Efficient Algorithms for Large-Scale Image Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Scalability of Terrain Visualization in Large Virtual Environments
WORDT ' Facultyof Mathematics and Natural Department of NIET UITGELEEND Mathematics and Computing Science Scalability of Terrain Visualization in Large Virtual Environments Esger G.N. Abbink Advisors: dr. J.B.TM. Roerdink Department of Mathematics and Computing Science University of Groningen drs. M.J.B. van Delden drs. M. Wierda Virtual Environments, Systems, and Consultancy Zeegse .(,-,-, June,2000 Rkunlv,,,IOIOi*S DDothk W1s*ud. 'iMP* IRS&SIICSIWI'U :.'von S r-;tus800 9' Avr')1rs.r Scalability of terrain visualization in large Virtual Environments Esger G.N. Abbink Department of Mathematics and Computing Science Graduate specialization High Performance Computing and Imaging Studentnumber 0831425 Gerkesklooster/ Zeegse, April 2000 Rapport vesc WR-2000/3 •1 Table of Contents Scalability of terrain visualization in large Virtual Environments..1 1. Introduction 4 2. Virtual Environments 6 2.1 Startingpoints 6 2.2 Means-end analysis 6 2.3 Man-in-the-loop 6 2.4 Hardware 8 2.5 Real-world simulators 9 2.5.1 Flight Simulators 9 2.5.2 Driving Simulators 9 2.5.3 Rail vehicle simulators 10 2.5.4 Ship Simulator 11 2.5.5 yE Walkthrough 11 2.5.6 Entertainment Simulators 12 2.5.7 Telepresence 12 2.5.8 Virtual GIS 13 2.6 Summary & practical continuation 13 3. Scalable terrain visualization 15 3.1 Introduction 15 3.2 The sample implementation 15 3.2.1 Introduction 15 3.2.2 Getting it to work 15 3.2.3 Porting the sample implementation to 4Space 16 3.3 Design 16 3.3.1 Goal 16 3.3.2 Requirements 16 3.3.3 Terrain representation 16 3.3.4 Basic setup 18 3.3.5 Tessellation algorithm 19 3.3.6 Implementation approach 23 3.4 Implementation 24 3.4.1 Terrain data generation 24 3.4.2 Implementing Central Differencing 24 3.4.2 Interfacing 4Space 28 3.4.3 Memory management 29 3.4.4 Dynamic data storages 30 3.4.4.1 Queue 30 3.4.4.2 Dynamic List & Pool 31 3.4.4.3 Red-Black Tree 31 3.4.4.4 Dynamic Storage 32 3.4.4.5 Evaluating performance 33 2 4. -

DRAFT - DATED MATERIAL the CONTENTS of THIS REVIEWER’S GUIDE IS INTENDED SOLELY for REFERENCE WHEN REVIEWING Rev a VERSIONS of VOODOO5 5500 REFERENCE BOARDS
Voodoo5™ 5500 for the PC Reviewer’s Guide DRAFT - DATED MATERIAL THE CONTENTS OF THIS REVIEWER’S GUIDE IS INTENDED SOLELY FOR REFERENCE WHEN REVIEWING Rev A VERSIONS OF VOODOO5 5500 REFERENCE BOARDS. THIS INFORMATION WILL BE REGULARLY UPDATED, AND REVIEWERS SHOULD CONTACT THE PERSONS LISTED IN THIS GUIDE FOR UPDATES BEFORE EVALUATING ANY VOODOO5 5500BOARD. 3dfx Interactive, Inc. 4435 Fortran Dr. San Jose, Ca 95134 408-935-4400 Brian Burke 214-570-2113 [email protected] PT Barnum 214-570-2226 [email protected] Bubba Wolford 281-578-7782 [email protected] www.3dfx.com www.3dfxgamers.com Copyright 2000 3dfx Interactive, Inc. All Rights Reserved. All other trademarks are the property of their respective owners. Visit the 3dfx Virtual Press Room at http://www.3dfx.com/comp/pressweb/index.html. Voodoo5 5500 Reviewers Guide xxxx 2000 Table of Contents Benchmarking the Voodoo5 5500 Page 5 • Cures for common benchmarking and image quality mistakes • Tips for benchmarking • Overclocking Guide INTRODUCTION Page 11 • Optimized for DVD Acceleration • Scalable Performance • Trend-setting Image quality Features • Texture Compression • Glide 2.x and 3.x Compatibility: The Most Titles • World-class Window’s GUI/video Acceleration SECTION 1: Voodoo5 5500 Board Overview Page 12 • General Features • 3D Features set • 2D Features set • Voodoo5 Video Subsystem • SLI • Texture compression • Fill Rate vs T&L • T-Buffer introduction • Alternative APIs (Al Reyes on Mac, Linux, BeOS and more) • Pricing & Availability • Warranty • Technical Support • Photos, screenshots, -

Mobile 3D Devices They're Not Little
Mobile 3D Devices -- They’re not little PCs! Stephen Wilkinson – Graphics Software Technical Lead Texas Instruments CSSD/OMAP Who is this guy? ! Involved with simulation and games since 1995 ! Worked on SIMNET for the US Army ! PC gaming ! Titles include WarBirds 1 & 2, Fighter Squadron, AMA SuperBike, NHRA Drag Racing, NHRA Main Event ! 30+ Casino Games (yeah, yeah) ! Worked on core technology for several console games ! D&D Heroes, Mission Impossible: Operation SURMA, and T3: Redemption (NGC, PS2, Xbox) ! Former member of the Graphics and Computer Vision group at Nokia Research Center ! Now the CSSD graphics software technical lead at Texas Instruments working on OMAP Introduction ! Mobile 3D hardware is not a “Mini-me” of your desktop PC. ! To obtain similar features and relatively high levels of performance, mobile hardware has made some tradeoffs compared to the power of your desktop Introduction… ! If you are just learning mobile 3D or have learned about graphics and performance on a more “traditional” platform such as a PC or console, this presentation should help you: ! Recognize the most important areas in mobile power and performance for 3D and game development ! Take appropriate lessons learned from desktop development whenever possible… ! Avoid lessons from the desktop which can make your game slower or more power-hungry than it could be! Mobile performance preview ! Some you know, some you may not… Sorted by acronym the main problems are: ! CPU ! GPU ! Memory ! Your game The Mobile CPU ! No, it doesn’t have a Hemi. The Mobile GPU ! No, there’s not really a tiny 3dfx Voodoo™ card in that handset Mobile Memory ! It’s SLOOOOOOOW…. -

AMD Radeon E8860
Components for AMD’s Embedded Radeon™ E8860 GPU INTRODUCTION The E8860 Embedded Radeon GPU available from CoreAVI is comprised of temperature screened GPUs, safety certi- fiable OpenGL®-based drivers, and safety certifiable GPU tools which have been pre-integrated and validated together to significantly de-risk the challenges typically faced when integrating hardware and software components. The plat- form is an off-the-shelf foundation upon which safety certifiable applications can be built with confidence. Figure 1: CoreAVI Support for E8860 GPU EXTENDED TEMPERATURE RANGE CoreAVI provides extended temperature versions of the E8860 GPU to facilitate its use in rugged embedded applications. CoreAVI functionally tests the E8860 over -40C Tj to +105 Tj, increasing the manufacturing yield for hardware suppliers while reducing supply delays to end customers. coreavi.com [email protected] Revision - 13Nov2020 1 E8860 GPU LONG TERM SUPPLY AND SUPPORT CoreAVI has provided consistent and dedicated support for the supply and use of the AMD embedded GPUs within the rugged Mil/Aero/Avionics market segment for over a decade. With the E8860, CoreAVI will continue that focused support to ensure that the software, hardware and long-life support are provided to meet the needs of customers’ system life cy- cles. CoreAVI has extensive environmentally controlled storage facilities which are used to store the GPUs supplied to the Mil/ Aero/Avionics marketplace, ensuring that a ready supply is available for the duration of any program. CoreAVI also provides the post Last Time Buy storage of GPUs and is often able to provide additional quantities of com- ponents when COTS hardware partners receive increased volume for existing products / systems requiring additional inventory. -

John Carmack Archive - .Plan (1998)
John Carmack Archive - .plan (1998) http://www.team5150.com/~andrew/carmack March 18, 2007 Contents 1 January 5 1.1 Some of the things I have changed recently (Jan 01, 1998) . 5 1.2 Jan 02, 1998 ............................ 6 1.3 New stuff fixed (Jan 03, 1998) ................. 7 1.4 Version 3.10 patch is now out. (Jan 04, 1998) ......... 8 1.5 Jan 09, 1998 ............................ 9 1.6 I AM GOING OUT OF TOWN NEXT WEEK, DON’T SEND ME ANY MAIL! (Jan 11, 1998) ................. 10 2 February 12 2.1 Ok, I’m overdue for an update. (Feb 04, 1998) ........ 12 2.2 Just got back from the Q2 wrap party in vegas that Activi- sion threw for us. (Feb 09, 1998) ................ 14 2.3 Feb 12, 1998 ........................... 15 2.4 8 mb or 12 mb voodoo 2? (Feb 16, 1998) ........... 19 2.5 I just read the Wired article about all the Doom spawn. (Feb 17, 1998) .......................... 20 2.6 Feb 22, 1998 ........................... 21 1 John Carmack Archive 2 .plan 1998 3 March 22 3.1 American McGee has been let go from Id. (Mar 12, 1998) . 22 3.2 The Old Plan (Mar 13, 1998) .................. 22 3.3 Mar 20, 1998 ........................... 25 3.4 I just shut down the last of the NEXTSTEP systems running at id. (Mar 21, 1998) ....................... 26 3.5 Mar 26, 1998 ........................... 28 4 April 30 4.1 Drag strip day! (Apr 02, 1998) ................. 30 4.2 Things are progressing reasonably well on the Quake 3 en- gine. (Apr 08, 1998) ....................... 31 4.3 Apr 16, 1998 .......................... -
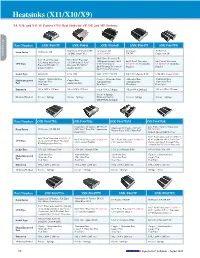
Heatsinks (X11/X10/X9)
Heatsinks (X11/X10/X9) X9, X10, and X11 1U Passive CPU Heat Sinks for UP, DP, and MP Systems Accessories Part Number SNK-P0037P SNK-P0041 SNK-P0046P SNK-P0047P SNK-P0047PD Proprietary 1U Passive, DP 1U Passive, UP 1U Passive, 1U Passive, Form Factor 1U Passive, DP (X9DBL Front CPU) (X11/X10/X9) UP, DP Proprietary, DP Intel® Xeon® Processor E3- Intel® Xeon® Processor Intel® Xeon® Processor 1200 product family; Intel® Intel® Xeon® Processor Intel® Xeon® Processor E5-2400 & Intel® Xeon® E5-2400 & Intel® Xeon® CPU Type Core™ i3 processor; E5-2600 v4/v3/v2 product E5-2600 v4/v3/v2 product Processor E5-2400 v2 Processor E5-2400 v2 Intel® Pentium® Processor & families families product families product families Intel® Celeron® Processor Socket Type LGA 1356 LGA 1356 LGA 1155/1151/1150 LGA 2011(Square ILM) LGA 2011 (Square ILM) Copper + Aluminum Base Copper + Aluminum Base Aluminum Base Aluminium Base Major Integrated Copper Base Aluminum Fins Aluminum Fins Aluminum Fins Aluminium Fins Part Aluminum Fins Heat Pipes Heat Pipes Heat Pipes Heat Pipes Dimension 90L x 90W x 27H mm 90L x 90W x 27H mm 95L x 95W x 27H mm 90L x 90W x 26H mm 90L x 110W x 27H mm Screws + Springs Mounting Method Screws + Springs Screws + Springs Mounting Bracket Screws + Springs Screws + Springs (BKT-0028L Included) Part Number SNK-P0047PS SNK-P0047PSC SNK-P0047PSM SNK-P0047PSR Proprietary 1U Passive, DP (1U 3/4 Low Profile Passive, Proprietary, Proprietary 1U Passive, DP (2U Form Factor 1U Passive, UP, DP, MP GPU/Intel® Xeon Phi™ coprocessor UP (X10/X9) Twin2+ Front CPU), -

Integrating Mali GPU with the Browser
Integrating Mali GPU with the Browser Wasim Abbas Staff Engineer, Mali Ecosystem 1 What’s Coming? § Introduction § Mali architecture § Optimizing for Mali § Common pitfalls § Questions 2 Introduction § Technical Lead of Middleware graphics team in Mali Ecosystem § Working with Skia, FireFox (Gecko) and WebKit teams (GPU acceleration for The Web) § Have worked with Mali content optimization and creation tools § Past expertise in the Game industry, engine development § Past expertise teaching Game engine architecture § Who are you? 3 Graphics in the Embedded World § Embedded / mobile graphics fundamentally different from PC § Not just a scaled down version of the desktop world § Completely different power and bandwidth budgets § No dedicated GPU memory or bus – all shared with CPU, video, DSP § Need to last days rather than hours on a single battery charge § Requires dedicated solutions § Must handle “PC use cases” with a mobile phone power budget § Maximize processing efficiency in an embedded memory subsystem 4 Optimizing for Mali § Understanding Mali architecture § Understanding your browser and underlying renderer § Understanding OpenGL ES API and what happens under the hood § Multi-level optimizations at system and application level § Optimizations at client level 5 Abstract Rendering Machine glDraw(1) glDraw(2) glDraw(3) eglSwapBuffers() Original article from Peter Harris at http://community.arm.com/groups/arm-mali-graphics/blog/2014/02/03/the-mali-gpu-an-abstract-machine-part-1 6 Abstract Rendering Machine Synchronous API, asynchronous -
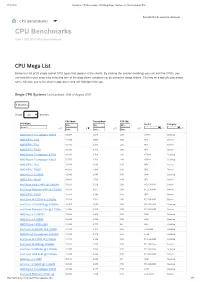
CPU Benchmarks - CPU Mega Page - Detailed List of Benchmarked Cpus
27.08.2020 PassMark - CPU Benchmarks - CPU Mega Page - Detailed List of Benchmarked CPUs CPU Benchmarks CPU Benchmarks Over 1,000,000 CPUs Benchmarked CPU Mega List Below is a list of all single socket CPU types that appear in the charts. By clicking the column headings you can sort the CPUs, you can also filter your search by selecting one of the drop down categories or by using the range sliders. Clicking on a specific processor name will take you to the chart it appears in and will highlight it for you. Single CPU Systems Last Updated: 26th of August 2020 Columns Show All entries CPU Mark Thread Mark TDP (W) CPU Name Min... - Min... - Min... - Socket Category Search... ▲▼ Max... ▲▼ Max... ▲▼ Max... ▲▼ ▲▼ ▲▼ AMD Ryzen Threadripper 3990X 80,087 2,518 280 sTRX4 Desktop AMD EPYC 7702 71,362 2,067 200 SP3 Server AMD EPYC 7742 67,185 2,376 225 SP3 Server AMD EPYC 7702P 64,395 2,316 200 SP3 Server AMD Ryzen Threadripper 3970X 64,015 2,704 280 sTRX4 Desktop AMD Ryzen Threadripper 3960X 55,707 2,702 280 sTRX4 Desktop AMD EPYC 7452 53,478 2,290 155 SP3 Server AMD EPYC 7502P 48,021 1,938 180 SP3 Server AMD Ryzen 9 3950X 39,246 2,743 105 AM4 Desktop AMD EPYC 7402P 39,118 1,742 180 SP3 Server Intel Xeon Gold 6248R @ 3.00GHz 38,521 2,270 205 FCLGA3647 Server Intel Xeon Platinum 8280 @ 2.70GHz 37,575 2,011 205 FCLGA3647 Server AMD EPYC 7302P 37,473 2,143 155 SP3 Server Intel Xeon W-3275M @ 2.50GHz 37,104 2,561 205 FCLGA3647 Server Intel Core i9-10980XE @ 3.00GHz 33,967 2,636 165 FCLGA2066 Desktop Intel Xeon Platinum 8168 @ 2.70GHz 33,398 2,167 205 -

Matrox in the New Millennium: Parhelia Reviewed Matrox in the New Millennium: Parhelia Reviewed by Brian Neal – July 2002
Ace’s Hardware Matrox in the New Millennium: Parhelia Reviewed Matrox in the New Millennium: Parhelia Reviewed By Brian Neal – July 2002 Introduction For some time following the introduction of the Matrox G400 and later the G450, we heard rumors about a "G800" project. About a year and a month ago, Matrox introduced the world to the G550. But the G550 lacked the performance and features of its competitors, and was relegated mostly to 2D work. The G550 was more an evolution of the G450 than anything else, but this time, things are different. Matrox's new Parhelia is an all-new design, incorporating modern features such as Direct X 8.1-compliant pixel and vertex shaders. The G550's 166 MHz 64-bit DDR SDRAM memory interface has been replaced with a far more robust 275 MHz (250 MHz OEM/bulk) 256-bit DDR SDRAM interface capable of 17.6 GB/s. This combined with some interesting and innovative features like hardware displacement-mapping, triple-head surround gaming, and the prospects for Matrox's next- generation product are looking quite good. The Matrox Parhelia But not everything is looking so bright for Parhelia. Manufactured on a 0.15µ process, the 80 million transistor GPU is quite large and also quite hot. Consequently, it currently clocks in at only 220 MHz. To contrast, compare the GeForce 4 Ti4400's 300 MHz clockrate. The low clockrate is compounded by a lack of hardware occlusion culling, which means the quad-pipeline renderer is significantly less efficient than many other contemporary designs when it comes to overdraw. -

Intel®Server Boards S2400LP
Intel® Server Boards S2400LP Technical Product Specification Intel order number G52803-002 Revision 2.0 December 2013 Platform Collaboration and Systems Division - Marketing Revision History Intel® Server Boards S2400LP TPS Revision History Date Revision Modifications Number May 2012 1.0 Initial release. December 2013 2.0 Added support for Intel® Xeon® processor E5-2400 v2 product family ii Intel order number G52803-002 Revision 2.0 Intel® Server Boards S2400LP TPS Disclaimers Disclaimers INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. A "Mission Critical Application" is any application in which failure of the Intel Product could result, directly or indirectly, in personal injury or death. SHOULD YOU PURCHASE OR USE INTEL'S PRODUCTS FOR ANY SUCH MISSION CRITICAL APPLICATION, YOU SHALL INDEMNIFY AND HOLD INTEL AND ITS SUBSIDIARIES, SUBCONTRACTORS AND AFFILIATES, AND THE DIRECTORS, OFFICERS, AND EMPLOYEES OF EACH, HARMLESS AGAINST ALL CLAIMS COSTS, DAMAGES, AND EXPENSES AND REASONABLE ATTORNEYS' FEES ARISING OUT OF, DIRECTLY OR INDIRECTLY, ANY CLAIM OF PRODUCT LIABILITY, PERSONAL INJURY, OR DEATH ARISING IN ANY WAY OUT OF SUCH MISSION CRITICAL APPLICATION, WHETHER OR NOT INTEL OR ITS SUBCONTRACTOR WAS NEGLIGENT IN THE DESIGN, MANUFACTURE, OR WARNING OF THE INTEL PRODUCT OR ANY OF ITS PARTS. -

Superworkstations
SuperWorkstations Enterprise-Class Systems Optimized for Media & Entertainment, Engineering, and Research 5038A-iL 7047GR-TRF 7047AX-TRF/72RF 7047A-T/73 7037A-i/iL High Performance GPU Optimized Hyper-Speed Storage Optimized w/ Dual CPU Workstation Versatile Features & I/O w/ 5 GPUs Workstation 8x SATA/ SAS 2.0 HDDs Mini-Tower Access Performance • Efficiency • Expandability • Reliability • Optimized Applications : Video Editing, Digital Content Creation, CAD/CAE/CAM Software Development, Scientific Research and Oil & Gas Applications • Whisper-Quiet 21dB Acoustics Models • Redundant Platinum Level (95%+) Digital Power Supplies Available • Up to 1TB DDR3 memory and 8x Hot-Swap HDDs • Up to 5x GPUs supported with PCI-E 3.0 x16 • Supports Intel® Xeon® Processor E5-2600/2400/1600 v2 series up to 150W CPUs and E3-1200 v3 Product Families • Server-Grade Design for 24x7 Operation www.supermicro.com/SuperWorkstations April 2014 High-Performance, High-Efficiency for Personal SuperComputing Hyper-Speed Workstation The Only 4+1 GPU New! Outperforms by 20% System in the Market Whisper-Quiet DP Compact High-End High Performance, Versatile Most Cost-Effective Whisper-Quiet Entry Level via Hardware Acceleration Up to 67% Performance Gain Solution with SAS DP Solution Compact DP Solution Features & I/O Access Maximus System Cost-Effective Solution ULTIMATE ULTIMATE HIGH END HIGH END MAINSTREAM MAINSTREAM MAINSTREAM ENTRY LEVEL SYSTEM 7047AX-TRF/72RF 7047GR-TRF 7047A-T/73 7037A-i 7037A-iL 5038A-iL 5037A-i 5037A-iL Socket R LGA 2011 Socket R LGA 2011 Socket -

Intel's Core 2 Family
Intel’s Core 2 family - TOCK lines II Nehalem to Haswell Dezső Sima Vers. 3.11 August 2018 Contents • 1. Introduction • 2. The Core 2 line • 3. The Nehalem line • 4. The Sandy Bridge line • 5. The Haswell line • 6. The Skylake line • 7. The Kaby Lake line • 8. The Kaby Lake Refresh line • 9. The Coffee Lake line • 10. The Cannon Lake line 3. The Nehalem line 3.1 Introduction to the 1. generation Nehalem line • (Bloomfield) • 3.2 Major innovations of the 1. gen. Nehalem line 3.3 Major innovations of the 2. gen. Nehalem line • (Lynnfield) 3.1 Introduction to the 1. generation Nehalem line (Bloomfield) 3.1 Introduction to the 1. generation Nehalem line (Bloomfield) (1) 3.1 Introduction to the 1. generation Nehalem line (Bloomfield) Developed at Hillsboro, Oregon, at the site where the Pentium 4 was designed. Experiences with HT Nehalem became a multithreaded design. The design effort took about five years and required thousands of engineers (Ronak Singhal, lead architect of Nehalem) [37]. The 1. gen. Nehalem line targets DP servers, yet its first implementation appeared in the desktop segment (Core i7-9xx (Bloomfield)) 4C in 11/2008 1. gen. 2. gen. 3. gen. 4. gen. 5. gen. West- Core 2 Penryn Nehalem Sandy Ivy Haswell Broad- mere Bridge Bridge well New New New New New New New New Microarch. Process Microarchi. Microarch. Process Microarch. Process Process 45 nm 65 nm 45 nm 32 nm 32 nm 22 nm 22 nm 14 nm TOCK TICK TOCK TICK TOCK TICK TOCK TICK (2006) (2007) (2008) (2010) (2011) (2012) (2013) (2014) Figure : Intel’s Tick-Tock development model (Based on [1]) * 3.1 Introduction to the 1.