Large-Scale Analyses of Site-Specific Evolutionary Rates Across
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

POLYMER STRUCTURE and CHARACTERIZATION Professor
POLYMER STRUCTURE AND CHARACTERIZATION Professor John A. Nairn Fall 2007 TABLE OF CONTENTS 1 INTRODUCTION 1 1.1 Definitions of Terms . 2 1.2 Course Goals . 5 2 POLYMER MOLECULAR WEIGHT 7 2.1 Introduction . 7 2.2 Number Average Molecular Weight . 9 2.3 Weight Average Molecular Weight . 10 2.4 Other Average Molecular Weights . 10 2.5 A Distribution of Molecular Weights . 11 2.6 Most Probable Molecular Weight Distribution . 12 3 MOLECULAR CONFORMATIONS 21 3.1 Introduction . 21 3.2 Nomenclature . 23 3.3 Property Calculation . 25 3.4 Freely-Jointed Chain . 27 3.4.1 Freely-Jointed Chain Analysis . 28 3.4.2 Comment on Freely-Jointed Chain . 34 3.5 Equivalent Freely Jointed Chain . 37 3.6 Vector Analysis of Polymer Conformations . 38 3.7 Freely-Rotating Chain . 41 3.8 Hindered Rotating Chain . 43 3.9 More Realistic Analysis . 45 3.10 Theta (Θ) Temperature . 47 3.11 Rotational Isomeric State Model . 48 4 RUBBER ELASTICITY 57 4.1 Introduction . 57 4.2 Historical Observations . 57 4.3 Thermodynamics . 60 4.4 Mechanical Properties . 62 4.5 Making Elastomers . 68 4.5.1 Diene Elastomers . 68 0 4.5.2 Nondiene Elastomers . 69 4.5.3 Thermoplastic Elastomers . 70 5 AMORPHOUS POLYMERS 73 5.1 Introduction . 73 5.2 The Glass Transition . 73 5.3 Free Volume Theory . 73 5.4 Physical Aging . 73 6 SEMICRYSTALLINE POLYMERS 75 6.1 Introduction . 75 6.2 Degree of Crystallization . 75 6.3 Structures . 75 Chapter 1 INTRODUCTION The topic of polymer structure and characterization covers molecular structure of polymer molecules, the arrangement of polymer molecules within a bulk polymer material, and techniques used to give information about structure or properties of polymers. -

Ideal Chain Conformations and Statistics
ENAS 606 : Polymer Physics Chinedum Osuji 01.24.2013:HO2 Ideal Chain Conformations and Statistics 1 Overview Consideration of the structure of macromolecules starts with a look at the details of chain level chemical details which can impact the conformations adopted by the polymer. In the case of saturated carbon ◦ backbones, while maintaining the desired Ci−1 − Ci − Ci+1 bond angle of 112 , the placement of the final carbon in the triad above can occur at any point along the circumference of a circle, defining a torsion angle '. We can readily recognize the energetic differences as a function this angle, U(') such that there are 3 minima - a deep minimum corresponding the the trans state, for which ' = 0 and energetically equivalent gauche− and gauche+ states at ' = ±120 degrees, as shown in Fig 1. Figure 1: Trans, gauche- and gauche+ configurations, and their energetic sates 1.1 Static Flexibility The static flexibility of the chain in equilibrium is determined by the difference between the levels of the energy minima corresponding the gauche and trans states, ∆. If ∆ < kT , the g+, g− and t states occur with similar probability, and so the chain can change direction and appears as a random coil. If ∆ takes on a larger value, then the t conformations will be enriched, so the chain will be rigid locally, but on larger length scales, the eventual occurrence of g+ and g− conformations imparts a random conformation. Overall, if we ignore details on some length scale smaller than lp, the persistence length, the polymer appears as a continuous flexible chain where 1 lp = l0 exp(∆/kT ) (1) where l0 is something like a monomer length. -

Native-Like Mean Structure in the Unfolded Ensemble of Small Proteins
B doi:10.1016/S0022-2836(02)00888-4 available online at http://www.idealibrary.com on w J. Mol. Biol. (2002) 323, 153–164 Native-like Mean Structure in the Unfolded Ensemble of Small Proteins Bojan Zagrovic1, Christopher D. Snow1, Siraj Khaliq2 Michael R. Shirts2 and Vijay S. Pande1,2* 1Biophysics Program The nature of the unfolded state plays a great role in our understanding of Stanford University, Stanford proteins. However, accurately studying the unfolded state with computer CA 94305-5080, USA simulation is difficult, due to its complexity and the great deal of sampling required. Using a supercluster of over 10,000 processors we 2Department of Chemistry have performed close to 800 ms of molecular dynamics simulation in Stanford University, Stanford atomistic detail of the folded and unfolded states of three polypeptides CA 94305-5080, USA from a range of structural classes: the all-alpha villin headpiece molecule, the beta hairpin tryptophan zipper, and a designed alpha-beta zinc finger mimic. A comparison between the folded and the unfolded ensembles reveals that, even though virtually none of the individual members of the unfolded ensemble exhibits native-like features, the mean unfolded structure (averaged over the entire unfolded ensemble) has a native-like geometry. This suggests several novel implications for protein folding and structure prediction as well as new interpretations for experiments which find structure in ensemble-averaged measurements. q 2002 Elsevier Science Ltd. All rights reserved Keywords: mean-structure hypothesis; unfolded state of proteins; *Corresponding author distributed computing; conformational averaging Introduction under folding conditions, with some notable exceptions.14 – 16 This is understandable since under Historically, the unfolded state of proteins has such conditions the unfolded state is an unstable, received significantly less attention than the folded fleeting species making any kind of quantitative state.1 The reasons for this are primarily its struc- experimental measurement very difficult. -
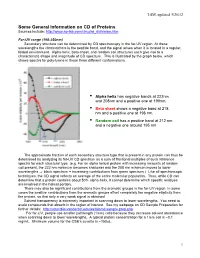
CD of Proteins Sources Include
LSM, updated 3/26/12 Some General Information on CD of Proteins Sources include: http://www.ap-lab.com/circular_dichroism.htm Far-UV range (190-250nm) Secondary structure can be determined by CD spectroscopy in the far-UV region. At these wavelengths the chromophore is the peptide bond, and the signal arises when it is located in a regular, folded environment. Alpha-helix, beta-sheet, and random coil structures each give rise to a characteristic shape and magnitude of CD spectrum. This is illustrated by the graph below, which shows spectra for poly-lysine in these three different conformations. • Alpha helix has negative bands at 222nm and 208nm and a positive one at 190nm. • Beta sheet shows a negative band at 218 nm and a positive one at 196 nm. • Random coil has a positive band at 212 nm and a negative one around 195 nm. The approximate fraction of each secondary structure type that is present in any protein can thus be determined by analyzing its far-UV CD spectrum as a sum of fractional multiples of such reference spectra for each structural type. (e.g. For an alpha helical protein with increasing amounts of random coil present, the 222 nm minimum becomes shallower and the 208 nm minimum moves to lower wavelengths ⇒ black spectrum + increasing contributions from green spectrum.) Like all spectroscopic techniques, the CD signal reflects an average of the entire molecular population. Thus, while CD can determine that a protein contains about 50% alpha-helix, it cannot determine which specific residues are involved in the helical portion. -

Protein Folding and Structure Prediction
Protein Folding and Structure Prediction A Statistician's View Ingo Ruczinski Department of Biostatistics, Johns Hopkins University Proteins Amino acids without peptide bonds. Amino acids with peptide bonds. ¡ Amino acids are the building blocks of proteins. Proteins Both figures show the same protein (the bacterial protein L). The right figure also highlights the secondary structure elements. Space Resolution limit of a light microscope Glucose Ribosome Red blood cell C−C bond Hemoglobin Bacterium 1 10 100 1000 10000 100000 1nm 1µm Distance [ A° ] Energy C−C bond Green Noncovalent bond light Glucose Thermal ATP 0.1 1 10 100 1000 Energy [ kcal/mol ] Non-Bonding Interactions Amino acids of a protein are joined by covalent bonding interactions. The polypep- tide is folded in three dimension by non-bonding interactions. These interactions, which can easily be disrupted by extreme pH, temperature, pressure, and denatu- rants, are: Electrostatic Interactions (5 kcal/mol) Hydrogen-bond Interactions (3-7 kcal/mol) Van Der Waals Interactions (1 kcal/mol) ¡ Hydrophobic Interactions ( 10 kcal/mol) The total inter-atomic force acting between two atoms is the sum of all the forces they exert on each other. Energy Profile Transition State Denatured State Native State Radius of Gyration of Denatured Proteins Do chemically denatured proteins behave as random coils? The radius of gyration Rg of a protein is defined as the root mean square dis- tance from each atom of the protein to their centroid. For an ideal (infinitely thin) random-coil chain in a solvent, the average radius 0.5 ¡ of gyration of a random coil is a simple function of its length n: Rg n For an excluded volume polymer (a polymer with non-zero thickness and non- trivial interactions between monomers) in a solvent, the average radius of gyra- 0.588 tion, we have Rg n (Flory 1953). -

Helix-Coil Conformational Change Accompanied by Anisotropic–Isotropic Transition
Polymer Journal, Vol.33, No. 11, pp 898—901 (2001) NOTES Helix-Coil Conformational Change Accompanied by Anisotropic–Isotropic Transition † Ning LIU, Jiaping LIN, Tao C HEN, Jianding CHEN, Dafei ZHOU, and Le LI Department of Polymer Science and Engineering, East China University of Science and Technology, Shanghai 200237, P. R. China (Received November 22, 2000; Accepted July 1, 2001) KEY WORDS Helix-Coil Transition / Liquid Crystal Polymer / Polypeptide / Anisotropic– Isotropic Transition / Polypeptides, particularly poly(γ-benzyl-L- limited study of this acid induced anisotropic–isotropic glutamate) (PBLG) and other glutamic acid ester transition has been reported.13, 14 The precise molecular polymers, have the ability to exist in α-helix, a well de- mechanism of the transition remains to be determined. fined chain conformation of long chain order and retain In the present work, the texture changes in the acid- such a structure in numerous organic solvents that sup- induced anisotropic–isotropic transition were studied port intramolecular hydrogen bonding.1, 2 If PBLG and by microscope observations and the corresponding related polypeptides are dissolved in a binary solvent molecular conformational changes were followed by IR mixture containing a non-helicogenic component such measurements. The effect of the polymer concentra- as dichloroacetic acid (DCA) or trifluoroacetic acid tion was studied. According to the information gained (TFA), they can undergo a conformational change from through the experiment, the molecular mechanism with the α-helix to random coil form due to the changes respect to the acid-induced helix-coil conformational in solvent composition, temperature or both.3, 4 The change was suggested. -

Native-Like Secondary Structure in a Peptide From
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Research Paper 473 Native-like secondary structure in a peptide from the ␣-domain of hen lysozyme Jenny J Yang1*, Bert van den Berg*, Maureen Pitkeathly, Lorna J Smith, Kimberly A Bolin2, Timothy A Keiderling3, Christina Redfield, Christopher M Dobson and Sheena E Radford4 Background: To gain insight into the local and nonlocal interactions that Addresses: Oxford Centre for Molecular Sciences contribute to the stability of hen lysozyme, we have synthesized two peptides and New Chemistry Laboratory, University of Oxford, South Parks Road, Oxford OX1 3QT, UK. that together comprise the entire ␣-domain of the protein. One peptide (peptide Present addresses: 1Department of Molecular 1–40) corresponds to the sequence that forms two ␣-helices, a loop region, and Physics and Biochemistry, Yale University, 266 a small -sheet in the N-terminal region of the native protein. The other (peptide Whitney Avenue, PO Box 208114, New Haven, 84–129) makes up the C-terminal part of the ␣-domain and encompasses two CT 06520-8114, USA. 2Department of Chemistry ␣-helices and a 310 helix in the native protein. and Biochemistry, University of California, Santa Cruz, CA 96064, USA. 3Department of Chemistry, University of Illinois, 845 West Taylor Street, Results: As judged by CD and a range of NMR parameters, peptide 1–40 has Chicago, IL 60607-7061, USA. 4Department of little secondary structure in aqueous solution and only a small number of local Biochemistry and Molecular Biology, University of hydrophobic interactions, largely in the loop region. -

Non-Covalent Interactions and How Macromolecules Fold
Non-covalent interactions and how macromolecules fold Lecture 6: Protein folding and misfolding Dr Philip Fowler Objective: Restate how proteins fold First-year Biophysics course Examine the thermodynamics of how a protein folds. Determine what factors affect the stability of the folded, native structure. Resolve the Levinthal Paradox Investigate the role misfolded proteins play in disease Summary: Proteins are marginally stable We can study the folding of proteins using e.g. denaturants Proteins can be unfolded by changing pH and temperature or by adding denaturants The concept of the protein folding funnel dispenses with the Levinthal Paradox Misfolded proteins can form aggregates known as fibrils; prions are infectious proteins Protein folding unfolded, extended state compact molten globule folded, compact native state (random coil) more water—water clusters of non-covalent interactions fewer protein—water hydrogen bonds hydrogen bonds (can form form cooperatively complete network) ∆H > 0 ☹ ∆H < 0 ☺ ☺ native fold is less flexible protein than molten globule protein can adopt fewer ∆S < 0 ☹ ∆S < 0 ☹ conformations when a molten globule much less local ordering of the water from the perspective of the ∆H < 0 ☺ ∆H ≈ 0 solvent, there is little difference water between the molten globule and ∆S > 0 ☺ ☺ ∆S ≈ 0 the folded, native state The hydrophobic effect causes the extended polypeptide chain to collapse and form a compact but dynamic molten globule. Clusters of non-covalent interactions within the protein then form cooperatively. Thermodynamics of folding lysozyme at 25 °C DG = DH TDS unfolded, extended state − folded, compact native state ΔG = -60.9 kJ mol-1 TΔS = -175 kJ mol-1 ΔH = -236 kJ mol-1 How much lysozyme is unfolded? includes " includes " (a) protein—protein"☺ (a) increase in entropy of the water "☺ DG = RT lnK (b) protein—water " ☹ (b) decrease in the entropy of the protein ☹ − (c) water—water interactions ☺ K ~ 4.7 x 1010 i.e. -

Molecular Dynamics of Folded and Disordered Polypeptides in Comparison with Nuclear
Molecular Dynamics of Folded and Disordered Polypeptides in Comparison with Nuclear Magnetic Resonance Measurement Thesis Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The Ohio State University By Lei Yu Graduate Program in Chemistry The Ohio State University 2018 Thesis Committee Rafael Brüschweiler, Advisor Sherwin Singer Copyrighted by Lei Yu 2018 2 Abstract With continuous increase in computer speed, molecular dynamics (MD) simulations have become a crucial biophysical method for the understanding of biochemical processes at atomic detail. However, current molecular mechanics force fields optimized for globular proteins often result in overly collapsed structures for intrinsically disordered proteins (IDPs). In order to study the relevant biological functions of IDPs, it is of great importance to utilize the appropriate force fields. Chemical shifts and J-coupling measurements from solution nuclear magnetic resonance (NMR) experiments serve as a common ground for force field assessment. Various combinations of protein force fields and water models were assessed by the direct comparison between back-calculated NMR parameters and experimental data. TIP4P-D water model was proven to improve the accuracy of back- calculation by producing more realistic dihedral angle ψ distributions. Amber99SBnmr1- ILDN and RSFF2+ force fields were shown to be optimal choices for tripeptide and IDP fragment simulations. The stability of the simulated two-helix bundle (THB) domain in the eukaryotic Na+/Ca2+ exchanger (NCX) suggested the transferable performance of Amber99SBnmr1-ILDN force field in company with TIP4P-D water model in folded proteins. Based on the assessment results, a research plan for future improvement of force fields by rebalancing dihedral angle distributions was proposed. -

Spring 2012 Lecture 10-12
CHM333 LECTURE 10 – 12: 2/4 – 2/11/13 SPRING 2013 Professor Christine Hrycyna Levels of Protein Structure: PRIMARY STRUCTURE (1°) - Defined, non-random sequence of amino acids along the peptide backbone o Described in two ways: § Amino acid composition § Amino acid sequence § M-L-D-G-C-G Peptide A § M-L-C-D-G-G Peptide B § Composition is IDENTICAL; Sequence is DIFFERENT - How to determine the COMPOSITION o Purify the protein of interest – separate away from all other types of proteins and biomolecules o Estimate the molecular weight of the protein o Establish the composition by complete hydrolysis of the protein under acidic conditions § Treat with 6M HCl at 110°C; 12-36 hours § Each peptide bond is broken and products are all of the free amino acids § Each amino acid is separated, identified and quantified § Final result: Know HOW MANY of each amino acid present in the original 66 CHM333 LECTURE 10 – 12: 2/4 – 2/11/13 SPRING 2013 Professor Christine Hrycyna - How to determine the ORDER o Determine the C-terminal amino acid § Use carboxypeptidase – enzyme that removes the last (C-terminal) amino acid in a free form by breaking the peptide bond • Hydrolyzes the peptide bond nearest the C-terminus o Identify the N-terminal amino acids in order § Process called SEQUENCING § Often difficult to characterize an intact protein § Instead, employ a “divide and conquer” approach to analyze peptide fragments of the intact protein § Cut large proteins into smaller parts § Use enzymes called PROTEASES • Cleave peptide bond in a specific way • TWO Examples: -

Hydrolyzed Collagen—Sources and Applications
molecules Review Hydrolyzed Collagen—Sources and Applications Arely León-López 1, Alejandro Morales-Peñaloza 2,Víctor Manuel Martínez-Juárez 1, Apolonio Vargas-Torres 1, Dimitrios I. Zeugolis 3,4 and Gabriel Aguirre-Álvarez 1,* 1 Instituto de Ciencias Agropecuarias, Universidad Autónoma del Estado de Hidalgo, Av. Universidad km 1. Ex Hacienda de Aquetzalpa. Tulancingo, Hidalgo 43600, Mexico; [email protected] (A.L.-L.); [email protected] (V.M.M.-J.); [email protected] (A.V.-T.) 2 Universidad Autónoma del Estado de Hidalgo, Escuela Superior de Apan, Carretera Apan-Calpulalpan s/n, Colonia, Chimalpa Tlalayote, Apan, Hidalgo 43920 Mexico; [email protected] 3 Regenerative, Modular & Developmental Engineering Laboratory (REMODEL), National University of Ireland Galway (NUI Galway), H91 TK33 Galway, Ireland; [email protected] 4 Science Foundation Ireland (SFI) Centre for Research in Medical Devices (CÚRAM) National University of Ireland Galway (NUI Galway), H91 TK33 Galway, Ireland * Correspondence: [email protected]; Tel.: +52-775-145-9265 Academic Editors: Manuela Pintado, Ezequiel Coscueta and María Emilia Brassesco Received: 7 October 2019; Accepted: 5 November 2019; Published: 7 November 2019 Abstract: Hydrolyzed collagen (HC) is a group of peptides with low molecular weight (3–6 KDa) that can be obtained by enzymatic action in acid or alkaline media at a specific incubation temperature. HC can be extracted from different sources such as bovine or porcine. These sources have presented health limitations in the last years. Recently research has shown good properties of the HC found in skin, scale, and bones from marine sources. Type and source of extraction are the main factors that affect HC properties, such as molecular weight of the peptide chain, solubility, and functional activity. -

Chapter 7. Polymer Solutions 7.1. Criteria for Polymers Solubility 7.2
Chapter 7. Polymer solutions 7.1. Criteria for polymers solubility 7.2. Conformations of dissolved polymer chains 7.3. Thermodynamics of polymer solutions 7.4. Phase equilibrium in polymer solutions 7.5. Fractionation of polymers by solubility Ariadne L Juwono Semester I 2006/2007 Departemen Fisika FMIPA UI 7.1. Criteria of polymer solubility The solution process The polymer dissolving occurs very slow and consists in 2 steps: 1. Solvent molecules slowly diffuse into the polymer a swolen gel. This process is very slow because of crosslinking, crytallinity, or strong hydrogen bonding. 2. The gel gradually disintegrates into a true solution. Agitation can speed up this process. For very high molecular weight, the solution process takes days or weeks. Ariadne L. Juwono Semester I 2006/2007 Departemen Fisika FMIPA UI Polymer texture and solubility Solubility relations in polymer systems are complex, because of •The size differences between polymer and solvent molecules, •The viscosity of the system, •The effects of the texture •The molecular weight of the polymer. Solubility depends on the nature of the solvent, the temperature of the solution, the topology of the polymer, and the crystallinity. Cross-linked polymers do not dissolve, but only swell with the solvent when an interaction between the polymer and the solvent occurs. Examples: •Light cross-linked rubbers swell, •Unvulcanized materials would dissolve, •Hard rubbers and thermosetting materials may not swell in any solvent. Ariadne L. Juwono Semester I 2006/2007 Departemen Fisika FMIPA UI Many non-polar crystalline polymers do not dissolve, except at the temperature near their crystalline melting points. Explanation: Crystallinity decreases as the melting point is approached and the melting point is depressed by the presence of the solvent, thus solubility can often achieved at temperatures below melting point.