Proposal for a Chinese Script Root Zone LGR
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Prioritizing African Languages: Challenges to Macro-Level Planning for Resourcing and Capacity Building
Prioritizing African Languages: Challenges to macro-level planning for resourcing and capacity building Tristan M. Purvis Christopher R. Green Gregory K. Iverson University of Maryland Center for Advanced Study of Language Abstract This paper addresses key considerations and challenges involved in the process of prioritizing languages in an area of high linguistic di- versity like Africa alongside other world regions. The paper identifies general considerations that must be taken into account in this process and reviews the placement of African languages on priority lists over the years and across different agencies and organizations. An outline of factors is presented that is used when organizing resources and planning research on African languages that categorizes major or crit- ical languages within a framework that allows for broad coverage of the full linguistic diversity of the continent. Keywords: language prioritization, African languages, capacity building, language diversity, language documentation When building language capacity on an individual or localized level, the question of which languages matter most is relatively less complicated than it is for those planning and providing for language capabilities at the macro level. An American anthropology student working with Sierra Leonean refugees in Forecariah, Guinea, for ex- ample, will likely know how to address and balance needs for lan- guage skills in French, Susu, Krio, and a set of other languages such as Temne and Mandinka. An education official or activist in Mwanza, Tanzania, will be concerned primarily with English, Swahili, and Su- kuma. An administrator of a grant program for Less Commonly Taught Languages, or LCTLs, or a newly appointed language authori- ty for the United States Department of Education, Department of Commerce, or U.S. -

Volume 11 JNCOLCTL Final Online.Pdf
Journal of the National Council of Less Commonly Taught Languages Vol. 11 Spring, 2012 Danko Šipka, Editor Antonia Schleicher, Managing Editor Charles Schleicher, Copy Editor Nyasha Gwaza, Production Editor Kevin Barry, Production Assistant The development of the Journal of the National Council of Less Commonly Taught Languages is made possible in part through a grant from the U.S. Department of Education Please address enquiries concerning advertising, subscriptions and issues to the NCOLCTL Secretariat at the following address: National African Language Resource Center 4231 Humanities Building, 455 N. Park St., Madison, WI 53706 Copyright © 2012, National Council of Less Commonly Taught Languages (NCOLCTL) iii The Journal of the National Council of Less Commonly Taught Languages, published annually by the Council, is dedicated to the issues and concerns related to the teaching and learning of Less Commonly Taught Languages. The Journal primarily seeks to address the interests of language teachers, administrators, and researchers. Arti- cles that describe innovative and successful teaching methods that are relevant to the concerns or problems of the profession, or that report educational research or experimentation in Less Commonly Taught Languages are welcome. Papers presented at the Council’s annual con- ference will be considered for publication, but additional manuscripts from members of the profession are also welcome. Besides the Journal Editor, the process of selecting material for publication is overseen by the Advisory Editorial Board, which con- sists of the foremost scholars, advocates, and practitioners of LCTL pedagogy. The members of the Board represent diverse linguistic and geographical categories, as well as the academic, government, and business sectors. -

Digital Editions of Premodern Chinese Texts: Methods and Problems – Exemplified Using the Daozang Jiyao1道藏輯要
Chung-Hwa Buddhist Journal (2012, 25:167-194) Taipei: Chung-Hwa Institute of Buddhist Studies 中華佛學學報第二十五期 頁 167-194 (民國一百零一年),臺北:中華佛學研究所 ISSN:1017-7132 Digital Editions of Premodern Chinese Texts: Methods and Problems – Exemplified Using the Daozang Jiyao1道藏輯要 Christian Wittern Kyoto University Abstract Digital editions do have a great potential for new avenues of research, but they also pose vexing research questions that have to be resolved adequately in order to make the resulting edition useful in the long run. One of the many differences between printed editions of texts and digital editions is the open-endedness of the latter, which means that it can be done incrementally and updated without incurring substantial expenses. The medium of digital editions requires the creator to make many assumptions about the texts explicit and record them in a way that can be processed automatically. This is a new concept, which seems foreign to the agenda of a scholar whose ultimate aim is to engage with the text. This article demonstrates that what seems like a detour is actually advancing the understanding of the text and the need objectify a text in this gives access to new dimensions of a text. It then goes on to provide details of a conceptual model for describing a premodern text digitally that has been developed working on a digital edition of the early Qing Daoist collection Daozang jiyao. Keywords: Text Encoding, Digital Editions, Character Encoding, XML, Doaist Studies 1 I would like to thank the anonymous reviewers for this journal for their very helpful suggestions for clarifications and general improvement of the article. -

The Effect of Pinyin in Chinese Vocabulary Acquisition with English-Chinese Bilingual Learners
St. Cloud State University theRepository at St. Cloud State Culminating Projects in TESL Department of English 12-2019 The Effect of Pinyin in Chinese Vocabulary Acquisition with English-Chinese Bilingual Learners Yahui Shi Follow this and additional works at: https://repository.stcloudstate.edu/tesl_etds Recommended Citation Shi, Yahui, "The Effect of Pinyin in Chinese Vocabulary Acquisition with English-Chinese Bilingual Learners" (2019). Culminating Projects in TESL. 17. https://repository.stcloudstate.edu/tesl_etds/17 This Thesis is brought to you for free and open access by the Department of English at theRepository at St. Cloud State. It has been accepted for inclusion in Culminating Projects in TESL by an authorized administrator of theRepository at St. Cloud State. For more information, please contact [email protected]. The Effect of Pinyin in Chinese Vocabulary Acquisition with English-Chinese Bilingual learners by Yahui Shi A Thesis Submitted to the Graduate Faculty of St. Cloud State University in Partial Fulfillment of the Requirements for the Degree Master of Arts in English: Teaching English as a Second Language December, 2019 Thesis Committee: Choonkyong Kim, Chairperson John Madden Zengjun Peng 2 Abstract This study investigates Chinese vocabulary acquisition of Chinese language learners in English-Chinese bilingual contexts; the 20 participants in this study were English native speakers, who were enrolled in a Chinese immersion program in central Minnesota. The study used a matching test, and the test contains seven sets of test items. In each set, there were six Chinese vocabulary words and the English translations of three of them. The six words are listed in one column on the left, and the three translations were in another column on the right. -

Languages of Southeast Asia
Jiarong Horpa Zhaba Amdo Tibetan Guiqiong Queyu Horpa Wu Chinese Central Tibetan Khams Tibetan Muya Huizhou Chinese Eastern Xiangxi Miao Yidu LuobaLanguages of Southeast Asia Northern Tujia Bogaer Luoba Ersu Yidu Luoba Tibetan Mandarin Chinese Digaro-Mishmi Northern Pumi Yidu LuobaDarang Deng Namuyi Bogaer Luoba Geman Deng Shixing Hmong Njua Eastern Xiangxi Miao Tibetan Idu-Mishmi Idu-Mishmi Nuosu Tibetan Tshangla Hmong Njua Miju-Mishmi Drung Tawan Monba Wunai Bunu Adi Khamti Southern Pumi Large Flowery Miao Dzongkha Kurtokha Dzalakha Phake Wunai Bunu Ta w an g M o np a Gelao Wunai Bunu Gan Chinese Bumthangkha Lama Nung Wusa Nasu Wunai Bunu Norra Wusa Nasu Xiang Chinese Chug Nung Wunai Bunu Chocangacakha Dakpakha Khamti Min Bei Chinese Nupbikha Lish Kachari Ta se N a ga Naxi Hmong Njua Brokpake Nisi Khamti Nung Large Flowery Miao Nyenkha Chalikha Sartang Lisu Nung Lisu Southern Pumi Kalaktang Monpa Apatani Khamti Ta se N a ga Wusa Nasu Adap Tshangla Nocte Naga Ayi Nung Khengkha Rawang Gongduk Tshangla Sherdukpen Nocte Naga Lisu Large Flowery Miao Northern Dong Khamti Lipo Wusa NasuWhite Miao Nepali Nepali Lhao Vo Deori Luopohe Miao Ge Southern Pumi White Miao Nepali Konyak Naga Nusu Gelao GelaoNorthern Guiyang MiaoLuopohe Miao Bodo Kachari White Miao Khamti Lipo Lipo Northern Qiandong Miao White Miao Gelao Hmong Njua Eastern Qiandong Miao Phom Naga Khamti Zauzou Lipo Large Flowery Miao Ge Northern Rengma Naga Chang Naga Wusa Nasu Wunai Bunu Assamese Southern Guiyang Miao Southern Rengma Naga Khamti Ta i N u a Wusa Nasu Northern Huishui -

THE MEDIA's INFLUENCE on SUCCESS and FAILURE of DIALECTS: the CASE of CANTONESE and SHAAN'xi DIALECTS Yuhan Mao a Thesis Su
THE MEDIA’S INFLUENCE ON SUCCESS AND FAILURE OF DIALECTS: THE CASE OF CANTONESE AND SHAAN’XI DIALECTS Yuhan Mao A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Arts (Language and Communication) School of Language and Communication National Institute of Development Administration 2013 ABSTRACT Title of Thesis The Media’s Influence on Success and Failure of Dialects: The Case of Cantonese and Shaan’xi Dialects Author Miss Yuhan Mao Degree Master of Arts in Language and Communication Year 2013 In this thesis the researcher addresses an important set of issues - how language maintenance (LM) between dominant and vernacular varieties of speech (also known as dialects) - are conditioned by increasingly globalized mass media industries. In particular, how the television and film industries (as an outgrowth of the mass media) related to social dialectology help maintain and promote one regional variety of speech over others is examined. These issues and data addressed in the current study have the potential to make a contribution to the current understanding of social dialectology literature - a sub-branch of sociolinguistics - particularly with respect to LM literature. The researcher adopts a multi-method approach (literature review, interviews and observations) to collect and analyze data. The researcher found support to confirm two positive correlations: the correlative relationship between the number of productions of dialectal television series (and films) and the distribution of the dialect in question, as well as the number of dialectal speakers and the maintenance of the dialect under investigation. ACKNOWLEDGMENTS The author would like to express sincere thanks to my advisors and all the people who gave me invaluable suggestions and help. -

ISO 639-3 Code Split Request Template
ISO 639-3 Registration Authority Request for Change to ISO 639-3 Language Code Change Request Number: 2019-061 (completed by Registration authority) Date: 2019 Aug 31 Primary Person submitting request: Kirk Miller E-mail address: kirkmillerat gmail dot com Names, affiliations and email addresses of additional supporters of this request: PLEASE NOTE: This completed form will become part of the public record of this change request and the history of the ISO 639-3 code set and will be posted on the ISO 639-3 website. Types of change requests Type of change proposed (check one): 1. Modify reference information for an existing language code element 2. Propose a new macrolanguage or modify a macrolanguage group 3. Retire a language code element from use (duplicate or non-existent) 4. Expand the denotation of a code element through the merging one or more language code elements into it (retiring the latter group of code elements) 5. Split a language code element into two or more new code elements 6. Create a code element for a previously unidentified language For proposing a change to an existing code element, please identify: Affected ISO 639-3 identifier: czh Associated reference name: Huizhou Chinese 5. Split a language code element into two or more code elements (a) List the languages into which this code element should be split: Jishe Hui Chinese Xiuyi Hui Chinese Qide Hui Chinese (Qiwu Hui Chinese) Jingzhan Hui Chinese Yanzhou Hui Chinese ���� (b) Referring to the criteria given above, give the rationale for splitting the existing code element into two or more languages: Despite their relatively small geographic area, there is a very low degree of intelligibility among the Huizhou lects. -

Learning Chinese Characters Through Applied
Learning(g Chinese Characters (汉字)g) through Applied Pattern Recognition Dr. Ta’id HOLMES (博士·福尔摩斯·大山) TIP SAP Research SE&T Non-Objectives Scientific Talk Relevancy &C& Completeness of fC Content Writing & Spea kin g © 2011 SAP AG. All rights reserved. 2 Objectives Activating your Intrinsic “Research Gene“ Raising your Curiosity Boost your Creativity, Motivation, & Happiness Gain a Basic Understanding of Written Chinese Develop a Profound Appreciation for the Different © 2011 SAP AG. All rights reserved. 3 Agenda (政纲) 1 Facts (事实) 2 History (历史) 3 Examples (实例) 4 Outlook (图景) © 2011 SAP AG. All rights reserved. 4 Facts (事实): Some Metrics 100,000+ characters 2000 simplified characters 3000 99% of characters used in newspapers 4000 you may consider yourself educated 6000 to read literature or Classical Chinese 1,300,000+ speakers © 2011 SAP AG. All rights reserved. 5 Total Number of Chinese Characters (汉字) Year Name of dictionary Number of characters 100 Shuowen Jiezi 9,353 543? Yupian 12,158 601 Qieyun 16,917 997 Longkan Shoujian 26,430 1011 Guangyun 26,194 1039 Jiyun 53, 525 1615 Zihui 33,179 1675 Zhengzitong 33, 440 1716 Kangxi Zidian 47,035 1916 Zhonghua Da Zidian 48,000 1989 Hanyu Da Zidian 54,678 1994 Zhonghua Zihai 85,568 2004 Yitizi Zidian 106,230 © 2011 SAP AG. All rights reserved. 6 1 Facts (事实) 2 History (历史) 3 Examples (实例) 4 Outlook (图景) © 2011 SAP AG. All rights reserved. 7 History (历史) Jiǎhú (賈湖) symbols: 6600-6200 BC © 2011 SAP AG. All rights reserved. 8 Shang Dynasty (商朝): 1600-1046 BC Oracle bone script (甲骨文) © 2011 SAP AG. -
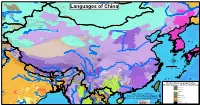
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

Yichang to Badong Expressway Project
IPP307 v2 World Bank Financed Highway Project Yiba Expressway in Hubei·P. R. China YBE_05 Public Disclosure Authorized Public Disclosure Authorized Yichang to Badong Expressway Project Social Assessment Report Final Public Disclosure Authorized Public Disclosure Authorized The World Bank Financed Project Office of HPCD Social Survey Research Center of Peking University 22 September 2008 1 Preface Entrusted by the World Bank Financed Project Execution Office (PEO) under the Hubei Provincial Communications Department (HPCD), the Social Survey Research Center of Peking University (SSRCPKU) conducted an independent assessment on the “Project of the Stretch from Yichang to Badong of the Highway from Shanghai to Chengdu”. The Yiba stretch of the highway from Shanghai to Chengdu is lying in the west of Hubei Province which is at the joint of middle reaches and upper reaches of the Yangtze River. The project area administratively belongs to Yiling District Yichang City, Zigui County, Xingshang County and Badong County of Shien Tujia & Miao Autonomous Prefecture. It adjoins Jianghan Plain in the east, Chongqing City in the west, Yangtze River in the south and Shengnongjia Forest, Xiangfan City etc in the north. The highway, extending 173 km, begins in Baihe, connecting Jingyi highway, and ends up in Badong County in the joint of Hubei and Sichuan, joining Wufeng highway in Chongqing. Under the precondition of sticking to the World Bank’s policy, the social assessment is going to make a judgment of the social impact exerted by the project, advance certain measures, and in the meanwhile bring forward supervision and appraisement system. During July 1st and 9th, 2007, the assessment team conducted the social investigation in Yiling District Yichang City, Zigui County, XingshanCounty and Badong County. -

ISO 639-3 Code Split Request Template
ISO 639-3 Registration Authority Request for Change to ISO 639-3 Language Code Change Request Number: 2019-065 (completed by Registration authority) Date: August 31, 2019 Primary Person submitting request: Kirk Miller Affiliation: E-mail address: kirkmiller at gmail dot com Names, affiliations and email addresses of additional supporters of this request: Postal address for primary contact person for this request (in general, email correspondence will be used): PLEASE NOTE: This completed form will become part of the public record of this change request and the history of the ISO 639-3 code set and will be posted on the ISO 639-3 website. Types of change requests This form is to be used in requesting changes (whether creation, modification, or deletion) to elements of the ISO 639 Codes for the representation of names of languages — Part 3: Alpha-3 code for comprehensive coverage of languages. The types of changes that are possible are to 1) modify the reference information for an existing code element, 2) propose a new macrolanguage or modify a macrolanguage group; 3) retire a code element from use, including merging its scope of denotation into that of another code element, 4) split an existing code element into two or more new language code elements, or 5) create a new code element for a previously unidentified language variety. Fill out section 1, 2, 3, 4, or 5 below as appropriate, and the final section documenting the sources of your information. The process by which a change is received, reviewed and adopted is summarized on the final page of this form. -

The Linguistic Analysis of Chinese Emoticon
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses Dissertations and Theses July 2015 THE LINGUISTIC ANALYSIS OF CHINESE EMOTICON Xiangxi Liu University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/masters_theses_2 Part of the Chinese Studies Commons Recommended Citation Liu, Xiangxi, "THE LINGUISTIC ANALYSIS OF CHINESE EMOTICON" (2015). Masters Theses. 236. https://doi.org/10.7275/6945608 https://scholarworks.umass.edu/masters_theses_2/236 This Open Access Thesis is brought to you for free and open access by the Dissertations and Theses at ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. THE LINGUISTIC ANALYSIS OF CHINESE EMOTICON A Thesis Presented by XIANGXI LIU Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF ARTS May 2015 Asian Languages and Literatures i © Copyright by Xiangxi Liu 2015 All Rights Reserved ii THE LINGUISTIC ANALYSIS OF CHINESE EMOTICON A Thesis Presented by XIANGXI LIU Approved as to style and content by: ______________________________________ Zhongwei Shen, Chair ______________________________________ Enhua Zhang, Member ______________________________________ Zhijun Wang, Member ________________________________________ Stephen Miller Director Asian Languages and Literatures ________________________________________ William Moebius, Chair Department of Languages, Literatures and Cultures iii ACKNOWLEDGMENTS First, I gratefully acknowledge my advisor, Zhongwei Shen, for granting me the opportunity to pursue my master’s degree under his guidance. Since I’m certainly not his typical student type: hard working, always meeting deadlines and attention to details.