Multicore Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Intel® Xeon® Processor E3-1200 V2 Product Family and LGA 1155 Socket
Intel® Xeon® Processor E3-1200 v2 Product Family and LGA 1155 Socket Thermal/Mechanical Specifications and Design Guidelines May 2012 Document Number: 324973-001 NFORMATIONLegal Lines and Disclaimers IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear facility applications. Intel may make changes to specifications and product descriptions at any time, without notice. This document contains information on products in the design phase of development. The information here is subject to change without notice. Do not finalize a design with this information. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Intel® Xeon® processor E3-1200 v2 product family and Intel® C200 Series Chipset family may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. -

Reviving the Development of Openchrome
Reviving the Development of OpenChrome Kevin Brace OpenChrome Project Maintainer / Developer XDC2017 September 21st, 2017 Outline ● About Me ● My Personal Story Behind OpenChrome ● Background on VIA Chrome Hardware ● The History of OpenChrome Project ● Past Releases ● Observations about Standby Resume ● Developmental Philosophy ● Developmental Challenges ● Strategies for Further Development ● Future Plans 09/21/2017 XDC2017 2 About Me ● EE (Electrical Engineering) background (B.S.E.E.) who specialized in digital design / computer architecture in college (pretty much the only undergraduate student “still” doing this stuff where I attended college) ● Graduated recently ● First time conference presenter ● Very experienced with Xilinx FPGA (Spartan-II through 7 Series FPGA) ● Fluent in Verilog / VHDL design and verification ● Interest / design experience with external communication interfaces (PCI / PCIe) and external memory interfaces (SDRAM / DDR3 SDRAM) ● Developed a simple DMA engine for PCI I/F validation w/Windows WDM (Windows Driver Model) kernel device driver ● Almost all the knowledge I have is self taught (university engineering classes were not very useful) 09/21/2017 XDC2017 3 Motivations Behind My Work ● General difficulty in obtaining meaningful employment in the digital hardware design field (too many students in the field, difficulty obtaining internship, etc.) ● Collects and repairs abandoned computer hardware (It’s like rescuing puppies!) ● Owns 100+ desktop computers and 20+ laptop computers (mostly abandoned old stuff I -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

"PCOM-B216VG-ECC.Pdf" (581 Kib)
Intel® Arrandale processor based Type II COM Express module support ECC DDR3 SDRAM PCOM-B216VG-ECC with Gigabit Ethernet 204pin ECC DDR3 SODIMM socket ® Intel QM57 ® Intel Arrandale processor FEATURES GENERAL CPU & Package: Intel® 45nm Arrandale Core i7/i5/i3 or Celeron P4505 ® Processor The Intel Arrandale and QM57 platform processor up to 2.66 GHz with 4MB Cache in FC-BGA package with turbo boost technology to maximize DMI x4 Link: 4.8GT/s (Full-Duplex) CPU & Graphic performance Chipset/Core Logic Intel® QM57 ® Intel Arrandale platform support variously System Memory Up to 8GB ECC DDR3 800/1066 SDRAM on two SODIMM sockets powerful processor from ultra low power AMI BIOS to mainstream performance type BIOS Storage Devices SATA: Support four SATA 300 and one IDE Supports Intel® intelligent power sharing Expansion Interface VGA and LVDS technology to reduce TDP (Thermal Six PCI Express x1 Design Power) LPC & SPI Interface High definition audio interface ® ® Enhance Intel vPro efficiency by Intel PCI 82577LM GbE PHY and AMT6.0 Hardware Monitoring CPU Voltage and Temperature technology Power Requirement TBA Support two ECC DDR3 800/1066 SDRAM on Dimension Dimension: 125(L) x 95(W) mm two SODIMM sockets, up to 8GB memory size Environment Operation Temperature: 0~60 °C Storage Temperature: -20~80 °C Operation Humidity: 5~90% I/O ORDERING GUIDE MIO N/A IrDA N/A PCOM-B216VG-ECC ® Standard Ethernet One Intel 82577LM Gigabit Ethernet PHY Intel® Arrandale processor based Type II COM Express module with ECC DDR3 SDRAM and Audio N/A Gigabit Ethernet USB Eight USB ports Keyboard & Mouse N/A CPU Intel® Core i7-610E SV (4M Cache, 2.53 GHz) Support List Intel® Core i7-620LE LV (4M Cache, 2.00 GHz) Intel® Core i7-620UE ULV (4M Cache, 1.06 GHz) Intel® Core i5-520E SV (3M Cache, 2.40 GHz) Intel® Celeron P4505 SV (2M Cache, 1.86 GHz) DISPLAY Graphic Controller Intel® Arrandale integrated Graphics Media Accelerator (Gen 5.75 with 12 execution units) * Specifications are subject to change without notice. -

QATS001 Agenda
Overview of Intel® QuickAssist Technology Dr. Nash Palaniswamy Intel Corporation and Guest Speaker Richard Kaufmann HP QATS001 Agenda • Intel® QuickAssist Technology Strategy • Overview of Solutions – Intel® Embedded Processor for 2008 (Tolapai), FSB-FPGA, AAL, etc. • A viewpoint from HP* on Accelerators • Summary 2 Intel® QuickAssist Technology – Comprehensive Approach to Acceleration • Multiple accelerator and attach options with software and ecosystem support • Performance and scalability based on customer needs and priorities Comprehensive Initiative to optimize the use and deployment of accelerators on Intel® architecture platforms. 3 Design Alternatives as Diverse as Application Requirements Accelerator Accelerator Software Design Attach Models Customized Solutions Power Software Maximum Efficiency Scalability Performance 4 Intel® Embedded Processor for 2008 (Tolapai) Single Die integrates - IA 32 based Core @ 600, 1066 and 1200MHz - DDR2 memory controller (MCH) - PCI Express* Technology - Standard IA PC peripherals (ICH) - 3x Gigabit Ethernet MACs - 3x TDM high-speed serial interfaces for 12 T1/E1 or SLIC/CODEC connections - Intel® QuickAssist Integrated Accelerator Vital Statistics - 148 million transistors - 1,088-ball FCBGA w/1.092 mm pitch - 37.5 mm x 37.5 mm package Intel's first integrated x86 processor, chipset and memory controller since 1994's 80386EX 5 Intel® QuickAssist® FPGA Acceleration Platform Source : Pat Gelsinger Keynote Fall IDF 2006 1. Open Ubiquitous Standards Based Approach PCI Express* Gen1, PCI Express* Gen2, Gen 3 in the future 2. Enable third party FSB-FPGA Modules – targeted for Financial Services Industry, Oil and Gas, Life Sciences, Digital Health, etc. FSB-FPGA Modules Targeted 1H08 3. Intel® QuickAssist Technology Accelerator Geneseo – PCI Express* Abstraction Layer (AAL) that seamlessly allows Source : Intel Internal the SW to access acceleration across various technologies. -

Improving Resource Utilization in Heterogeneous CPU-GPU Systems
Improving Resource Utilization in Heterogeneous CPU-GPU Systems A Dissertation Presented to the Faculty of the School of Engineering and Applied Science University of Virginia In Partial Fulfillment of the requirements for the Degree Doctor of Philosophy (Computer Engineering) by Michael Boyer May 2013 c 2013 Michael Boyer Abstract Graphics processing units (GPUs) have attracted enormous interest over the past decade due to substantial increases in both performance and programmability. Programmers can potentially leverage GPUs for substantial performance gains, but at the cost of significant software engineering effort. In practice, most GPU applications do not effectively utilize all of the available resources in a system: they either fail to use use a resource at all or use a resource to less than its full potential. This underutilization can hurt both performance and energy efficiency. In this dissertation, we address the underutilization of resources in heterogeneous CPU-GPU systems in three different contexts. First, we address the underutilization of a single GPU by reducing CPU-GPU interaction to improve performance. We use as a case study a computationally-intensive video-tracking application from systems biology. Because of the high cost of CPU-GPU coordination, our initial, straightforward attempts to accelerate this application failed to effectively utilize the GPU. By leveraging some non-obvious optimization strategies, we significantly decreased the amount of CPU-GPU interaction and improved the performance of the GPU implementation by 26x relative to the best CPU implementation. Based on the lessons we learned, we present general guidelines for optimizing GPU applications as well as recommendations for system-level changes that would simplify the development of high-performance GPU applications. -

Intel® G31 Express Chipset Product Brief
Product Brief Intel® G31 Express Chipset Intel® G31 Express Chipset Flexibility and scalability for essential computing The Intel® G31 Express Chipset supports Intel’s upcoming 45nm processors and enables Windows Vista* premium experience for value conscious consumers. The Intel G31 Express Chipset Desktop PC platforms, combined with either the Intel® Core™2 Duo or the Intel® Core™2 Quad processor, deliver new technologies and innovating capabilities for all consumers. With a 1333MHz system bus, DDR2 memory technology and support for Windows Vista Premium, the Intel G31 Express chipset enables scalability and performance for essential computing. Support for 45nm processor technology and Intel® Fast Memory Access (Intel® FMA) provide increased system performance for today’s computing needs. The Intel G31 Express Chipset enables a Intel® I/O Controller Hub (Intel® ICH7/R) balanced platform for everyday computing needs. The Intel G31 Express Chipset elevates storage performance with Serial Intel® Viiv™ processor technology ATA (SATA) and enhancements to Intel® Matrix Storage Technology2. Intel® Viiv™ processor technology1 is a set of PC technologies designed This chipset has four integrated SATA ports for transfer rates up to 3 for the enjoyment of digital entertainment in the home. The Intel G31 Gb/s (300 MB/s) to SATA hard drives or optical devices. Support for RAID Express Chipset supports Intel Viiv processor technology with either the 0, 1, 5 and 10 allows for different RAID capabilities that address specific Intel® ICH7R or ICH7DH SKUs. needs and usages. For example, critical data can be stored on one array designed for high reliability, while performance-intensive applications like Faster System Performance games can reside on a separate array designed for maximum The Intel® G31 Express Chipset Graphics Memory Controller Hub (GMCH) performance. -

Intel® Core™ I7 Processor Family for the LGA-2011 Socket
Intel® Core™ i7 Processor Family for the LGA-2011 Socket Datasheet, Volume 1 Supporting Desktop Intel® Core™ i7-3960X and i7-3970X Extreme Edition Processor for the LGA-2011 Socket Supporting Desktop Intel® Core™ i7-39xxK and i7-38xx Processor Series for the LGA-2011 Socket This is volume 1 of 2. February 2014 Reference Number: 326196-003 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear facility applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The information here is subject to change without notice. Do not finalize a design with this information. The products described in this document may contain design defects or errors known as errata which may cause the product to deviate from published specifications. -
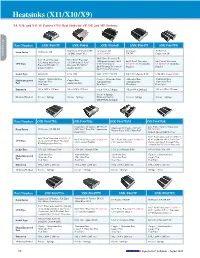
Heatsinks (X11/X10/X9)
Heatsinks (X11/X10/X9) X9, X10, and X11 1U Passive CPU Heat Sinks for UP, DP, and MP Systems Accessories Part Number SNK-P0037P SNK-P0041 SNK-P0046P SNK-P0047P SNK-P0047PD Proprietary 1U Passive, DP 1U Passive, UP 1U Passive, 1U Passive, Form Factor 1U Passive, DP (X9DBL Front CPU) (X11/X10/X9) UP, DP Proprietary, DP Intel® Xeon® Processor E3- Intel® Xeon® Processor Intel® Xeon® Processor 1200 product family; Intel® Intel® Xeon® Processor Intel® Xeon® Processor E5-2400 & Intel® Xeon® E5-2400 & Intel® Xeon® CPU Type Core™ i3 processor; E5-2600 v4/v3/v2 product E5-2600 v4/v3/v2 product Processor E5-2400 v2 Processor E5-2400 v2 Intel® Pentium® Processor & families families product families product families Intel® Celeron® Processor Socket Type LGA 1356 LGA 1356 LGA 1155/1151/1150 LGA 2011(Square ILM) LGA 2011 (Square ILM) Copper + Aluminum Base Copper + Aluminum Base Aluminum Base Aluminium Base Major Integrated Copper Base Aluminum Fins Aluminum Fins Aluminum Fins Aluminium Fins Part Aluminum Fins Heat Pipes Heat Pipes Heat Pipes Heat Pipes Dimension 90L x 90W x 27H mm 90L x 90W x 27H mm 95L x 95W x 27H mm 90L x 90W x 26H mm 90L x 110W x 27H mm Screws + Springs Mounting Method Screws + Springs Screws + Springs Mounting Bracket Screws + Springs Screws + Springs (BKT-0028L Included) Part Number SNK-P0047PS SNK-P0047PSC SNK-P0047PSM SNK-P0047PSR Proprietary 1U Passive, DP (1U 3/4 Low Profile Passive, Proprietary, Proprietary 1U Passive, DP (2U Form Factor 1U Passive, UP, DP, MP GPU/Intel® Xeon Phi™ coprocessor UP (X10/X9) Twin2+ Front CPU), -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -

Memorandum in Opposition to Hewlett-Packard Company's Motion to Quash Intel's Subpoena Duces Tecum
ORIGINAL UNITED STATES OF AMERICA BEFORE THE FEDERAL TRADE COMMISSION ) In the Matter of ) ) DOCKET NO. 9341 INTEL. CORPORATION, ) a corporation ) PUBLIC ) .' ) MEMORANDUM IN OPPOSITION TO HEWLETT -PACKARD COMPANY'S MOTION TO QUASH INTEL'S SUBPOENA DUCES TECUM Intel Corporation ("Intel") submits this memorandum in opposition to Hewlett-Packard Company's ("HP") motion to quash Intel's subpoena duces tecum issued on March 11,2010 ("Subpoena"). HP's motion should be denied, and it should be ordered to comply with Intel's Subpoena, as narrowed by Intel's April 19,2010 letter. Intel's Subpoena seeks documents necessary to defend against Complaint Counsel's broad allegations and claimed relief. The Complaint alleges that Intel engaged in unfair business practices that maintained its monopoly over central processing units ("CPUs") and threatened to give it a monopoly over graphics processing units ("GPUs"). See CompI. iiii 2-28. Complaint Counsel's Interrogatory Answers state that it views HP, the world's largest manufacturer of personal computers, as a centerpiece of its case. See, e.g., Complaint Counsel's Resp. and Obj. to Respondent's First Set ofInterrogatories Nos. 7-8 (attached as Exhibit A). Complaint Counsel intends to call eight HP witnesses at trial on topics crossing virtually all of HP' s business lines, including its purchases ofCPUs for its commercial desktop, commercial notebook, and server businesses. See Complaint Counsel's May 5, 2010 Revised Preliminary Witness List (attached as Exhibit B). Complaint Counsel may also call HP witnesses on other topics, including its PUBLIC FTC Docket No. 9341 Memorandum in Opposition to Hewlett-Packard Company's Motion to Quash Intel's Subpoena Duces Tecum USIDOCS 7544743\'1 assessment and purchases of GPUs and chipsets and evaluation of compilers, benchmarks, interface standards, and standard-setting bodies. -

System Design for Telecommunication Gateways
P1: OTE/OTE/SPH P2: OTE FM BLBK307-Bachmutsky August 30, 2010 15:13 Printer Name: Yet to Come SYSTEM DESIGN FOR TELECOMMUNICATION GATEWAYS Alexander Bachmutsky Nokia Siemens Networks, USA A John Wiley and Sons, Ltd., Publication P1: OTE/OTE/SPH P2: OTE FM BLBK307-Bachmutsky August 30, 2010 15:13 Printer Name: Yet to Come P1: OTE/OTE/SPH P2: OTE FM BLBK307-Bachmutsky August 30, 2010 15:13 Printer Name: Yet to Come SYSTEM DESIGN FOR TELECOMMUNICATION GATEWAYS P1: OTE/OTE/SPH P2: OTE FM BLBK307-Bachmutsky August 30, 2010 15:13 Printer Name: Yet to Come P1: OTE/OTE/SPH P2: OTE FM BLBK307-Bachmutsky August 30, 2010 15:13 Printer Name: Yet to Come SYSTEM DESIGN FOR TELECOMMUNICATION GATEWAYS Alexander Bachmutsky Nokia Siemens Networks, USA A John Wiley and Sons, Ltd., Publication P1: OTE/OTE/SPH P2: OTE FM BLBK307-Bachmutsky August 30, 2010 15:13 Printer Name: Yet to Come This edition first published 2011 C 2011 John Wiley & Sons, Ltd Registered office John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, United Kingdom For details of our global editorial offices, for customer services and for information about how to apply for permission to reuse the copyright material in this book please see our website at www.wiley.com. The right of the author to be identified as the author of this work has been asserted in accordance with the Copyright, Designs and Patents Act 1988. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, except as permitted by the UK Copyright, Designs and Patents Act 1988, without the prior permission of the publisher.