Nucleotide Sequence and Analysis of the 58.3 to 65.5-Kb Early Region of Bacteriophage T4
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Electrophoretic Variation in Adenylate Kinase Ofneisseria
Proc. Natl. Acad. Sci. USA Vol. 92, pp. 10535-10539, November 1995 Genetics Electrophoretic variation in adenylate kinase of Neisseria meningitidis is due to inter- and intraspecies recombination (natural transformation/linkage disequilibrium/mosaic genes/multilocus enzyme electrophoresis/nonclonal population structure) EDWARD FEIL, GILL CARPENTER, AND BRIAN G. SPRATT* Molecular Microbiology Group, School of Biological Sciences, University of Sussex, Falmer, Brighton BN1 9QG, United Kingdom Communicated by John Maynard Smith, University of Sussex, Falmer, Brighton, United Kingdom, August 7, 1995 ABSTRACT In prokaryotic and eukaryotic organisms, their growth cycles and the availability of this mechanism of the electrophoretic variation in housekeeping enzymes from genetic exchange appears to have a profound effect on their natural populations is assumed to have arisen by the accu- evolution and population biology (3, 13-17). mulation of stochastic predominantly neutral mutations. In Caugant et al. (18) carried out an extensive MLEE survey of the naturally transformable bacterium Neisseria meningitidis, meningococci, analyzing variation at 15 enzyme loci in 688 we show that variation in the electrophoretic mobility of isolates recovered predominantly from patients with invasive adenylate kinase is due to inter- and intraspecies recombina- disease. Although the results from this survey appeared to tion rather than mutation. The nucleotide sequences of the imply relatively high levels of linkage disequilibrium, it has adenylate kinase gene (adk) from isolates that express the been pointed out (3, 17) that artificially high levels of linkage predominant slow electrophoretic variant were rather uni- disequilibrium may result from sampling bias, in this case form, differing in sequence at an average of 1.1% of nucleotide through the disproportionately high frequency in the data set sites. -

B Number Gene Name Mrna Intensity Mrna
sample) total list predicted B number Gene name assignment mRNA present mRNA intensity Gene description Protein detected - Membrane protein membrane sample detected (total list) Proteins detected - Functional category # of tryptic peptides # of tryptic peptides # of tryptic peptides detected (membrane b0002 thrA 13624 P 39 P 18 P(m) 2 aspartokinase I, homoserine dehydrogenase I Metabolism of small molecules b0003 thrB 6781 P 9 P 3 0 homoserine kinase Metabolism of small molecules b0004 thrC 15039 P 18 P 10 0 threonine synthase Metabolism of small molecules b0008 talB 20561 P 20 P 13 0 transaldolase B Metabolism of small molecules chaperone Hsp70; DNA biosynthesis; autoregulated heat shock b0014 dnaK 13283 P 32 P 23 0 proteins Cell processes b0015 dnaJ 4492 P 13 P 4 P(m) 1 chaperone with DnaK; heat shock protein Cell processes b0029 lytB 1331 P 16 P 2 0 control of stringent response; involved in penicillin tolerance Global functions b0032 carA 9312 P 14 P 8 0 carbamoyl-phosphate synthetase, glutamine (small) subunit Metabolism of small molecules b0033 carB 7656 P 48 P 17 0 carbamoyl-phosphate synthase large subunit Metabolism of small molecules b0048 folA 1588 P 7 P 1 0 dihydrofolate reductase type I; trimethoprim resistance Metabolism of small molecules peptidyl-prolyl cis-trans isomerase (PPIase), involved in maturation of b0053 surA 3825 P 19 P 4 P(m) 1 GenProt outer membrane proteins (1st module) Cell processes b0054 imp 2737 P 42 P 5 P(m) 5 GenProt organic solvent tolerance Cell processes b0071 leuD 4770 P 10 P 9 0 isopropylmalate -

The Microbiota-Produced N-Formyl Peptide Fmlf Promotes Obesity-Induced Glucose
Page 1 of 230 Diabetes Title: The microbiota-produced N-formyl peptide fMLF promotes obesity-induced glucose intolerance Joshua Wollam1, Matthew Riopel1, Yong-Jiang Xu1,2, Andrew M. F. Johnson1, Jachelle M. Ofrecio1, Wei Ying1, Dalila El Ouarrat1, Luisa S. Chan3, Andrew W. Han3, Nadir A. Mahmood3, Caitlin N. Ryan3, Yun Sok Lee1, Jeramie D. Watrous1,2, Mahendra D. Chordia4, Dongfeng Pan4, Mohit Jain1,2, Jerrold M. Olefsky1 * Affiliations: 1 Division of Endocrinology & Metabolism, Department of Medicine, University of California, San Diego, La Jolla, California, USA. 2 Department of Pharmacology, University of California, San Diego, La Jolla, California, USA. 3 Second Genome, Inc., South San Francisco, California, USA. 4 Department of Radiology and Medical Imaging, University of Virginia, Charlottesville, VA, USA. * Correspondence to: 858-534-2230, [email protected] Word Count: 4749 Figures: 6 Supplemental Figures: 11 Supplemental Tables: 5 1 Diabetes Publish Ahead of Print, published online April 22, 2019 Diabetes Page 2 of 230 ABSTRACT The composition of the gastrointestinal (GI) microbiota and associated metabolites changes dramatically with diet and the development of obesity. Although many correlations have been described, specific mechanistic links between these changes and glucose homeostasis remain to be defined. Here we show that blood and intestinal levels of the microbiota-produced N-formyl peptide, formyl-methionyl-leucyl-phenylalanine (fMLF), are elevated in high fat diet (HFD)- induced obese mice. Genetic or pharmacological inhibition of the N-formyl peptide receptor Fpr1 leads to increased insulin levels and improved glucose tolerance, dependent upon glucagon- like peptide-1 (GLP-1). Obese Fpr1-knockout (Fpr1-KO) mice also display an altered microbiome, exemplifying the dynamic relationship between host metabolism and microbiota. -

Blueprint Genetics ADK Single Gene Test
ADK single gene test Test code: S02595 Phenotype information Hypermethioninemia due to adenosine kinase deficiency Alternative gene names AK Panels that include the ADK gene Comprehensive Metabolism Panel Organic Acidemia/Aciduria & Cobalamin Deficiency Panel Test Strengths The strengths of this test include: CAP accredited laboratory CLIA-certified personnel performing clinical testing in a CLIA-certified laboratory Powerful sequencing technologies, advanced target enrichment methods and precision bioinformatics pipelines ensure superior analytical performance Careful construction of clinically effective and scientifically justified gene panels Our Nucleus online portal providing transparent and easy access to quality and performance data at the patient level Our publicly available analytic validation demonstrating complete details of test performance ~2,000 non-coding disease causing variants in our clinical grade NGS assay for panels (please see ‘Non-coding disease causing variants covered by this test’) Our rigorous variant classification scheme Our systematic clinical interpretation workflow using proprietary software enabling accurate and traceable processing of NGS data Our comprehensive clinical statements Test Limitations This test does not detect the following: Complex inversions Gene conversions Balanced translocations Mitochondrial DNA variants Repeat expansion disorders unless specifically mentioned Non-coding variants deeper than ±20 base pairs from exon-intron boundary unless otherwise indicated (please see above non-coding variants covered by the test). This test may not reliably detect the following: Low level mosaicism (variant with a minor allele fraction of 14.6% is detected with 90% probability) Stretches of mononucleotide repeats Indels larger than 50bp Single exon deletions or duplications https://blueprintgenetics.com/ Variants within pseudogene regions/duplicated segments The sensitivity of this test may be reduced if DNA is extracted by a laboratory other than Blueprint Genetics. -
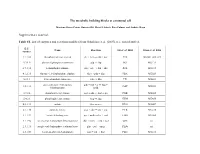
The Metabolic Building Blocks of a Minimal Cell Supplementary
The metabolic building blocks of a minimal cell Mariana Reyes-Prieto, Rosario Gil, Mercè Llabrés, Pere Palmer and Andrés Moya Supplementary material. Table S1. List of enzymes and reactions modified from Gabaldon et. al. (2007). n.i.: non identified. E.C. Name Reaction Gil et. al. 2004 Glass et. al. 2006 number 2.7.1.69 phosphotransferase system glc + pep → g6p + pyr PTS MG041, 069, 429 5.3.1.9 glucose-6-phosphate isomerase g6p ↔ f6p PGI MG111 2.7.1.11 6-phosphofructokinase f6p + atp → fbp + adp PFK MG215 4.1.2.13 fructose-1,6-bisphosphate aldolase fbp ↔ gdp + dhp FBA MG023 5.3.1.1 triose-phosphate isomerase gdp ↔ dhp TPI MG431 glyceraldehyde-3-phosphate gdp + nad + p ↔ bpg + 1.2.1.12 GAP MG301 dehydrogenase nadh 2.7.2.3 phosphoglycerate kinase bpg + adp ↔ 3pg + atp PGK MG300 5.4.2.1 phosphoglycerate mutase 3pg ↔ 2pg GPM MG430 4.2.1.11 enolase 2pg ↔ pep ENO MG407 2.7.1.40 pyruvate kinase pep + adp → pyr + atp PYK MG216 1.1.1.27 lactate dehydrogenase pyr + nadh ↔ lac + nad LDH MG460 1.1.1.94 sn-glycerol-3-phosphate dehydrogenase dhp + nadh → g3p + nad GPS n.i. 2.3.1.15 sn-glycerol-3-phosphate acyltransferase g3p + pal → mag PLSb n.i. 2.3.1.51 1-acyl-sn-glycerol-3-phosphate mag + pal → dag PLSc MG212 acyltransferase 2.7.7.41 phosphatidate cytidyltransferase dag + ctp → cdp-dag + pp CDS MG437 cdp-dag + ser → pser + 2.7.8.8 phosphatidylserine synthase PSS n.i. cmp 4.1.1.65 phosphatidylserine decarboxylase pser → peta PSD n.i. -

The Target Landscape of N4-Hydroxycytidine Based on Its Chemical Neighborhood Jordi Mestres*
bioRxiv preprint doi: https://doi.org/10.1101/2020.03.30.016485; this version posted April 1, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. The target landscape of N4-hydroxycytidine based on its chemical neighborhood Jordi Mestres* Research Group on Systems Pharmacology, Research Program on Biomedical Informatics (GRIB), IMIM Hospital del Mar Medical Research Institute and University Pompeu Fabra, Parc de Recerca Biomedica (PRBB), Doctor Aiguader 88, 08003 Barcelona, Catalonia, Spain; and Chemotargets SL, Parc Cientific de Barcelona (PCB), Baldiri Reixac 4, 08028 Barcelona, Catalonia, Spain Abstract N4-hydroxycytidine (NHC) has been recently reported to have promising antiviral activity against SARS-CoV-2. To join worldwide efforts in identifying potential drug targets against this pandemic, the target landscape of NHC was defined by extracting all known targets of its chemical neighborhood, including drugs, analogues, and metabolites, and by performing target predictions from two independent platforms, following the recent Public Health Assessment via Structural Evaluation (PHASE) protocol. The analysis provides a list of over 30 protein targets that could be useful in future design activities of new COVID-19 antivirals. The relevance for existing drugs within the same chemical space, such as remdesivir, is also discussed. * Email: [email protected] bioRxiv preprint doi: https://doi.org/10.1101/2020.03.30.016485; this version posted April 1, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -

NIPRO Enzymes
Thermostable Enzymes for Clinical Chemistry NIPRO Enzymes From Zymomonas mobilis ALCOHOL DEHYDROGENASE (ZM-ADH) GLUCOKINASE (ZM-GlcK) GLUCOSE-6-PHOSPHATE DEHYDROGENASE (ZM-G6PDH) From Bacillus stearothermophilus ACETATE KINASE (AK) ADENYLATE KINASE (AdK) ALANINE DEHYDROGENASE (AlaDH) ALANINE RACEMASE (AlaR) DIAPHORASE Ⅰ [EC 1.6.99.-] (Di-1) GLUCOKINASE (GlcK) α-GLUCOSIDASE (α-Glu) LEUCINE DEHYDROGENASE (LeuDH) PHOSPHOFRUCTOKINASE (PFK) PHOSPHOGLUCOSE ISOMERASE (PGI) PHOSPHOTRANSACETYLASE (PTA) POLYNUCLEOTIDE PHOSPHORYLASE (PNPase) PYRUVATE KINASE (PK) SUPEROXIDE DISMUTASE (SOD) From Others DIAPHORASE22 (Di-22) GALACTOSE DEHYDROGENASE (GalDH) GLUCOKINASE2 (GlcK2) GLUCOSE DEHYDROGENASE (GlcDH2) D-LACTATE DEHYDROGENASE (D-LDH) MALATE DEHYDROGENASE (MDH) MUTAROTASE (MRO) PHENYLALANINE DEHYDROGENASE (PheDH) 6-PHOSPHOGLUCONATE DEHYDROGENASE (6PGDH) SORBITOL DEHYDROGENASE (SorDH) ご照会は下記へお願い申し上げます。 For more information, please contact ニプロ株式会社 NIPRO CORPORATION 本 社/〒531-8510 大阪市北区本庄西3丁目9番3号 3-9-3,Honjo-Nishi,Kita-ku Tel (06)6373-3168 Osaka 531-8510 Japan Phone +81 6 6373 3168 e-mail : [email protected] Fax +81 6 6373 8978 http://www.nipro.co.jp/ja/ Bacillus stearothermophilus is used as a synonym of Geobacillus stearothermophilus . 2016.04 Quality The Quality Management System of Uji Factory, NIPRO Corp. has been certified as to meet the requirements of ISO9001 in the scope of The Development and Production of Enzymes for Analytical Reagents and Industrial Use by JAPAN CHEMICAL QUALITY ASSURANCE LTD. ISO9001 ニプロ株式会社 国内事業部 宇治工場 NIPRO ENZYMES ALCOHOL DEHYDROGENASE (ZM-ADH) [EC 1 .1 .1 .1] from Zymomonas mobilis Alcohol + NAD+ ↔ Aldehyde + NADH + H+ SPECIFICATION State : Lyophilized Specific activity : more than 400 U/mg protein Contaminants : (as ZM-ADH activity = 100 %) Glucose-6-phosphate dehydrogenase < 0.10 % Glucokinase < 0.02 % Pyruvate kinase < 0.02 % NADH oxidase < 0.01 % Lactate dehydrogenase < 0.01 % PROPERTIES Molecular weight : ca. -

Dynamic Epigenetic Regulation of Glioblastoma Tumorigenicity Through
Dynamic epigenetic regulation of glioblastoma PNAS PLUS tumorigenicity through LSD1 modulation of MYC expression David Kozonoa,1, Jie Lib,1, Masayuki Nittaa, Oltea Sampetreanc, David Gondab, Deepa S. Kushwahaa, Dmitry Merzona, Valya Ramakrishnanb, Shan Zhua, Kaya Zhua, Hiroko Matsuid, Olivier Harismendyd, Wei Huae, Ying Maoe, Chang-Hyuk Kwonf, Hideyuki Sayac, Ichiro Nakanof, Donald P. Pizzog, Scott R. VandenBergg, and Clark C. Chenb,2 aDepartment of Radiation Oncology, Dana-Farber Cancer Institute, Boston, MA 02215; bDivision of Neurosurgery, University of California, San Diego, La Jolla, CA 92093; cDivision of Gene Regulation, Keio University School of Medicine, Tokyo 160-8582, Japan; dDepartment of Pediatrics and Rady Children’s Hospital, University of California, San Diego, La Jolla, CA 92093; eDepartment of Neurosurgery, Huashan Hospital, Fudan University, Shanghai 200040, China; fDepartment of Neurological Surgery, Ohio State University Medical Center, Columbus, OH 43210; and gDepartment of Pathology, University of California, San Diego, La Jolla, CA 92037 Edited by William A Weiss, University of California, San Francisco, CA, and accepted by the Editorial Board June 15, 2015 (received for review January 29, 2015) The available evidence suggests that the lethality of glioblastoma is glioblastoma cells into a stem-like state, including avian myelo- driven by small subpopulations of cells that self-renew and exhibit cytomatosis viral oncogene homolog (MYC) (11), oligodendrocyte tumorigenicity. It remains unclear whether tumorigenicity exists as lineage transcription factor 2 (OLIG2), SRY (sex determining a static property of a few cells or as a dynamically acquired prop- region Y)-box 2 (SOX2), and POU class 3 homeobox 2 (POU3F2) erty. We used tumor-sphere and xenograft formation as assays for (12). -

PRODUCTS and SERVICES Target List
PRODUCTS AND SERVICES Target list Kinase Products P.1-11 Kinase Products Biochemical Assays P.12 "QuickScout Screening Assist™ Kits" Kinase Protein Assay Kits P.13 "QuickScout Custom Profiling & Panel Profiling Series" Targets P.14 "QuickScout Custom Profiling Series" Preincubation Targets Cell-Based Assays P.15 NanoBRET™ TE Intracellular Kinase Cell-Based Assay Service Targets P.16 Tyrosine Kinase Ba/F3 Cell-Based Assay Service Targets P.17 Kinase HEK293 Cell-Based Assay Service ~ClariCELL™ ~ Targets P.18 Detection of Protein-Protein Interactions ~ProbeX™~ Stable Cell Lines Crystallization Services P.19 FastLane™ Structures ~Premium~ P.20-21 FastLane™ Structures ~Standard~ Kinase Products For details of products, please see "PRODUCTS AND SERVICES" on page 1~3. Tyrosine Kinases Note: Please contact us for availability or further information. Information may be changed without notice. Expression Protein Kinase Tag Carna Product Name Catalog No. Construct Sequence Accession Number Tag Location System HIS ABL(ABL1) 08-001 Full-length 2-1130 NP_005148.2 N-terminal His Insect (sf21) ABL(ABL1) BTN BTN-ABL(ABL1) 08-401-20N Full-length 2-1130 NP_005148.2 N-terminal DYKDDDDK Insect (sf21) ABL(ABL1) [E255K] HIS ABL(ABL1)[E255K] 08-094 Full-length 2-1130 NP_005148.2 N-terminal His Insect (sf21) HIS ABL(ABL1)[T315I] 08-093 Full-length 2-1130 NP_005148.2 N-terminal His Insect (sf21) ABL(ABL1) [T315I] BTN BTN-ABL(ABL1)[T315I] 08-493-20N Full-length 2-1130 NP_005148.2 N-terminal DYKDDDDK Insect (sf21) ACK(TNK2) GST ACK(TNK2) 08-196 Catalytic domain -

Adenosine Kinase Inhibition Selectively Promotes Rodent and Porcine Islet Β-Cell Replication
Adenosine kinase inhibition selectively promotes rodent and porcine islet β-cell replication Justin P. Annesa,b, Jennifer Hyoje Ryua, Kelvin Lama, Peter J. Carolana,c, Katrina Utza, Jennifer Hollister-Lockd, Anthony C. Arvanitesa, Lee L. Rubina, Gordon Weird, and Douglas A. Meltona,e,1 aDepartment of Stem Cell and Regenerative Biology, Harvard Stem Cell Institute, Cambridge, MA 02138; bDivision of Genetics, Department of Medicine, Brigham and Women’s Hospital and Harvard Medical School, Boston, MA 02115; cDivision of Gastroenterology, Department of Medicine, Massachusetts General Hospital, Boston, MA 02114; dSection of Islet Cell and Regenerative Biology, Joslin Diabetes Center, Department of Medicine, Harvard Medical School, Boston, MA 02115; and eHoward Hughes Medical Institute, Harvard University, Cambridge, MA 02138 Contributed by Douglas A. Melton, January 21, 2012 (sent for review October 1, 2011) Diabetes is a pathological condition characterized by relative insulin with the intent of finding compounds for the treatment of T2DM deficiency, persistent hyperglycemia, and, consequently, diffuse (27). Unfortunately, this study did not identify compounds with micro- and macrovascular disease. One therapeutic strategy is to β-cell-selective replication-promoting activity. Therefore, it is likely amplify insulin-secretion capacity by increasing the number of the that these molecular targets have an unacceptable risk profile for insulin-producing β cells without triggering a generalized prolifera- use in vivo. One explanation for why only nonspecific mitogenic tive response. Here, we present the development of a small-molecule compounds were found is that the screen was performed on a re- screening platform for the identification of molecules that increase versibly transformed cell line that may no longer retain metabolic β characteristics of primary β cells. -

Page 1 Exploring the Understudied Human Kinome For
bioRxiv preprint doi: https://doi.org/10.1101/2020.04.02.022277; this version posted June 30, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Exploring the understudied human kinome for research and therapeutic opportunities Nienke Moret1,2,*, Changchang Liu1,2,*, Benjamin M. Gyori2, John A. Bachman,2, Albert Steppi2, Rahil Taujale3, Liang-Chin Huang3, Clemens Hug2, Matt Berginski1,4,5, Shawn Gomez1,4,5, Natarajan Kannan,1,3 and Peter K. Sorger1,2,† *These authors contributed equally † Corresponding author 1The NIH Understudied Kinome Consortium 2Laboratory of Systems Pharmacology, Department of Systems Biology, Harvard Program in Therapeutic Science, Harvard Medical School, Boston, Massachusetts 02115, USA 3 Institute of Bioinformatics, University of Georgia, Athens, GA, 30602 USA 4 Department of Pharmacology, The University of North Carolina at Chapel Hill, Chapel Hill, NC 27599, USA 5 Joint Department of Biomedical Engineering at the University of North Carolina at Chapel Hill and North Carolina State University, Chapel Hill, NC 27599, USA Key Words: kinase, human kinome, kinase inhibitors, drug discovery, cancer, cheminformatics, † Peter Sorger Warren Alpert 432 200 Longwood Avenue Harvard Medical School, Boston MA 02115 [email protected] cc: [email protected] 617-432-6901 ORCID Numbers Peter K. Sorger 0000-0002-3364-1838 Nienke Moret 0000-0001-6038-6863 Changchang Liu 0000-0003-4594-4577 Ben Gyori 0000-0001-9439-5346 John Bachman 0000-0001-6095-2466 Albert Steppi 0000-0001-5871-6245 Page 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.04.02.022277; this version posted June 30, 2020.