Unicode Request for Modification of Voqs Character Modifier Letter Small
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

Videotex/Teletext Presentation Level Protocol Syntax (North American PIPS) I
American Canadian National Adopted for Use by the Federal Government REFERENCE | NBS PUBLICATIONS r i(/. f 1 1 wS\3 No.121 1986 | North American PLPS i Government use. pederai d has been adopted l°'Fe " , Government are c0™e„,ation Level This standard within ,hc Federal ^^eUrie*■*.ca,ions available concerning 'ts . ds Publication . list the P . Processing Deta''S °n Processing Standards for a cornet the Standards Qf SSSCU-*- American <C !ri b Canadian National CL'UCX IJ A- Standards Standard Association .110-1983 T500-1983 NBS RESEARCH INFORMATION Videotex/Teletext CENTER Presentation Level Protocol Syntax North American PLPS Published in December, 1983 by American National Standards Institute, Inc. Canadian Standards Association 1430 Broadway 178 Rexdale Boulevard New York, NY 10018 Rexdale (Toronto), Ontario M9W 1R3 (Approved November 3, 1983) (Approved October 3, 1983) American National Standards and Canadian Standards Standards approved by the American National Standards Institute (ANSI) and the Canadian Standards Association (CSA) imply a consensus of those substantially concerned with their scope and provisions. These standards are intended as guides to aid the manufacturer, the consumer, and the general public. The existence of a standard does not in any respect preclude any of the above groups, whether they have approved the standard or not, from manufacturing, marketing, purchasing, or using products, processes, or procedures not conforming to the standard. These standards are subject to periodic review and users are cautioned to obtain the latest editions. In this standard, the words ''shall/' "should,” and "may" represent requirements, recommendations, and options, respectively, as specified in ANSI and CSA policy and style guides. -
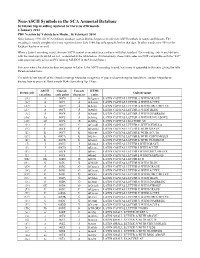
Non-ASCII Symbols in the SCA Armorial Database
Non-ASCII Symbols in the SCA Armorial Database by Iulstan Sigewealding, updated by Herveus d'Ormonde 4 January 2014 PDF Version by Yehuda ben Moshe, 16 February 2014 Since January 1996, the SCA Ordinary database (oanda.db) has begun to encode non-ASCII symbols in names and blazons. The encoding is mostly complete for items registered since July 1980, but only sporadic before that date. In other words, over 90% of the database has been revised. When a Latin-1 encoding exists, the non-ASCII symbol is encoded in accordance with that standard. The resulting code is an 8-bit byte with the most-significant bit set to 1, as detailed in the table below. (Unfortunately, these 8-bit codes are NOT compatible with the "437" code page normally active on PCs running MS-DOS in the United States.) For cases where the character does not appear in Latin-1, the ASCII encoding is used, but a note is appended to the entry giving the fully Da'ud encoded form. The table below lists all of the Da'ud encodings Morsulus recognizes. If you need something not listed there, contact Morsulus to discuss how to proceed. Don't simply Make Something Up. Please. ASCII Unicode Unicode HTML Da'ud code Unicode name encoding code point character entity {'A} A 00C0 À À LATIN CAPITAL LETTER A WITH GRAVE {A'} A 00C1 Á Á LATIN CAPITAL LETTER A WITH ACUTE {A^} A 00C2 Â Â LATIN CAPITAL LETTER A WITH CIRCUMFLEX {A~} A 00C3 Ã Ã LATIN CAPITAL LETTER A WITH TILDE {A:} A 00C4 Ä Ä LATIN CAPITAL LETTER A WITH DIAERESIS {Ao} Aa 00C5 Å Å LATIN CAPITAL LETTER -

MSR-4: Annotated Repertoire Tables, Non-CJK
Maximal Starting Repertoire - MSR-4 Annotated Repertoire Tables, Non-CJK Integration Panel Date: 2019-01-25 How to read this file: This file shows all non-CJK characters that are included in the MSR-4 with a yellow background. The set of these code points matches the repertoire specified in the XML format of the MSR. Where present, annotations on individual code points indicate some or all of the languages a code point is used for. This file lists only those Unicode blocks containing non-CJK code points included in the MSR. Code points listed in this document, which are PVALID in IDNA2008 but excluded from the MSR for various reasons are shown with pinkish annotations indicating the primary rationale for excluding the code points, together with other information about usage background, where present. Code points shown with a white background are not PVALID in IDNA2008. Repertoire corresponding to the CJK Unified Ideographs: Main (4E00-9FFF), Extension-A (3400-4DBF), Extension B (20000- 2A6DF), and Hangul Syllables (AC00-D7A3) are included in separate files. For links to these files see "Maximal Starting Repertoire - MSR-4: Overview and Rationale". How the repertoire was chosen: This file only provides a brief categorization of code points that are PVALID in IDNA2008 but excluded from the MSR. For a complete discussion of the principles and guidelines followed by the Integration Panel in creating the MSR, as well as links to the other files, please see “Maximal Starting Repertoire - MSR-4: Overview and Rationale”. Brief description of exclusion -

L2/08-034R Introduction There Are a Number of Characters in Unicode That Have Glyph Variants Which Are Not Yet Documented in the Unicode Standard
Request to document glyph variants Submitted by: Lorna A. Priest Submitted date: 18 April 2008 Doc #: L2/08-034R Introduction There are a number of characters in Unicode that have glyph variants which are not yet documented in The Unicode Standard. This document is a request to document those glyph variants. Suggested replacement chart We would like to request a change to “Figure 7-1. Alternative Glyphs in Latin.” 1. a ɑ g ɡ 2. Ɓ Ƃ Ħ Ħ 땲 Ŋ 똺 Ɲ Ɲ Ɔ ɔ 뒜 내 ƥ ƥ Ʋ ʋ ò ó 3. Was #2 4. Was #3 5. Was #4 A change to the text could be: “Common typographical variations of basic Latin letters include the open- and closed-loop forms of the lowercase letters “a” and “g”, as shown in the first example in Figure 7-1. In ordinary Latin text, such distinctions are merely glyphic alternates for the same characters; however, phonetic transcription systems, such as IPA and Pinyin, often make systematic distinctions between these forms. There are also typographical variations in various Latin-based orthographies. These are shown in example 2 in Figure 7-1. We would also recommend the addition of a similar chart in the Cyrillic section of the standard. Suggested text would follow what is currently in “7.1 Latin”: Alternative Glyphs. Some characters have alternative representations, although they have a common semantic. In such cases, a preferred glyph is chosen to represent the character in the code charts, even though it may not be the form used under all circumstances. -

Considerations in the Identification and Management of Variant Elements in Latin Script Tables for IDN Registration
Considerations in the identification and management of variant elements in Latin script tables for IDN registration Cary Karp Swedish Museum of Natural History This Support Brief was contributed to the ICANN VIP initiative by the host of its Latin script study, the Internet Infrastructure Foundation, with the support of the Swedish Museum of Natural History. The code points available for use in IDNs are all taken from the Unicode Character Code Charts. The Latin script is divided there into nine blocks. The one headed “Basic Latin” restates the ASCII repertoire and therefore includes the familiar letter-digit-hyphen (“LDH”) array to which TLD registries previously restricted all second-level domain names. The TLD labels, themselves, were further restricted to the letters in that repertoire. Latin letters other than the ‘a–z’ encoded in ASCII, as well as diacritically marked and otherwise decorated forms are presented in supplemental and extended Latin blocks, with further Latin letters in blocks under the heading “Phonetic Symbols”. Many of the marked letters can be represented with differing series of code points. Other letters that are intrinsically different and have different code points may share the same glyph. Protocol constraint renders the first of these situations tractable. Contextual restriction on the use of certain code points is necessary for the second. Basic concepts and considerations in the protocol and contextual management of these conditions are discussed below, with specific regard to the local collation of permissible IDN character repertoires and the identification of variant relationships among the listed characters. The rubric “Support Brief” indicates the intention of this text serving as a source document for the study group’s deliberations and report, without being a structured work in itself. -

Unicode Request for Modifier-Letter Support Background
Unicode request for modifier-letter support Kirk Miller, [email protected] 2020 April 14 Background This request expands on Peter Constable’s 2003 ‘Proposal to Encode Additional Phonetic Modifier Letters in the UCS’ (https://www.unicode.org/L2/L2003/03180-add-mod-ltr.pdf), and illustrates characters that were requested in that proposal, but not illustrated and therefore not accepted at the time. Constable’s notes (Section F of his proposal) included a good summary: In general, modifier letters are used in phonetic transcription to represent secondary aspects of articulation. Secondary articulations may involve aspects of simultaneous articulation that are considered to be in some sense less dominant to the basic sound (for instance, nasalized vowels are typically conceived in terms of their oral counterparts but with the additional secondary articulation of nasalization); or they may involve a transitional articulation of a type that might otherwise be considered a complete speech sound in its own right but for various reasons is interpreted by the linguist as a secondary element in a complex speech sound (for instance, diphthongs, or nasal onset of oral stop consonants). In some situations, the recommended transcription [by the International Phonetic Association] would not involve a modifier letter; thus, many of the proposed characters are not officially approved IPA notation. Nevertheless, the use of these modifier letters if fairly commonplace among linguists, even those that advocate the use of IPA. It’s notable that one of Constable’s illustrations, of ⟨ᶿ⟩, came from the IPA Handbook despite not being officially part of the alphabet. Such usage goes back over a century, with ⟨ʃᶜ̧⟩ given as an example in the IPA chart of 1900, and that among the linguists such usage is ‘commonplace among’ is Peter Ladefoged, president of the IPA from 1986 to 1991, organizer of the 1989 Kiel convention that overhauled the alphabet, and long-time editor of the IPA Journal (JIPA). -

The Unicode Cookbook for Linguists
The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran Michael Cysouw language Translation and Multilingual Natural science press Language Processing 10 Translation and Multilingual Natural Language Processing Editors: Oliver Czulo (Universität Leipzig), Silvia Hansen-Schirra (Johannes Gutenberg-Universität Mainz), Reinhard Rapp (Johannes Gutenberg-Universität Mainz) In this series: 1. Fantinuoli, Claudio & Federico Zanettin (eds.). New directions in corpus-based translation studies. 2. Hansen-Schirra, Silvia & Sambor Grucza (eds.). Eyetracking and Applied Linguistics. 3. Neumann, Stella, Oliver Čulo & Silvia Hansen-Schirra (eds.). Annotation, exploitation and evaluation of parallel corpora: TC3 I. 4. Czulo, Oliver & Silvia Hansen-Schirra (eds.). Crossroads between Contrastive Linguistics, Translation Studies and Machine Translation: TC3 II. 5. Rehm, Georg, Felix Sasaki, Daniel Stein & Andreas Witt (eds.). Language technologies for a multilingual Europe: TC3 III. 6. Menzel, Katrin, Ekaterina Lapshinova-Koltunski & Kerstin Anna Kunz (eds.). New perspectives on cohesion and coherence: Implications for translation. 7. Hansen-Schirra, Silvia, Oliver Czulo & Sascha Hofmann (eds). Empirical modelling of translation and interpreting. 8. Svoboda, Tomáš, Łucja Biel & Krzysztof Łoboda (eds.). Quality aspects in institutional translation. 9. Fox, Wendy. Can integrated titles improve the viewing experience? Investigating the impact of subtitling on the reception and enjoyment of film using eye tracking and questionnaire data. 10. Moran, Steven & Michael Cysouw. The Unicode cookbook for linguists: Managing writing systems using orthography profiles ISSN: 2364-8899 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran Michael Cysouw language science press Steven Moran & Michael Cysouw. 2018. The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles (Translation and Multilingual Natural Language Processing 10). -
Cyrillic Range: 0400–04FF
Cyrillic Range: 0400–04FF This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -
ISO/IEC 9995-3 Revision the Revised ISO/IEC 9995-3 Is Intended to Fulfill the Following Goals: 1
Information about the Revision of ISO/IEC 9995-3 Karl Pentzlin — [email protected] — 2009-09-16 This paper is no official SC35 document. All opinions presented in this paper are the personal opinions of the author. This picture shows the common secondary group (displayed in blue) applied to a US standard keyboard. 1. Introduction The ISO/IEC JTC 1/SC 35/WG 1 has decided to revise the existing ISO/IEC 9995-3 "Complementary layouts of the alphanumeric zone of the alphanumeric section" substantially. (Also, for more extensive needs, a new work item “ISO/IEC 9995-9 Multilingual, multiscript keyboard group layouts” is initiated.) The revision of ISO/IEC 9995-3 is currently to be circulated as FDIS (Final Draft International Standard) to the national bodies which will finally decide about it in the due process, which may result in a formal published standard out the first half of 2010. All information presented here, based on a FDIS (Final Draft International Standard), is final in principle, as in the FDIS state only editorial changes still can be made. Thus, while formally there is no guarantee that the standard in fact will be adopted, the information contained in the FDIS document can be considered as final and reliable, as there was no "No" vote in the previous FCD (Final Committee Draft) ballot. 2. The present edition of ISO/IEC 9995-3 The present edition of ISO/IEC 9995-3 was published in 2002 and is entitled: Information technology — Keyboard layouts for text and office systems — Part 3: Complementary layouts of the alphanumeric zone of the alphanumeric section The standard defines an "common secondary group layout", which is a mapping of characters to the unshifted and shifted positions (and, in one case, also to a third level beyond unshifted/shifted) of the 48 alphanumeric keys of a standard PC keyboard to be reached by a "group selector" (which could be a special key working similar to the "Right Alt" or"AltGr" key of some keyboards, but the exact mechanism is not subject of the standard).