The Wili Benchmark Dataset for Written Natural Language Identification
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

From Arabic Style Toward Javanese Style: Comparison Between Accents of Javanese Recitation and Arabic Recitation
From Arabic Style toward Javanese Style: Comparison between Accents of Javanese Recitation and Arabic Recitation Nur Faizin1 Abstract Moslem scholars have acceptedmaqamat in reciting the Quran otherwise they have not accepted macapat as Javanese style in reciting the Quran such as recitationin the State Palace in commemoration of Isra` Miraj 2015. The paper uses a phonological approach to accents in Arabic and Javanese style in recitingthe first verse of Surah Al-Isra`. Themethod used here is analysis of suprasegmental sound (accent) by usingSpeech Analyzer programand the comparison of these accents is analyzed by descriptive method. By doing so, the author found that:first, there is not any ideological reason to reject Javanese style because both of Arabic and Javanese style have some aspects suitable and unsuitable with Ilm Tajweed; second, the suitability of Arabic style was muchthan Javanese style; third, it is not right to reject recitingthe Quran with Javanese style only based on assumption that it evokedmistakes and errors; fourth, the acceptance of Arabic style as the art in reciting the Quran should risedacceptanceof the Javanese stylealso. So, rejection of reciting the Quranwith Javanese style wasnot due to any reason and it couldnot be proofed by any logical argument. Keywords: Recitation, Arabic Style, Javanese Style, Quran. Introduction There was a controversial event in commemoration of Isra‘ Mi‘raj at the State Palacein Jakarta May 15, 2015 ago. The recitation of the Quran in the commemoration was recitedwithJavanese style (langgam).That was not common performance in relation to such as official event. Muhammad 58 Nur Faizin, From Arabic Style toward Javanese Style Yasser Arafat, a lecture of Sunan Kalijaga State Islamic University Yogyakarta has been reciting first verse of Al-Isra` by Javanese style in the front of state officials and delegationsof many countries. -

A COMPARATIVE STUDY of ENGLISH and KURDISH CONNECTIVES in NEWSPAPER OPINION ARTICLES Thesis Submitted for the Degree of Doctor
A COMPARATIVE STUDY OF ENGLISH AND KURDISH CONNECTIVES IN NEWSPAPER OPINION ARTICLES Thesis submitted for the degree of Doctor of Philosophy at the University of Leicester by Rashwan Ramadan Salih BA, MA School of English University of Leicester 2014 A comparative study of English and Kurdish connectives in newspaper opinion articles Abstract This thesis is a comparative study that investigates English and Kurdish connectives which signal conjunctive relations in online newspaper opinion articles. This study utilises the Hallidayan framework of connectives in light of the principles of Relevance Theory established by Sperber and Wilson (1995). That is, connectives are considered in terms of their procedural meanings; i.e. the different interpretations they signal within different contexts, rather than their conceptual meanings. It finds that Halliday and Hasan’s (1976) classification of conjunctive relations and connectives needs to be modified, in order to lay out a clearer classification of English connectives that could account for their essential characteristics and properties. This modified classification would also help classify Kurdish connectives with greater accuracy. The comparison between connectives from both languages is examined through the use of translation techniques such as creating paradigms of correspondence between the equivalent connectives from both languages (Aijmer et al, 2006). Relevance Theoretic framework shows that any given text consists of two segments (S1 and S2), and these segments are constrained by different elements according to the four sub-categories of conjunctive relations. Different characteristics of connectives are considered in relation to the different subcategories of the Hallidayan framework of the conjunctive relations as follows: additive: the semantic content of the segments S1 and S2; adversative: the polysemy of the connectives; causal-conditional: iconicity in the order of the segments and temporal: the time scenes in the segments S1 and S2 The thesis comprises eight chapters. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
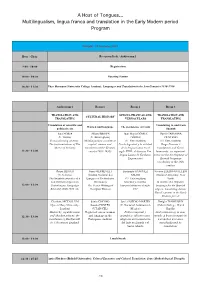
Program Hot FINAL
A Host of Tongues… Multilingualism, lingua franca and translation in the Early Modern period Program Thursday, 13 December 2018 Hour / Chair Reception Desk / Auditorium 1 9:00 - 10:00 Registration 10:00 - 10:30 Opening Session 10:30 - 11:30 Theo Hermans (UniVersity College London): Languages and Translation in the Low Countries 1550-1700 Auditorium 1 Room 1 Room 2 Room 3 TRANSLATION AND LINGUA FRANCAS AND TRANSLATION AND CULTURAL HISTORY TRANSLATING VERNACULARS TRANSLATING Translation of scientific and Translating to and from Women and language The persistence of Latin political texts Spanish Sara NORJA Hilary BROWN Juan María GÓMEZ DaviD CARMONA (U. Turku) (U. Birmingham) GÓMEZ CENTENO Vernacularising alchemy: Multilingualism as cultural (U. ExtremaDura) (U. ExtremaDura) The (re)translations of The capital: women and Por la dignidad y la utilidad Diego Gracián’s Mirror of Alchemy translation at the German de la lengua latina en el translations and Greek 11:30 - 12:00 courts (1600-1635) siglo XVIII: el discurso Pro loanwords: an important lingua Latina de Girolamo factor for the development of Lagomarsini Spanish language vocabulary in the 16th century Chiara BENATI Nana METREVELI Eustaquio SÁNCHEZ Vicente LLEDÓ-GUILLEM (U. Genova) (Institut National Des SALOR (Hofstra University, New The linguistic practice of a Langues et Civilisations (U. ExtremaDura) York) Low German surgeon in Orientales) Sanctius y el sermo In search of a Hispanic 12:00 - 12:30 Copenhagen, Kongelige The Secret Writing of hispanolatinus en el siglo language for the Spanish Bibliotek, GKS 1663 4to Georgian Women XVI empire: translating Ausiàs March’s poems in the Early Modern period Charlotte MCCALLUM Sónia COELHO Javier ESPINO MARTÍN Dwight TENHUISEN (Queen Mary University, Susana FONTES (U. -

Unicode Request for Cyrillic Modifier Letters Superscript Modifiers
Unicode request for Cyrillic modifier letters L2/21-107 Kirk Miller, [email protected] 2021 June 07 This is a request for spacing superscript and subscript Cyrillic characters. It has been favorably reviewed by Sebastian Kempgen (University of Bamberg) and others at the Commission for Computer Supported Processing of Medieval Slavonic Manuscripts and Early Printed Books. Cyrillic-based phonetic transcription uses superscript modifier letters in a manner analogous to the IPA. This convention is widespread, found in both academic publication and standard dictionaries. Transcription of pronunciations into Cyrillic is the norm for monolingual dictionaries, and Cyrillic rather than IPA is often found in linguistic descriptions as well, as seen in the illustrations below for Slavic dialectology, Yugur (Yellow Uyghur) and Evenki. The Great Russian Encyclopedia states that Cyrillic notation is more common in Russian studies than is IPA (‘Transkripcija’, Bol’šaja rossijskaja ènciplopedija, Russian Ministry of Culture, 2005–2019). Unicode currently encodes only three modifier Cyrillic letters: U+A69C ⟨ꚜ⟩ and U+A69D ⟨ꚝ⟩, intended for descriptions of Baltic languages in Latin script but ubiquitous for Slavic languages in Cyrillic script, and U+1D78 ⟨ᵸ⟩, used for nasalized vowels, for example in descriptions of Chechen. The requested spacing modifier letters cannot be substituted by the encoded combining diacritics because (a) some authors contrast them, and (b) they themselves need to be able to take combining diacritics, including diacritics that go under the modifier letter, as in ⟨ᶟ̭̈⟩BA . (See next section and e.g. Figure 18. ) In addition, some linguists make a distinction between spacing superscript letters, used for phonetic detail as in the IPA tradition, and spacing subscript letters, used to denote phonological concepts such as archiphonemes. -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

A Bavarian-Speaking Exception in Alemannic-Speaking Switzerland: the Case of Samnaun 48 Located
47 A Bavarian -speaking 1. Introduction1 data2 is missing, as the study by Gröger is the Exception in Alemannic- only detailed linguistic description of the speaking Switzerland: he municipality of Samnaun, situated German dialect in Samnaun. in the extreme east of Switzerland, In this paper, I present a new research The Case of Samnaun project which seeks to fill this gap. The T stands out from the rest of German- speaking Switzerland: Samnaun is usually project is dedicated to the current linguistic A Project Presentation described as the only place where not an situation in Samnaun. Its working title is Alemannic, but a Bavarian dialect is spoken Bairisch-alemannischer Sprachkontakt. Das Journal Article (cf., e.g., Sonderegger 2003: 2839; Wiesinger Spektrum der sprachlichen Variation in Susanne Oberholzer 1983: 817). This claim is based on a study by Samnaun (‘Bavarian-Alemannic Language Gröger (1924) and has found its way into Contact. The Range of Linguistic Variation in Samnaun has been described as the only Samnaun’). This paper describes Samnaun Bavarian-speaking municipality in Ale- many linguistic descriptions of (German- mannic-speaking Switzerland on the basis speaking) Switzerland. In the literature, this and summarises the available descriptions of of a study done in 1924. Hints in the viewpoint has been almost unchallenged for its language situation as well as the aims, literature about the presence of other over 90 years. Hints about the presence of research questions, and methods of the varieties for everyday communication – an other varieties (an Alemannic dialect as well planned project. intermediate variety on the dialect- In section 2, I sketch the municipality of standard -axis as well as an Alemannic as an intermediate variety on the dialect- dialect – have not resulted in more recent standard-axis) from the second half of the Samnaun. -

Prayer Cards (709)
Pray for the Nations Pray for the Nations A Che in China A'ou in China Population: 43,000 Population: 2,800 World Popl: 43,000 World Popl: 2,800 Total Countries: 1 Total Countries: 1 People Cluster: Tibeto-Burman, other People Cluster: Tai Main Language: Ache Main Language: Chinese, Mandarin Main Religion: Ethnic Religions Main Religion: Ethnic Religions Status: Unreached Status: Unreached Evangelicals: 0.00% Evangelicals: 0.00% Chr Adherents: 0.00% Chr Adherents: 0.00% Scripture: Translation Needed Scripture: Complete Bible www.joshuaproject.net Source: Operation China, Asia Harvest www.joshuaproject.net Source: Operation China, Asia Harvest "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations A-Hmao in China Achang in China Population: 458,000 Population: 35,000 World Popl: 458,000 World Popl: 74,000 Total Countries: 1 Total Countries: 2 People Cluster: Miao / Hmong People Cluster: Tibeto-Burman, other Main Language: Miao, Large Flowery Main Language: Achang Main Religion: Christianity Main Religion: Ethnic Religions Status: Significantly reached Status: Partially reached Evangelicals: 75.0% Evangelicals: 7.0% Chr Adherents: 80.0% Chr Adherents: 7.0% Scripture: Complete Bible Scripture: Complete Bible www.joshuaproject.net www.joshuaproject.net Source: Anonymous Source: Wikipedia "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations Achang, Husa in China Adi -

M. Ricklefs an Inventory of the Javanese Manuscript Collection in the British Museum
M. Ricklefs An inventory of the Javanese manuscript collection in the British Museum In: Bijdragen tot de Taal-, Land- en Volkenkunde 125 (1969), no: 2, Leiden, 241-262 This PDF-file was downloaded from http://www.kitlv-journals.nl Downloaded from Brill.com09/29/2021 11:29:04AM via free access AN INVENTORY OF THE JAVANESE MANUSCRIPT COLLECTION IN THE BRITISH MUSEUM* he collection of Javanese manuscripts in the British Museum, London, although small by comparison with collections in THolland and Indonesia, is nevertheless of considerable importance. The Crawfurd collection, forming the bulk of the manuscripts, provides a picture of the types of literature being written in Central Java in the late eighteenth and early nineteenth centuries, a period which Dr. Pigeaud has described as a Literary Renaissance.1 Because they were acquired by John Crawfurd during his residence as an official of the British administration on Java, 1811-1815, these manuscripts have a convenient terminus ad quem with regard to composition. A large number of the items are dated, a further convenience to the research worker, and the dates are seen to cluster in the four decades between AD 1775 and AD 1815. A number of the texts were originally obtained from Pakualam I, who was installed as an independent Prince by the British admini- stration. Some of the manuscripts are specifically said to have come from him (e.g. Add. 12281 and 12337), and a statement in a Leiden University Bah ad from the Pakualaman suggests many other volumes in Crawfurd's collection also derive from this source: Tuwan Mister [Crawfurd] asked to be instructed in adat law, with examples of the Javanese usage. -

Wikipedia, the Free Encyclopedia 03-11-09 12:04
Tea - Wikipedia, the free encyclopedia 03-11-09 12:04 Tea From Wikipedia, the free encyclopedia Tea is the agricultural product of the leaves, leaf buds, and internodes of the Camellia sinensis plant, prepared and cured by various methods. "Tea" also refers to the aromatic beverage prepared from the cured leaves by combination with hot or boiling water,[1] and is the common name for the Camellia sinensis plant itself. After water, tea is the most widely-consumed beverage in the world.[2] It has a cooling, slightly bitter, astringent flavour which many enjoy.[3] The four types of tea most commonly found on the market are black tea, oolong tea, green tea and white tea,[4] all of which can be made from the same bushes, processed differently, and in the case of fine white tea grown differently. Pu-erh tea, a post-fermented tea, is also often classified as amongst the most popular types of tea.[5] Green Tea leaves in a Chinese The term "herbal tea" usually refers to an infusion or tisane of gaiwan. leaves, flowers, fruit, herbs or other plant material that contains no Camellia sinensis.[6] The term "red tea" either refers to an infusion made from the South African rooibos plant, also containing no Camellia sinensis, or, in Chinese, Korean, Japanese and other East Asian languages, refers to black tea. Contents 1 Traditional Chinese Tea Cultivation and Technologies 2 Processing and classification A tea bush. 3 Blending and additives 4 Content 5 Origin and history 5.1 Origin myths 5.2 China 5.3 Japan 5.4 Korea 5.5 Taiwan 5.6 Thailand 5.7 Vietnam 5.8 Tea spreads to the world 5.9 United Kingdom Plantation workers picking tea in 5.10 United States of America Tanzania. -

The Culture of Wikipedia
Good Faith Collaboration: The Culture of Wikipedia Good Faith Collaboration The Culture of Wikipedia Joseph Michael Reagle Jr. Foreword by Lawrence Lessig The MIT Press, Cambridge, MA. Web edition, Copyright © 2011 by Joseph Michael Reagle Jr. CC-NC-SA 3.0 Purchase at Amazon.com | Barnes and Noble | IndieBound | MIT Press Wikipedia's style of collaborative production has been lauded, lambasted, and satirized. Despite unease over its implications for the character (and quality) of knowledge, Wikipedia has brought us closer than ever to a realization of the centuries-old Author Bio & Research Blog pursuit of a universal encyclopedia. Good Faith Collaboration: The Culture of Wikipedia is a rich ethnographic portrayal of Wikipedia's historical roots, collaborative culture, and much debated legacy. Foreword Preface to the Web Edition Praise for Good Faith Collaboration Preface Extended Table of Contents "Reagle offers a compelling case that Wikipedia's most fascinating and unprecedented aspect isn't the encyclopedia itself — rather, it's the collaborative culture that underpins it: brawling, self-reflexive, funny, serious, and full-tilt committed to the 1. Nazis and Norms project, even if it means setting aside personal differences. Reagle's position as a scholar and a member of the community 2. The Pursuit of the Universal makes him uniquely situated to describe this culture." —Cory Doctorow , Boing Boing Encyclopedia "Reagle provides ample data regarding the everyday practices and cultural norms of the community which collaborates to 3. Good Faith Collaboration produce Wikipedia. His rich research and nuanced appreciation of the complexities of cultural digital media research are 4. The Puzzle of Openness well presented. -

Orthography of Solomon Birnbaum
iQa;;&u*,"" , I iii The "Orthodox" Orthography of Solomon Birnbaum Kalman Weiser YORK UNIVERSITY Apart from the YIVO Institute's Standard Yiddish Orthography, the prevalent sys tem in the secular sector, two other major spelling codes for Yiddish are current today. Sovetisher oysteyg (Soviet spelling) is encountered chiefly among aging Yid dish speakers from the former Soviet bloc and appears in print with diminishing frequency since the end of the Cold War. In contrast, "maskiIic" spelling, the system haphazardly fashioned by 19th-century proponents of the Jewish Enlightenment (which reflects now obsolete Germanized conventions) continues to thrive in the publications of the expanding hasidic sector. As the one group that has by and large preserved and even encouraged Yiddish as its communal vernacular since the Holocaust, contemporary ultra-Orthodox (and primarily hasidic) Jews regard themselves as the custodians of the language and its traditions. Yiddish is considered a part of the inheritance of their pious East European ancestors, whose way of life they idealize and seek to recreate as much as possible. l The historic irony of this development-namely, the enshrinement of the work of secularized enlighteners, who themselves were bent on modernizing East European Jewry and uprooting Hasidism-is probably lost upon today's tens of thousands of hasidic Yiddish speakers. The irony, however, was not lost on Solomon (in German, Salomo; in Yiddish, Shloyme) Birnbaum (1898-1989), a pioneering Yiddish linguist and Hebrew pa leographer in the ultra-Orthodox sector. This essay examines Birnbaum's own "Or thodox" orthography for Yiddish in both its purely linguistic and broader ideolog ical contexts in interwar Poland, then home to the largest Jewish community in Europe and the world center of Yiddish culture.