Intel's Core 2 Family
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Intel® Architecture Instruction Set Extensions and Future Features Programming Reference
Intel® Architecture Instruction Set Extensions and Future Features Programming Reference 319433-037 MAY 2019 Intel technologies features and benefits depend on system configuration and may require enabled hardware, software, or service activation. Learn more at intel.com, or from the OEM or retailer. No computer system can be absolutely secure. Intel does not assume any liability for lost or stolen data or systems or any damages resulting from such losses. You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifica- tions. Current characterized errata are available on request. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Intel does not guarantee the availability of these interfaces in any future product. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be obtained by calling 1- 800-548-4725, or by visiting http://www.intel.com/design/literature.htm. Intel, the Intel logo, Intel Deep Learning Boost, Intel DL Boost, Intel Atom, Intel Core, Intel SpeedStep, MMX, Pentium, VTune, and Xeon are trademarks of Intel Corporation in the U.S. -

1 in the United States District Court
Case 6:20-cv-00779 Document 1 Filed 08/25/20 Page 1 of 33 IN THE UNITED STATES DISTRICT COURT WESTERN DISTRICT OF TEXAS AUSTIN DIVISION AURIGA INNOVATIONS, INC. C.A. No. 6:20-cv-779 Plaintiff, v. JURY TRIAL DEMANDED INTEL CORPORATION, HP INC., and HEWLETT PACKARD ENTERPRISE COMPANY, Defendants COMPLAINT Plaintiff Auriga Innovations, Inc. (“Auriga” or “Plaintiff”) files this complaint for patent infringeMent against Defendants Intel Corporation (“Intel”), HP Inc. (“HPI”), and Hewlett Packard Enterprise Company (“HPE”) (collectively, “Defendants”) under 35 U.S.C. § 217 et seq. as a result of Defendants’ unauthorized use of Auriga’s patents and alleges as follows: THE PARTIES 1. Auriga is a corporation organized and existing under the laws of the state of Delaware with its principal place of business at 1891 Robertson Road, Suite 100, Ottawa, ON K2H 5B7 Canada. 2. On information and belief, Intel is a Delaware corporation with a place of business at 2200 Mission College Boulevard, Santa Clara, California 95054. 3. On information and belief, since April 1989, Intel has been registered to do business in the State of Texas under Texas Taxpayer Number 19416727436 and has places of business at 1 Case 6:20-cv-00779 Document 1 Filed 08/25/20 Page 2 of 33 1300 S Mopac Expressway, Austin, Texas 78746; 6500 River Place Blvd, Bldg 7, Austin, Texas 78730; and 5113 Southwest Parkway, Austin, Texas 78735 (collectively, “Intel Austin Offices”). https://www.intel.com/content/www/us/en/location/usa.htMl. 4. On information and belief, HPI is a Delaware corporation with a principal place of business at 1501 Page Mill Road, Palo Alto, CA 94304. -

Horizontal PDF Slides
1 2 Speed, speed, speed $1000 TCR hashing competition D. J. Bernstein Crowley: “I have a problem where I need to make some University of Illinois at Chicago; cryptography faster, and I’m Ruhr University Bochum setting up a $1000 competition funded from my own pocket for Reporting some recent work towards the solution.” symmetric-speed discussions, Not fast enough: Signing H(M), especially from RWC 2020. where M is a long message. Not included in this talk: “[On a] 900MHz Cortex-A7 NISTLWC. • [SHA-256] takes 28.86 cpb ::: Short inputs. • BLAKE2b is nearly twice as FHE/MPC ciphers. • fast ::: However, this is still a lot slower than I’m happy with.” 1 2 3 Speed, speed, speed $1000 TCR hashing competition Instead choose random R and sign (R; H(R; M)). D. J. Bernstein Crowley: “I have a problem where I need to make some Note that H needs only “TCR”, University of Illinois at Chicago; cryptography faster, and I’m not full collision resistance. Ruhr University Bochum setting up a $1000 competition Does this allow faster H design? funded from my own pocket for TCR breaks how many rounds? Reporting some recent work towards the solution.” symmetric-speed discussions, Not fast enough: Signing H(M), especially from RWC 2020. where M is a long message. Not included in this talk: “[On a] 900MHz Cortex-A7 NISTLWC. • [SHA-256] takes 28.86 cpb ::: Short inputs. • BLAKE2b is nearly twice as FHE/MPC ciphers. • fast ::: However, this is still a lot slower than I’m happy with.” 1 2 3 Speed, speed, speed $1000 TCR hashing competition Instead choose random R and sign (R; H(R; M)). -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

"PCOM-B216VG-ECC.Pdf" (581 Kib)
Intel® Arrandale processor based Type II COM Express module support ECC DDR3 SDRAM PCOM-B216VG-ECC with Gigabit Ethernet 204pin ECC DDR3 SODIMM socket ® Intel QM57 ® Intel Arrandale processor FEATURES GENERAL CPU & Package: Intel® 45nm Arrandale Core i7/i5/i3 or Celeron P4505 ® Processor The Intel Arrandale and QM57 platform processor up to 2.66 GHz with 4MB Cache in FC-BGA package with turbo boost technology to maximize DMI x4 Link: 4.8GT/s (Full-Duplex) CPU & Graphic performance Chipset/Core Logic Intel® QM57 ® Intel Arrandale platform support variously System Memory Up to 8GB ECC DDR3 800/1066 SDRAM on two SODIMM sockets powerful processor from ultra low power AMI BIOS to mainstream performance type BIOS Storage Devices SATA: Support four SATA 300 and one IDE Supports Intel® intelligent power sharing Expansion Interface VGA and LVDS technology to reduce TDP (Thermal Six PCI Express x1 Design Power) LPC & SPI Interface High definition audio interface ® ® Enhance Intel vPro efficiency by Intel PCI 82577LM GbE PHY and AMT6.0 Hardware Monitoring CPU Voltage and Temperature technology Power Requirement TBA Support two ECC DDR3 800/1066 SDRAM on Dimension Dimension: 125(L) x 95(W) mm two SODIMM sockets, up to 8GB memory size Environment Operation Temperature: 0~60 °C Storage Temperature: -20~80 °C Operation Humidity: 5~90% I/O ORDERING GUIDE MIO N/A IrDA N/A PCOM-B216VG-ECC ® Standard Ethernet One Intel 82577LM Gigabit Ethernet PHY Intel® Arrandale processor based Type II COM Express module with ECC DDR3 SDRAM and Audio N/A Gigabit Ethernet USB Eight USB ports Keyboard & Mouse N/A CPU Intel® Core i7-610E SV (4M Cache, 2.53 GHz) Support List Intel® Core i7-620LE LV (4M Cache, 2.00 GHz) Intel® Core i7-620UE ULV (4M Cache, 1.06 GHz) Intel® Core i5-520E SV (3M Cache, 2.40 GHz) Intel® Celeron P4505 SV (2M Cache, 1.86 GHz) DISPLAY Graphic Controller Intel® Arrandale integrated Graphics Media Accelerator (Gen 5.75 with 12 execution units) * Specifications are subject to change without notice. -

Intel® Server Board S3420GP
Intel® Server Board S3420GP Technical Product Specification Intel order number E65697-010 Revision 2.4 January, 2011 Enterprise Platforms and Services Division - Marketing Revision History Intel® Server Board S3420GP TPS Revision History Date Revision Modifications Number Feb. 2009 0.3 Initial release. May 2009 0.5 Update block diagram. July. 2009 0.9 Updated POST error code and diagram. Aug. 2009 1.0 Updated MTBF. Nov. 2009 1.1 Additional details for memory configuration. Dec. 2009 1.2 Added Intel® Server Board S3420GPV details. Dec. 2009 2.0 Updated processor name. Jan. 2010 2.1 Corrected the typo. Apr. 2010 2.2 Corrected the typo, updated processor name and remove CCC certification marking information. July. 2010 2.3 Corrected the typo. Jan.2011 2.4 Corrected the typo. Added RDIMM support on S3420GPV. Updated Table 45. Add USB device readiness beep code information. ii Revision 2.4 Intel order number E65697-010 Intel® Server Board S3420GP TPS Disclaimers Disclaimers Information in this document is provided in connection with Intel® products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel's Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. -

MBP4ASG41M-VS3.Pdf
ASRock > G41M-VS3 Página 1 de 2 Home | Global / English [Change] About ASRock Products News Support Forum Download Awards Dealer Zone Where to Buy Products G41M-VS3 Motherboard Series »G41M-VS3 Translate »Overview & Specifications ■ Supports FSB1333/1066/800/533 MHz CPUs »Download ■ Supports Dual Channel DDR3 1333(OC) ■ Intel® Graphics Media Accelerator X4500, Pixel Shader 4.0, DirectX 10, Max. shared »Manual memory 1759MB »FAQ ■ EuP Ready »CPU Support List ■ Supports ASRock XFast RAM, XFast LAN, XFast USB Technologies ■ Supports Instant Boot, Instant Flash, OC DNA, ASRock OC Tuner (Up to 158% CPU »Memory QVL frequency increase) »Beta Zone ■ Supports Intelligent Energy Saver (Up to 20% CPU Power Saving) ■ Free Bundle : CyberLink DVD Suite - OEM and Trial; Creative Sound Blaster X-Fi MB - Trial This model may not be sold worldwide. Please contact your local dealer for the availability of this model in your region. Product Specifications General - LGA 775 for Intel® Core™ 2 Extreme / Core™ 2 Quad / Core™ 2 Duo / Pentium® Dual Core / Celeron® Dual Core / Celeron, supporting Penryn Quad Core Yorkfield and Dual Core Wolfdale processors - Supports FSB1333/1066/800/533 MHz CPU - Supports Hyper-Threading Technology - Supports Untied Overclocking Technology - Supports EM64T CPU - Northbridge: Intel® G41 Chipset - Southbridge: Intel® ICH7 - Dual Channel DDR3 memory technology - 2 x DDR3 DIMM slots - Supports DDR3 1333(OC)/1066/800 non-ECC, un-buffered memory Memory - Max. capacity of system memory: 8GB* *Due to the operating system limitation, the actual memory size may be less than 4GB for the reservation for system usage under Windows® 32-bit OS. For Windows® 64-bit OS with 64-bit CPU, there is no such limitation. -

Intel ® Xeon ® Processor 3500 Series
Intel® Xeon® Processor 3500 Series Datasheet, Volume 1 July 2009 Document Number: 321332-002 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. INTEL PRODUCTS ARE NOT INTENDED FOR USE IN MEDICAL, LIFE SAVING, OR LIFE SUSTAINING APPLICATIONS. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Intel® Xeon® Processor 3500 Series may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Intel processor numbers are not a measure of performance. Processor numbers differentiate features within each processor family, not across different processor families. See http://www.intel.com/products/processor_number for details. Over time processor numbers will increment based on changes in clock, speed, cache, FSB, or other features, and increments are not intended to represent proportional or quantitative increases in any particular feature. -

Lambert-Mastersreport-2016
Copyright by Timothy Michael Lambert 2016 The Report Committee for Timothy Michael Lambert Certifies that this is the approved version of the following report: Enterprise Platform Systems Management Security Threats and Mitigation Techniques APPROVED BY SUPERVISING COMMITTEE: Supervisor: Suzanne Barber Elie Jreij Enterprise Platform Systems Management Security Threats and Mitigation Techniques by Timothy Michael Lambert, B.S.E.E., M.B.A. Report Presented to the Faculty of the Graduate School of The University of Texas at Austin in Partial Fulfillment of the Requirements for the Degree of Master of Science in Engineering The University of Texas at Austin December 2016 Dedication For Jake Lambert, whose life and passing spurned the author’s commitment to enter and dedication to complete this degree program. Acknowledgements I would like to express special thanks to my family and employer, Dell Technologies, Inc., for allowing me the time to pursue my educational and professional interests via this superb graduate program. Additionally, I would like to thank my supervisor, Dr. Suzanne Barber, and reader, Elie Jreij, who is a professional mentor in this research area. v Abstract Enterprise Platform Systems Management Security Threats and Mitigation Techniques Timothy Michael Lambert, MSE The University of Texas at Austin, 2016 Supervisor: Suzanne Barber Developers and technologists of enterprise systems such as servers, storage and networking products must constantly anticipate new cybersecurity threats and evolving security requirements. These requirements are typically sourced from marketing, customer expectations, manufacturing and evolving government standards. Much ongoing major research focus has been on securing the main enterprise system purpose functionality, operating system, network and storage. -

Evolution of Microprocessor Performance
EvolutionEvolution ofof MicroprocessorMicroprocessor PerformancePerformance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static & dynamic branch predication. Even with these improvements, the restriction of issuing a single instruction per cycle still limits the ideal CPI = 1 Multiple Issue (CPI <1) Multi-cycle Pipelined T = I x CPI x C (single issue) Superscalar/VLIW/SMT Original (2002) Intel Predictions 1 GHz ? 15 GHz to ???? GHz IPC CPI > 10 1.1-10 0.5 - 1.1 .35 - .5 (?) Source: John P. Chen, Intel Labs We next examine the two approaches to achieve a CPI < 1 by issuing multiple instructions per cycle: 4th Edition: Chapter 2.6-2.8 (3rd Edition: Chapter 3.6, 3.7, 4.3 • Superscalar CPUs • Very Long Instruction Word (VLIW) CPUs. Single-issue Processor = Scalar Processor EECC551 - Shaaban Instructions Per Cycle (IPC) = 1/CPI EECC551 - Shaaban #1 lec # 6 Fall 2007 10-2-2007 ParallelismParallelism inin MicroprocessorMicroprocessor VLSIVLSI GenerationsGenerations Bit-level parallelism Instruction-level Thread-level (?) (TLP) 100,000,000 (ILP) Multiple micro-operations Superscalar /VLIW per cycle Simultaneous Single-issue CPI <1 u Multithreading SMT: (multi-cycle non-pipelined) Pipelined e.g. Intel’s Hyper-threading 10,000,000 CPI =1 u uuu u u Chip-Multiprocessors (CMPs) u Not Pipelined R10000 e.g IBM Power 4, 5 CPI >> 1 uuuuuuu u AMD Athlon64 X2 u uuuuu Intel Pentium D u uuuuuuuu u u 1,000,000 u uu uPentium u u uu i80386 u i80286 -
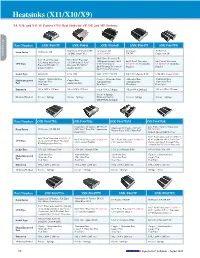
Heatsinks (X11/X10/X9)
Heatsinks (X11/X10/X9) X9, X10, and X11 1U Passive CPU Heat Sinks for UP, DP, and MP Systems Accessories Part Number SNK-P0037P SNK-P0041 SNK-P0046P SNK-P0047P SNK-P0047PD Proprietary 1U Passive, DP 1U Passive, UP 1U Passive, 1U Passive, Form Factor 1U Passive, DP (X9DBL Front CPU) (X11/X10/X9) UP, DP Proprietary, DP Intel® Xeon® Processor E3- Intel® Xeon® Processor Intel® Xeon® Processor 1200 product family; Intel® Intel® Xeon® Processor Intel® Xeon® Processor E5-2400 & Intel® Xeon® E5-2400 & Intel® Xeon® CPU Type Core™ i3 processor; E5-2600 v4/v3/v2 product E5-2600 v4/v3/v2 product Processor E5-2400 v2 Processor E5-2400 v2 Intel® Pentium® Processor & families families product families product families Intel® Celeron® Processor Socket Type LGA 1356 LGA 1356 LGA 1155/1151/1150 LGA 2011(Square ILM) LGA 2011 (Square ILM) Copper + Aluminum Base Copper + Aluminum Base Aluminum Base Aluminium Base Major Integrated Copper Base Aluminum Fins Aluminum Fins Aluminum Fins Aluminium Fins Part Aluminum Fins Heat Pipes Heat Pipes Heat Pipes Heat Pipes Dimension 90L x 90W x 27H mm 90L x 90W x 27H mm 95L x 95W x 27H mm 90L x 90W x 26H mm 90L x 110W x 27H mm Screws + Springs Mounting Method Screws + Springs Screws + Springs Mounting Bracket Screws + Springs Screws + Springs (BKT-0028L Included) Part Number SNK-P0047PS SNK-P0047PSC SNK-P0047PSM SNK-P0047PSR Proprietary 1U Passive, DP (1U 3/4 Low Profile Passive, Proprietary, Proprietary 1U Passive, DP (2U Form Factor 1U Passive, UP, DP, MP GPU/Intel® Xeon Phi™ coprocessor UP (X10/X9) Twin2+ Front CPU), -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References .............................................