

Asia in Motion: Geographies and Genealogies
Asia in Motion: Geographies and Genealogies Organized by With support from from PRIMUS Visual Histories of South Asia Foreword by Christopher Pinney Edited by Annamaria Motrescu-Mayes and Marcus Banks This book wishes to introduce the scholars of South Asian and Indian History to the in-depth evaluation of visual research methods as the research framework for new historical studies. This volume identifies and evaluates the current developments in visual sociology and digital anthropology, relevant to the study of contemporary South Asian constructions of personal and national identities. This is a unique and excellent contribution to the field of South Asian visual studies, art history and cultural analysis. This text takes an interdisciplinary approach while keeping its focus on the visual, on material cultural and on art and aesthetics. – Professor Kamran Asdar Ali, University of Texas at Austin 978-93-86552-44-0 u Royal 8vo u 312 pp. u 2018 u HB u ` 1495 u $ 71.95 u £ 55 Hidden Histories Religion and Reform in South Asia Edited by Syed Akbar Hyder and Manu Bhagavan Dedicated to Gail Minault, a pioneering scholar of women’s history, Islamic Reformation and Urdu Literature, Hidden Histories raises questions on the role of identity in politics and private life, memory and historical archives. Timely and thought provoking, this book will be of interest to all who wish to study how the diverse and plural past have informed our present. Hidden Histories powerfully defines and celebrates a field that has refused to be occluded by majoritarian currents. – Professor Kamala Visweswaran, University of California, San Diego 978-93-86552-84-6 u Royal 8vo u 324 pp. -

Languages in the Rohingya Response
Languages in the Rohingya response This overview relates to a Translators without Borders (TWB) study of the role of language in humanitarian service access and community relations in Cox’s Bazar, Bangladesh and Sittwe, Myanmar. Language use and word choice has implications for culture, identity and politics in the Myanmar context. Six languages play a role in the Rohingya response in Myanmar and Bangladesh. Each brings its own challenges for translation, interpretation, and general communication. These languages are Bangla, Chittagonian, Myanmar, Rakhine, Rohingya, and English. Bangla Bangla’s near-sacred status in Bangladeshi society derives from the language’s tie to the birth of the nation. Bangladesh is perhaps the only country in the world which was founded on the back of a language movement. Bangladeshi gained independence from Pakistan in 1971, among other things claiming their right to use Bangla and not Urdu. Bangladeshis gave their lives for the cause of preserving their linguistic heritage and the people retain a patriotic attachment to the language. The trauma of the Liberation War is still fresh in the collective memory. Pride in Bangla as the language of national unity is unique in South Asia - a region known for its cultural, religious, and linguistic diversity. Despite the elevated status of Bangla, the country is home to over 40 languages and dialects. This diversity is not obvious because Bangladeshis themselves do not see it as particularly important. People across the country have a local language or dialect apart from Bangla that is spoken at home and with neighbors and friends. But Bangla is the language of collective, national identity - it is the language of government, commerce, literature, music and film. -

Map by Steve Huffman; Data from World Language Mapping System
Svalbard Greenland Jan Mayen Norwegian Norwegian Icelandic Iceland Finland Norway Swedish Sweden Swedish Faroese FaroeseFaroese Faroese Faroese Norwegian Russia Swedish Swedish Swedish Estonia Scottish Gaelic Russian Scottish Gaelic Scottish Gaelic Latvia Latvian Scots Denmark Scottish Gaelic Danish Scottish Gaelic Scottish Gaelic Danish Danish Lithuania Lithuanian Standard German Swedish Irish Gaelic Northern Frisian English Danish Isle of Man Northern FrisianNorthern Frisian Irish Gaelic English United Kingdom Kashubian Irish Gaelic English Belarusan Irish Gaelic Belarus Welsh English Western FrisianGronings Ireland DrentsEastern Frisian Dutch Sallands Irish Gaelic VeluwsTwents Poland Polish Irish Gaelic Welsh Achterhoeks Irish Gaelic Zeeuws Dutch Upper Sorbian Russian Zeeuws Netherlands Vlaams Upper Sorbian Vlaams Dutch Germany Standard German Vlaams Limburgish Limburgish PicardBelgium Standard German Standard German WalloonFrench Standard German Picard Picard Polish FrenchLuxembourgeois Russian French Czech Republic Czech Ukrainian Polish French Luxembourgeois Polish Polish Luxembourgeois Polish Ukrainian French Rusyn Ukraine Swiss German Czech Slovakia Slovak Ukrainian Slovak Rusyn Breton Croatian Romanian Carpathian Romani Kazakhstan Balkan Romani Ukrainian Croatian Moldova Standard German Hungary Switzerland Standard German Romanian Austria Greek Swiss GermanWalser CroatianStandard German Mongolia RomanschWalser Standard German Bulgarian Russian France French Slovene Bulgarian Russian French LombardRomansch Ladin Slovene Standard -

The Rohingya Origin Story: Two Narratives, One Conflict
Combating Extremism SHAREDFACT SHEET VISIONS The Rohingya Origin Story: Two Narratives, One Conflict At the center of the Rohingya Crisis is a question about the group’s origin. It is in this identity, and the contrasting histories that the two sides claim (i.e., the Rohingya minority and the Buddhist government/some civilians), where religion and politics collide. Although often cast as a religious war, the contemporary conflict didn’t exist until World War II, when the minority Muslim Rohingya sided with British colonial rulers, while the Buddhist majority allied with the invading Japanese. However, it took years for the identity politics to fully take root. It was 1982, when the Rohingya were stripped of their citizenship by law (For more on this, see “Q&A on the Rohingya Crisis & Buddhist Extremism in Myanmar”). Myanmarese army commander Senior General Min Aung Hlaing made it clear that Rohingya origin lay at the heart of the matter when, on September 16, 2017, he posted to Facebook a statement saying that the current military action against the Rohingya is “unfinished business” stemming back to the Second World War. He also stated, “They have demanded recognition as Rohingya, which has never been an ethnic group in Myanmar. [The] Bengali issue is a national cause and we need to be united in establishing the truth.”i This begs the question, what is the truth? There is no simple answer to this question. At the present time, there are two dominant, opposing narratives regarding the Rohingya ethnic group’s history: one from the Rohingya perspective, and the other from the neighboring Rakhine and Bamar peoples. -

What Matters?
Finding the right Host Getting relief goods: words in the Community A re-emerging concern within Rohingya language Feedback the Rohingya community WHAT Find out more on page 1 Find out more on page 2 Find out more on page 3 MATTERS? Humanitarian Feedback Bulletin on Rohingya Response Issue 12 × Wednesday, October 03, 2018 There have been many flows back and forth along the standard Burmese and Rakhine. When the ‘new Rohingya’ Finding the porous Bangladesh-Myanmar border over the last 50 joined the registered community in the camps, the linguistic years. In the early 1990s, about 250,000 Rohingya people differences became clear. So did the need to consider those right words in the fled to Bangladesh from northern Myanmar to escape differences when communicating with the community. a military crackdown. Some of those people returned Rohingya language to Myanmar, but many remained in Bangladesh. The ‘Registered Rohingya’ now use many Bangla words community that stayed behind is usually referred to as Clear communication with the Rohingya the ‘registered Rohingya’, even though some of them are In the past three decades, various government and non-government community is one of the most challenging not officially ‘registered’ as refugees by UNHCR and the institutions exposed the ‘registered Rohingya’ community to aspects of the current response. It requires us to government of Bangladesh. standard Bangla. Those that went to Bangladeshi schools learned understand how their language is evolving, how how to read and write in standard Bangla. Rohingya men learned different languages have influenced it, and how In 2017, another 700,000 Rohingya people crossed Bangla in their interactions beyond the camp, through trade or distinct dialects are emerging. -

Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo
Asia No. Language [ISO 639-3 Code] Country (Region) 1 A’ou [aou] Iouo China 2 Abai Sungai [abf] Iouo Malaysia 3 Abaza [abq] Iouo Russia, Turkey 4 Abinomn [bsa] Iouo Indonesia 5 Abkhaz [abk] Iouo Georgia, Turkey 6 Abui [abz] Iouo Indonesia 7 Abun [kgr] Iouo Indonesia 8 Aceh [ace] Iouo Indonesia 9 Achang [acn] Iouo China, Myanmar 10 Ache [yif] Iouo China 11 Adabe [adb] Iouo East Timor 12 Adang [adn] Iouo Indonesia 13 Adasen [tiu] Iouo Philippines 14 Adi [adi] Iouo India 15 Adi, Galo [adl] Iouo India 16 Adonara [adr] Iouo Indonesia Iraq, Israel, Jordan, Russia, Syria, 17 Adyghe [ady] Iouo Turkey 18 Aer [aeq] Iouo Pakistan 19 Agariya [agi] Iouo India 20 Aghu [ahh] Iouo Indonesia 21 Aghul [agx] Iouo Russia 22 Agta, Alabat Island [dul] Iouo Philippines 23 Agta, Casiguran Dumagat [dgc] Iouo Philippines 24 Agta, Central Cagayan [agt] Iouo Philippines 25 Agta, Dupaninan [duo] Iouo Philippines 26 Agta, Isarog [agk] Iouo Philippines 27 Agta, Mt. Iraya [atl] Iouo Philippines 28 Agta, Mt. Iriga [agz] Iouo Philippines 29 Agta, Pahanan [apf] Iouo Philippines 30 Agta, Umiray Dumaget [due] Iouo Philippines 31 Agutaynen [agn] Iouo Philippines 32 Aheu [thm] Iouo Laos, Thailand 33 Ahirani [ahr] Iouo India 34 Ahom [aho] Iouo India 35 Ai-Cham [aih] Iouo China 36 Aimaq [aiq] Iouo Afghanistan, Iran 37 Aimol [aim] Iouo India 38 Ainu [aib] Iouo China 39 Ainu [ain] Iouo Japan 40 Airoran [air] Iouo Indonesia 1 Asia No. Language [ISO 639-3 Code] Country (Region) 41 Aiton [aio] Iouo India 42 Akeu [aeu] Iouo China, Laos, Myanmar, Thailand China, Laos, Myanmar, Thailand, -
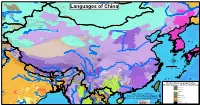
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

Rohingyas in Bangladesh: Owning Rohingya Identity in Disowning Spaces
ROHINGYAS IN BANGLADESH: OWNING ROHINGYA IDENTITY IN DISOWNING SPACES ISHRAT ZAKIA SULTANA A DISSERTATION SUBMITTED TO THE FACULTY OF GRADUATE STUDIES IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY GRADUATE PROGRAM IN SOCIOLOGY YORK UNIVERSITY TORONTO, ONTARIO MARCH 2019 © Ishrat Zakia Sultana, 2019 ABSTRACT This dissertation focuses on Rohingya people, with a special emphasis on Rohingya youth and young adults, and how they construct their identities. While Rohingya ethnic identity is deeply rooted in Burma, it is influenced by how they grow up and reach adulthood within a protracted situation in Bangladesh. Many Rohingya youth and young adults find it complicated to define who they are because they belong to a place, Burma, that does not consider them “citizens,” and they reside in a place, Bangladesh, that never recognizes them as “residents.” The uncertainty around Rohingya identity raises several questions: How does the experience of displacement and refugeeness in Bangladesh shape identity among Rohingya people, particularly among the youth and young adults? What is Rohingya identity? In what ways do they retain their Rohingya identity in the context of their non-citizen status in Bangladesh? While they are stateless, how are the social rights of citizenship experienced by Rohingya people? Using ethnographic methods, I spent nine months in Cox’s Bazar, Bangladesh, between 2014 and 2016 to collect data for this research. I interviewed 44 Rohingya people. Rohingyas first arrived in Bangladesh in 1978. After that, many Rohingya people were born and/or raised in Bangladeshi refugee camps, and have never left, while others were forcefully repatriated by Bangladeshi government and then forced to return to Bangladesh again by the Burmese government during 1992-1993 (Abrar, 1995; Pittaway, 2008; Loescher & Milner, 2008; Ullah, 2011; Murshid, 2014). -

The Rohingya Issue: a Thorny Obstacle Between Burma (Myanmar) and Bangladesh
The Rohingya Issue: A Thorny Obstacle between Burma (Myanmar) and Bangladesh Kei NEMOTO Introduction Though the political and economic relationships among the countries of the sub-region of Eastern South Asia have been strengthened since 1990s, the ties between Burma (Myanmar) and Bangladesh have often been disrupted by the Rohingya issue. The Rohingyas, a Muslim minority group residing in the northwestern part of the Arakan (Rakhine) State1 in Burma, have not been recognized as a national minority by the state since 1974 when the Ne Win government denied their citizenship officially. They have suffered from oppression under the Burmese government and the Burmese Army (Tatmadaw). They fled en masse to Bangladesh twice by crossing the Naf River on the border. The Rohingya refugees numbered between 200,000 and 250,000 in 1978 and more than 250,000 in 1991. These exoduses largely were resolved through agreements on the repatriation between the two governments and relief operations by the United Nations as well as the United Nations High Commissioner for Refugees (UNHCR). However, Burmese military government has no intention to accept those returnees as a national minority and instead classifies them as foreigners or illegal immigrants. The Government of Bangladesh which fears of accepting another mass exodus of refugees has been strengthening the border patrol system, but has actually not been able to stop the daily continuous trespassing of the Rohingyas from Arakan to Bangladesh. There seems no guarantee that another exodus may not happen in the future. Since the latter half of 1990s, the two towns, Maungdaw (of Arakan) and Teknaf (of Bangladesh) between the Naf River, have been identified by the two governments as the future strongholds for promoting the border trade2. -

Journal of Public Policy Research
OCTOBER, 2017 SPECIAL ISSUE Journal of Public Policy Research GRADUATE JOURNAL OF THE SCHOOL OF PUBLIC POLICY AND GOVERNANCE SPECIAL ISSUE: CITIZENSHIP UNDER VECTORS OF DISCRIMINATION A Perpetrator Narrative on Domestic Violence: Case Study of Rohingya Masculinities in Refugee Camps | Ayyagari Subramaniam A Battle of the Wills, “Marzi”, “Majboori”, and a Negative Approach to “Izzat” in the Life of a Rohingya Woman | Divya Jose Problems and Issues of Stateless People in North-East India | H. Vanlallawta Tribes and Gender: The Question of Empowerment in the Autonomous District Council in Manipur | Khamliansang Naulak Exclusion of Particularly Vulnerable Tribal Groups: A Case Study of Maharashtra | Mahindra N. Wardhalwar Immigration and Border Politics: Seeing the ‘Other’ in Assam | Jeemut Pratim Das HYDERABAD CAMPUS Surrender and Rehabilitation Policy for the Left-Wing Extremists | Nitin N. Zade Lived Experience of Women Sarpanch and Ex- Sarpanch Under the Panchayati Raj | Shambhavi Sharma Older Women: Problems and Beyond | Sampurna Das TATA INSTITUTE OF SOCIAL SCIENCES, HYDERABAD, INDIA Editors Dr S. Siva Raju Professor and Deputy Director, Tata Institute of Social Sciences, Hyderabad (TISS-Hyd) Dr Aseem Prakash Professor and Chairperson, School of Public Policy and Governance, (SPPG) TISS-Hyd Dr Amit Sadhukhan Assistant Professor, SPPG, TISS- Hyd Dr Ekta Singh Assistant Professor, SPPG, TISS- Hyd Dr Gayatri Nair Assistant Professor, SPPG, TISS- Hyd Managing Editor Dr Amit Upadhyay Assistant Professor, SPPG, TISS- Hyd Executive Editors -

Strategic Panorama 2015 Spanish Institute for Strategic Studies
Strategic Panorama 2015 Spanish Institute for Strategic Studies MINISTRY OF DEFENCE Strategic Panorama Spanish Institute for 2015 Strategic Studies MINISTRY OF DEFENCE GENERAL CATALOGUE OF OFFICIAL PUBLICATIONS http://www.publicacionesoficiales.boe.es/ Publishes: SECRETARÍA GENERAL TÉCNICA http://publicaciones.defensa.gob.es/ © Author and Publisher, 2015 NIPO: 083-15-162-5 (paper edition) NIPO: 083-15-163-0 (e-book edition) ISBN: 978-84-9091-080-1 (paper edition) ISBN: 978-84-9091-081-8 (e-book edition) Legal deposit: M-15981-2015 Relase date: june 2015 Printed by: Spanish Ministry of Defence The authors are solely responsible for the opinions expresed in the articles in this publication. The exploitation righits of this work are protected by the Spanish Intellectual Property Act. No parts of this publication may be produced, stored or transmitted in any way nor by any means, electronic, mechanical or print, including photocopies or any other means without prior, express, written con- sent of the © copyright holders. This publication is printed on chlorine-free paper obtained from certified sustainable forestry. INDEX Introduction ............................................................................................................. 9 Security: perception and reality .............................................................................. 13 The map of risks and threats .................................................................................. 19 Oil, at 50 dollars per barrel ....................................................................................