Predicting the Gender of Flemish Twitter Users Using an Ensemble of Classifiers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Koen Wauters
De Rijkste Belgen Ranking van de Rijkste Belgen https://derijkstebelgen.be Koen Wauters Date : 4 maart 2016 Weinig Belgen die Koen Wauters niet kennen, maar ook weinigen die weten dat het dankzij Bob Savenberg is dat we ooit van Clouseau hoorden. Hij richtte met enkele vrienden de popgroep op in de jaren '80 en enkele jaren later vervoegden de broertjes Wauters het team. Met Koen Wauters als boegbeeld haalde Clouseau in 1987 zijn eerst hit binnen met 'Brandweer'. Twee jaar later volgde hun echt doorbraak met een deelname aan de voorrondes van het Eurovisiesongfestival. Het nummer 'Anne' strandde op de tweede plaats maar werd wel een gigantische hit in Vlaanderen en Nederland. In 1991 werd Clouseau rechtstreeks naar het Eurovisiesongfestival gestuurd met het liedje 'Geef het op' maar ook daarmee haalden ze slechts de zestiende plaats. Gelukkig ging het hen in eigen land wel voor de wind en volgden de hitsingles elkaar op. Ondanks het steeds groter wordende succes van de groep verlaat Bob Savenberg in 1996 als laatste bandlid de groep Clouseau. Koen en Kris besluiten om alleen verder te gaan. Een goede keuze want het vertrek van de oprichter belet de band niet om de ene hit na de andere te scoren en geregeld een nieuw album uit te brengen. Dit alles met succes want in de herfst van 2001 bracht Clouseau de cd 'En Dans' uit, die elf weken op één stond in de Belgische Ultratop Albums. Ook het album 'Vanbinnen' (2004) scoorde hoge ogen toen het in voorverkoop reeds platina bleek. Sinds 2000 vinden er geregeld optredens van Clouseau plaats in het Sportpaleis. -

De Vele Gezichten Van the Voice Van Vlaanderen
Arf & Yes en CHAUVET 32 De vele gezichten van The > Voice van Vlaanderen Wat is jouw favoriete herinnering aan The Voice? Stel deze vraag ners. “Het design ging altijd over evenwicht, het visueel aan een willekeurige groep Belgen en je krijgt waarschijnlijk aantrekkelijk maken voor zowel het live als tv-publiek.” een zeer uitgebreid antwoord en een geanimeerde conversatie gevuld met een hele hoop amusante voorbeelden. Als één van de MULTIFUNCTIONEEL DESIGN langstlopende en meest succesvolle shows van het wereldwijd Voor dit seizoen van The Voice kreeg de set een volledige bekende reality-tv concept is The Voice van Vlaanderen vaak makeover naar een veelzijdig design waarin moeiteloos hét gespreksonderwerp in koffietenten of op sociale media in geschakeld kon worden tussen grote, panoramische het land. Het was ook een springplank voor enkele van de meest looks en een intiemere setting om alle emoties van het gevierde Belgische zangers. aanstormende talent in beeld te brengen. De set slaat ook aan bij het live publiek dankzij de levendige kleuren Fotografie Picturesk en heeft diepte en definitie die zich perfect vertalen op het televisiescherm. Een centrale rol in de opdracht van m het VTM-programma te ondersteunen met het Arf & Yes team om een multifunctioneel design te kleurrijke en dynamische visuals zorgde Arf & creëren werd gespeeld door de 12 Maverick MK2 Profiles OYes dit jaar voor een design met meer dan 300 en bijna 300 ÉPIX Strip lineaire armaturen in de set. De CHAUVET Professional armaturen, geleverd door Ph- veelzijdige Mavericks speelden twee rollen en werden lippo Productions. “We ontwerpen The Voice al een hele gebruikt als key lights voor de deelnemers en de coaches tijd”, zei programmer en operator Jonas Weyn, die aan de én om een dramatische touch te geven als backlights show werkte met een heel team van lighting- en setdesig- tijdens de optredens. -
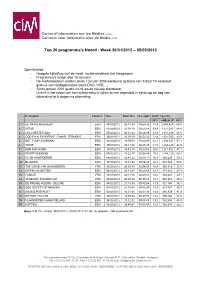
Top 20 Programma's Noord - Week 30/01/2012 – 05/02/2012
Centre d’Information sur les Médias A.S.B.L. Centrum voor Informatie over de Media V.Z.W. Top 20 programma's Noord - Week 30/01/2012 – 05/02/2012 Specificaties: - Hoogste kijkcijfers van de week, reclameblokken niet inbegrepen - Programma's langer dan 15 minuten - De marktaandelen worden sinds 1 januari 2006 berekend op basis van Totaal TV exclusief gebruik van randapparatuur zoals DVD, VCR, ... - Sinds januari 2010 geldt Live+6 als de nieuwe standaard. Live+6 is het totaal van het rechtstreeks tv kijken en het uitgesteld tv kijken op de dag van uitzending tot 6 dagen na uitzending. Description Channel Date Start Time R.Length North + guests rat% rat#_in_K shr% 1 DE PAPPENHEIMERS EEN 05/02/2012 20:31:29 00:59:12 34,9 2.055,629 66,6 2 WITSE EEN 05/02/2012 21:34:19 00:50:54 33,4 1.971,231 64,4 3 COLCHESTER ZOO EEN 05/02/2012 20:01:44 00:26:09 22,9 1.351,229 51,6 4 GOD EN KLEIN PIERKE - DANIEL TERMONT EEN 30/01/2012 20:39:29 00:52:54 22,6 1.331,700 42,9 5 HET 7 UUR-JOURNAAL EEN 02/02/2012 19:00:03 00:40:09 22,1 1.304,033 57,1 6 THUIS EEN 30/01/2012 20:11:56 00:25:25 21,5 1.268,420 42,9 7 MAN BIJT HOND EEN 30/01/2012 19:43:14 00:20:48 20,6 1.211,802 47,7 8 SPORTWEEKEND EEN 05/02/2012 19:22:17 00:33:49 19,5 1.148,120 43,7 9 FC DE KAMPIOENEN EEN 04/02/2012 20:43:22 00:33:11 16,8 990,625 39,3 10 BLOKKEN EEN 31/01/2012 18:31:44 00:26:18 16,8 987,763 53,0 11 THE VOICE VAN VLAANDEREN VTM 03/02/2012 20:50:38 02:04:05 16,4 965,416 38,5 12 DIEREN IN NESTEN EEN 04/02/2012 20:11:47 00:29:58 14,9 878,922 37,8 13 FAMILIE VTM 31/01/2012 20:11:16 00:28:41 -

Cim Tv Spring 2019
CIM TV SPRING 2019 1 MEDIALAAN – de Per sgroep Publishing takes the lead in Januar y! Gaining a , the MEDIALAAN – de Persgroep Publishing registered their best January ever. Three of our channels recorded significant growth: • VTM (+0,5% to 24,9%, VVA 18-54) • Vitaya (+0,6% to 6,1%, V 18-54) • CAZ (+0,3% to 2,6%, M 18-54) Q2 showed a slight decline (-0,7% to 7,7%, VVA 18-44). In fact this makes VTM the market leader for January. 2 Source: CIM Audimetrie 17u-24u / live+vosdal SEVERAL NEW PROGRAMMES HELPED KICK-START THE SPRING SEASON, TOGETHER WITH A NUMBER OF EXISTING MOVERS. DE LUIZENMOEDER Right from the start with episode 1, the new feel good series De Luizenmoeder managed to attract a large audience (1,133,000 viewers for episode 1). The average viewing figure for De Luizenmoeder is – equivalent to a (VVA 18-54). HOLLAND - BELGIE Following a pilot last year, Holland-België has now gained a 3 prominent place in the schedule and with a it has attained an excellent score (VVA 18-54). 30 YEARS OF VTM Obviously the first few weeks of 2019 focused in particular on 30 years of VTM, with a major show on 1 February as the high point. No less than 1,359,000 viewers joined us on our trip down memory lane! Moreover, several former cult programmes such as Blind Date were also given a slot in the schedule this spring. With impressive success: 787,000 viewers and 36,9% market share! 4 Studio Tarara, the very first fiction series launched by the production company Shelter, started this week with 679,000 viewers and 30,8% market share. -

Book JAVNOST 2-2014.Indb
GOVERNMENT INTERVENTION IN MARRIAGES OF CONVENIENCE BETWEEN TV BROADCASTERS AND KAREN DONDERS 110 - DISTRIBUTORS TOM EVENS Abstract Albeit largely neglected in communication sciences re- Karen Donders is Professor search, industrial convergence has put the relation between of Policy Analysis and legacy content media like TV broadcasters and distributors European Media Markets at (cable, satellite) fi rmly on the policy agenda. There seems to the Communication Sciences be an increasing awareness of the gatekeeping characteris- Department of the Vrije tics of mainstream as well as online video distribution, and Universiteit Brussel; e-mail: the power distributors can exert vis-à-vis television broad- [email protected]. casters in terms of the bundling of services and pricing. The relation between TV broadcasters and distributors is Tom Evens is Senior increasingly characterised by confl icts. Because of public Researcher at the Research 93 2, pp. (2014), No. Vol.21 disputes between broadcasters and distributors, and threats Group for Media & ICT of blackout, several governments across Europe are indeed (iMinds-MICT) at Ghent discussing the necessity of regulatory intervention in order University; e-mail: to decrease tension and promote cooperation in their media [email protected]. sectors. The article therefore questions how broadcasters have problematised their relation with distributors and put it on the policy agenda, whether it is up to governments to intervene in the relationship between broadcasters and distributors, and whether the proposed policy actions are likely to remedy the tensions in the marketplace. 93 Introduction Distribution has always been a key factor in content industries. Essentially, dis- tribution is the part of the media supply chain determining access to the audience. -
AWARDS BELGIUM up North Kwam Als Winnaar “Best Formule
EXPOSURE MUSIC AWARDS BELGIUM Up North kwam als winnaar “best formule. Drie genres met ieder hoe het allemaal begon... live” uit de bus, Vienna kaapte de twee finalisten, zorgden voor een prijs “best song” weg. fenomenale Awardnight. Felix De “godfather” van Exposure heet Pallas won nipt tegen Slow Pilot Jan De Bondt. Een prille vijftiger In 2013 organiseerden we de in “pop”. Stefan Dixon moest de die in 2010 ons concept bedacht. tweede editie inclusief showcases. duimen leggen tegen Milo Meskens Het idee ontstond in Londen, De finale werd gewonnen door in “singersong”. The Father, the waar hij al decennialang werkt en Marieke Lightband (“best live”) en Son and the Holy Simon haalden menig concertzalen heeft gezien. Portrait B (“best song”). Meer dan het net van Ides Moon in “rock/ Hieronder ook regelmatig Belgische 200 bands schreven zich in voor alternative”. bands, waaronder Zornik, Ozark vier genres. Henry, The Hickey Underworld... De plaats van onze vierde Award- In 2015 hadden we een zeer night blijft dezelfde: muziekclub Wanneer zijn toenmalige werkgever sterke editie met een verfijnde Nosta is nu de naam! Graham Nicholas het bankleven vaarwel zei, richtte hij samen met Dean Hill Exposure Music Awards UK op in 2007. Toen werd Jan reeds betrokken. Zo organiseerden ze regelmatig concerten in Londen, in samenwerking met Duvel en de Bar Music Hall in de hippe buurt Shoreditch. vi.be. We hebben daarnaast ook de UK blijven betrekken als juryleden, Hieruit ontstond het idee om het wat voor andere invalshoeken concept naar België te brengen. zorgt in het quoteren. Het grote verschil is dat er in de UK slechts één winnaar is, De eerste Awardnight vond plaats waar we in België opteren voor in maart 2011 in de Nijdrop, Opwijk. -

Van Eva, Noora En Isak Naar Jana, Zoë En Robbe
VAN EVA, NOORA EN ISAK NAAR JANA, ZOË EN ROBBE EEN VERGELIJKENDE FILMANALYSE TUSSEN HET NOORSE SKAM EN HAAR VLAAMSE FORMAT-ADAPTATIE WTFOCK Wetenschappelijk artikel Aantal woorden: 9.907 Fien Strobbe Stamnummer: 01503942 Promotor: Prof. dr. Stijn Joye Commissaris: dr. Eduard Cuelenaere Masterproef voorgelegd voor het behalen van de graad master in de Communicatiewetenschappen afstudeerrichting Film- en Televisiestudies Academiejaar: 2019 - 2020 Deze pagina is niet beschikbaar omdat ze persoonsgegevens bevat. Universiteitsbibliotheek Gent, 2021. This page is not available because it contains personal information. Ghent Universit , Librar , 2021. Woord vooraf Deze masterproef werd geschreven in het kader van mijn opleiding Communicatiewetenschappen met als afstudeerrichting Film- en televisiestudies aan de Universiteit Gent. Na een jaar intensief bezig geweest te zijn om dit onderzoek zo goed mogelijk te vervolledigen, stel ik u met trots het eindresultaat voor. Het schrijven van de masterproef mag dan wel een individueel werk zijn, maar dankzij de hulp en steun van prof. dr. Stijn Joye en dr. Jono Van Belle kreeg ik het afgelopen jaar een concrete visie over waar ik naar toe wilde. Mede door hun nuttige en constructieve feedback kon ik telkens terug verder aan de slag. Ook dank ik graag mijn vrienden die altijd voor mij klaar stonden wanneer ik vragen of problemen inzake de masterproef met hen besprak. Tot slot wil ik graag mijn ouders bedanken om mij de afgelopen vier jaar te steunen en altijd in mij te geloven. 1 Abstract The digital first series wtFOCK is currently a hot topic among the Flemish youth. The series origins in the Norwegian SKAM format, which has already been adapted in several European countries. -

The Voice Van Vlaanderen Nieuw Seizoen Vanaf 8 September 2017 Op Vrijdag Om 20.40
THE VOICE VAN VLAANDEREN NIEUW SEIZOEN VANAF 8 SEPTEMBER 2017 OP VRIJDAG OM 20.40 CLASH OF THE TITANS The clash of the titans. Dat wordt het vijfde seizoen van The Voice van Vlaanderen. Vier absolute autoriteiten uit de Vlaamse muziekwereld binden de strijd aan met elkaar. Allemaal gaan ze op zoek naar die ene vocale parel die hun team naar de overwinning kan loodsen. Onder hen een nieuw – bekend – gezicht, want coach Alex Callier is terug van weggeweest. Hij neemt samen met kleppers Koen Wauters, Natalia en Bart Peeters plaats op de coachstoel. Tijdens het Voice-parcours duikt er bovendien een belangrijke nieuwigheid op die de spanning de hoogte in jaagt… Wie weet één van de vier topcoaches te strikken en zingt zichzelf naar de Battles en de liveshows? Voor het vijfde seizoen verwelkomt The Voice van Vlaanderen een oude bekende op de draaistoel. Alex Callier, de man die Vlaanderen in seizoen 1 en 2 de ‘grain’ leerde kennen, keert met heel veel goesting terug. De reeks wordt ook de vijfde van ancien Koen Wauters, die met Lola zijn eerste overwinning opstak. Het coachkwartet wordt aangevuld met muzikale titanen Natalia en Bart Peeters. Begeleiding van de bovenste plank is voor de kandidaten dus ook dit jaar een garantie. Samen met host An Lemmens zorgen zij voor topentertainment op vrijdag. Dat The Voice van Vlaanderen voor velen een vaste entertainmentafspraak is, bewijzen de cijfers. Het vorige seizoen was wekelijks goed voor bijna 1 miljoen kijkers – 985.000 om precies te zijn – en 49,9% marktaandeel (VVA 18-54, alle cijfers live +7). -

WINTERSE GRIEZELTOCHTEN GEZELLIG GRIEZELEN MET HET GEZIN in ENKELE STAPPEN EEN TOPACTIVITEIT! Twee Griezelverhalen in Één Tocht
WINTERSE GRIEZELTOCHTEN GEZELLIG GRIEZELEN MET HET GEZIN IN ENKELE STAPPEN EEN TOPACTIVITEIT! Twee griezelverhalen in één tocht An Neven, schrijfster van (jong)volwassenverhalen, verzon speciaal voor kwb twee griezelverhalen. Haar schrijfstijl? Een vleugje humor met een stukje regenboog. Bent Van Looy, die de verhalen insprak, is alvast fan! -10 jarigen Amalia is een jonge heks die aan de Heksenacademie wil studeren. Ze moet eerst slagen voor het toelatingsexamen, en dat loopt niet helemaal goed… Een grappig verhaal voor kinderen met veel fantasie. +10 jarigen Vier tieners gaan in de zomer samen kamperen. Een van hen is dol op spooklegendes en wil achterhalen of ze echt waar zijn. Loopt dat goed af? Een spannend verhaal voor de stoere knapen onder ons. instagram nevenna_schrijft Organiseer een griezeltocht in jouw buurt Concept De winterse griezeltocht is een wandeltocht met als rode draad een griezelverhaal voor kinderen of tieners. De deelnemers vinden tijdens de tocht op 7 verschillende plaatsen een griezelbord. Op deze borden staat een QR-code waarmee ze telkens een deeltje van het griezelverhaal op de smartphone kunnen beluisteren. Na elk audiofragment krijgen de kinderen of jongeren als extraatje een opdracht die ze onderweg kunnen vervullen. Op het Leuk weetje: de verhalen werden ingesproken door einde van de wandeling hebben de deelnemers het hele griezelverhaal gehoord. Bent Van Looy. Hij is een Vlaamse zanger, componist en muzikant. Hij is frontman van Das Pop en jureerde Doelgroep meermaals in The Voice van Vlaanderen. Deze activiteit richt zich op gezinnen. De griezelborden zijn ontworpen op maat van kinderen. De verhalen zijn dan weer opgesplitst in een verhaal voor –10 jarigen en een iets griezeliger verhaal voor +10 jarigen. -

Lights Are Tim and His Team Worked Tirelessly Under Some Serious Many More; While in the UK, Robe Was Again the Major Really Too Numerous to List in Any Entirety
Eve ~nts 02 32Tele~ celebrates its 20th Anniversary in 2014 vision WE ARE ALL very proud of this landmark achievement, the largest Robe Review to date, featuring a fantastic new Sta and this is a big shout-out to everyone who has made it design and look. happen over the years and shared the enormous passion, The last 12 months have been among the most exciting in ~ge commitment and imagination that has helped develop and Robe’s history. We have focused on building our team and push our brand ~ and our ‘family’ ~ forward. 48 adding the experience and energy of some highly talented Thanks to all of you ~ your hard work and foresight is a people, ramping up several gears… in anticipation of constant inspiration. launching the BMFL series. 83 ~ Welcome to our 2013-14 Robe Review. It is a snapshot of We are very much looking forward to the next year and the Fest some of the diverse and innovative projects and contexts in future, to realising more dreams, expanding our community, ~ivals which our products have been used over the last year. and naturally, also to keeping firmly grounded! This is a bumper-edition of the Robe Review ~ 132 pages We will be continuing the great communication we enjoy of news, action and comment highlighting the dedication with our distributors, lighting designers, end users and all The~96 of many individuals, companies and organisations. It is interested parties - current, potential and future. atre Please enjoy reading! Josef Valchář 109Clu General Manager, CEO ~bs Chu116 ~rch ROBE12 REVIEW13 -14 Cont come Ven -

Annemie Turtelboom Inburgeren in Antwerpen Boekenbeurs 2013 Inhoud Dwars 84
studentenblad Universiteit Antwerpen dwarsnummer 84 | jaargang 13 december 2013 | gratis www.dwars.be Annemie Turtelboom inburgeren in Antwerpen boekenbeurs 2013 inhoud dwars 84 04 26 10 32 Annemie Turtelboom dossier: integratie 350 jaar kunst in ‘t Stad boekenbeurs Plichtbewust, doelgericht en gefocust Deel III over de geïntegreerde richtin- Fred Bervoets over de Academie voor Eens per jaar rept de boekminnende Belg handelt Vrouwe Justitia. dwars wikt en gen van Universiteit Antwerpen. Rector Schone Kunsten in gallerij ‘de Zwarte zich naar Antwerpen. Waarom? Pennen- weegt het justitie-apparaat. Verschoren spreekt. Panter’ . ridders spreken, dwars concludeert. cultuur onderwijs Antwerpen maatschappij 10 350 jaar kunst in Antwerpen 09 microscoop op 18 de dag van 03 editoriaal Fred Bervoets en de Academie wetenschap Sinterklaas 04 Annemie Turtelboom 11 utopia in absentia het Higgsdeeltje 24 Antwerpen Centraal de zeven hoofdzonden van Elvis Peeters 26 dossier: integratie kerkschip Sint Jozef Justitie 14 dwars neemt een loopje rector Verschoren vervolgt 32 boekenbeurs 16 moeder, waarom dopen met... 29 voorbeeldig student over de liefde voor het boek wij? Slongs Dievanongs judoka Roxane Taeymans 36 Antwerpen inspireert sociale druk of individualisme? Espectro 20 inburgeren in Antwerpen geen peulenschil 33 contraire satire 2 Coverfoto: Martijn Fraanje een storm ergens, ver weg editoriaal Vooreerst: moge schaamte en scheurbuik ons dag van Jezus voor de deur. De barmhartige Samaritaan die – naar mijn weten – nooit allen in het midden van de nacht bekruipen. een geldsom heeft gedoneerd. Akkoord, het opwekken van de doden en het verzorgen De Filipijnse tragedie kan de gulle Belg geen van de melaatsen zijn zeer aimabele en filantropische doeleinden. -
Een Publieksonderzoek Naar De Kijkmotieven En Receptie
UNIVERSITEIT GENT FACULTEIT POLITIEKE EN SOCIALE WETENSCHAPPEN De succesformat van talentenshows op commerciële televisie: Een publieksonderzoek naar de kijkmotieven en receptie Wetenschappelijke verhandeling Aantal woorden: 26.932 PIETER BULCKAERT MASTERPROEF COMMUNICATIEWETENSCHAPPEN Afstudeerrichting FILM & TELEVISIESTUDIES PROMOTOR: PROF. DR. DANIËL BILTEREYST COMMISSARIS: SUSAN VERTOONT ACADEMIEJAAR 2013 – 2014 1 Deze pagina is niet beschikbaar omdat ze persoonsgegevens bevat. Universiteitsbibliotheek Gent, 2021. This page is not available because it contains personal information. Ghent Universit , Librar , 2021. Inhoudsopgave Inhoudsopgave ........................................................................................................................................ 3 Abstract ................................................................................................................................................... 7 Dankwoord ............................................................................................................................................. 8 Inleiding .................................................................................................................................................. 9 Deel 1: literatuuronderzoek ................................................................................................................. 12 1. Reality-tv .................................................................................................................................. 12 1.1.