PDF Output of CLIC (Clustering by Inferred Co-Expression)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Gene Knockdown of CENPA Reduces Sphere Forming Ability and Stemness of Glioblastoma Initiating Cells
Neuroepigenetics 7 (2016) 6–18 Contents lists available at ScienceDirect Neuroepigenetics journal homepage: www.elsevier.com/locate/nepig Gene knockdown of CENPA reduces sphere forming ability and stemness of glioblastoma initiating cells Jinan Behnan a,1, Zanina Grieg b,c,1, Mrinal Joel b,c, Ingunn Ramsness c, Biljana Stangeland a,b,⁎ a Department of Molecular Medicine, Institute of Basic Medical Sciences, The Medical Faculty, University of Oslo, Oslo, Norway b Norwegian Center for Stem Cell Research, Department of Immunology and Transfusion Medicine, Oslo University Hospital, Oslo, Norway c Vilhelm Magnus Laboratory for Neurosurgical Research, Institute for Surgical Research and Department of Neurosurgery, Oslo University Hospital, Oslo, Norway article info abstract Article history: CENPA is a centromere-associated variant of histone H3 implicated in numerous malignancies. However, the Received 20 May 2016 role of this protein in glioblastoma (GBM) has not been demonstrated. GBM is one of the most aggressive Received in revised form 23 July 2016 human cancers. GBM initiating cells (GICs), contained within these tumors are deemed to convey Accepted 2 August 2016 characteristics such as invasiveness and resistance to therapy. Therefore, there is a strong rationale for targeting these cells. We investigated the expression of CENPA and other centromeric proteins (CENPs) in Keywords: fi CENPA GICs, GBM and variety of other cell types and tissues. Bioinformatics analysis identi ed the gene signature: fi Centromeric proteins high_CENP(AEFNM)/low_CENP(BCTQ) whose expression correlated with signi cantly worse GBM patient Glioblastoma survival. GBM Knockdown of CENPA reduced sphere forming ability, proliferation and cell viability of GICs. We also Brain tumor detected significant reduction in the expression of stemness marker SOX2 and the proliferation marker Glioblastoma initiating cells and therapeutic Ki67. -

Centromere RNA Is a Key Component for the Assembly of Nucleoproteins at the Nucleolus and Centromere
Downloaded from genome.cshlp.org on September 23, 2021 - Published by Cold Spring Harbor Laboratory Press Letter Centromere RNA is a key component for the assembly of nucleoproteins at the nucleolus and centromere Lee H. Wong,1,3 Kate H. Brettingham-Moore,1 Lyn Chan,1 Julie M. Quach,1 Melisssa A. Anderson,1 Emma L. Northrop,1 Ross Hannan,2 Richard Saffery,1 Margaret L. Shaw,1 Evan Williams,1 and K.H. Andy Choo1 1Chromosome and Chromatin Research Laboratory, Murdoch Childrens Research Institute & Department of Paediatrics, University of Melbourne, Royal Children’s Hospital, Parkville 3052, Victoria, Australia; 2Peter MacCallum Research Institute, St. Andrew’s Place, East Melbourne, Victoria 3002, Australia The centromere is a complex structure, the components and assembly pathway of which remain inadequately defined. Here, we demonstrate that centromeric ␣-satellite RNA and proteins CENPC1 and INCENP accumulate in the human interphase nucleolus in an RNA polymerase I–dependent manner. The nucleolar targeting of CENPC1 and INCENP requires ␣-satellite RNA, as evident from the delocalization of both proteins from the nucleolus in RNase-treated cells, and the nucleolar relocalization of these proteins following ␣-satellite RNA replenishment in these cells. Using protein truncation and in vitro mutagenesis, we have identified the nucleolar localization sequences on CENPC1 and INCENP. We present evidence that CENPC1 is an RNA-associating protein that binds ␣-satellite RNA by an in vitro binding assay. Using chromatin immunoprecipitation, RNase treatment, and “RNA replenishment” experiments, we show that ␣-satellite RNA is a key component in the assembly of CENPC1, INCENP, and survivin (an INCENP-interacting protein) at the metaphase centromere. -
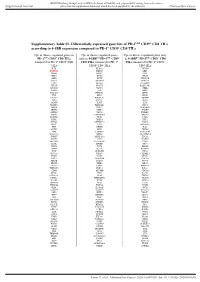
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

1 AGING Supplementary Table 2
SUPPLEMENTARY TABLES Supplementary Table 1. Details of the eight domain chains of KIAA0101. Serial IDENTITY MAX IN COMP- INTERFACE ID POSITION RESOLUTION EXPERIMENT TYPE number START STOP SCORE IDENTITY LEX WITH CAVITY A 4D2G_D 52 - 69 52 69 100 100 2.65 Å PCNA X-RAY DIFFRACTION √ B 4D2G_E 52 - 69 52 69 100 100 2.65 Å PCNA X-RAY DIFFRACTION √ C 6EHT_D 52 - 71 52 71 100 100 3.2Å PCNA X-RAY DIFFRACTION √ D 6EHT_E 52 - 71 52 71 100 100 3.2Å PCNA X-RAY DIFFRACTION √ E 6GWS_D 41-72 41 72 100 100 3.2Å PCNA X-RAY DIFFRACTION √ F 6GWS_E 41-72 41 72 100 100 2.9Å PCNA X-RAY DIFFRACTION √ G 6GWS_F 41-72 41 72 100 100 2.9Å PCNA X-RAY DIFFRACTION √ H 6IIW_B 2-11 2 11 100 100 1.699Å UHRF1 X-RAY DIFFRACTION √ www.aging-us.com 1 AGING Supplementary Table 2. Significantly enriched gene ontology (GO) annotations (cellular components) of KIAA0101 in lung adenocarcinoma (LinkedOmics). Leading Description FDR Leading Edge Gene EdgeNum RAD51, SPC25, CCNB1, BIRC5, NCAPG, ZWINT, MAD2L1, SKA3, NUF2, BUB1B, CENPA, SKA1, AURKB, NEK2, CENPW, HJURP, NDC80, CDCA5, NCAPH, BUB1, ZWILCH, CENPK, KIF2C, AURKA, CENPN, TOP2A, CENPM, PLK1, ERCC6L, CDT1, CHEK1, SPAG5, CENPH, condensed 66 0 SPC24, NUP37, BLM, CENPE, BUB3, CDK2, FANCD2, CENPO, CENPF, BRCA1, DSN1, chromosome MKI67, NCAPG2, H2AFX, HMGB2, SUV39H1, CBX3, TUBG1, KNTC1, PPP1CC, SMC2, BANF1, NCAPD2, SKA2, NUP107, BRCA2, NUP85, ITGB3BP, SYCE2, TOPBP1, DMC1, SMC4, INCENP. RAD51, OIP5, CDK1, SPC25, CCNB1, BIRC5, NCAPG, ZWINT, MAD2L1, SKA3, NUF2, BUB1B, CENPA, SKA1, AURKB, NEK2, ESCO2, CENPW, HJURP, TTK, NDC80, CDCA5, BUB1, ZWILCH, CENPK, KIF2C, AURKA, DSCC1, CENPN, CDCA8, CENPM, PLK1, MCM6, ERCC6L, CDT1, HELLS, CHEK1, SPAG5, CENPH, PCNA, SPC24, CENPI, NUP37, FEN1, chromosomal 94 0 CENPL, BLM, KIF18A, CENPE, MCM4, BUB3, SUV39H2, MCM2, CDK2, PIF1, DNA2, region CENPO, CENPF, CHEK2, DSN1, H2AFX, MCM7, SUV39H1, MTBP, CBX3, RECQL4, KNTC1, PPP1CC, CENPP, CENPQ, PTGES3, NCAPD2, DYNLL1, SKA2, HAT1, NUP107, MCM5, MCM3, MSH2, BRCA2, NUP85, SSB, ITGB3BP, DMC1, INCENP, THOC3, XPO1, APEX1, XRCC5, KIF22, DCLRE1A, SEH1L, XRCC3, NSMCE2, RAD21. -

Supplementary Table S1. Correlation Between the Mutant P53-Interacting Partners and PTTG3P, PTTG1 and PTTG2, Based on Data from Starbase V3.0 Database
Supplementary Table S1. Correlation between the mutant p53-interacting partners and PTTG3P, PTTG1 and PTTG2, based on data from StarBase v3.0 database. PTTG3P PTTG1 PTTG2 Gene ID Coefficient-R p-value Coefficient-R p-value Coefficient-R p-value NF-YA ENSG00000001167 −0.077 8.59e-2 −0.210 2.09e-6 −0.122 6.23e-3 NF-YB ENSG00000120837 0.176 7.12e-5 0.227 2.82e-7 0.094 3.59e-2 NF-YC ENSG00000066136 0.124 5.45e-3 0.124 5.40e-3 0.051 2.51e-1 Sp1 ENSG00000185591 −0.014 7.50e-1 −0.201 5.82e-6 −0.072 1.07e-1 Ets-1 ENSG00000134954 −0.096 3.14e-2 −0.257 4.83e-9 0.034 4.46e-1 VDR ENSG00000111424 −0.091 4.10e-2 −0.216 1.03e-6 0.014 7.48e-1 SREBP-2 ENSG00000198911 −0.064 1.53e-1 −0.147 9.27e-4 −0.073 1.01e-1 TopBP1 ENSG00000163781 0.067 1.36e-1 0.051 2.57e-1 −0.020 6.57e-1 Pin1 ENSG00000127445 0.250 1.40e-8 0.571 9.56e-45 0.187 2.52e-5 MRE11 ENSG00000020922 0.063 1.56e-1 −0.007 8.81e-1 −0.024 5.93e-1 PML ENSG00000140464 0.072 1.05e-1 0.217 9.36e-7 0.166 1.85e-4 p63 ENSG00000073282 −0.120 7.04e-3 −0.283 1.08e-10 −0.198 7.71e-6 p73 ENSG00000078900 0.104 2.03e-2 0.258 4.67e-9 0.097 3.02e-2 Supplementary Table S2. -

How Does SUMO Participate in Spindle Organization?
cells Review How Does SUMO Participate in Spindle Organization? Ariane Abrieu * and Dimitris Liakopoulos * CRBM, CNRS UMR5237, Université de Montpellier, 1919 route de Mende, 34090 Montpellier, France * Correspondence: [email protected] (A.A.); [email protected] (D.L.) Received: 5 July 2019; Accepted: 30 July 2019; Published: 31 July 2019 Abstract: The ubiquitin-like protein SUMO is a regulator involved in most cellular mechanisms. Recent studies have discovered new modes of function for this protein. Of particular interest is the ability of SUMO to organize proteins in larger assemblies, as well as the role of SUMO-dependent ubiquitylation in their disassembly. These mechanisms have been largely described in the context of DNA repair, transcriptional regulation, or signaling, while much less is known on how SUMO facilitates organization of microtubule-dependent processes during mitosis. Remarkably however, SUMO has been known for a long time to modify kinetochore proteins, while more recently, extensive proteomic screens have identified a large number of microtubule- and spindle-associated proteins that are SUMOylated. The aim of this review is to focus on the possible role of SUMOylation in organization of the spindle and kinetochore complexes. We summarize mitotic and microtubule/spindle-associated proteins that have been identified as SUMO conjugates and present examples regarding their regulation by SUMO. Moreover, we discuss the possible contribution of SUMOylation in organization of larger protein assemblies on the spindle, as well as the role of SUMO-targeted ubiquitylation in control of kinetochore assembly and function. Finally, we propose future directions regarding the study of SUMOylation in regulation of spindle organization and examine the potential of SUMO and SUMO-mediated degradation as target for antimitotic-based therapies. -

The Genetic Program of Pancreatic Beta-Cell Replication in Vivo
Page 1 of 65 Diabetes The genetic program of pancreatic beta-cell replication in vivo Agnes Klochendler1, Inbal Caspi2, Noa Corem1, Maya Moran3, Oriel Friedlich1, Sharona Elgavish4, Yuval Nevo4, Aharon Helman1, Benjamin Glaser5, Amir Eden3, Shalev Itzkovitz2, Yuval Dor1,* 1Department of Developmental Biology and Cancer Research, The Institute for Medical Research Israel-Canada, The Hebrew University-Hadassah Medical School, Jerusalem 91120, Israel 2Department of Molecular Cell Biology, Weizmann Institute of Science, Rehovot, Israel. 3Department of Cell and Developmental Biology, The Silberman Institute of Life Sciences, The Hebrew University of Jerusalem, Jerusalem 91904, Israel 4Info-CORE, Bioinformatics Unit of the I-CORE Computation Center, The Hebrew University and Hadassah, The Institute for Medical Research Israel- Canada, The Hebrew University-Hadassah Medical School, Jerusalem 91120, Israel 5Endocrinology and Metabolism Service, Department of Internal Medicine, Hadassah-Hebrew University Medical Center, Jerusalem 91120, Israel *Correspondence: [email protected] Running title: The genetic program of pancreatic β-cell replication 1 Diabetes Publish Ahead of Print, published online March 18, 2016 Diabetes Page 2 of 65 Abstract The molecular program underlying infrequent replication of pancreatic beta- cells remains largely inaccessible. Using transgenic mice expressing GFP in cycling cells we sorted live, replicating beta-cells and determined their transcriptome. Replicating beta-cells upregulate hundreds of proliferation- related genes, along with many novel putative cell cycle components. Strikingly, genes involved in beta-cell functions, namely glucose sensing and insulin secretion were repressed. Further studies using single molecule RNA in situ hybridization revealed that in fact, replicating beta-cells double the amount of RNA for most genes, but this upregulation excludes genes involved in beta-cell function. -
![CENPO Mouse Monoclonal Antibody [Clone ID: OTI7F9] Product Data](https://docslib.b-cdn.net/cover/9915/cenpo-mouse-monoclonal-antibody-clone-id-oti7f9-product-data-2339915.webp)
CENPO Mouse Monoclonal Antibody [Clone ID: OTI7F9] Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for CF809481 CENPO Mouse Monoclonal Antibody [Clone ID: OTI7F9] Product data: Product Type: Primary Antibodies Clone Name: OTI7F9 Applications: WB Recommended Dilution: WB 1:2000 Reactivity: Human Host: Mouse Isotype: IgG2b Clonality: Monoclonal Immunogen: Human recombinant protein fragment corresponding to amino acids 1-230 of human CENPO (NP_077298) produced in E.coli. Formulation: Lyophilized powder (original buffer 1X PBS, pH 7.3, 8% trehalose) Reconstitution Method: For reconstitution, we recommend adding 100uL distilled water to a final antibody concentration of about 1 mg/mL. To use this carrier-free antibody for conjugation experiment, we strongly recommend performing another round of desalting process. (OriGene recommends Zeba Spin Desalting Columns, 7KMWCO from Thermo Scientific) Purification: Purified from mouse ascites fluids or tissue culture supernatant by affinity chromatography (protein A/G) Conjugation: Unconjugated Storage: Store at -20°C as received. Stability: Stable for 12 months from date of receipt. Predicted Protein Size: 33.6 kDa Gene Name: Homo sapiens centromere protein O (CENPO), transcript variant 1, mRNA. Database Link: NP_077298 Entrez Gene 79172 Human Q9BU64 This product is to be used for laboratory only. Not for diagnostic or therapeutic use. View online » ©2021 OriGene Technologies, Inc., 9620 Medical Center Drive, Ste 200, Rockville, MD 20850, US 1 / 2 CENPO Mouse Monoclonal Antibody [Clone ID: OTI7F9] – CF809481 Background: This gene encodes a component of the interphase centromere complex. The encoded protein is localized to the centromere throughout the cell cycle and is required for bipolar spindle assembly, chromosome segregation and checkpoint signaling during mitosis. -

Genome-Wide Screening Identifies Genes and Biological Processes
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 10-12-2018 Genome-Wide Screening Identifies Genes and Biological Processes Implicated in Chemoresistance and Oncogene-Induced Apoptosis Tengyu Ko Louisiana State University and Agricultural and Mechanical College, [email protected] Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Cancer Biology Commons, Cell Biology Commons, and the Genomics Commons Recommended Citation Ko, Tengyu, "Genome-Wide Screening Identifies Genes and Biological Processes Implicated in Chemoresistance and Oncogene- Induced Apoptosis" (2018). LSU Doctoral Dissertations. 4715. https://digitalcommons.lsu.edu/gradschool_dissertations/4715 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. GENOME-WIDE SCREENING IDENTIFIES GENES AND BIOLOGICAL PROCESSES IMPLICATED IN CHEMORESISTANCE AND ONCOGENE- INDUCED APOPTOSIS A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Biomedical and Veterinary Medical Sciences through the Department of Comparative Biomedical Sciences by Tengyu Ko B.S., University of California, Santa Barbara 2010 December 2018 ACKNOWLEDGEMENTS I would like to express my sincerest gratitude to my major supervisor Dr. Shisheng Li for giving me the opportunity to join his team and the freedom to pursue projects. I appreciate all of his thoughts and efforts. Truly, none of these findings would be possible without his supervisions, supports, insightful discussions, and patience. -

Downloaded Per Proteome Cohort Via the Web- Site Links of Table 1, Also Providing Information on the Deposited Spectral Datasets
www.nature.com/scientificreports OPEN Assessment of a complete and classifed platelet proteome from genome‑wide transcripts of human platelets and megakaryocytes covering platelet functions Jingnan Huang1,2*, Frauke Swieringa1,2,9, Fiorella A. Solari2,9, Isabella Provenzale1, Luigi Grassi3, Ilaria De Simone1, Constance C. F. M. J. Baaten1,4, Rachel Cavill5, Albert Sickmann2,6,7,9, Mattia Frontini3,8,9 & Johan W. M. Heemskerk1,9* Novel platelet and megakaryocyte transcriptome analysis allows prediction of the full or theoretical proteome of a representative human platelet. Here, we integrated the established platelet proteomes from six cohorts of healthy subjects, encompassing 5.2 k proteins, with two novel genome‑wide transcriptomes (57.8 k mRNAs). For 14.8 k protein‑coding transcripts, we assigned the proteins to 21 UniProt‑based classes, based on their preferential intracellular localization and presumed function. This classifed transcriptome‑proteome profle of platelets revealed: (i) Absence of 37.2 k genome‑ wide transcripts. (ii) High quantitative similarity of platelet and megakaryocyte transcriptomes (R = 0.75) for 14.8 k protein‑coding genes, but not for 3.8 k RNA genes or 1.9 k pseudogenes (R = 0.43–0.54), suggesting redistribution of mRNAs upon platelet shedding from megakaryocytes. (iii) Copy numbers of 3.5 k proteins that were restricted in size by the corresponding transcript levels (iv) Near complete coverage of identifed proteins in the relevant transcriptome (log2fpkm > 0.20) except for plasma‑derived secretory proteins, pointing to adhesion and uptake of such proteins. (v) Underrepresentation in the identifed proteome of nuclear‑related, membrane and signaling proteins, as well proteins with low‑level transcripts. -

Gene Network Disruptions and Neurogenesis Defects in the Adult Ts1cje Mouse Model of Down Syndrome
Gene Network Disruptions and Neurogenesis Defects in the Adult Ts1Cje Mouse Model of Down Syndrome Chelsee A. Hewitt1,3*, King-Hwa Ling1,4,6, Tobias D. Merson1, Ken M. Simpson1, Matthew E. Ritchie1, Sarah L. King1, Melanie A. Pritchard5, Gordon K. Smyth1, Tim Thomas1,2, Hamish S. Scott1,4*., Anne K. Voss1,2. 1 The Walter and Eliza Hall Institute of Medical Research, Melbourne, Australia, 2 Department of Medical Biology, University of Melbourne, Melbourne, Australia, 3 Department of Pathology, The Peter MacCallum Cancer Centre, Melbourne, Australia, 4 Department of Molecular Pathology, The Centre for Cancer Biology, The Institute of Medical and Veterinary Science and The Hanson Institute, SA Pathology, and The Adelaide Cancer Research Institute, School of Medicine, University of Adelaide, Adelaide, Australia, 5 Department of Biochemistry and Molecular Biology, Monash University, Victoria, Australia, 6 Department of Obstetrics and Gynaecology, Faculty of Medicine and Health Sciences, Universiti Putra Malaysia, Selangor, Malaysia Abstract Background: Down syndrome (DS) individuals suffer mental retardation with further cognitive decline and early onset Alzheimer’s disease. Methodology/Principal Findings: To understand how trisomy 21 causes these neurological abnormalities we investigated changes in gene expression networks combined with a systematic cell lineage analysis of adult neurogenesis using the Ts1Cje mouse model of DS. We demonstrated down regulation of a number of key genes involved in proliferation and cell cycle progression including Mcm7, Brca2, Prim1, Cenpo and Aurka in trisomic neurospheres. We found that trisomy did not affect the number of adult neural stem cells but resulted in reduced numbers of neural progenitors and neuroblasts. Analysis of differentiating adult Ts1Cje neural progenitors showed a severe reduction in numbers of neurons produced with a tendency for less elaborate neurites, whilst the numbers of astrocytes was increased. -

CENPO Expression Regulates Gastric Cancer Cell Proliferation and Is Associated with Poor Patient Prognosis
MOLECULAR MEDICINE REPORTS 20: 3661-3670, 2019 CENPO expression regulates gastric cancer cell proliferation and is associated with poor patient prognosis YI CAO1, JIANBO XIONG1, ZHENGRONG LI1, GUOYANG ZHANG1, YI TU2, LIZHEN WANG2 and ZHIGANG JIE1 Departments of 1Gastrointestinal Surgery and 2Pathology, The First Affiliated Hospital, Nanchang University, Nanchang, Jiangxi 330006, P.R. China Received January 21, 2019; Accepted July 17, 2019 DOI: 10.3892/mmr.2019.10624 Abstract. Gastric cancer (GC) is one of the most common death worldwide (1-3). Due to the progression of GC and high malignancies worldwide; however, understanding of its devel- recurrence rates following surgical resection, GC remains a opment and carcinogenesis is currently limited. Centromere major public health issue. Therefore, elucidating the molecular protein O (CENPO), is a newly discovered constitutive mechanisms underlying GC tumorigenesis is required in order centromeric protein, associated with cell death. The expres- to identify prognostic markers and novel effective treatments. sion of CENPO in human cancers, including GC, is currently Previous studies have demonstrated that the normal expres- unknown. The aim of the present study was to investigate the sion of centromere proteins is essential for mitosis (4) and clinical association between CENPO and GC, and to eluci- abnormal core centromere proteins may increase the incidence date the potential mechanisms of CENPO in the process of of chromosomal instability, aneuploidy, and lead to oncogen- GC progression. The results demonstrated that CENPO was esis (5,6). In a previous study, >40 proteins were identified expressed at high levels in GC and was correlated with p-TNM in the interphase centromere complex (ICEN) by proteomic stage.