Incorporating Predictor Network in Penalized Regression with Application to Microarray Data
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

The Activation of the Glucagon-Like Peptide-1 (GLP-1) Receptor by Peptide and Non-Peptide Ligands
The Activation of the Glucagon-Like Peptide-1 (GLP-1) Receptor by Peptide and Non-Peptide Ligands Clare Louise Wishart Submitted in accordance with the requirements for the degree of Doctor of Philosophy of Science University of Leeds School of Biomedical Sciences Faculty of Biological Sciences September 2013 I Intellectual Property and Publication Statements The candidate confirms that the work submitted is her own and that appropriate credit has been given where reference has been made to the work of others. This copy has been supplied on the understanding that it is copyright material and that no quotation from the thesis may be published without proper acknowledgement. The right of Clare Louise Wishart to be identified as Author of this work has been asserted by her in accordance with the Copyright, Designs and Patents Act 1988. © 2013 The University of Leeds and Clare Louise Wishart. II Acknowledgments Firstly I would like to offer my sincerest thanks and gratitude to my supervisor, Dr. Dan Donnelly, who has been nothing but encouraging and engaging from day one. I have thoroughly enjoyed every moment of working alongside him and learning from his guidance and wisdom. My thanks go to my academic assessor Professor Paul Milner whom I have known for several years, and during my time at the University of Leeds he has offered me invaluable advice and inspiration. Additionally I would like to thank my academic project advisor Dr. Michael Harrison for his friendship, help and advice. I would like to thank Dr. Rosalind Mann and Dr. Elsayed Nasr for welcoming me into the lab as a new PhD student and sharing their experimental techniques with me, these techniques have helped me no end in my time as a research student. -
Receptor Internalization Assays
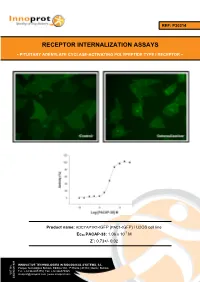
REF: P30214 RECEPTOR INTERNALIZATION ASSAYS - PITUITARY ADENYLATE CYCLASE-ACTIVATING POLYPEPTIDE TYPE I RECEPTOR - Product name: ADCYAP1R1-tGFP (PAC1-tGFP) / U2OS cell line -7 Ec50 PACAP-38: 1.06 x 10 M Z´: 0.73+/- 0.02 INNOVATIVE TECHNOLOGIES IN BIOLOGICAL SYSTEMS, S.L. Parque Tecnológico Bizkaia, Edifício 502, 1ª Planta | 48160 | Derio | Bizkaia Tel.: +34 944005355 | Fax: +34 946579925 VAT No. [email protected] | www.innoprot.com ESB95481909 Product Name: ADCYAP1R1-tGFP_U2OS Reference: P30214 Rep. Official Full Name: Pituitary adenylate cyclase- activating polypeptide type I receptor DNA Accession Number: Gene Bank AY366498 Host Cell: U2OS References: P30214: 2 vials of 3 x 106 proliferative cells P30214-DA: 1 vial of 2 x 106 division-arrested cells Storage: Liquid Nitrogen Assay Briefly description About ADCYAP1R1 Each vial of ADCYAP1R1 Internalization Assay Pituitary adenylate cyclase-activating Cell Line contains U2OS cells stably expressing polypeptide type I receptor, also known as human Pituitary adenylate cyclase-activating PAC1 is a protein that in humans is encoded by polypeptide type I receptor tagged in the N- the ADCYAP1R1 gene. ADCYAP1R1 is a terminus with tGFP protein. membrane-associated protein and shares significant homology with members of the Innoprot’s ADCYAP1R1-tGFP Internalization glucagon/secretin receptor family. This receptor Assay Cell Line has been designed to assay binds pituitary adenylate cyclase activating potential agonists/ antagonists against peptide (PACAP) mediating several biological ADCYAP1R1, modulating its activation and the activities and it is positively coupled to following redistribution process inside the cells. adenylate cyclase. This cell line will allow the image analysis of the stimuli induced by the compounds. -

Differential Gene Expression in Oligodendrocyte Progenitor Cells, Oligodendrocytes and Type II Astrocytes
Tohoku J. Exp. Med., 2011,Differential 223, 161-176 Gene Expression in OPCs, Oligodendrocytes and Type II Astrocytes 161 Differential Gene Expression in Oligodendrocyte Progenitor Cells, Oligodendrocytes and Type II Astrocytes Jian-Guo Hu,1,2,* Yan-Xia Wang,3,* Jian-Sheng Zhou,2 Chang-Jie Chen,4 Feng-Chao Wang,1 Xing-Wu Li1 and He-Zuo Lü1,2 1Department of Clinical Laboratory Science, The First Affiliated Hospital of Bengbu Medical College, Bengbu, P.R. China 2Anhui Key Laboratory of Tissue Transplantation, Bengbu Medical College, Bengbu, P.R. China 3Department of Neurobiology, Shanghai Jiaotong University School of Medicine, Shanghai, P.R. China 4Department of Laboratory Medicine, Bengbu Medical College, Bengbu, P.R. China Oligodendrocyte precursor cells (OPCs) are bipotential progenitor cells that can differentiate into myelin-forming oligodendrocytes or functionally undetermined type II astrocytes. Transplantation of OPCs is an attractive therapy for demyelinating diseases. However, due to their bipotential differentiation potential, the majority of OPCs differentiate into astrocytes at transplanted sites. It is therefore important to understand the molecular mechanisms that regulate the transition from OPCs to oligodendrocytes or astrocytes. In this study, we isolated OPCs from the spinal cords of rat embryos (16 days old) and induced them to differentiate into oligodendrocytes or type II astrocytes in the absence or presence of 10% fetal bovine serum, respectively. RNAs were extracted from each cell population and hybridized to GeneChip with 28,700 rat genes. Using the criterion of fold change > 4 in the expression level, we identified 83 genes that were up-regulated and 89 genes that were down-regulated in oligodendrocytes, and 92 genes that were up-regulated and 86 that were down-regulated in type II astrocytes compared with OPCs. -

Single-Cell Analysis of Crohn's Disease Lesions Identifies
bioRxiv preprint doi: https://doi.org/10.1101/503102; this version posted December 20, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Single-cell analysis of Crohn’s disease lesions identifies a pathogenic cellular module associated with resistance to anti-TNF therapy JC Martin1,2,3, G Boschetti1,2,3, C Chang1,2,3, R Ungaro4, M Giri5, LS Chuang5, S Nayar5, A Greenstein6, M. Dubinsky7, L Walker1,2,5,8, A Leader1,2,3, JS Fine9, CE Whitehurst9, L Mbow9, S Kugathasan10, L.A. Denson11, J.Hyams12, JR Friedman13, P Desai13, HM Ko14, I Laface1,2,8, Guray Akturk1,2,8, EE Schadt15,16, S Gnjatic1,2,8, A Rahman1,2,5,8, , M Merad1,2,3,8,17,18*, JH Cho5,17,*, E Kenigsberg1,15,16,17* 1 Precision Immunology Institute, Icahn School of Medicine at Mount Sinai, New York, NY 10029, USA. 2 Tisch Cancer Institute, Icahn School of Medicine at Mount Sinai, New York, NY 10029, USA. 3 Department of Oncological Sciences, Icahn School of Medicine at Mount Sinai, New York, NY 10029, USA. 4 The Dr. Henry D. Janowitz Division of Gastroenterology, Icahn School of Medicine at Mount Sinai, New York City, NY 10029, USA. 5 Charles Bronfman Institute for Personalized Medicine, Icahn School of Medicine at Mount Sinai, New York, NY 10029, USA. 6 Department of Colorectal Surgery, Icahn School of Medicine at Mount Sinai, New York, NY 10029, USA 7 Department of Pediatrics, Susan and Leonard Feinstein IBD Clinical Center, Icahn School of Medicine at Mount Sinai, New York, NY 10029, USA. -

G Protein-Coupled Receptors
S.P.H. Alexander et al. The Concise Guide to PHARMACOLOGY 2015/16: G protein-coupled receptors. British Journal of Pharmacology (2015) 172, 5744–5869 THE CONCISE GUIDE TO PHARMACOLOGY 2015/16: G protein-coupled receptors Stephen PH Alexander1, Anthony P Davenport2, Eamonn Kelly3, Neil Marrion3, John A Peters4, Helen E Benson5, Elena Faccenda5, Adam J Pawson5, Joanna L Sharman5, Christopher Southan5, Jamie A Davies5 and CGTP Collaborators 1School of Biomedical Sciences, University of Nottingham Medical School, Nottingham, NG7 2UH, UK, 2Clinical Pharmacology Unit, University of Cambridge, Cambridge, CB2 0QQ, UK, 3School of Physiology and Pharmacology, University of Bristol, Bristol, BS8 1TD, UK, 4Neuroscience Division, Medical Education Institute, Ninewells Hospital and Medical School, University of Dundee, Dundee, DD1 9SY, UK, 5Centre for Integrative Physiology, University of Edinburgh, Edinburgh, EH8 9XD, UK Abstract The Concise Guide to PHARMACOLOGY 2015/16 provides concise overviews of the key properties of over 1750 human drug targets with their pharmacology, plus links to an open access knowledgebase of drug targets and their ligands (www.guidetopharmacology.org), which provides more detailed views of target and ligand properties. The full contents can be found at http://onlinelibrary.wiley.com/doi/ 10.1111/bph.13348/full. G protein-coupled receptors are one of the eight major pharmacological targets into which the Guide is divided, with the others being: ligand-gated ion channels, voltage-gated ion channels, other ion channels, nuclear hormone receptors, catalytic receptors, enzymes and transporters. These are presented with nomenclature guidance and summary information on the best available pharmacological tools, alongside key references and suggestions for further reading. -

Multi-Functionality of Proteins Involved in GPCR and G Protein Signaling: Making Sense of Structure–Function Continuum with In
Cellular and Molecular Life Sciences (2019) 76:4461–4492 https://doi.org/10.1007/s00018-019-03276-1 Cellular andMolecular Life Sciences REVIEW Multi‑functionality of proteins involved in GPCR and G protein signaling: making sense of structure–function continuum with intrinsic disorder‑based proteoforms Alexander V. Fonin1 · April L. Darling2 · Irina M. Kuznetsova1 · Konstantin K. Turoverov1,3 · Vladimir N. Uversky2,4 Received: 5 August 2019 / Revised: 5 August 2019 / Accepted: 12 August 2019 / Published online: 19 August 2019 © Springer Nature Switzerland AG 2019 Abstract GPCR–G protein signaling system recognizes a multitude of extracellular ligands and triggers a variety of intracellular signal- ing cascades in response. In humans, this system includes more than 800 various GPCRs and a large set of heterotrimeric G proteins. Complexity of this system goes far beyond a multitude of pair-wise ligand–GPCR and GPCR–G protein interactions. In fact, one GPCR can recognize more than one extracellular signal and interact with more than one G protein. Furthermore, one ligand can activate more than one GPCR, and multiple GPCRs can couple to the same G protein. This defnes an intricate multifunctionality of this important signaling system. Here, we show that the multifunctionality of GPCR–G protein system represents an illustrative example of the protein structure–function continuum, where structures of the involved proteins represent a complex mosaic of diferently folded regions (foldons, non-foldons, unfoldons, semi-foldons, and inducible foldons). The functionality of resulting highly dynamic conformational ensembles is fne-tuned by various post-translational modifcations and alternative splicing, and such ensembles can undergo dramatic changes at interaction with their specifc partners. -

Immunobiology of VPAC2 Receptor
Aus der Medizinischen Poliklinik-Innenstadt der Ludwig-Maximilians-Universität München Direktor: Professor Dr. med. M. Reincke Immunobiology of the VPAC2 Receptor Dissertation zum Erwerb des Doktorgrades der Medizin an der Medizinischen Fakultät der Ludwig-Maximilians-Universität zu München Vorgelegt von Carola Grinninger aus München 2010 Mit Genehmigung der Medizinischen Fakultät der Universität München Berichterstatter: Prof. Dr. med. S. Schewe Mitberichterstatter: PD Dr. B. Bachmeier Prof. Dr. H. Kellner Prof. Dr. U. Gresser Betreuung durch den promovierten Mitarbeiter: PD Dr. P. J. Nelson Dekan: Prof. Dr. med. Dr. h.c. M. Reiser, FACR, FRCR Tag der mündlichen Prüfung: 07.10.2010 2 CONTENTS Contents……………………………………………………………………….…3 Summary…………………………………………………………………………5 1. Introduction……………………………………………………………………10 1.1 General introduction……………………………………………………...10 1.2 G-Protein-coupled Receptors…………………………………………….10 1.3 G-protein-coupled signalling…………………………………………….13 1.4 Molecularbiology and structure of VPAC Receptors………………...….15 1.5 Vasoactive Intestinal Peptide (VIP)……………………………………...22 1.5.1 Biochemical structure of vasoactive intestinal peptide………...............22 1.6 VIP and intracellular signaling…………………………………………...25 1.7 VIP and rheumatoid arthritis…………………………………..…………26 1.8 Hypothesis………………………………………………………………..29 2. Materials……………………………………………………..………………31 2.1 Bacteria ……………………………………………………………….…31 2.2 Vectors……………………………………………………………….…..31 2.3 Cells………………………………………………………………….…..32 2.4 Mice……………………………………………………………….….….33 2.5 Oligonucleotides………………………………………………….….…..33 -

Current Topics in Medicinal Chemistry, 2019, 19, 1399-1417 REVIEW ARTICLE
Send Orders for Reprints to [email protected] 1399 Current Topics in Medicinal Chemistry, 2019, 19, 1399-1417 REVIEW ARTICLE ISSN: 1568-0266 eISSN: 1873-4294 Impact Factor: Targeting the PAC1 Receptor for Neurological and Metabolic Disorders 3.442 The international journal for in-depth reviews on Current Topics in Medicinal Chemistry BENTHAM SCIENCE Chenyi Liao1, Mathilde P. de Molliens2, Severin T. Schneebeli1, Matthias Brewer1, Gaojie Song3, David Chatenet2, Karen M. Braas4, Victor May4,* and Jianing Li1,* 1Department of Chemistry, University of Vermont, Burlington, VT 05405, USA; 2INRS – Institut Armand-Frappier, 531 boul. des Prairies, Laval, QC H7V 1B7, Canada; 3Shanghai Key Laboratory of Regulatory Biology, Institute of Bio- medical Sciences and School of Life Sciences, East China Normal University, Shanghai, 200241, P.R. China; 4Department of Neurological Sciences, University of Vermont, Larner College of Medicine, 149 Beaumont Avenue, Bur- lington, VT 05405, USA Abstract: The pituitary adenylate cyclase-activating polypeptide (PACAP)-selective PAC1 receptor (PAC1R, ADCYAP1R1) is a member of the vasoactive intestinal peptide (VIP)/secretin/glucagon fam- ily of G protein-coupled receptors (GPCRs). PAC1R has been shown to play crucial roles in the central and peripheral nervous systems. The activation of PAC1R initiates diverse downstream signal transduc- tion pathways, including adenylyl cyclase, phospholipase C, MEK/ERK, and Akt pathways that regu- late a number of physiological systems to maintain functional homeostasis. Accordingly, at times of tissue injury or insult, PACAP/PAC1R activation of these pathways can be trophic to blunt or delay apoptotic events and enhance cell survival. Enhancing PAC1R signaling under these conditions has the potential to mitigate cellular damages associated with cerebrovascular trauma (including stroke), neu- A R T I C L E H I S T O R Y rodegeneration (such as Parkinson’s and Alzheimer's disease), or peripheral organ insults. -

CGRP Signaling Via CALCRL Increases Chemotherapy Resistance and Stem Cell Properties in Acute Myeloid Leukemia
International Journal of Molecular Sciences Article CGRP Signaling via CALCRL Increases Chemotherapy Resistance and Stem Cell Properties in Acute Myeloid Leukemia 1,2 1,2, 1,2, 1,2 Tobias Gluexam , Alexander M. Grandits y, Angela Schlerka y, Chi Huu Nguyen , Julia Etzler 1,2 , Thomas Finkes 1,2, Michael Fuchs 3, Christoph Scheid 3, Gerwin Heller 1,2 , Hubert Hackl 4 , Nathalie Harrer 5, Heinz Sill 6 , Elisabeth Koller 7 , Dagmar Stoiber 8,9, Wolfgang Sommergruber 10 and Rotraud Wieser 1,2,* 1 Division of Oncology, Department of Medicine I, Medical University of Vienna, Waehringer Guertel 18-20, 1090 Vienna, Austria; [email protected] (T.G.); [email protected] (A.M.G.); [email protected] (A.S.); [email protected] (C.H.N.); [email protected] (J.E.); thomas.fi[email protected] (T.F.); [email protected] (G.H.) 2 Comprehensive Cancer Center, Spitalgasse 23, 1090 Vienna, Austria 3 Department I of Internal Medicine, Center for Integrated Oncology Aachen Bonn Cologne Duesseldorf, University of Cologne, Kerpener Str. 62, 50937 Cologne, Germany; [email protected] (M.F.); [email protected] (C.S.) 4 Institute of Bioinformatics, Biocenter, Medical University of Innsbruck, Innrain 80, 6020 Innsbruck, Austria; [email protected] 5 Department for Cancer Research, Boehringer Ingelheim RCV GmbH & Co KG, Dr. Boehringer-Gasse 5-11, A-1121 Vienna, Austria; [email protected] 6 Division of Hematology, Medical University of Graz, Auenbruggerplatz -

Neuronal, Stromal, and T-Regulatory Cell Crosstalk in Murine Skeletal Muscle
Neuronal, stromal, and T-regulatory cell crosstalk in murine skeletal muscle Kathy Wanga,b,1,2, Omar K. Yaghia,b,1, Raul German Spallanzania,b,1, Xin Chena,b,3, David Zemmoura,b,4, Nicole Laia, Isaac M. Chiua, Christophe Benoista,b,5, and Diane Mathisa,b,5 aDepartment of Immunology, Harvard Medical School, Boston, MA 02115; and bEvergrande Center for Immunologic Diseases, Harvard Medical School and Brigham and Women’s Hospital, Boston, MA 02115 Contributed by Diane Mathis, January 15, 2020 (sent for review December 23, 2019; reviewed by David A. Hafler and Jeffrey V. Ravetch) A distinct population of Foxp3+CD4+ regulatory T (Treg) cells pro- reduced in aged mice characterized by poor muscle regeneration + motes repair of acutely or chronically injured skeletal muscle. The (7). IL-33 mSCs can be found in close association with nerve accumulation of these cells depends critically on interleukin (IL)-33 pro- structures in skeletal muscle, including nerve fibers, nerve bun- duced by local mesenchymal stromal cells (mSCs). An intriguing phys- + dles, and muscle spindles that control proprioception (7). ical association among muscle nerves, IL-33 mSCs, and Tregs has been Given the intriguing functional and/or physical associations reported, and invites a deeper exploration of this cell triumvirate. Here + among muscle nerves, mSCs, and Tregs, and in particular, their we evidence a striking proximity between IL-33 muscle mSCs and co-ties to IL-33, we were inspired to more deeply explore this both large-fiber nerve bundles and small-fiber sensory neurons; report axis. Here, we used whole-mount immunohistochemical imag- that muscle mSCs transcribe an array of genes encoding neuropep- ing as well as population-level and single-cell RNA sequencing tides, neuropeptide receptors, and other nerve-related proteins; define (scRNA-seq) to examine the neuron/mSC/Treg triumvirate in muscle mSC subtypes that express both IL-33 and the receptor for the calcitonin-gene–related peptide (CGRP); and demonstrate that up- or hindlimb muscles. -

Gpcrs Globally Coevolved with Receptor Activity-Modifying Proteins, Ramps
GPCRs globally coevolved with receptor activity-modifying proteins, RAMPs Shahar Barbasha, Emily Lorenzena, Torbjörn Perssona,b, Thomas Hubera,1, and Thomas P. Sakmara,b,1 aLaboratory of Chemical Biology and Signal Transduction, The Rockefeller University, New York, NY, 10065; and bDepartment of Neurobiology, Care Sciences and Society, Division for Neurogeriatrics, Center for Alzheimer Research, Karolinska Institutet, 141 57 Huddinge, Sweden Edited by Andrew C. Kruse, Harvard University, and accepted by Editorial Board Member K. C. Garcia September 28, 2017 (received for review July 22, 2017) Receptor activity-modifying proteins (RAMPs) are widely expressed between the two. Therefore, highly coevolved protein pairs could in human tissues and, in some cases, have been shown to affect be members in the same pathway, or they could be components surface expression or ligand specificity of G-protein–coupled recep- of the same complex. tors (GPCRs). However, whether RAMP−GPCR interactions are wide- Previously, several cases of coevolution of receptor genes and spread, and the nature of their functional consequences, remains their endogenous protein−ligand genes were reported (13), but largely unknown. In humans, there are three RAMPs and over large-scale coevolution of different signal transduction components 800 expressed GPCRs, making direct experimental approaches chal- was not examined. Phylogenetic analysis to conclude coevolution lenging. We analyzed relevant genomic data from all currently avail- could be implemented by two complementary approaches. The able sequenced organisms. We discovered that RAMPs and GPCRs first searches for ortholog genes across species with the assumption tend to have orthologs in the same species and have correlated that interacting proteins would tend to coexist in genomes (10). -

MCR-17-2-Highlights 335..335
Molecular Cancer Research Highlights February 2019 * Volume 17 * Number 2 Selected Articles from This Issue Protein-protein interaction network involving genes associated with GO:receptor activity Pan-Cancer Metastasis Correlates TGFBR3 ACVR2A NR2C2 NR2F1 AHR HNF4G HNF4A GRIK5 ARNT CALCRL CRCP ASGR1 TLR4 TLR5 GRID2 et al. DLG3 MED13 CFI TSHR ASGR2 TNFRSF4 CD226 Chen and Zhang Page 476 TLR1 ERBB4 MED17 SEC63 TLR10 AGER GRIA2 NR0B2 MED30 GLP1R LHCGR DERL1 TNFRSF9 ITGB2 KCNJ1 ESRRG NR5A2 Chen and Zhang and colleagues describe a systematic analysis SEC62 SORL1 MERTK BMPR2 GPR183 TRAM1 BMPR1A CFTR KCNH2 GPC6 of molecular correlates of metastasis using The Cancer Genome NRP1 PTPRR EPHB6 CD80 MED14 MED1 PPARA CELSR2 NCAM1 RYK CD86 Atlas (TCGA) datasets across 11 different cancer types, with data PPARG STRA6 EPNA3 LRP2 EFNB2 INTS6 CD28 PIGR ESRRB involving mRNA, microRNA, protein, and DNA methylation. NR4A2 THRAP3 TFRC GRM5 CD79B FLT1 ATP6AP2 NTRK1 INSRR NR3C1 XPR1 While some differential expression patterns associated with FCGR2C KDR ITGB1 CD79A CD3G AMOT ITGA4 IL2RA INSR PTPRC metastasis may be shared across multiple cancer types, each NR2F2 CD4 FZD4 DDR2 CXCR5 CD36 CD46 ITGAV ITGB6 VTN one also shows a metastasis signature that is distinct. When DLG1 CXCR4 CD1D IFNAR1 CALM3 GRM7 CNR1 FZD5 CD55 HCRTR1 combining TCGA data with that from multiple independent ADRB1 GABRR1 CSF1R NPC1 CR2 GABRR2 F2R F2 KCNQ5 CD47 LIFR ANTXR2 MET CD97 GP1BA fi LRP6 CR1 P2RX2 ABCC9 IL6ST pro ling datasets of metastatic tumors, the resulting catalog of FLT4 OSMR PTPRH P2RX4 KCNJ8 CUL5 GHR PTPRB gene-level alterations, according to cancer type, provides a Higher expression in metastasis versus primary for given cancer type BRCA CESC CRC ESCA HNSC PAAD PCPG PRAD SARC SKCM THCA resource for future studies.