Efficient Algorithms for Large-Scale Image Analysis
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
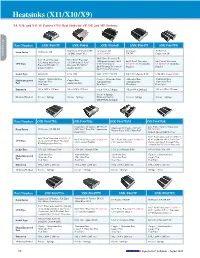
Heatsinks (X11/X10/X9)
Heatsinks (X11/X10/X9) X9, X10, and X11 1U Passive CPU Heat Sinks for UP, DP, and MP Systems Accessories Part Number SNK-P0037P SNK-P0041 SNK-P0046P SNK-P0047P SNK-P0047PD Proprietary 1U Passive, DP 1U Passive, UP 1U Passive, 1U Passive, Form Factor 1U Passive, DP (X9DBL Front CPU) (X11/X10/X9) UP, DP Proprietary, DP Intel® Xeon® Processor E3- Intel® Xeon® Processor Intel® Xeon® Processor 1200 product family; Intel® Intel® Xeon® Processor Intel® Xeon® Processor E5-2400 & Intel® Xeon® E5-2400 & Intel® Xeon® CPU Type Core™ i3 processor; E5-2600 v4/v3/v2 product E5-2600 v4/v3/v2 product Processor E5-2400 v2 Processor E5-2400 v2 Intel® Pentium® Processor & families families product families product families Intel® Celeron® Processor Socket Type LGA 1356 LGA 1356 LGA 1155/1151/1150 LGA 2011(Square ILM) LGA 2011 (Square ILM) Copper + Aluminum Base Copper + Aluminum Base Aluminum Base Aluminium Base Major Integrated Copper Base Aluminum Fins Aluminum Fins Aluminum Fins Aluminium Fins Part Aluminum Fins Heat Pipes Heat Pipes Heat Pipes Heat Pipes Dimension 90L x 90W x 27H mm 90L x 90W x 27H mm 95L x 95W x 27H mm 90L x 90W x 26H mm 90L x 110W x 27H mm Screws + Springs Mounting Method Screws + Springs Screws + Springs Mounting Bracket Screws + Springs Screws + Springs (BKT-0028L Included) Part Number SNK-P0047PS SNK-P0047PSC SNK-P0047PSM SNK-P0047PSR Proprietary 1U Passive, DP (1U 3/4 Low Profile Passive, Proprietary, Proprietary 1U Passive, DP (2U Form Factor 1U Passive, UP, DP, MP GPU/Intel® Xeon Phi™ coprocessor UP (X10/X9) Twin2+ Front CPU), -

Efficient Algorithms for Large-Scale Image Analysis
Efficient Algorithms for Large-Scale Image Analysis zur Erlangung des akademischen Grades eines Doktors der Ingenieurwissenschaften der Fakultät für Informatik des Karlsruher Instituts für Technologie genehmigte Dissertation von Jan Wassenberg aus Koblenz Tag der mündlichen Prüfung: 24. Oktober 2011 Erster Gutachter: Prof. Dr. Peter Sanders Zweiter Gutachter: Prof. Dr.-Ing. Jürgen Beyerer Abstract The past decade has seen major improvements in the capabilities and availability of imaging sensor systems. Commercial satellites routinely provide panchromatic images with sub-meter resolution. Airborne line scanner cameras yield multi-spectral data with a ground sample distance of 5 cm. The resulting overabundance of data brings with it the challenge of timely analysis. Fully auto- mated processing still appears infeasible, but an intermediate step might involve a computer-assisted search for interesting objects. This would reduce the amount of data for an analyst to examine, but remains a challenge in terms of processing speed and working memory. This work begins by discussing the trade-offs among the various hardware architectures that might be brought to bear upon the problem. FPGA and GPU-based solutions are less universal and entail longer development cycles, hence the choice of commodity multi-core CPU architectures. Distributed processing on a cluster is deemed too costly. We will demonstrate the feasibility of processing aerial images of 100 km × 100 km areas at 1 m resolution within 2 hours on a single workstation with two processors and a total of twelve cores. Because existing approaches cannot cope with such amounts of data, each stage of the image processing pipeline – from data access and signal processing to object extraction and feature computation – will have to be designed from the ground up for maximum performance. -
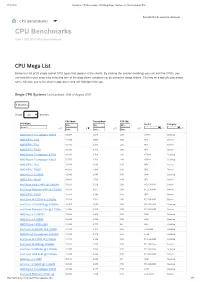
CPU Benchmarks - CPU Mega Page - Detailed List of Benchmarked Cpus
27.08.2020 PassMark - CPU Benchmarks - CPU Mega Page - Detailed List of Benchmarked CPUs CPU Benchmarks CPU Benchmarks Over 1,000,000 CPUs Benchmarked CPU Mega List Below is a list of all single socket CPU types that appear in the charts. By clicking the column headings you can sort the CPUs, you can also filter your search by selecting one of the drop down categories or by using the range sliders. Clicking on a specific processor name will take you to the chart it appears in and will highlight it for you. Single CPU Systems Last Updated: 26th of August 2020 Columns Show All entries CPU Mark Thread Mark TDP (W) CPU Name Min... - Min... - Min... - Socket Category Search... ▲▼ Max... ▲▼ Max... ▲▼ Max... ▲▼ ▲▼ ▲▼ AMD Ryzen Threadripper 3990X 80,087 2,518 280 sTRX4 Desktop AMD EPYC 7702 71,362 2,067 200 SP3 Server AMD EPYC 7742 67,185 2,376 225 SP3 Server AMD EPYC 7702P 64,395 2,316 200 SP3 Server AMD Ryzen Threadripper 3970X 64,015 2,704 280 sTRX4 Desktop AMD Ryzen Threadripper 3960X 55,707 2,702 280 sTRX4 Desktop AMD EPYC 7452 53,478 2,290 155 SP3 Server AMD EPYC 7502P 48,021 1,938 180 SP3 Server AMD Ryzen 9 3950X 39,246 2,743 105 AM4 Desktop AMD EPYC 7402P 39,118 1,742 180 SP3 Server Intel Xeon Gold 6248R @ 3.00GHz 38,521 2,270 205 FCLGA3647 Server Intel Xeon Platinum 8280 @ 2.70GHz 37,575 2,011 205 FCLGA3647 Server AMD EPYC 7302P 37,473 2,143 155 SP3 Server Intel Xeon W-3275M @ 2.50GHz 37,104 2,561 205 FCLGA3647 Server Intel Core i9-10980XE @ 3.00GHz 33,967 2,636 165 FCLGA2066 Desktop Intel Xeon Platinum 8168 @ 2.70GHz 33,398 2,167 205 -

Intel®Server Boards S2400LP
Intel® Server Boards S2400LP Technical Product Specification Intel order number G52803-002 Revision 2.0 December 2013 Platform Collaboration and Systems Division - Marketing Revision History Intel® Server Boards S2400LP TPS Revision History Date Revision Modifications Number May 2012 1.0 Initial release. December 2013 2.0 Added support for Intel® Xeon® processor E5-2400 v2 product family ii Intel order number G52803-002 Revision 2.0 Intel® Server Boards S2400LP TPS Disclaimers Disclaimers INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. A "Mission Critical Application" is any application in which failure of the Intel Product could result, directly or indirectly, in personal injury or death. SHOULD YOU PURCHASE OR USE INTEL'S PRODUCTS FOR ANY SUCH MISSION CRITICAL APPLICATION, YOU SHALL INDEMNIFY AND HOLD INTEL AND ITS SUBSIDIARIES, SUBCONTRACTORS AND AFFILIATES, AND THE DIRECTORS, OFFICERS, AND EMPLOYEES OF EACH, HARMLESS AGAINST ALL CLAIMS COSTS, DAMAGES, AND EXPENSES AND REASONABLE ATTORNEYS' FEES ARISING OUT OF, DIRECTLY OR INDIRECTLY, ANY CLAIM OF PRODUCT LIABILITY, PERSONAL INJURY, OR DEATH ARISING IN ANY WAY OUT OF SUCH MISSION CRITICAL APPLICATION, WHETHER OR NOT INTEL OR ITS SUBCONTRACTOR WAS NEGLIGENT IN THE DESIGN, MANUFACTURE, OR WARNING OF THE INTEL PRODUCT OR ANY OF ITS PARTS. -

Superworkstations
SuperWorkstations Enterprise-Class Systems Optimized for Media & Entertainment, Engineering, and Research 5038A-iL 7047GR-TRF 7047AX-TRF/72RF 7047A-T/73 7037A-i/iL High Performance GPU Optimized Hyper-Speed Storage Optimized w/ Dual CPU Workstation Versatile Features & I/O w/ 5 GPUs Workstation 8x SATA/ SAS 2.0 HDDs Mini-Tower Access Performance • Efficiency • Expandability • Reliability • Optimized Applications : Video Editing, Digital Content Creation, CAD/CAE/CAM Software Development, Scientific Research and Oil & Gas Applications • Whisper-Quiet 21dB Acoustics Models • Redundant Platinum Level (95%+) Digital Power Supplies Available • Up to 1TB DDR3 memory and 8x Hot-Swap HDDs • Up to 5x GPUs supported with PCI-E 3.0 x16 • Supports Intel® Xeon® Processor E5-2600/2400/1600 v2 series up to 150W CPUs and E3-1200 v3 Product Families • Server-Grade Design for 24x7 Operation www.supermicro.com/SuperWorkstations April 2014 High-Performance, High-Efficiency for Personal SuperComputing Hyper-Speed Workstation The Only 4+1 GPU New! Outperforms by 20% System in the Market Whisper-Quiet DP Compact High-End High Performance, Versatile Most Cost-Effective Whisper-Quiet Entry Level via Hardware Acceleration Up to 67% Performance Gain Solution with SAS DP Solution Compact DP Solution Features & I/O Access Maximus System Cost-Effective Solution ULTIMATE ULTIMATE HIGH END HIGH END MAINSTREAM MAINSTREAM MAINSTREAM ENTRY LEVEL SYSTEM 7047AX-TRF/72RF 7047GR-TRF 7047A-T/73 7037A-i 7037A-iL 5038A-iL 5037A-i 5037A-iL Socket R LGA 2011 Socket R LGA 2011 Socket -

Intel's Core 2 Family
Intel’s Core 2 family - TOCK lines II Nehalem to Haswell Dezső Sima Vers. 3.11 August 2018 Contents • 1. Introduction • 2. The Core 2 line • 3. The Nehalem line • 4. The Sandy Bridge line • 5. The Haswell line • 6. The Skylake line • 7. The Kaby Lake line • 8. The Kaby Lake Refresh line • 9. The Coffee Lake line • 10. The Cannon Lake line 3. The Nehalem line 3.1 Introduction to the 1. generation Nehalem line • (Bloomfield) • 3.2 Major innovations of the 1. gen. Nehalem line 3.3 Major innovations of the 2. gen. Nehalem line • (Lynnfield) 3.1 Introduction to the 1. generation Nehalem line (Bloomfield) 3.1 Introduction to the 1. generation Nehalem line (Bloomfield) (1) 3.1 Introduction to the 1. generation Nehalem line (Bloomfield) Developed at Hillsboro, Oregon, at the site where the Pentium 4 was designed. Experiences with HT Nehalem became a multithreaded design. The design effort took about five years and required thousands of engineers (Ronak Singhal, lead architect of Nehalem) [37]. The 1. gen. Nehalem line targets DP servers, yet its first implementation appeared in the desktop segment (Core i7-9xx (Bloomfield)) 4C in 11/2008 1. gen. 2. gen. 3. gen. 4. gen. 5. gen. West- Core 2 Penryn Nehalem Sandy Ivy Haswell Broad- mere Bridge Bridge well New New New New New New New New Microarch. Process Microarchi. Microarch. Process Microarch. Process Process 45 nm 65 nm 45 nm 32 nm 32 nm 22 nm 22 nm 14 nm TOCK TICK TOCK TICK TOCK TICK TOCK TICK (2006) (2007) (2008) (2010) (2011) (2012) (2013) (2014) Figure : Intel’s Tick-Tock development model (Based on [1]) * 3.1 Introduction to the 1. -

Robo-8121Vg2 Vg2a
Intel® CoreTM Xeon E5 2400 Series Processor based PICMG 1.3 SHB with DDR3 SDRAM, ROBO-8121VG2 DVI-I, Dual Gigabit Ethernet, Audio and USB VG2A FEATURES GENERAL CPU & Package: Intel® CoreTM Xeon E5 2400 processor (Ivy Bridge-EN) ® Processor Support Intel Core Xeon E5 2400 Series in LGA 1356 Socket processors in LGA 1356 package Chipset/Core Logic Intel® C604 PCH Delivers up to 192GB DDR3 1066/1333 System Memory Up to 192GB DDR3 1066/1333 ECC SDRAM on six 240-pin DIMM sockets on six DIMM sockets BIOS AMI EFI BIOS Matrox G200A Graphic Storage Devices SATA: Support One On-board SATA 600, One SATA 600 (via backplane) Watchdog Timer Programmable via software from 0.5 sec. to 254.5 sec. Expansion Interface Two PCIE x 16 and One PCIE x 4 Hardware Monitoring System monitor (fan, temperature, voltage) Dimension Dimension: 338.5(L) x 126.39(W) / 13.33”(L) x 4.98” (W) Environment Operating Temperature: 0 to 55oC Storage Temperature: -20 to 80oC Relative Humidity: 5% to 90%, non-condensing I/O MIO Two serial (RS-232) RXTX on via backplane USB Six USB 2.0 ports (Four USB ports via backplane) Ethernet -Dual 10BASE-T/100BASE-TX/1000BASE-T Ethernet -PCI Express x1 interface based Gigabit Ethernet -Dual RJ-45 connector with two LED indicators ORDERING GUIDE Keyboard & Mouse Two USB 2.0 ports on bracket dedicated to keyboard & mouse Standard ROBO-8121VG2 PICMG 1.3(PCI-E+PCI).Intel Core Xeon E5 Series processors.SHB.w/Dual GbE DISPLAY ® Graphic Controller - Matrox G200A Graphic Chip Display Interface Support one VGA port on I/O bracket * Specifications are subject to change without notice. -
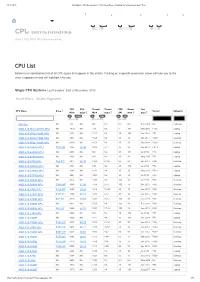
CPU Benchmarks - CPU Mega Page - Detailed List of Benchmarked Cpus
29.11.2019 PassMark - CPU Benchmarks - CPU Mega Page - Detailed List of Benchmarked CPUs 1 2 3 4 5 1 1 40000 1 4000 1 400 2 3 4 5 1 40000 1 4000 1 400 CPU Benchmarks Over 1,000,000 CPUs Benchmarked CPU List Below is an alphabetical list of all CPU types that appear in the charts. Clicking on a specific processor name will take you to the chart it appears in and will highlight it for you. Single CPU Systems Last Updated: 29th of November 2019 Reset Filters Enable Pagination CPU CPU Thread Thread TDP Power Test CPU Name Price 1 Socket Category Mark Value 2 Mark Value 3 (W) Perf. 4 Date 5 1 40000 1 4000 1 400 686 Gen NA 288 NA NA NA NA NA Feb 2009 NA Unknown AMD A10 Micro-6700T APU NA 1970 NA 778 NA 5 394 May 2015 FT3b Laptop AMD A10 PRO-7350B APU NA 3152 NA 1012 NA 19 165 Jun 2014 FP3 Laptop AMD A10 PRO-7800B APU NA 4997 NA 1559 NA 65 76 Oct 2014 FM2+ Desktop AMD A10 PRO-7850B APU NA 5380 NA 1601 NA 95 56 Nov 2014 FM2+ Desktop AMD A10-4600M APU $109.95 3115 28.34 1005 9.14 35 89 Apr 2012 FS1r2 Laptop AMD A10-4655M APU NA 2605 NA 861 NA 25 104 Jul 2012 FP2 Laptop AMD A10-4657M APU NA 2906 NA 887 NA 35 83 May 2013 FP2 Laptop AMD A10-5700 APU $64.50* 4214 65.35 1358 21.06 65 64 Jun 2012 FM2 Desktop AMD A10-5745M APU NA 2764 NA 913 NA 25 110 Jul 2013 FP2 Laptop AMD A10-5750M APU NA 3340 NA 1108 NA 35 95 May 2013 FS1r2 Laptop AMD A10-5757M APU NA 3084 NA 1063 NA 35 88 Jul 2013 FP2 Laptop AMD A10-5800B APU NA 4614 NA 1489 NA 100 46 Jul 2013 FM2 Desktop AMD A10-5800K APU $149.99* 4649 31.00 1458 9.72 100 46 Oct 2012 FM2 Desktop AMD A10-6700 APU -
Processor Socket Types Pdf
Processor socket types pdf Continue The LGA 775, the Socket AM2 earth grid socket mesh connector in computer hardware, processor connector or processor slot contains one or more mechanical components that provide mechanical and electrical connections between the microprocessor and the printed circuit board (PCB). This allows you to place and replace the CPU without solder. Common outlets have retention clips that apply constant force that must be overcome when the device is inserted. For chips with a large number of pins, zero insertion force (SIF) is preferable. Common outlets include Pin Grid Array (PGA) or Land Grid Array (LGA). These structures apply compression force after either the pen (PGA type) or surface plate (LGA type) is put in place. This provides excellent mechanical retention while avoiding the risk of bending the pin when inserting the chip into the socket. Some devices use Ball Grid Array (BGA) connectors, although they require soldering and are generally not considered replaceable by users. CPU connectors are used on the motherboard on desktop and server computers. Because they make it easy to change components, they are also used to prototyply prototype new circuits. Laptops typically use surface-mount processors that take up less space on the motherboard than sockets. As the density of pins in modern sockets increases, the requirements for the technique of making circuit boards increase, which allows you to successfully send a large number of signals to nearby components. Similarly, within the chip carrier, the technology of wire communication also becomes more demanding with the increase in the number of contacts and the density of the pin. -

X9DBU-3F 1.1.Indb
X9DBU-3F X9DBU-iF USER’S MANUAL Revision 1.1 The information in this User’s Manual has been carefully reviewed and is believed to be accurate. The vendor assumes no responsibility for any inaccuracies that may be contained in this document, and makes no commitment to update or to keep current the information in this manual, or to notify any person or organization of the updates. Please Note: For the most up-to-date version of this manual, please see our Website at www.supermicro.com. Super Micro Computer, Inc. ("Supermicro") reserves the right to make changes to the product described in this manual at any time and without notice. This product, including software and docu- mentation, is the property of Supermicro and/or its licensors, and is supplied only under a license. Any use or reproduction of this product is not allowed, except as expressly permitted by the terms of said license. IN NO EVENT WILL SUPER MICRO COMPUTER, INC. BE LIABLE FOR DIRECT, INDIRECT, SPECIAL, INCIDENTAL, SPECULATIVE OR CONSEQUENTIAL DAMAGES ARISING FROM THE USE OR INABILITY TO USE THIS PRODUCT OR DOCUMENTATION, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. IN PARTICULAR, SUPER MICRO COMPUTER, INC. SHALL NOT HAVE LIABILITY FOR ANY HARDWARE, SOFTWARE, OR DATA STORED OR USED WITH THE PRODUCT, INCLUDING THE COSTS OF REPAIRING, REPLACING, INTEGRATING, INSTALLING OR RECOVERING SUCH HARDWARE, SOFTWARE, OR DATA. Any disputes arising between the manufacturer and the customer shall be governed by the laws of Santa Clara County in the State of California, USA. The State of California, County of Santa Clara shall be the exclusive venue for the resolution of any such disputes. -

Intel®Server Board S2400GP
Intel® Server Board S2400GP Technical Product Specification Intel order number G50295-002 Revision 1.1 September, 2013 Enterprise Platforms and Services Division - Marketing Revision History Intel® Server Board S2400GP (Preliminary) TPS Revision History Date Revision Modifications Number May 2012 1.0 Initial release. May 2012 1.01 Add NIC Port MAC address. January 2013 1.02 Fix some typo. December 2013 1.1 Correct Memory support information in page 2 Disclaimers Information in this document is provided in connection with Intel® products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel®’s Terms and Conditions of Sale for such products, Intel® assumes no liability whatsoever, and Intel® disclaims any express or implied warranty, relating to sale and/or use of Intel® products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel® products are not intended for use in medical, life-saving, or life sustaining applications. Intel® may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or “undefined”. Intel® reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Intel® Server Board S2400GP may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. -

Introducing the Intel® Xeon® Processor E5 Family
Built to Scale: Introducing the Intel® Xeon® Processor E5 Family Abdulkariem Abusharkh Business Development Manager - Gulf Intel® Corporation The Heart of a Flexible, Efficient Data Center More Devices More Data More Options More Users More Connections Compelling User Experiences IT Needs the Best Combination of Performance, Built-in Capabilities, and Cost-effectiveness Introducing the Intel® Xeon® Processor E5 Family 80% Performance Gain1 Breakthrough I/O Innovation Trusted Security Best Data Center Perf per Watt2 The Heart of a Flexible, Efficient Data Center Built to Scale Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. 1: Performance comparison using best submitted/published 2-socket server results on the SPECfp*_rate_base2006 benchmark as of 6 March 2012. Configuration details in backup 2: Performance comparison using SPEC_Power results published as of March 6th, 2012. See back up for configuration details. For more information go to intel.com/performance Intel® Xeon® Processor Family for Business Scalable Enterprise Mainstream Enterprise Scalable (up to 256-way) Top-of-the-line performance, Versatile (up to 2-way) scalability, and reliability Best combination of Small performance, power efficiency, Business and cost Mission Critical Performance and reliability for the most Enterprise Server business critical workloads with outstanding Economical (1-way) and more Versatility for infrastructure apps (up to 4S) economics dependable vs.